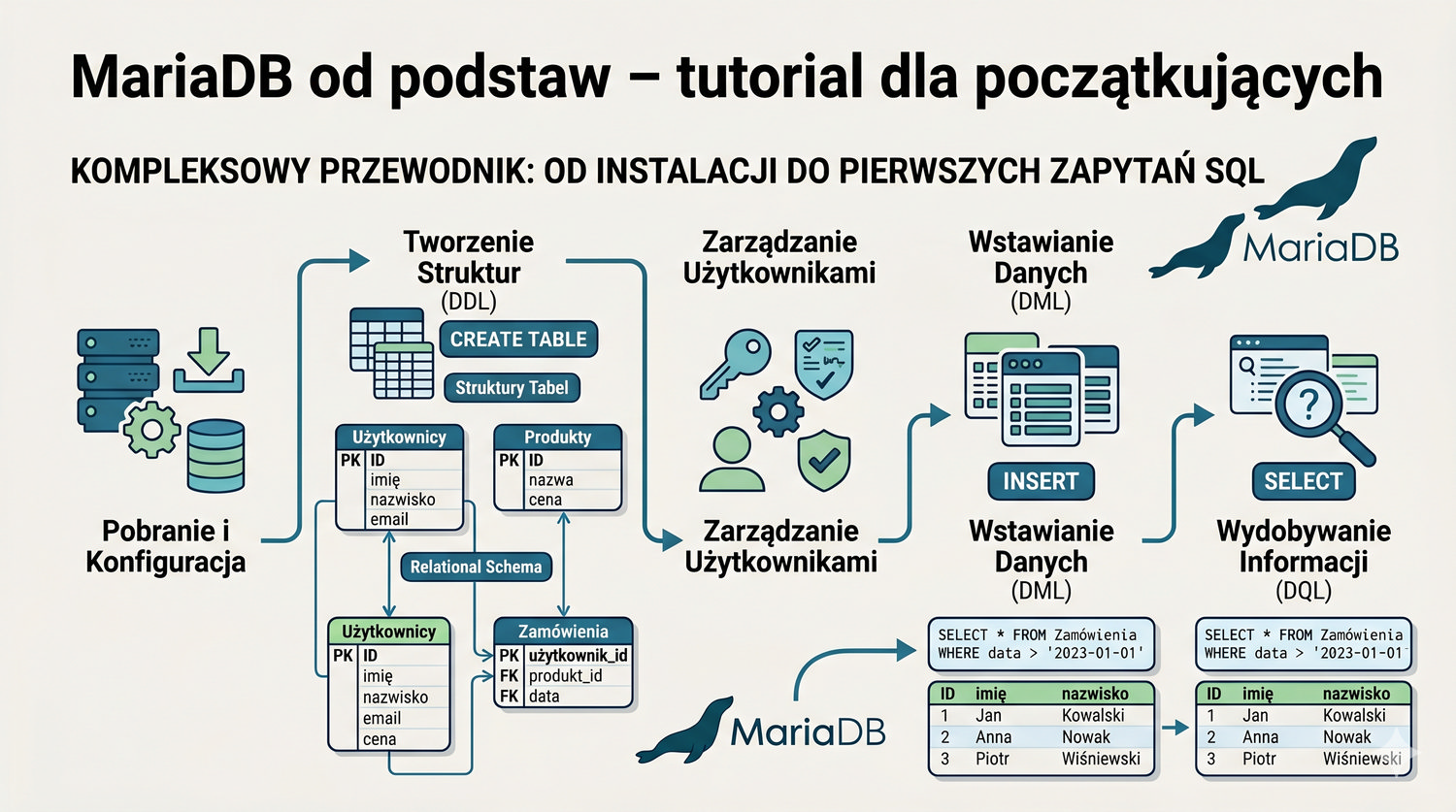
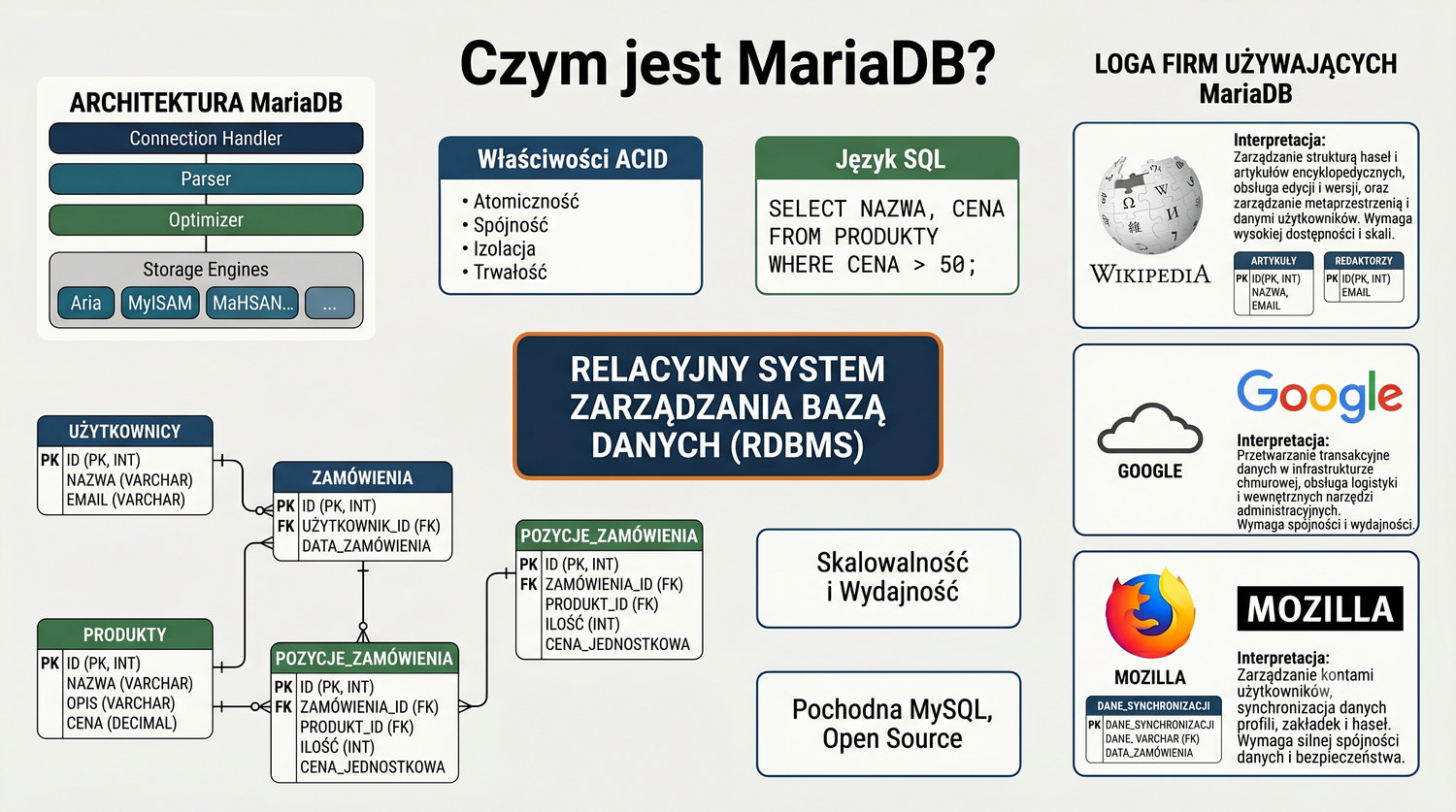
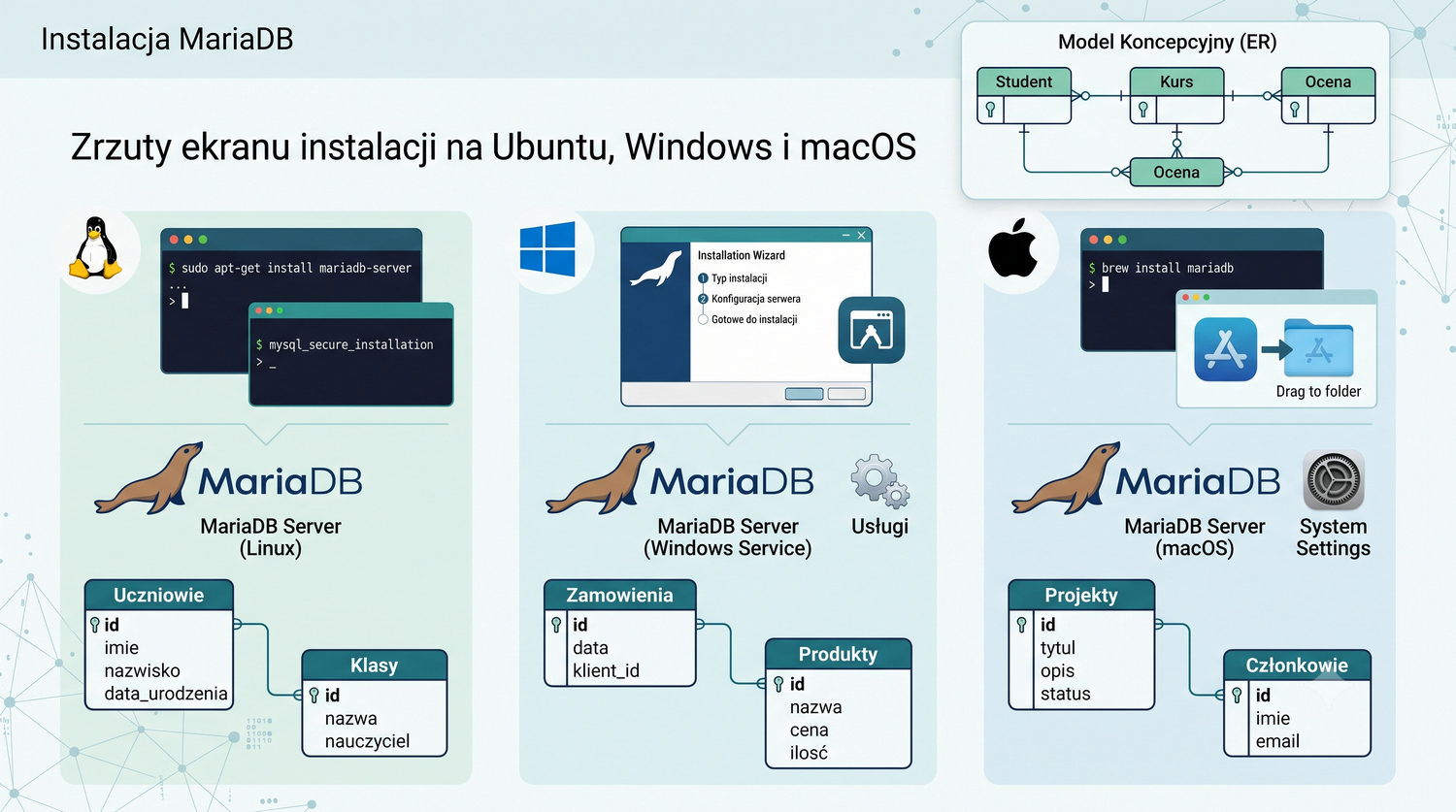
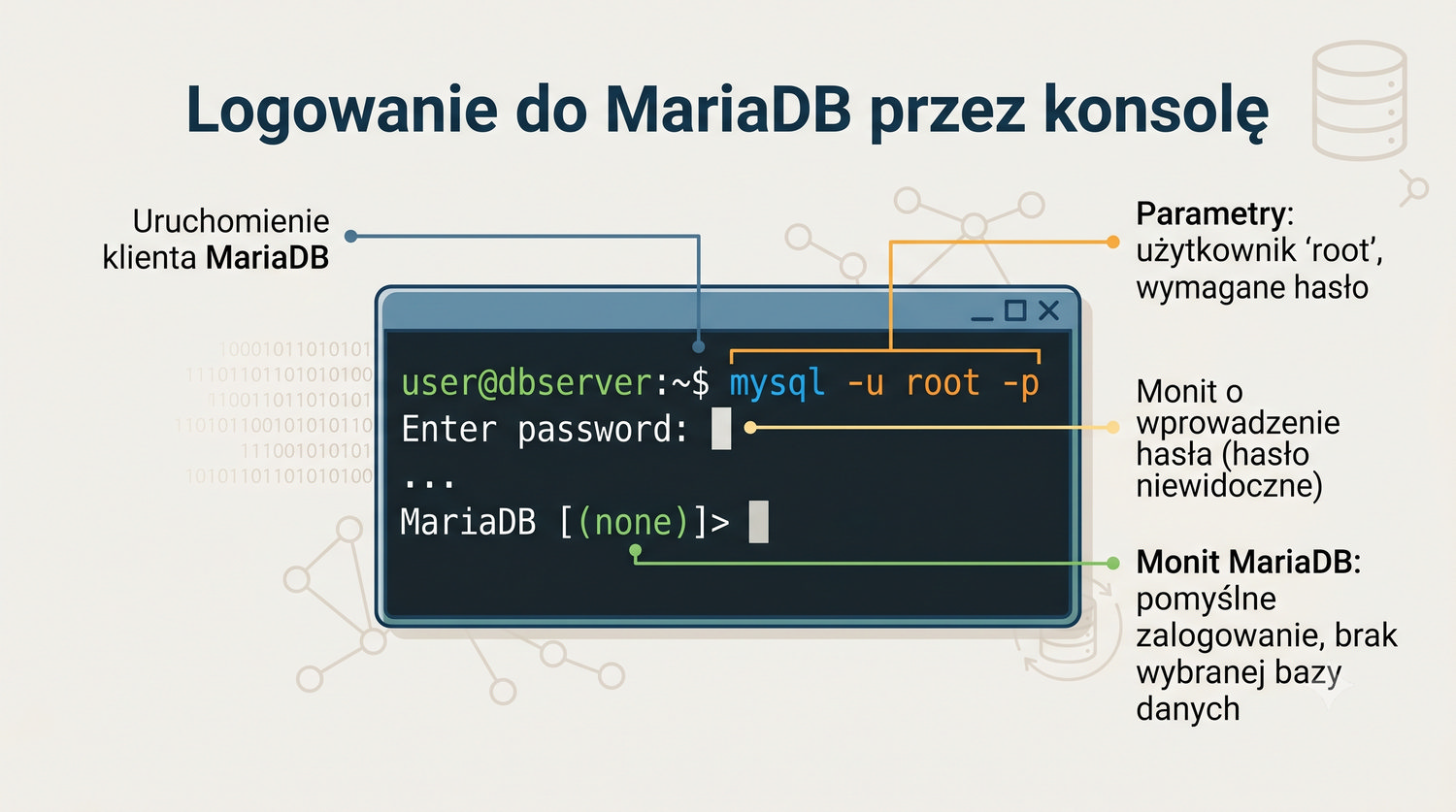
Kompleksowy przewodnik: od instalacji do pierwszych zapytań SQL
Zakładamy zerowy poziom wiedzy – zaczniemy od uruchomienia MariaDB, a skończymy na zaawansowanych zapytaniach SQL.
Czego się nauczysz?
- Instalacji i uruchamiania MariaDB
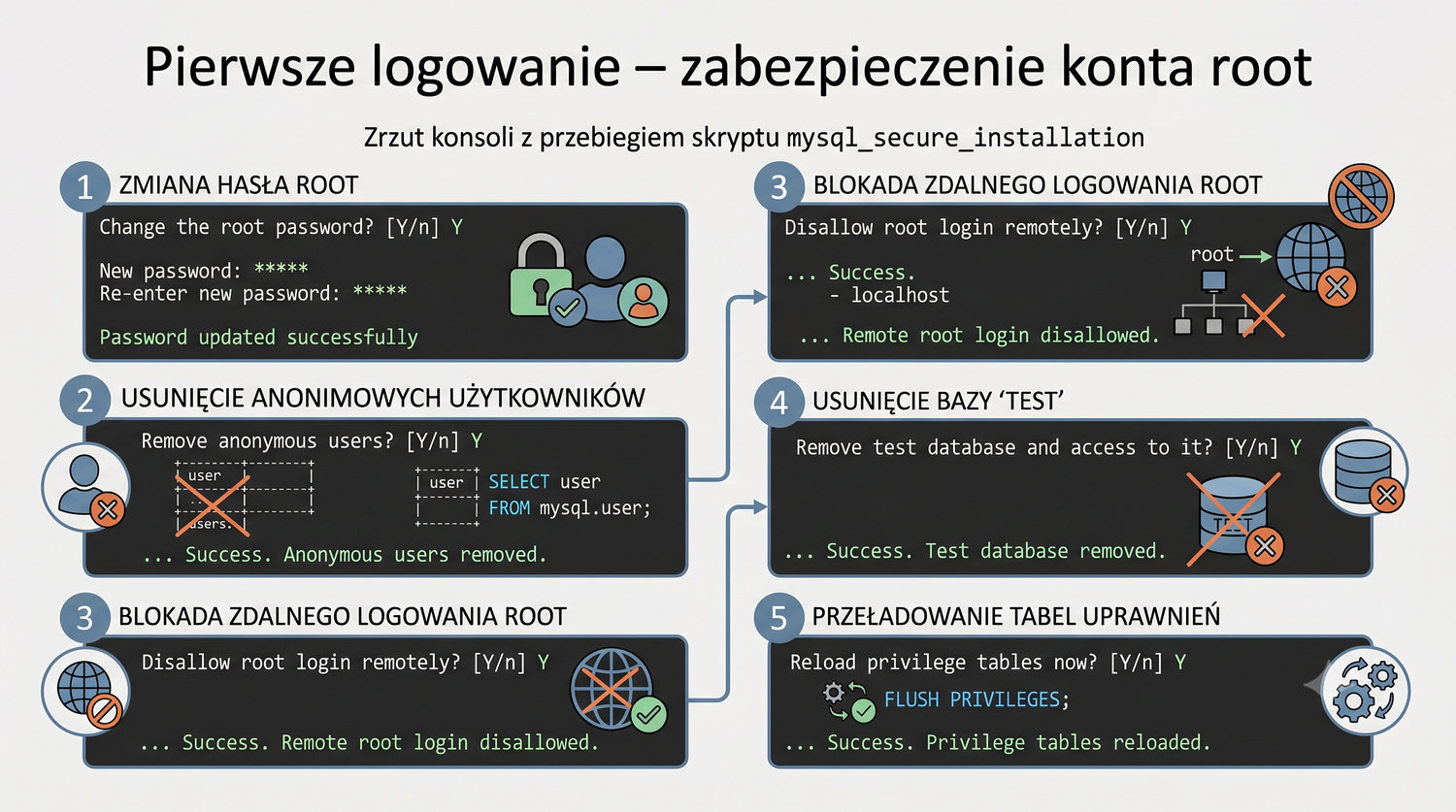
- Logowania i podstawowej konfiguracji
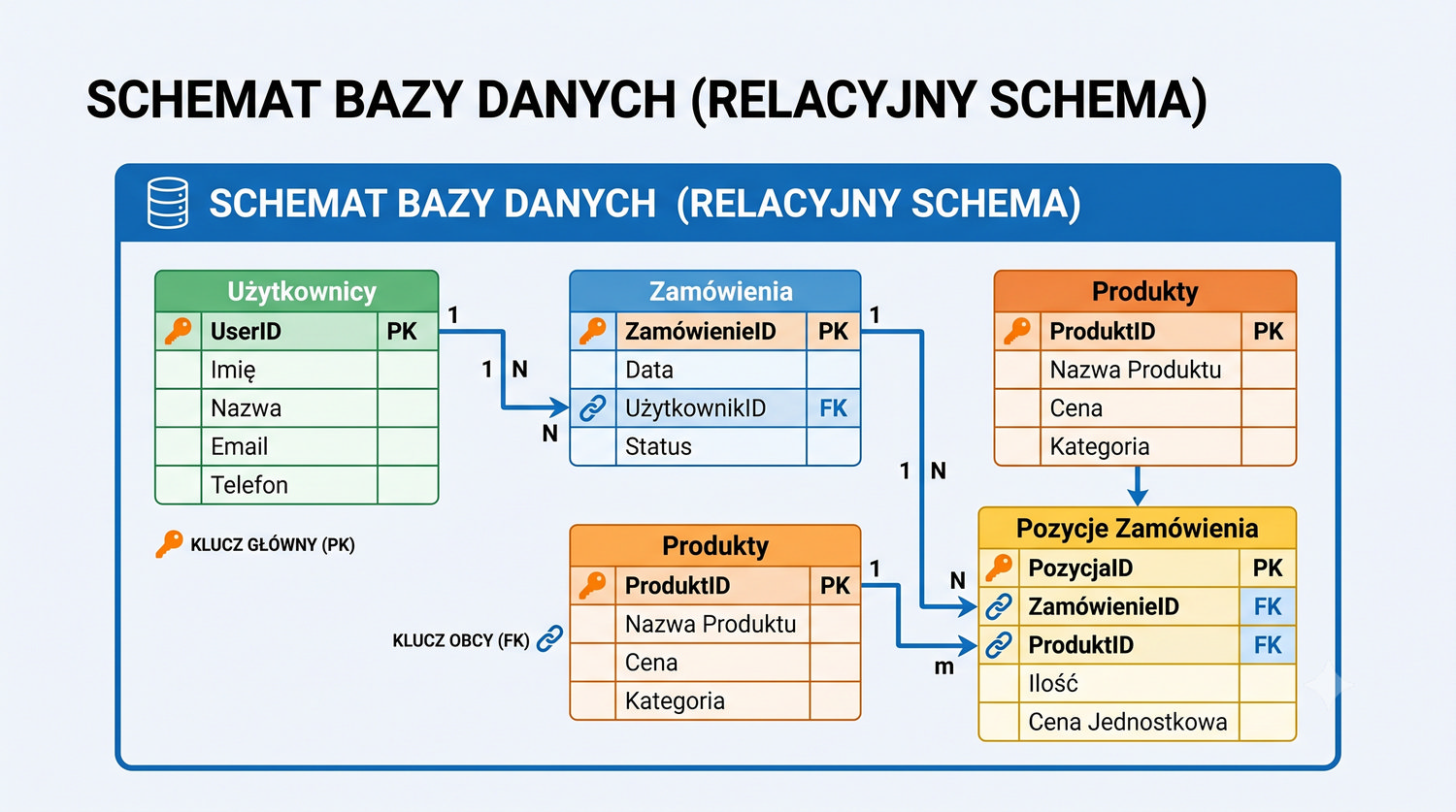
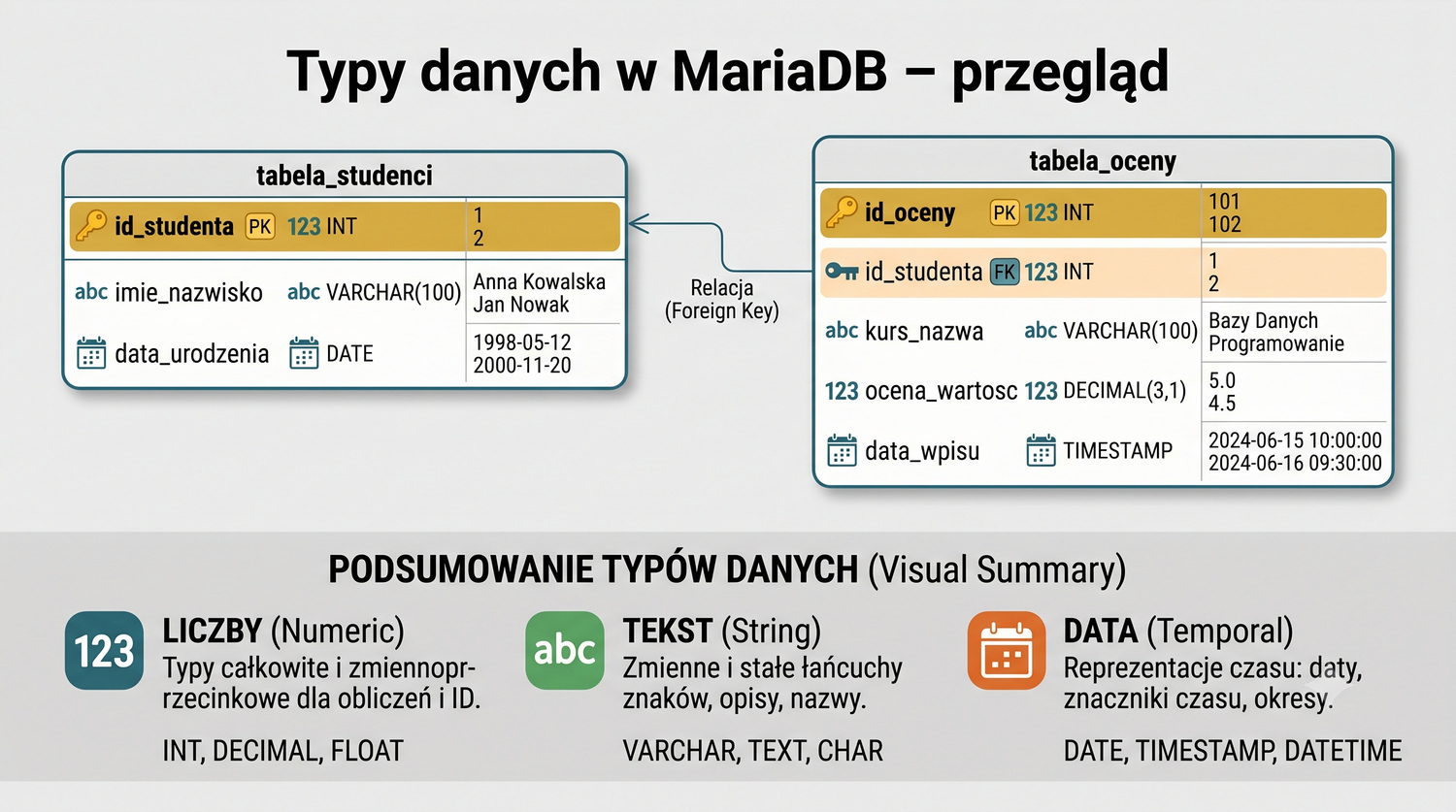
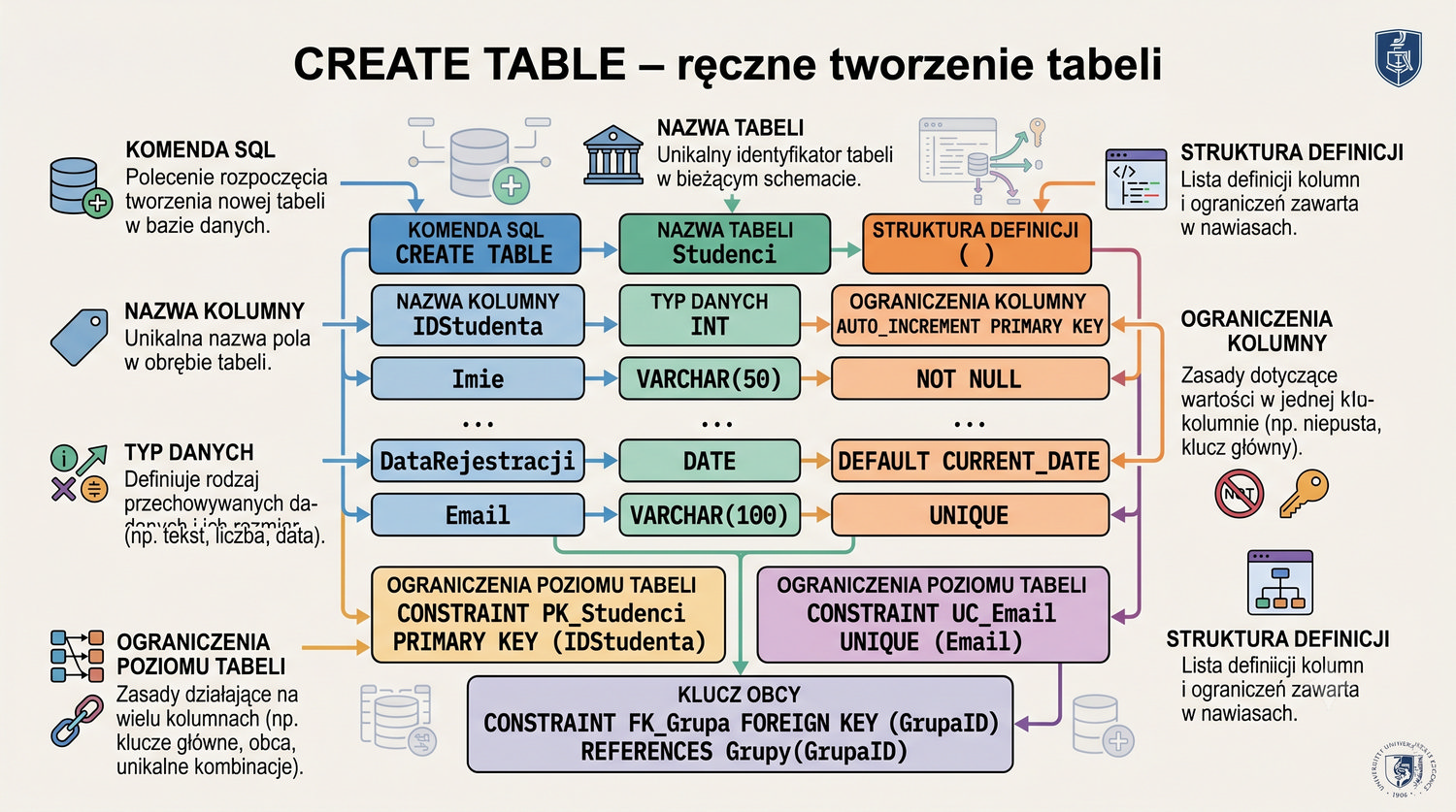
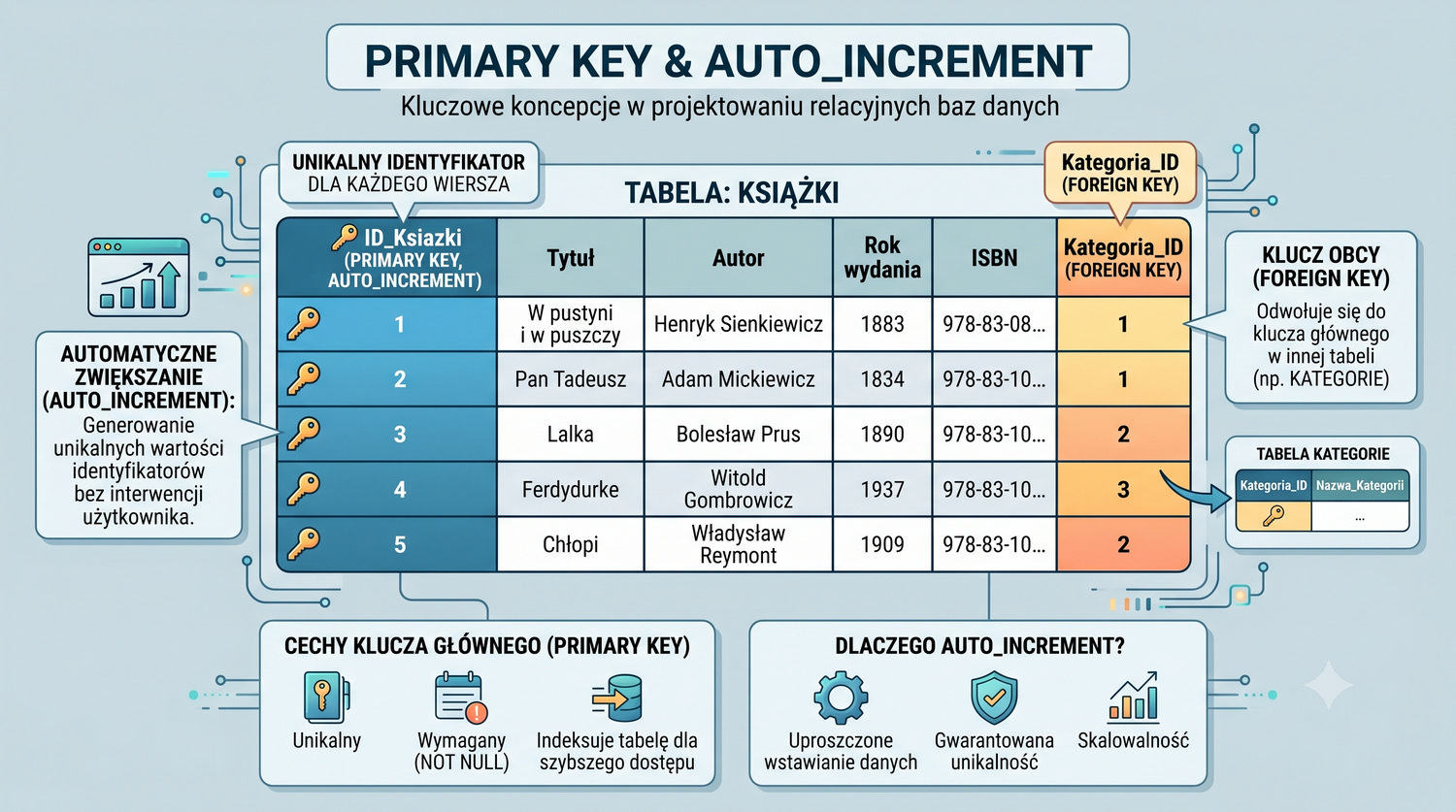
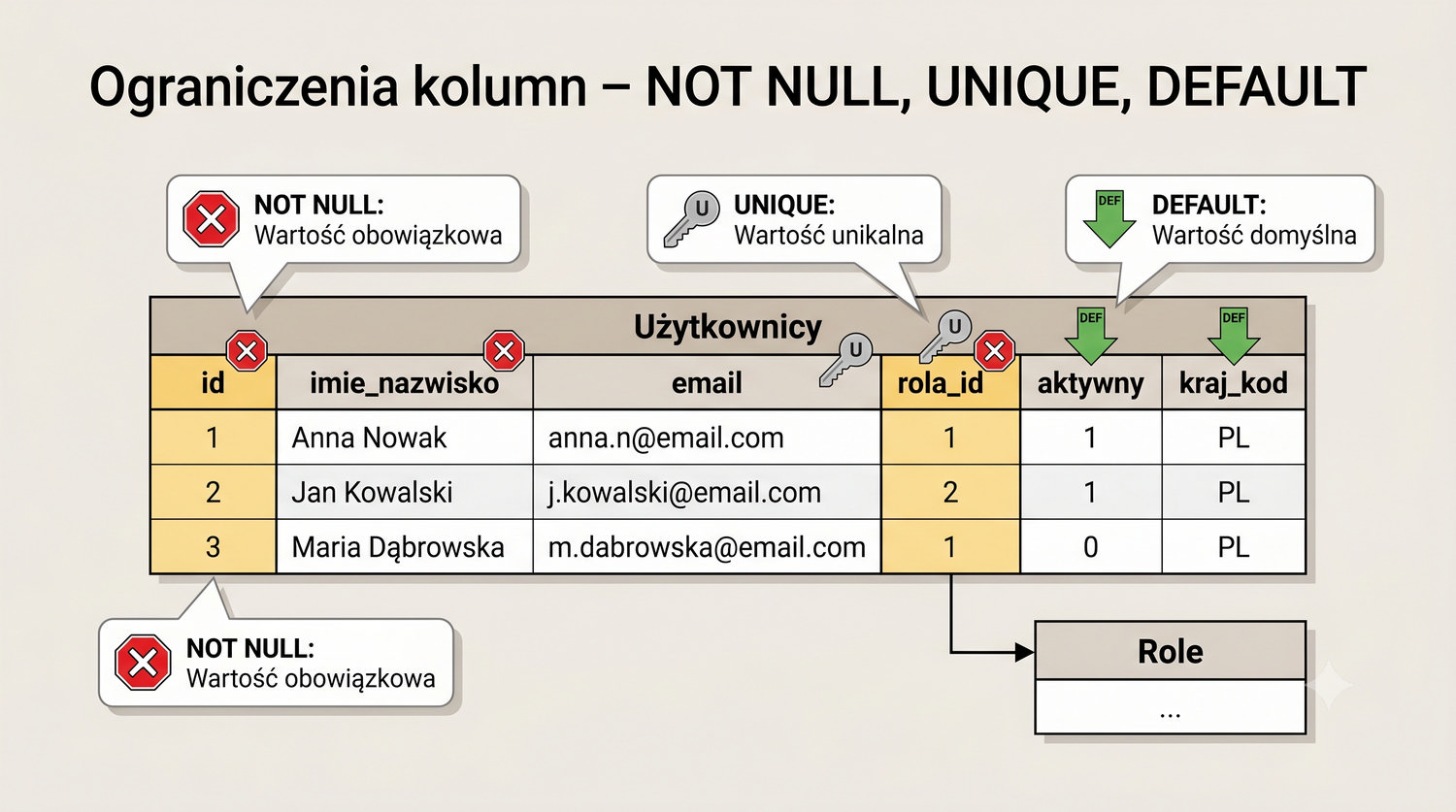
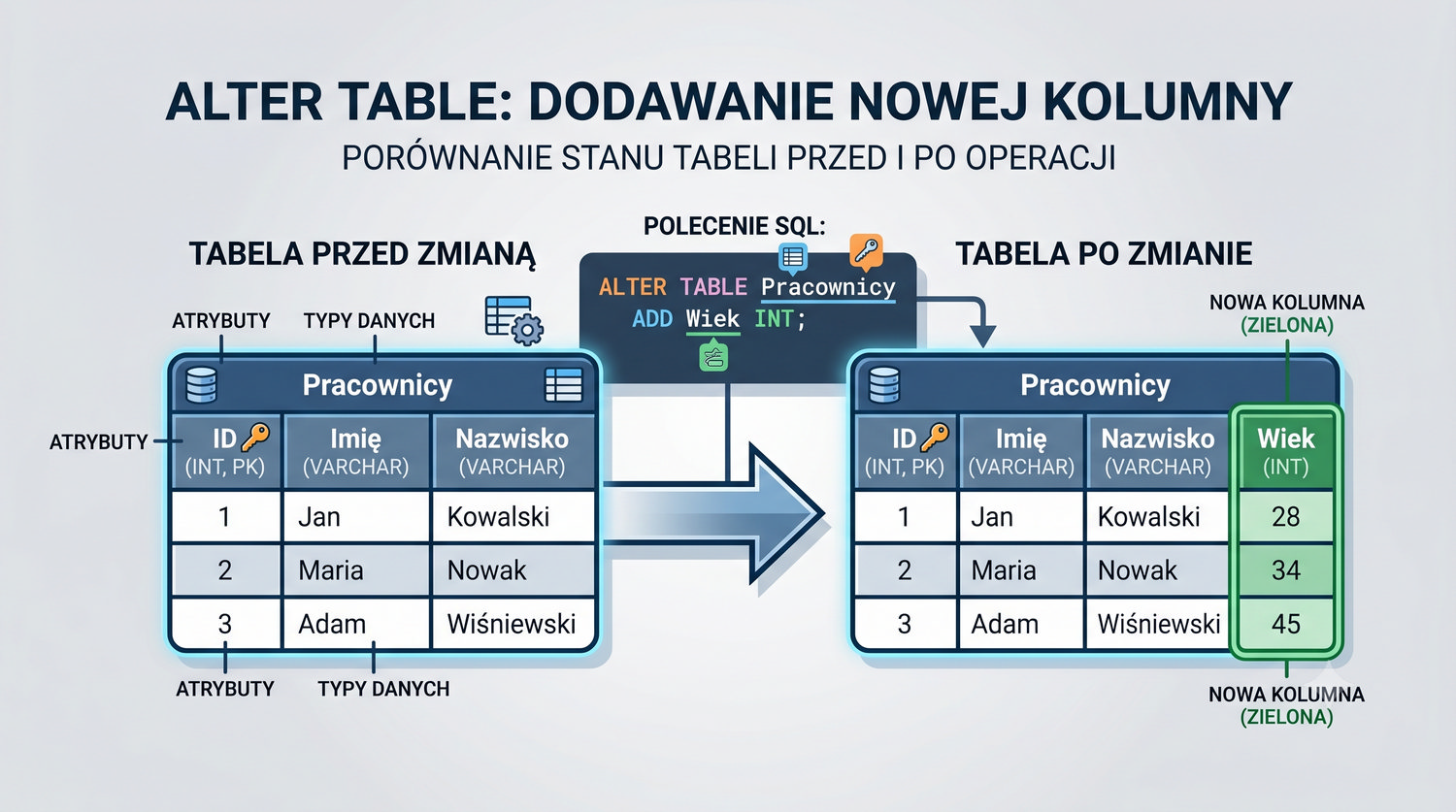
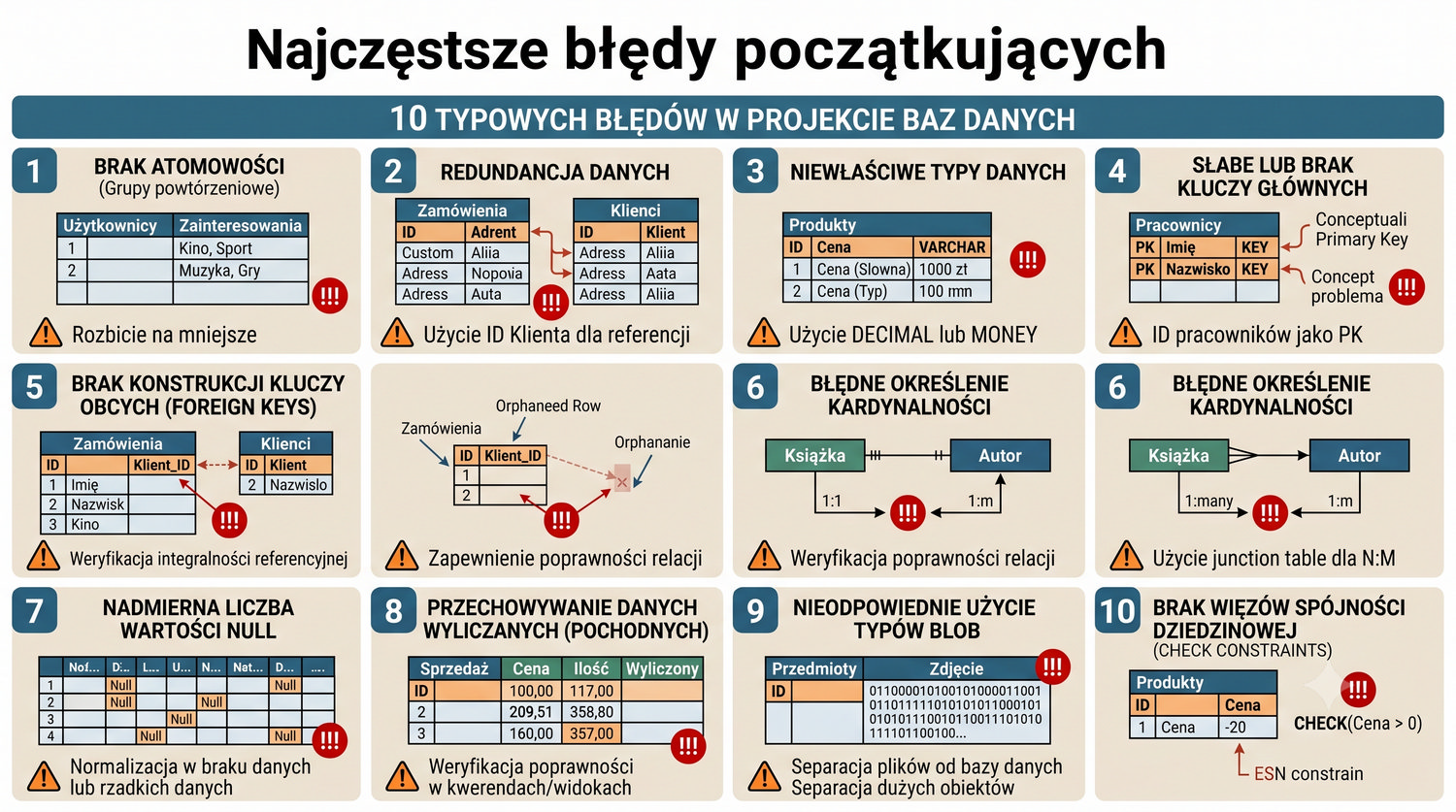
- Tworzenia baz danych i tabel (ręcznie)
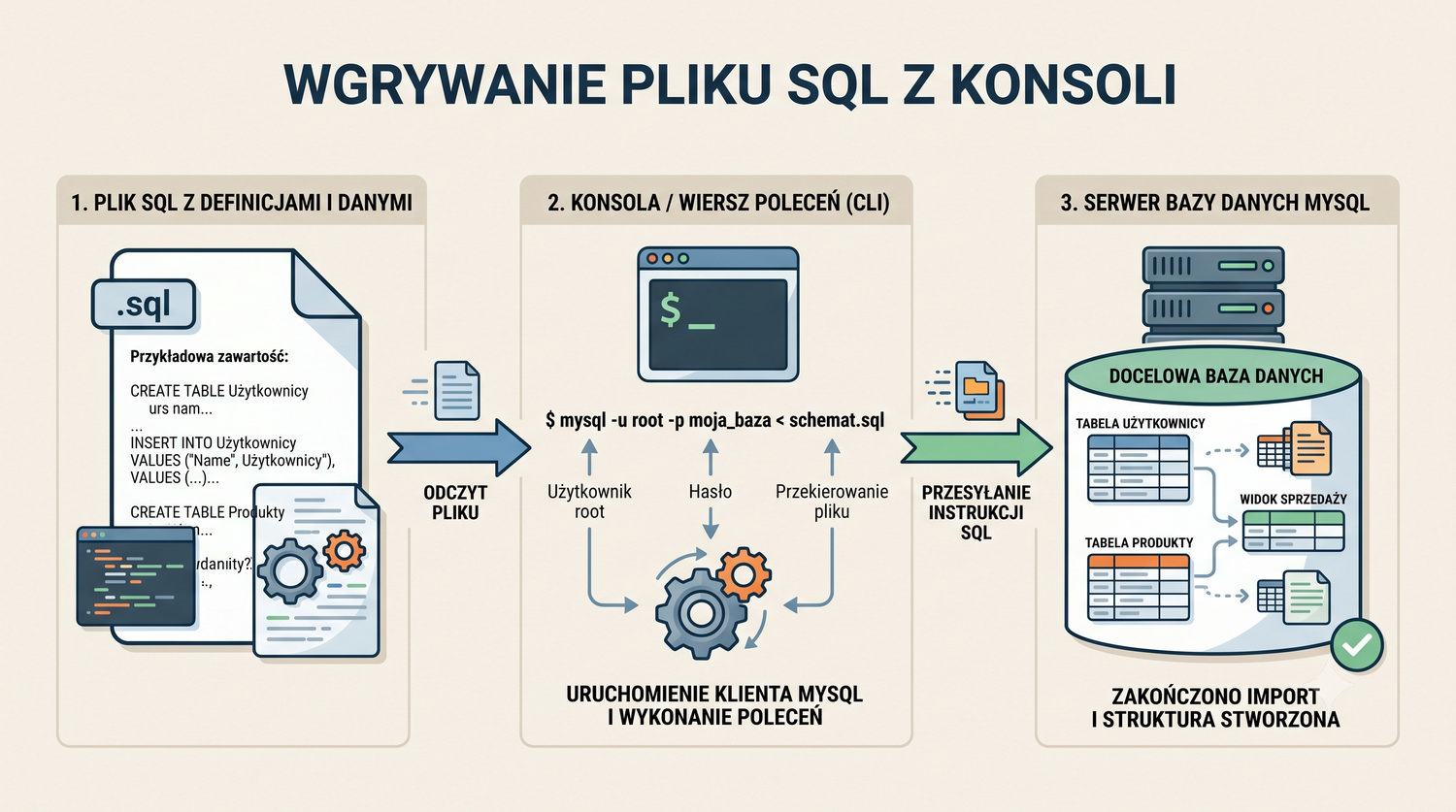
- Wgrywania plików SQL
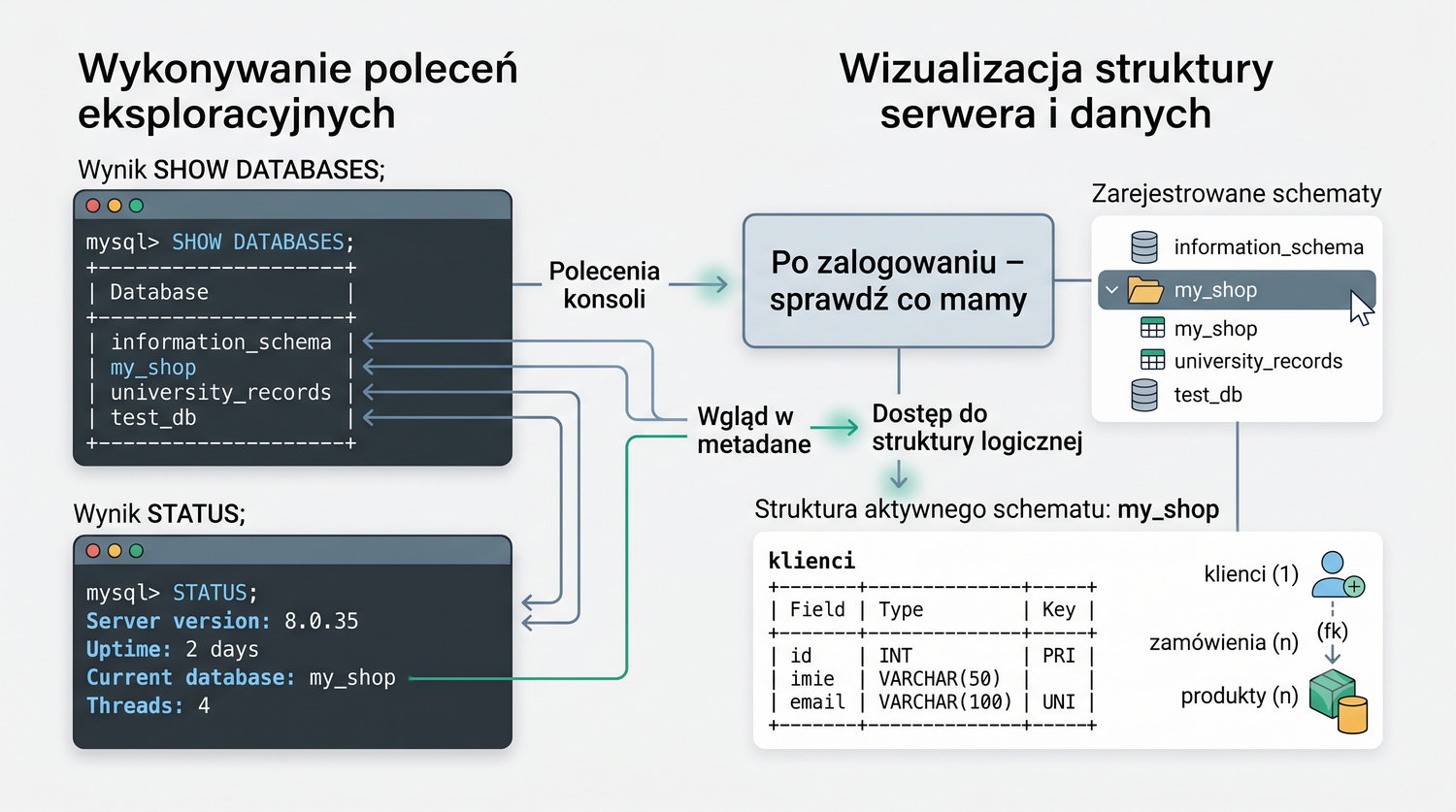
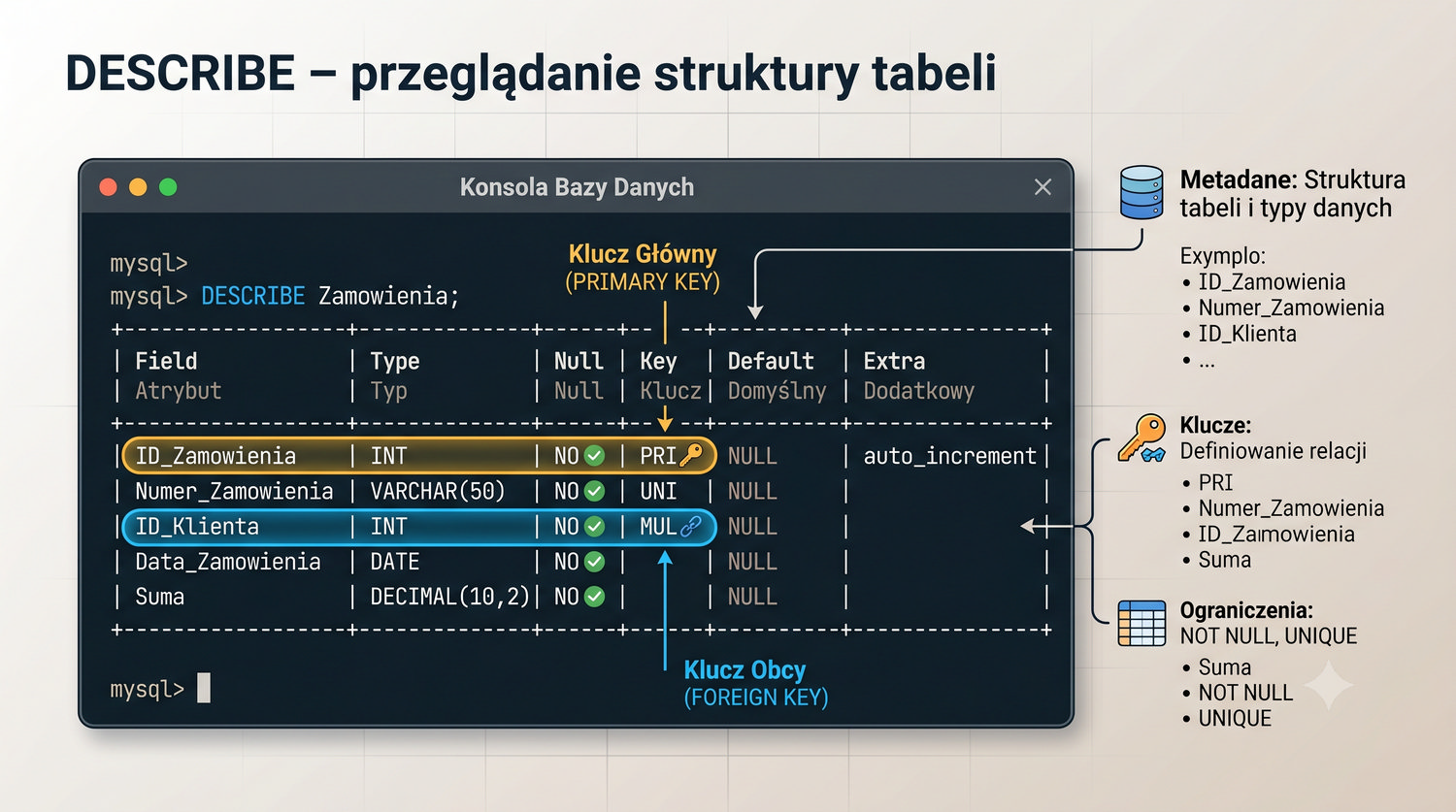
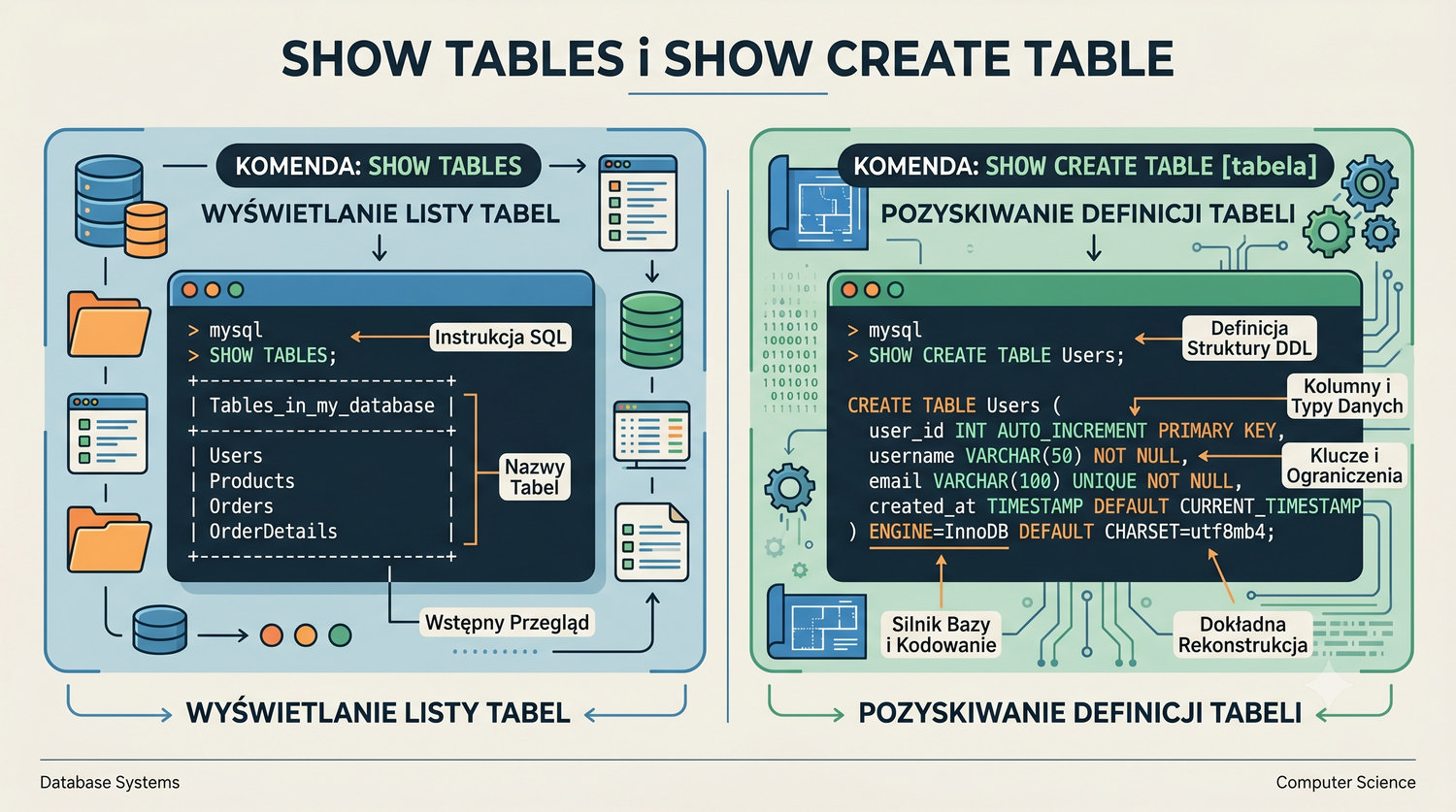
- Przeglądania struktury bazy
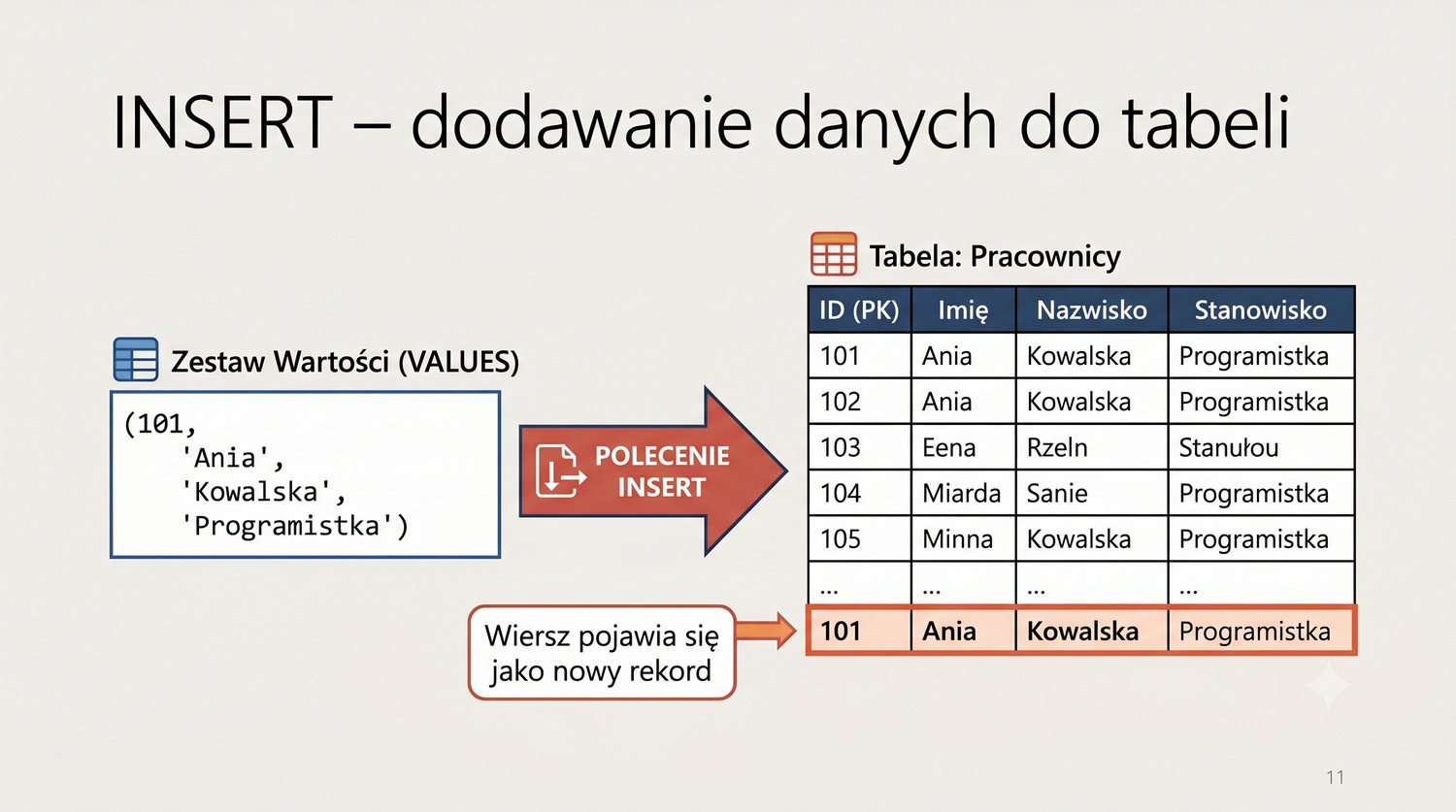
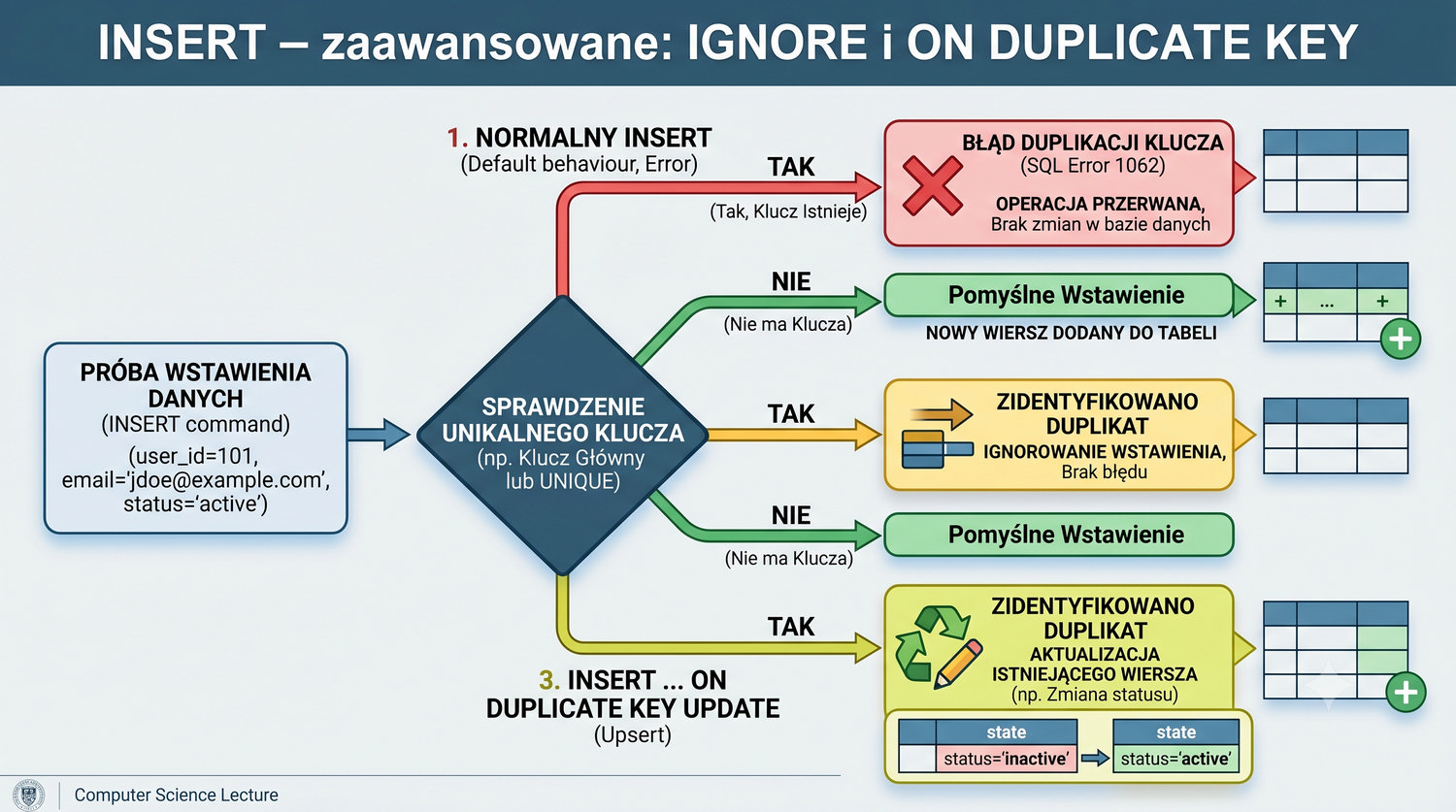
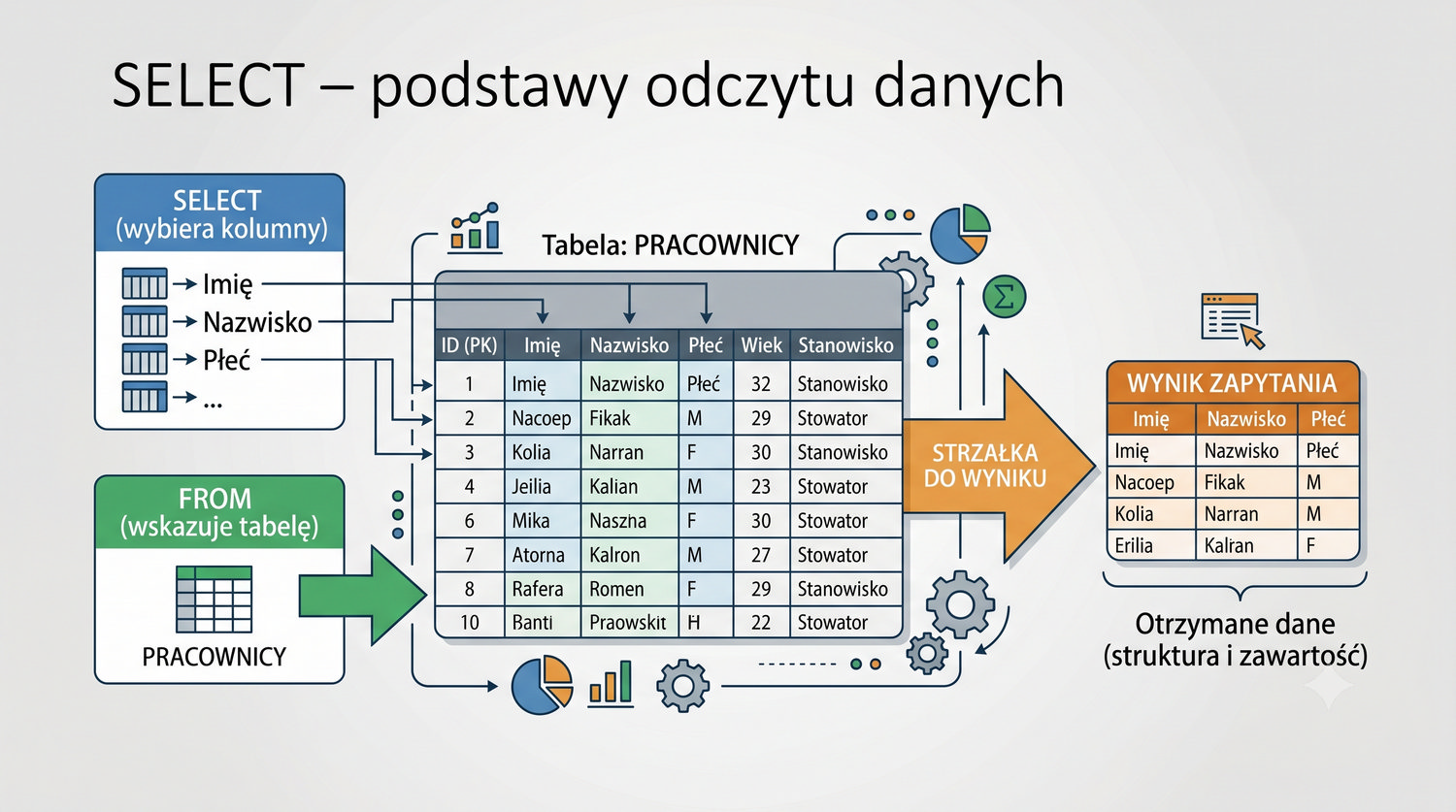
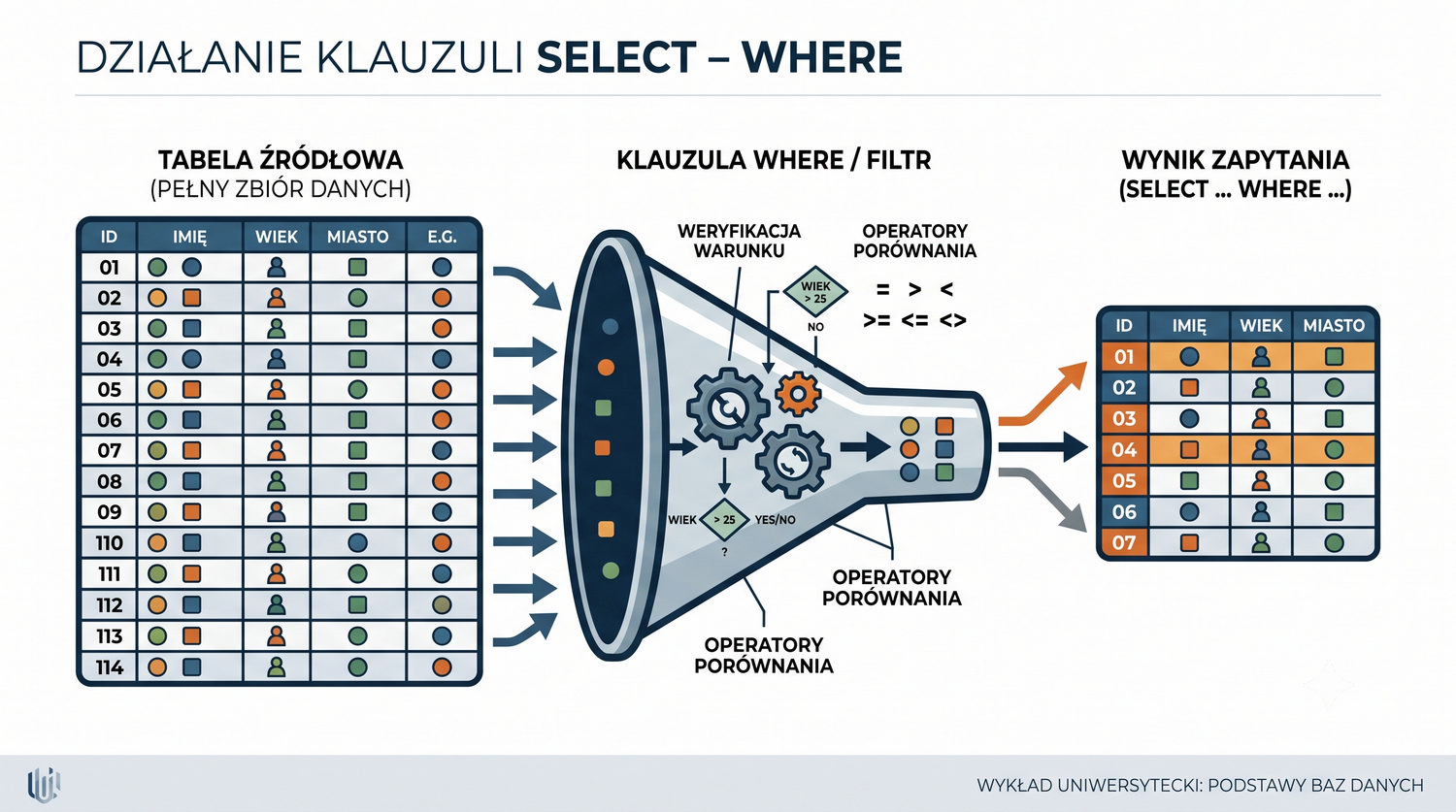
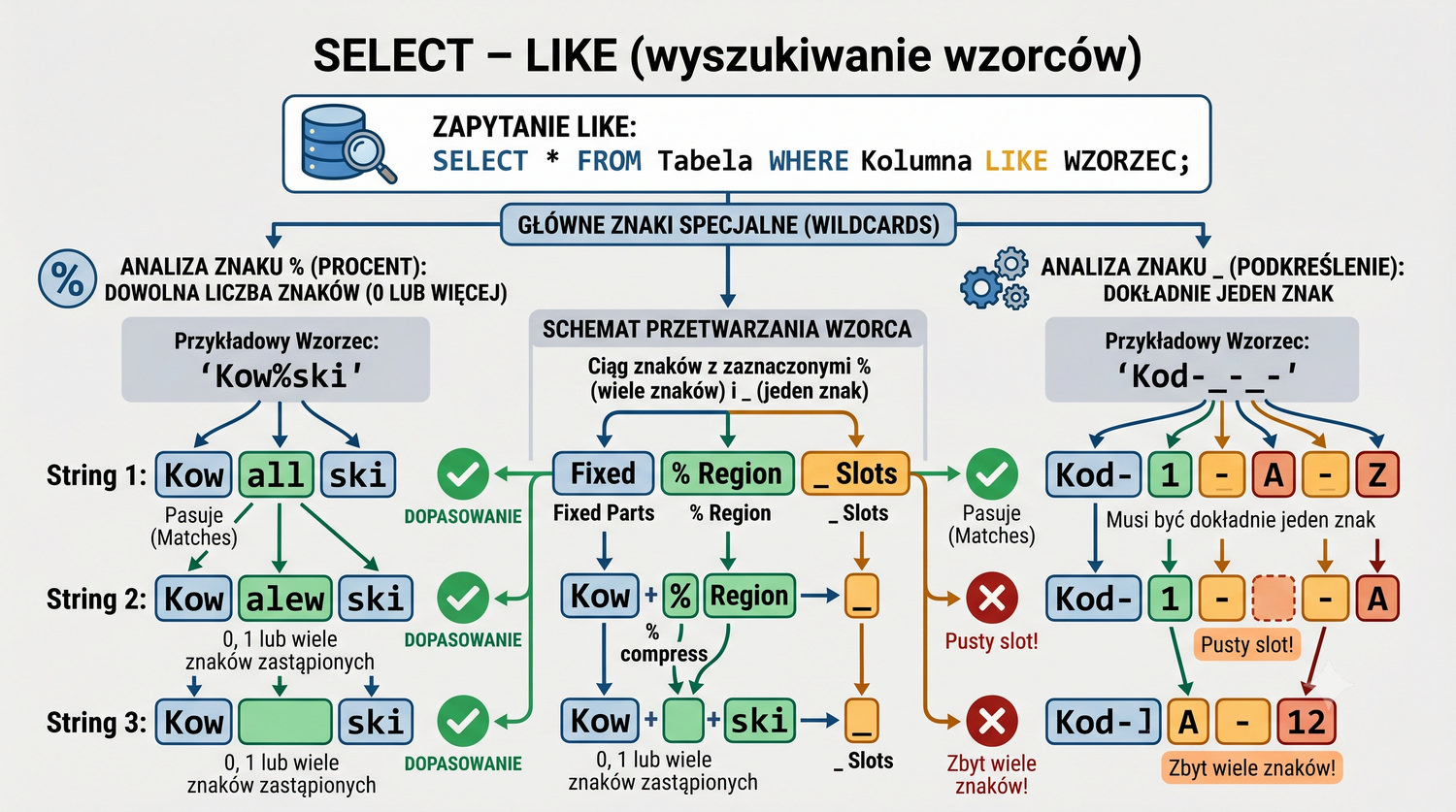
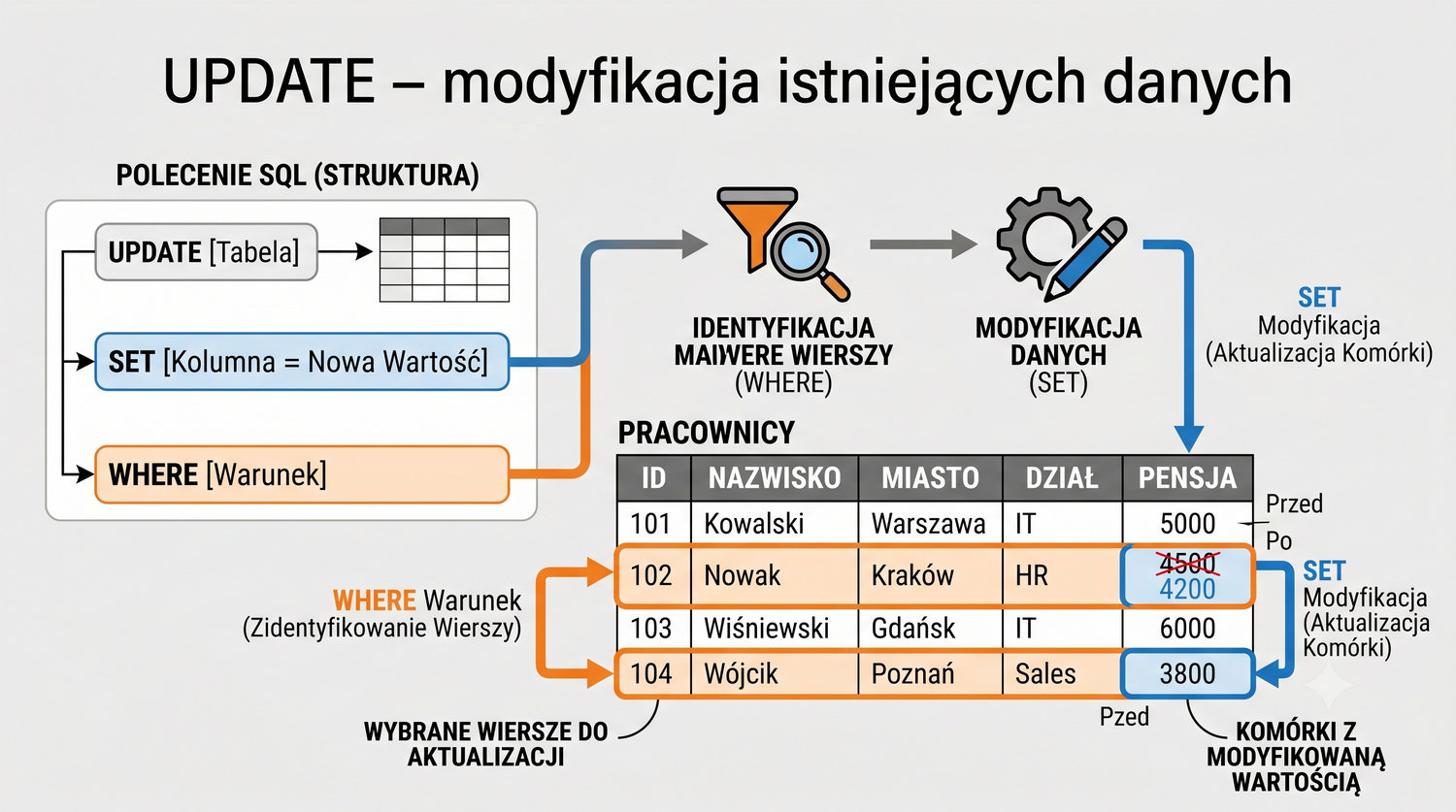
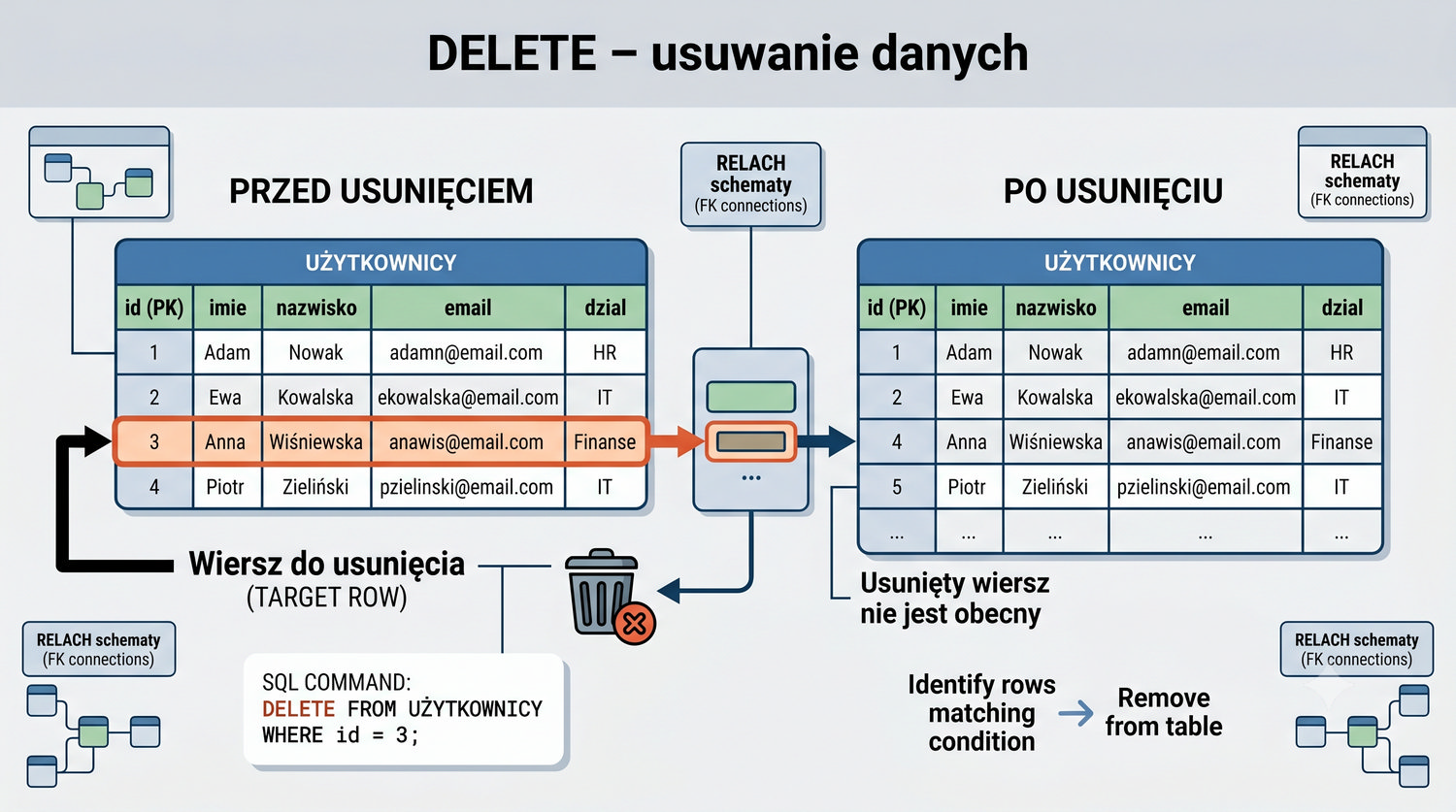
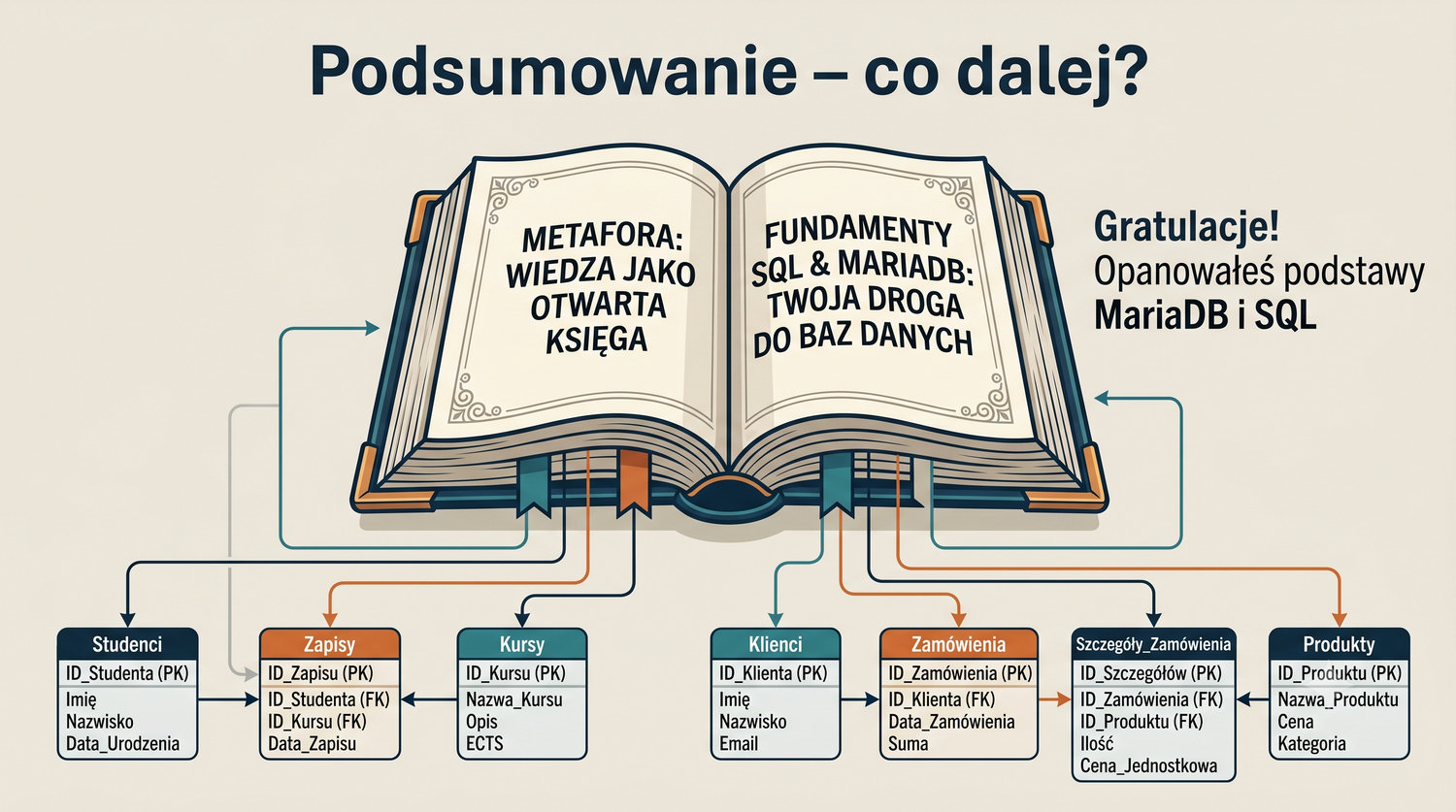
- Poleceń SQL: INSERT, SELECT, UPDATE, DELETE
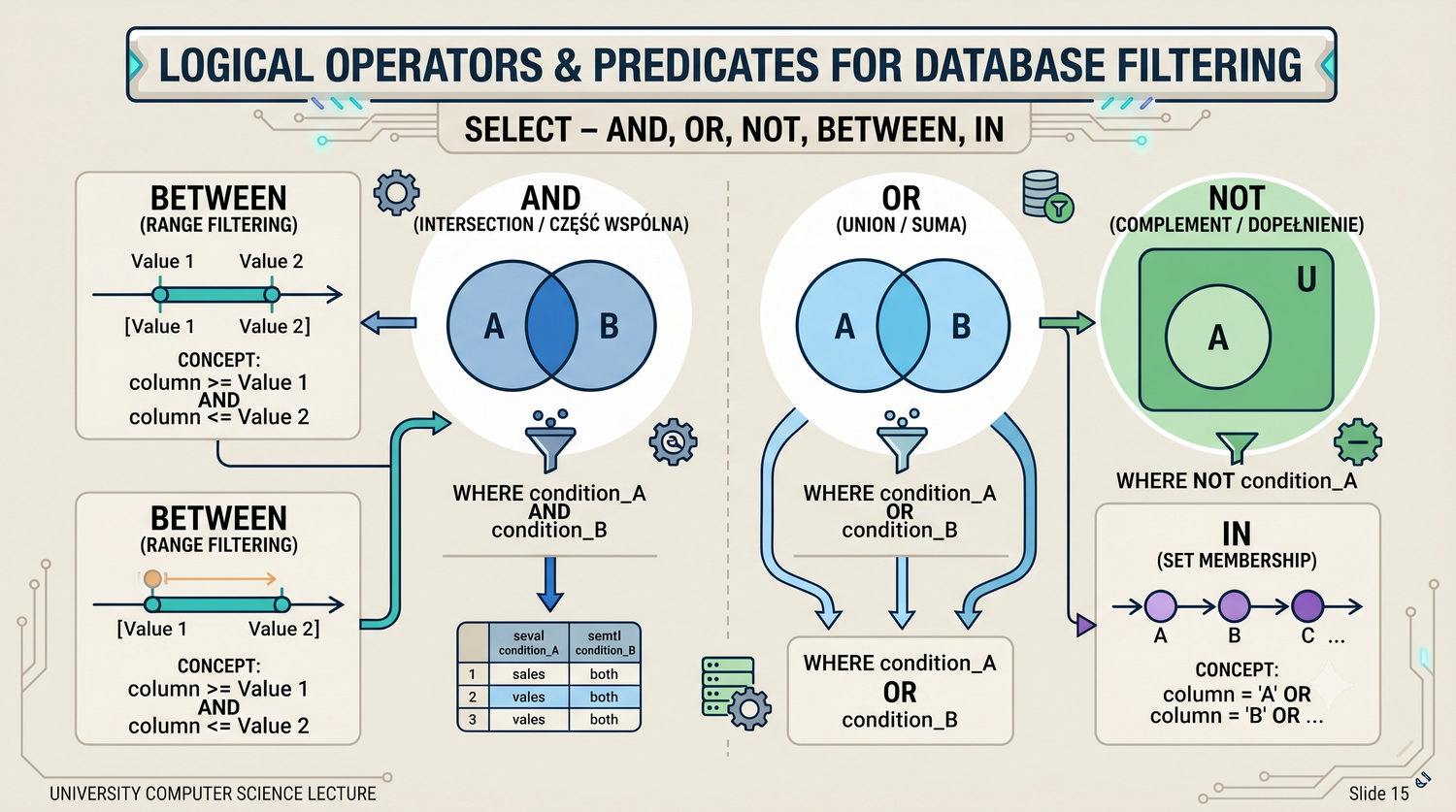
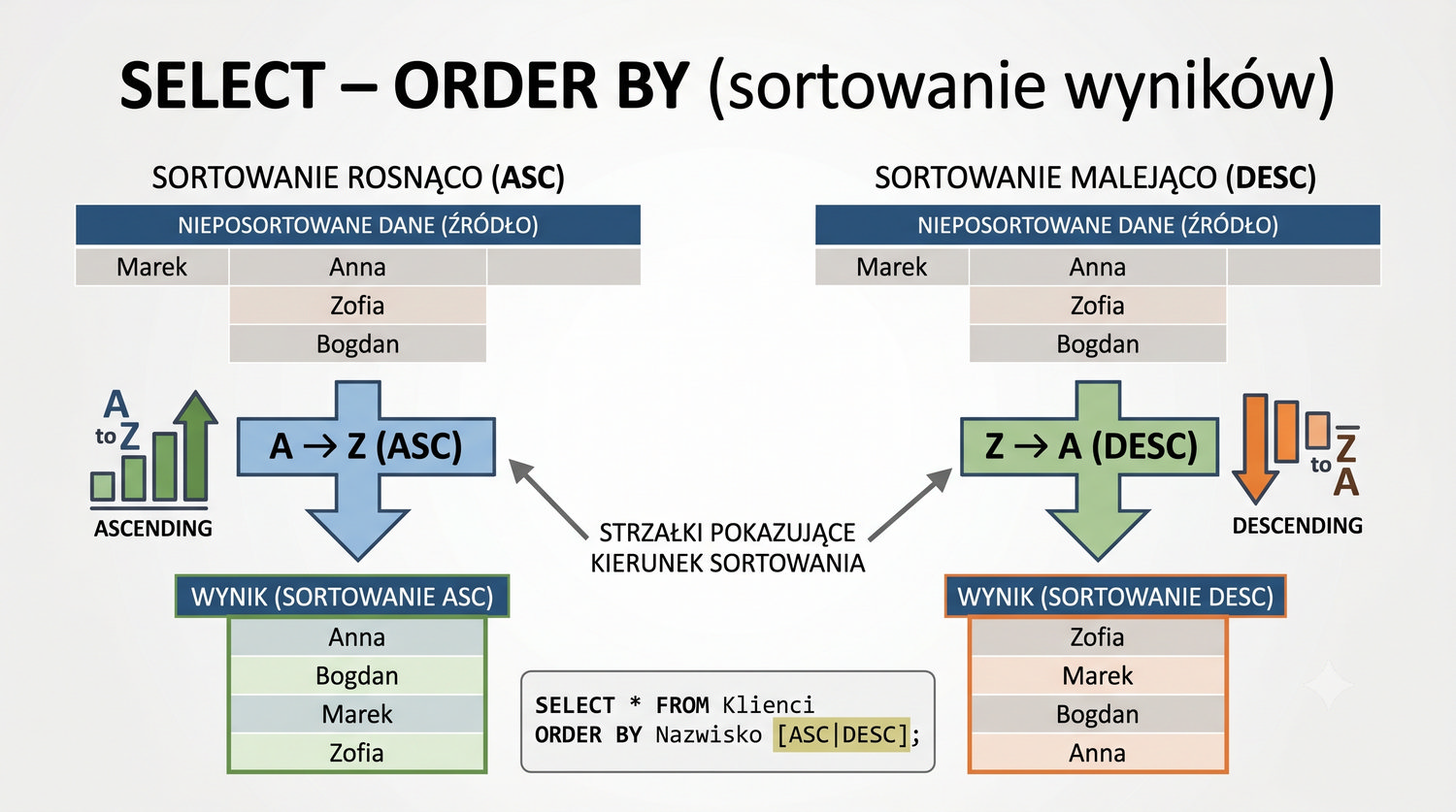
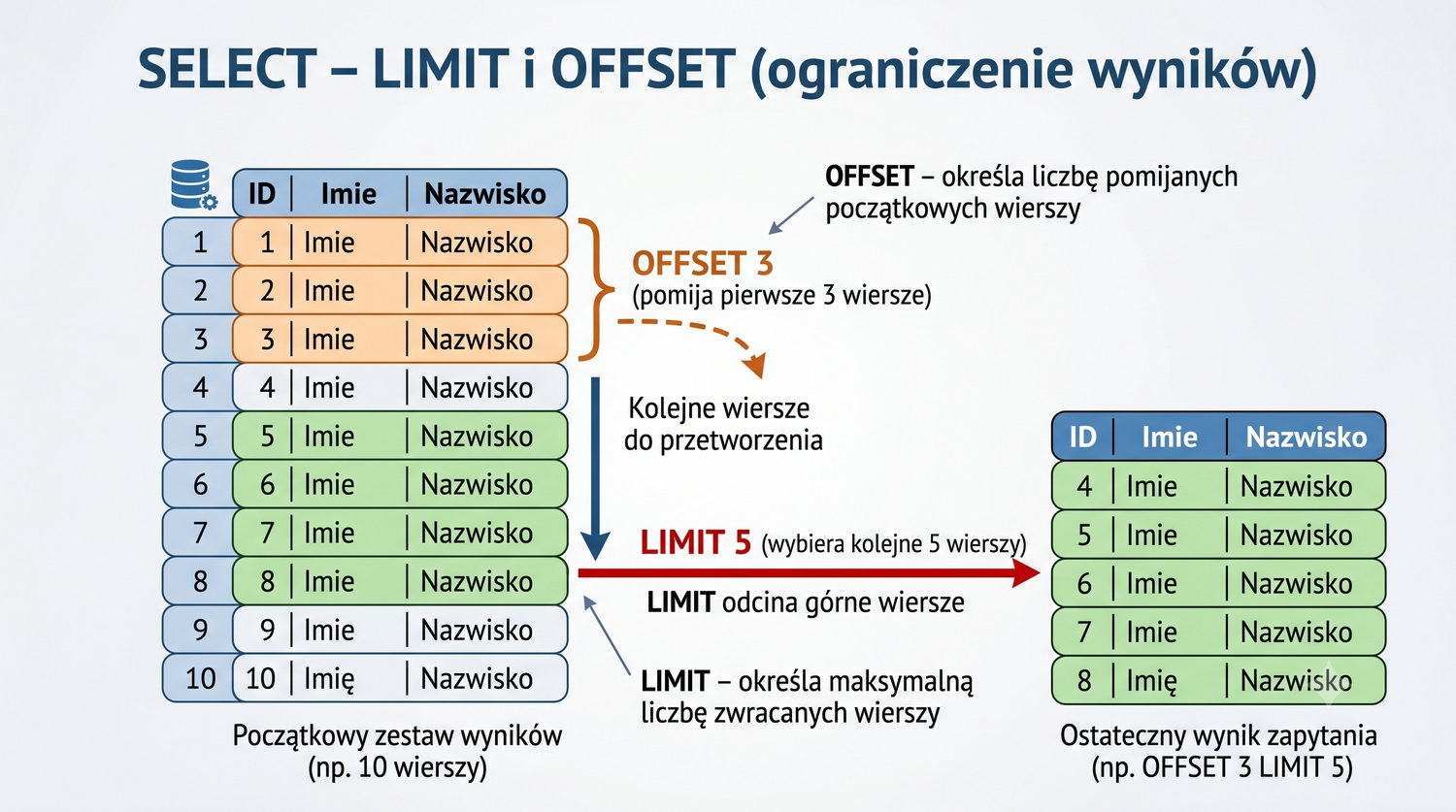
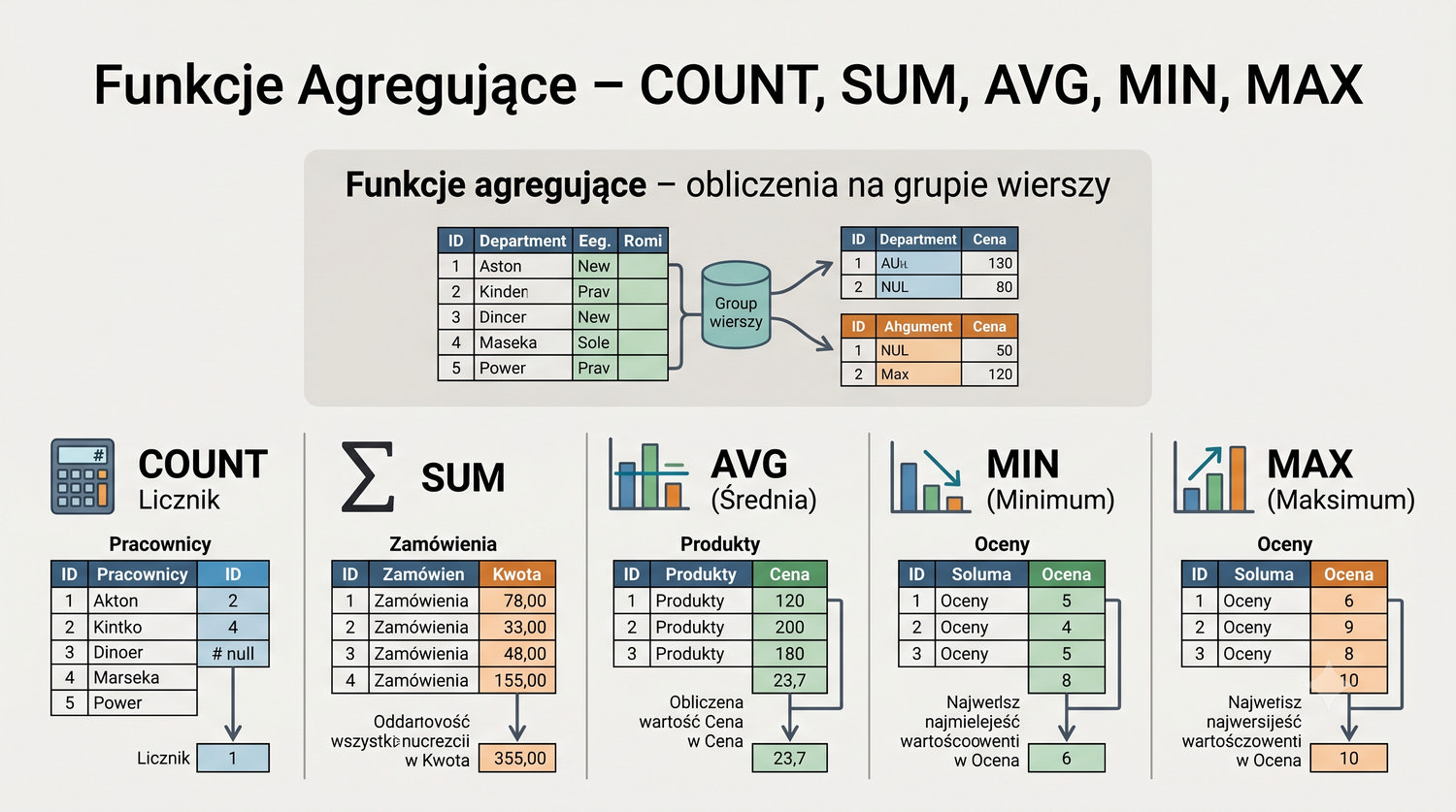
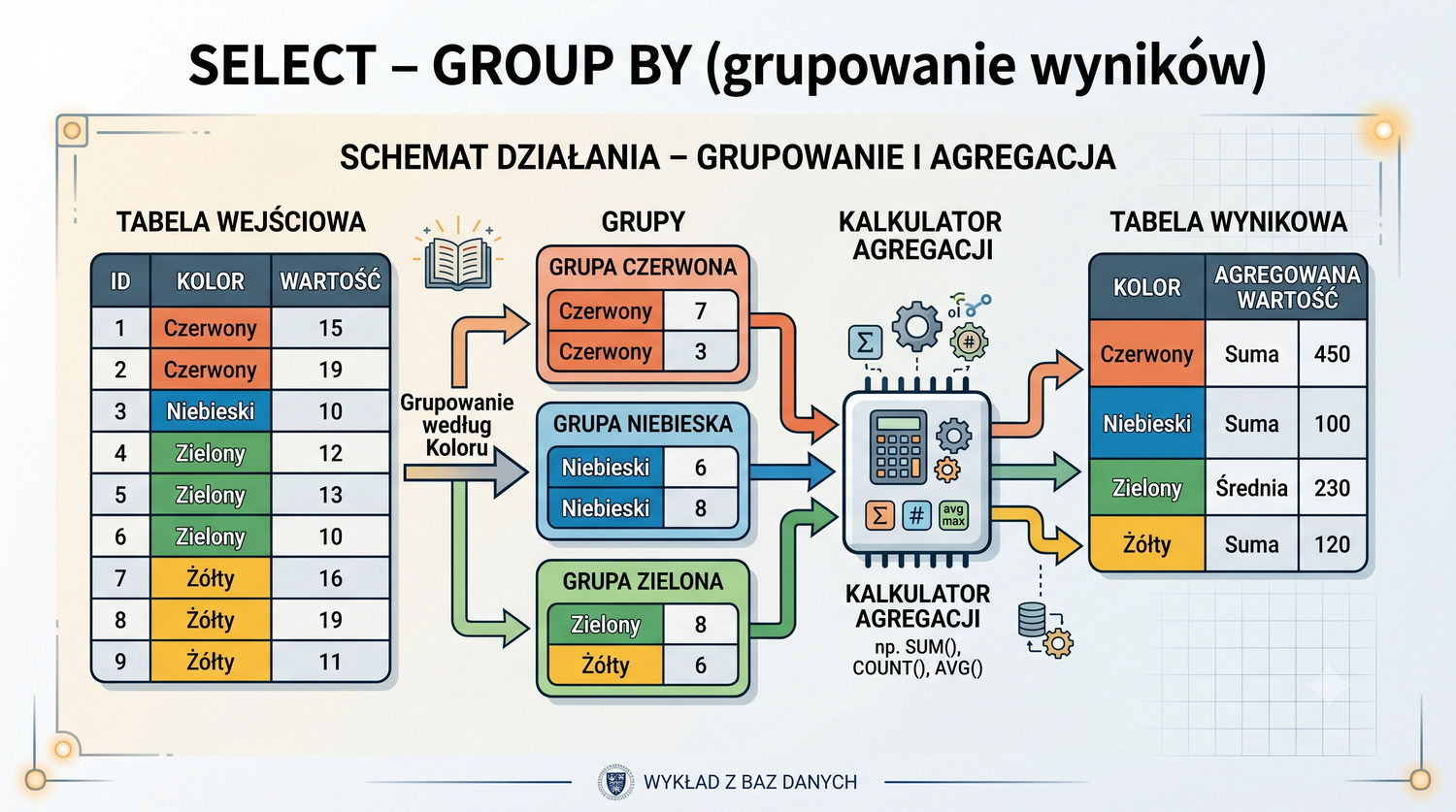
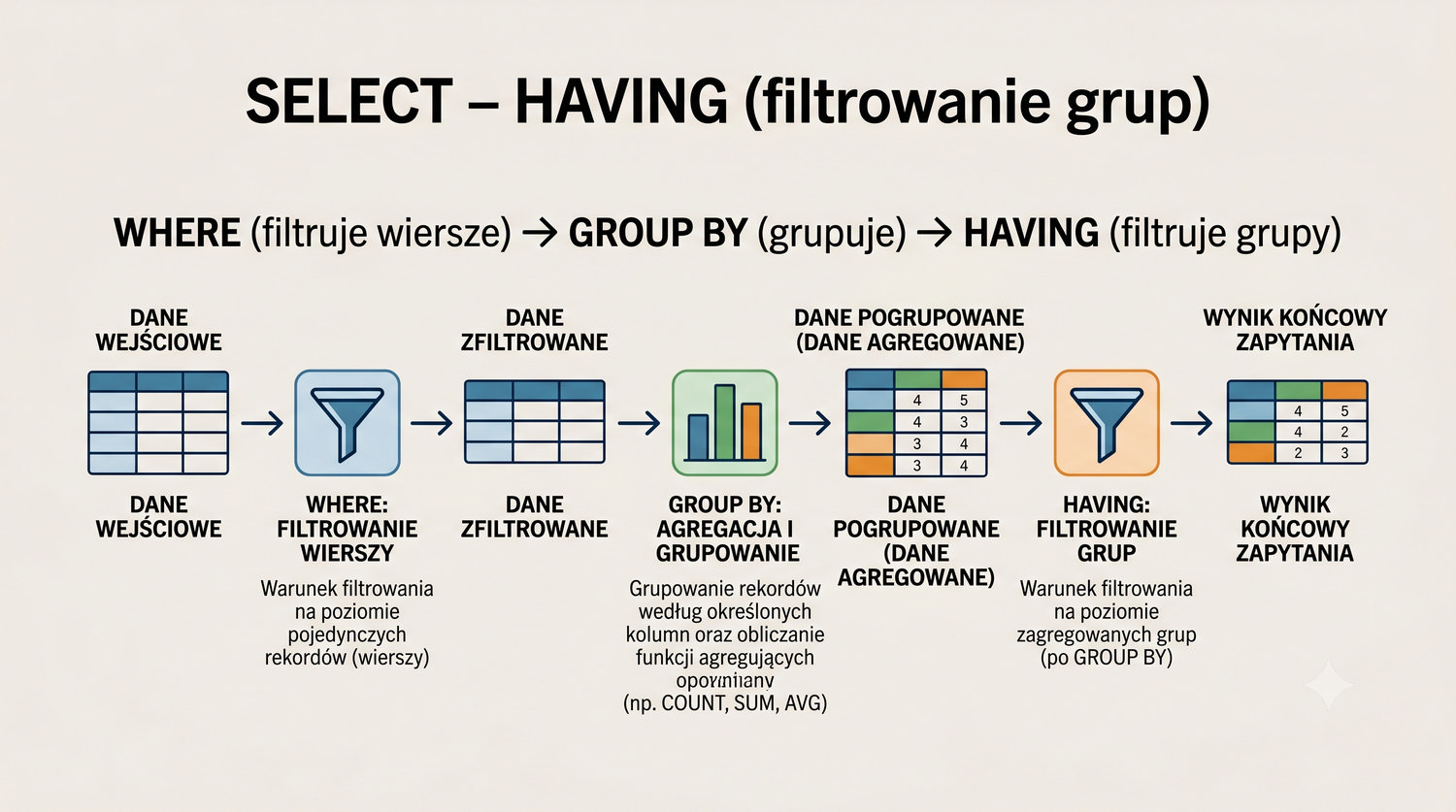
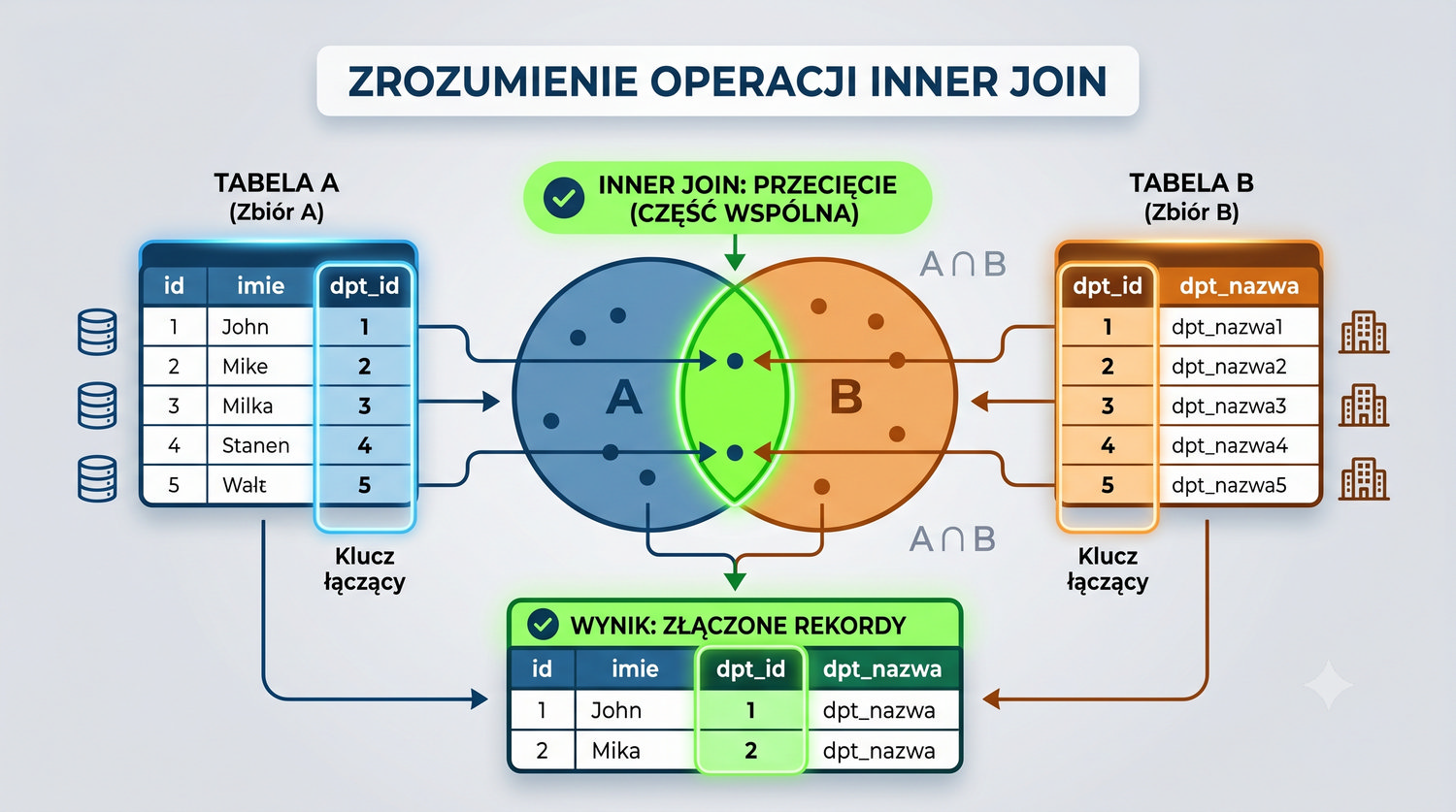
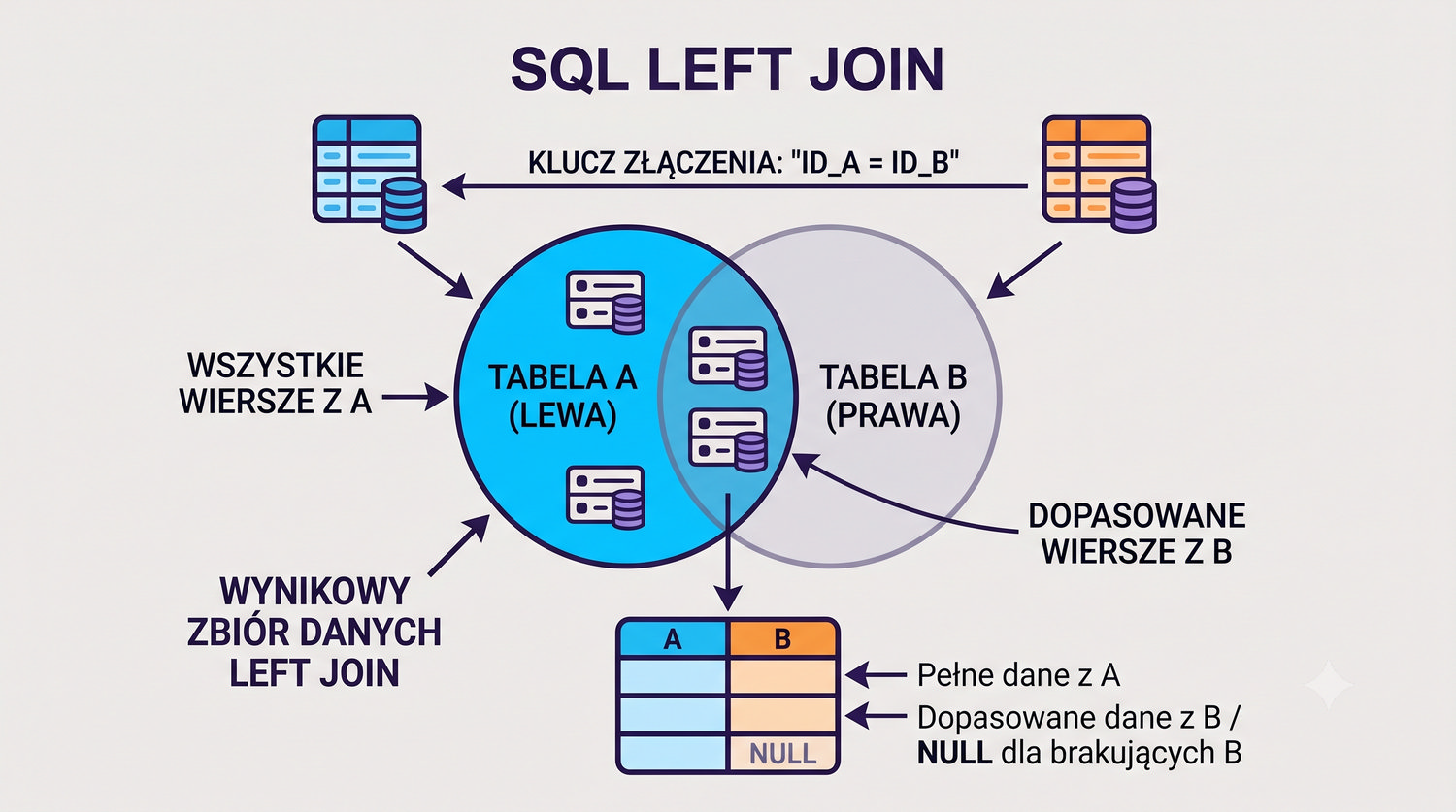
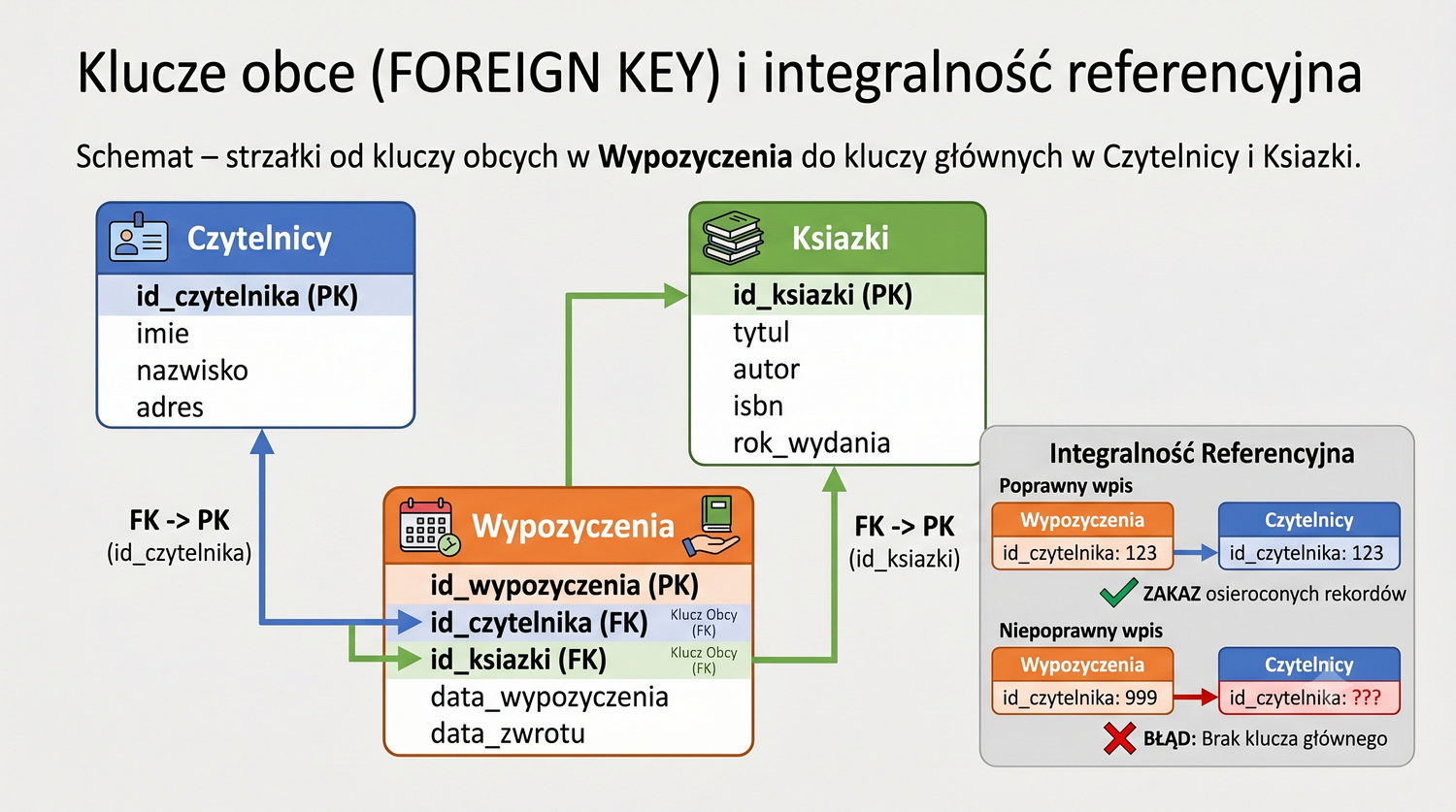
- Łączenia tabel (JOIN), grupowania, indeksów
Nie potrzebujesz żadnego doświadczenia – wszystko wyjaśniamy krok po kroku.