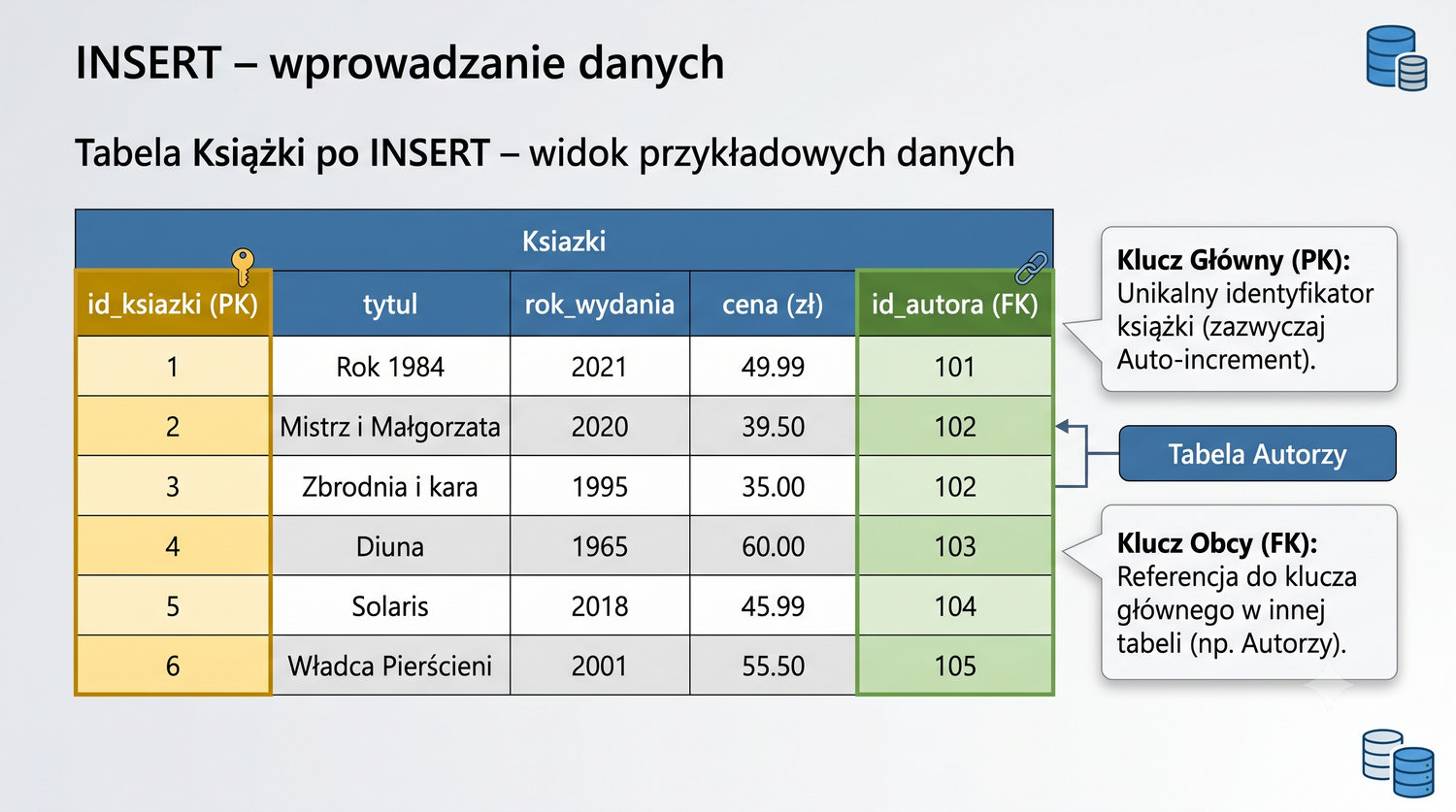
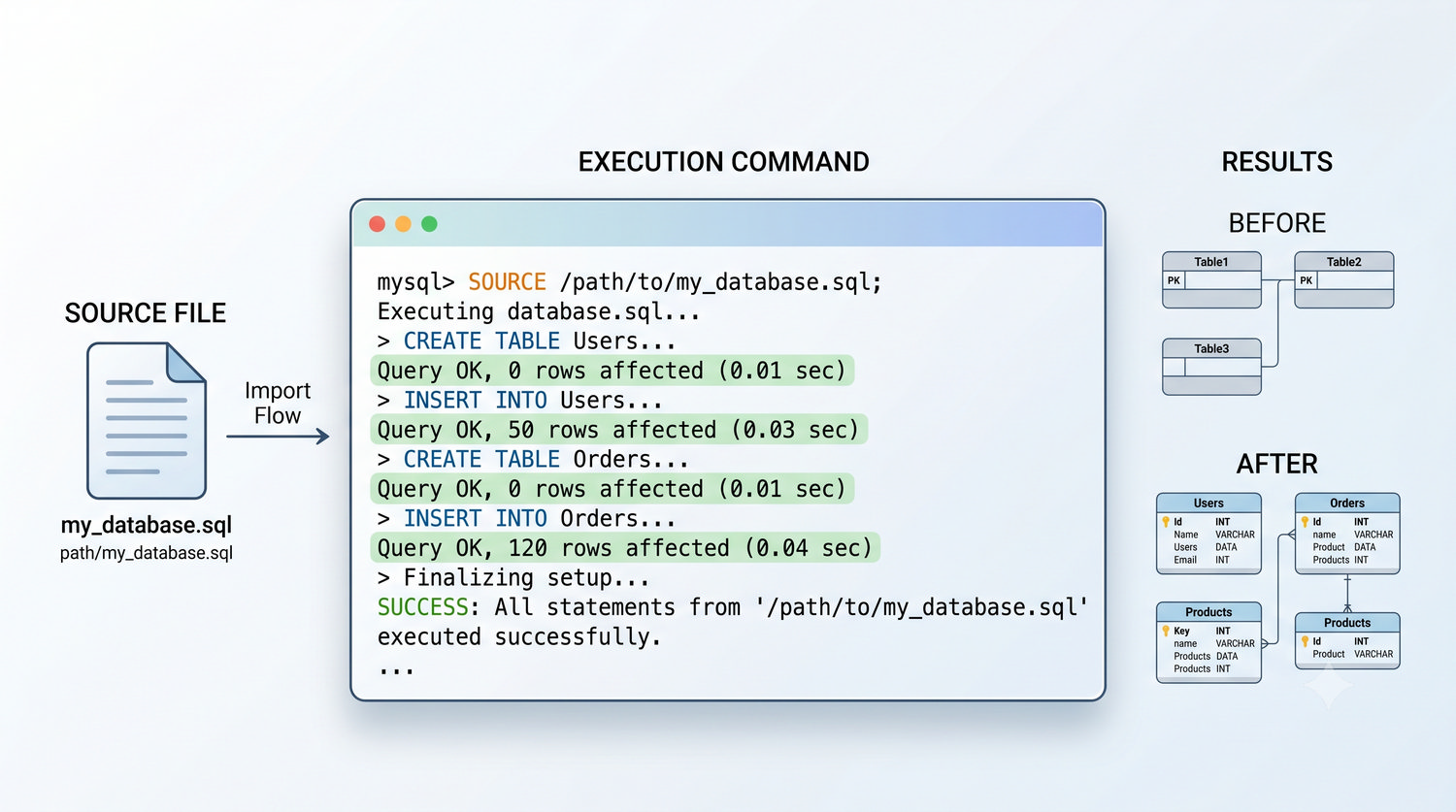
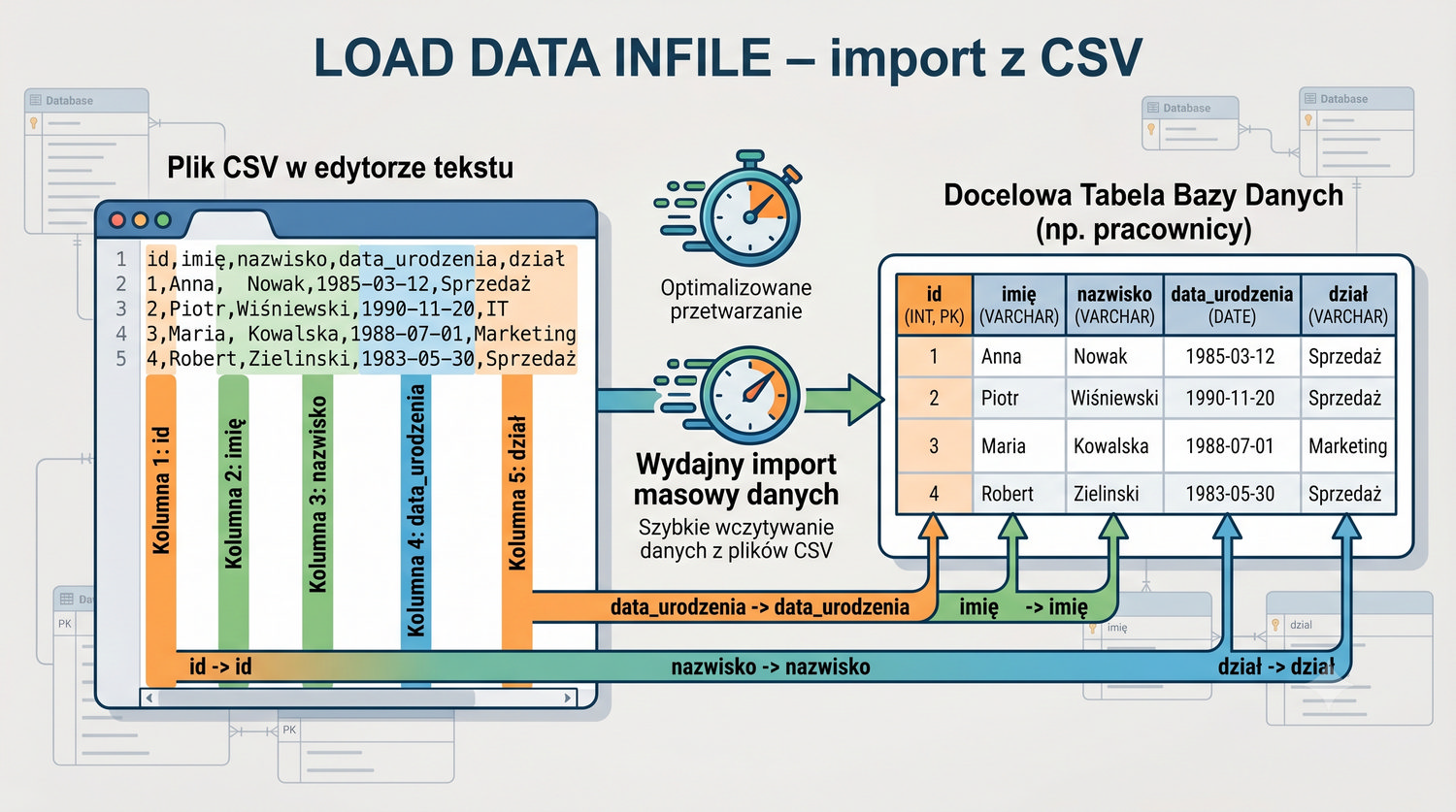
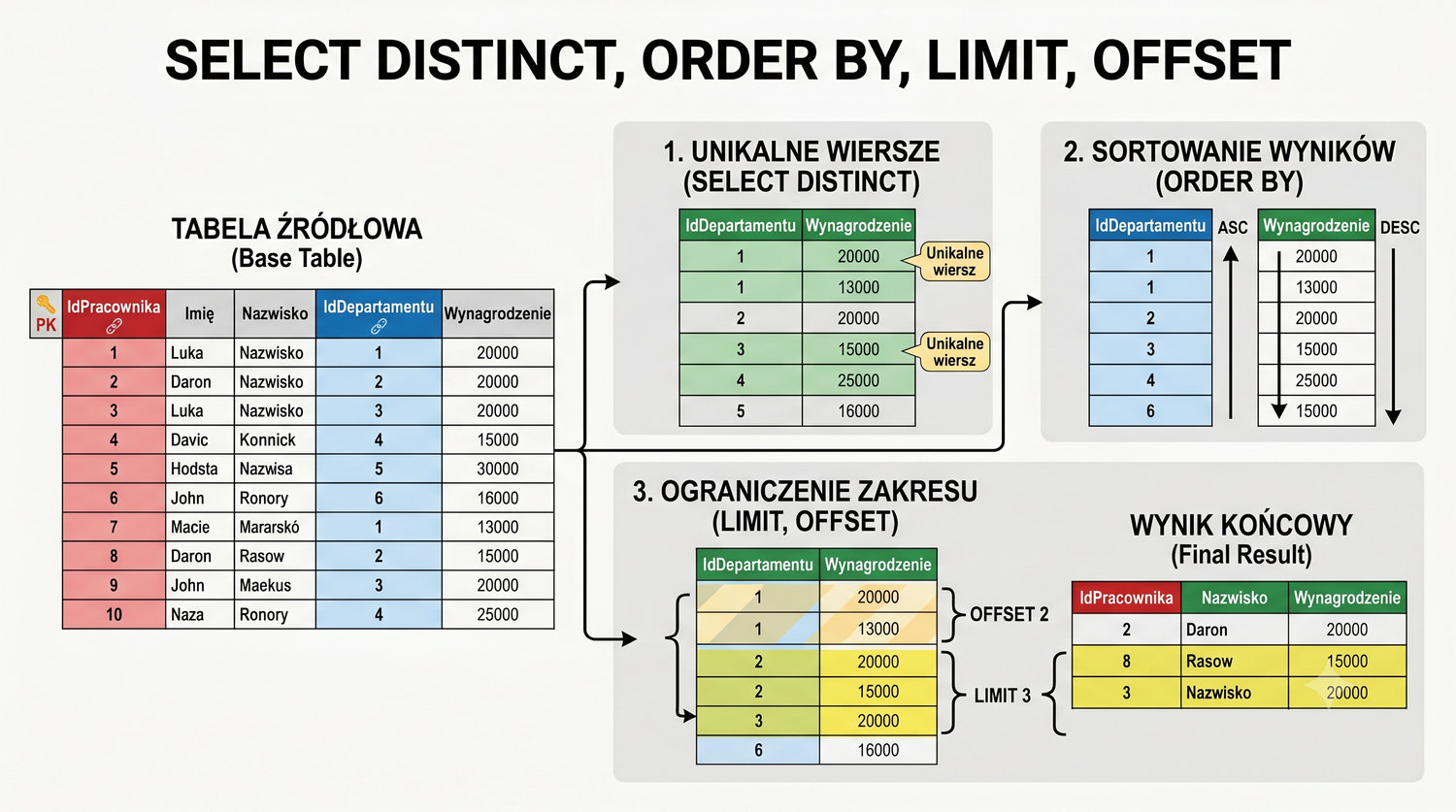
Od uruchomienia serwera po zaawansowane zapytania – kompletny kurs SQL
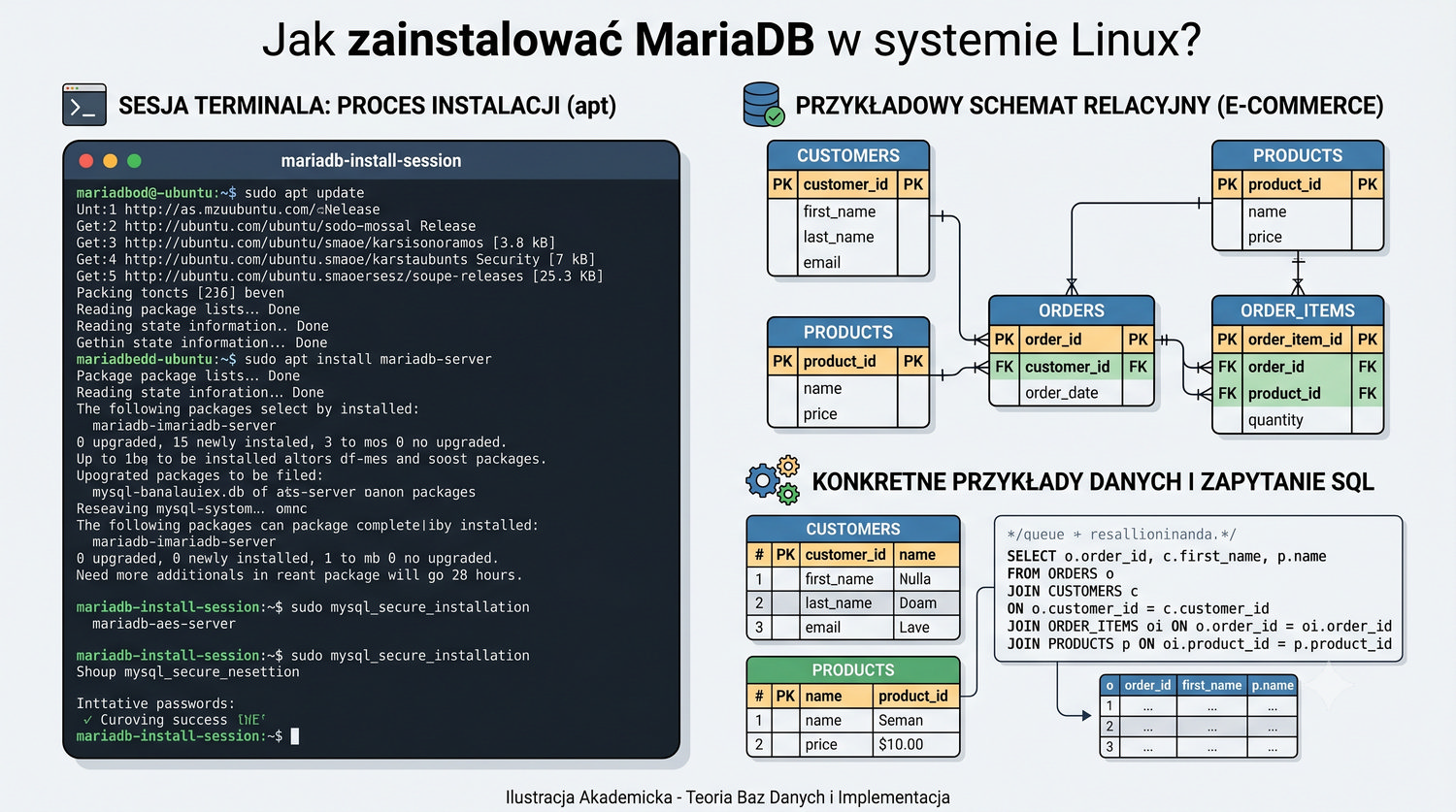
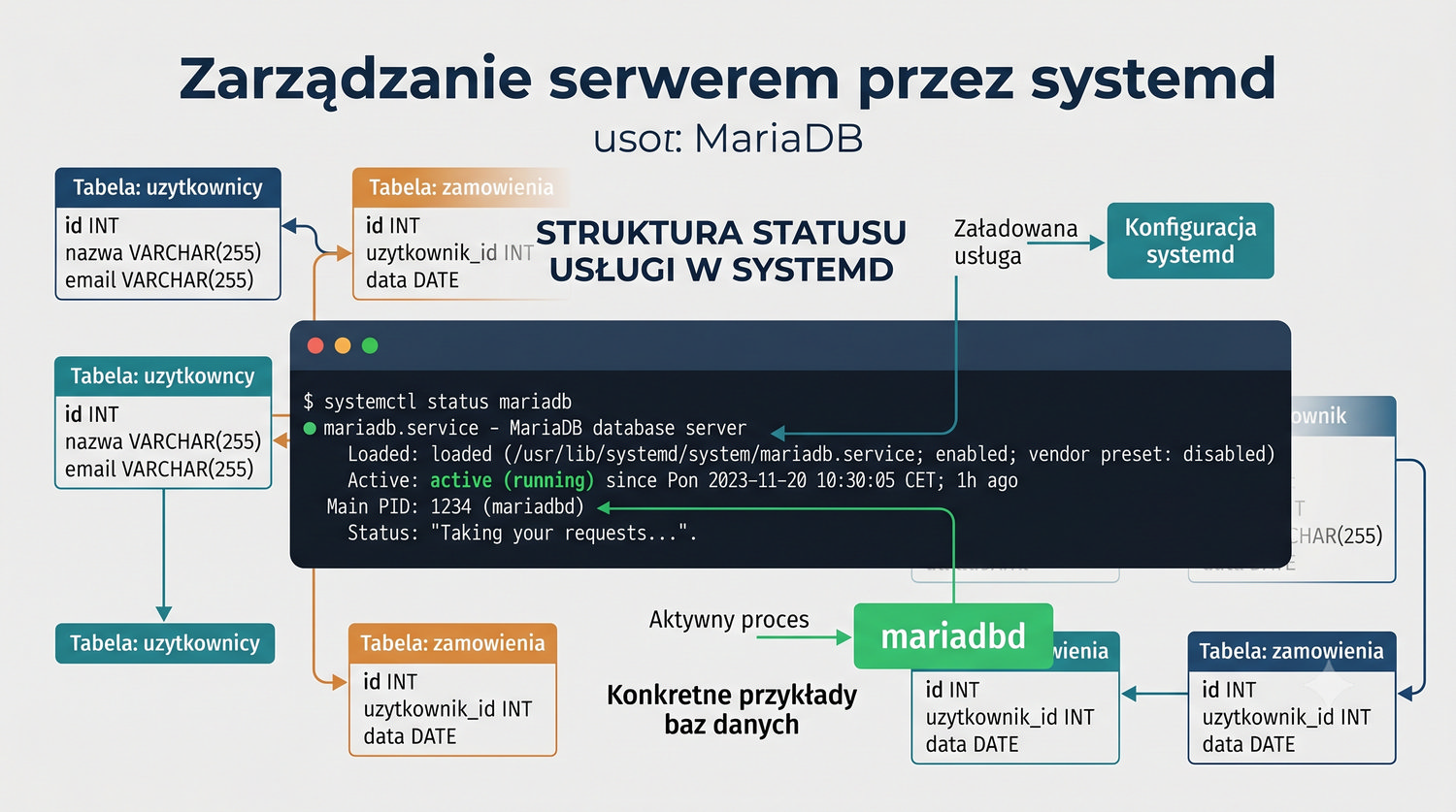
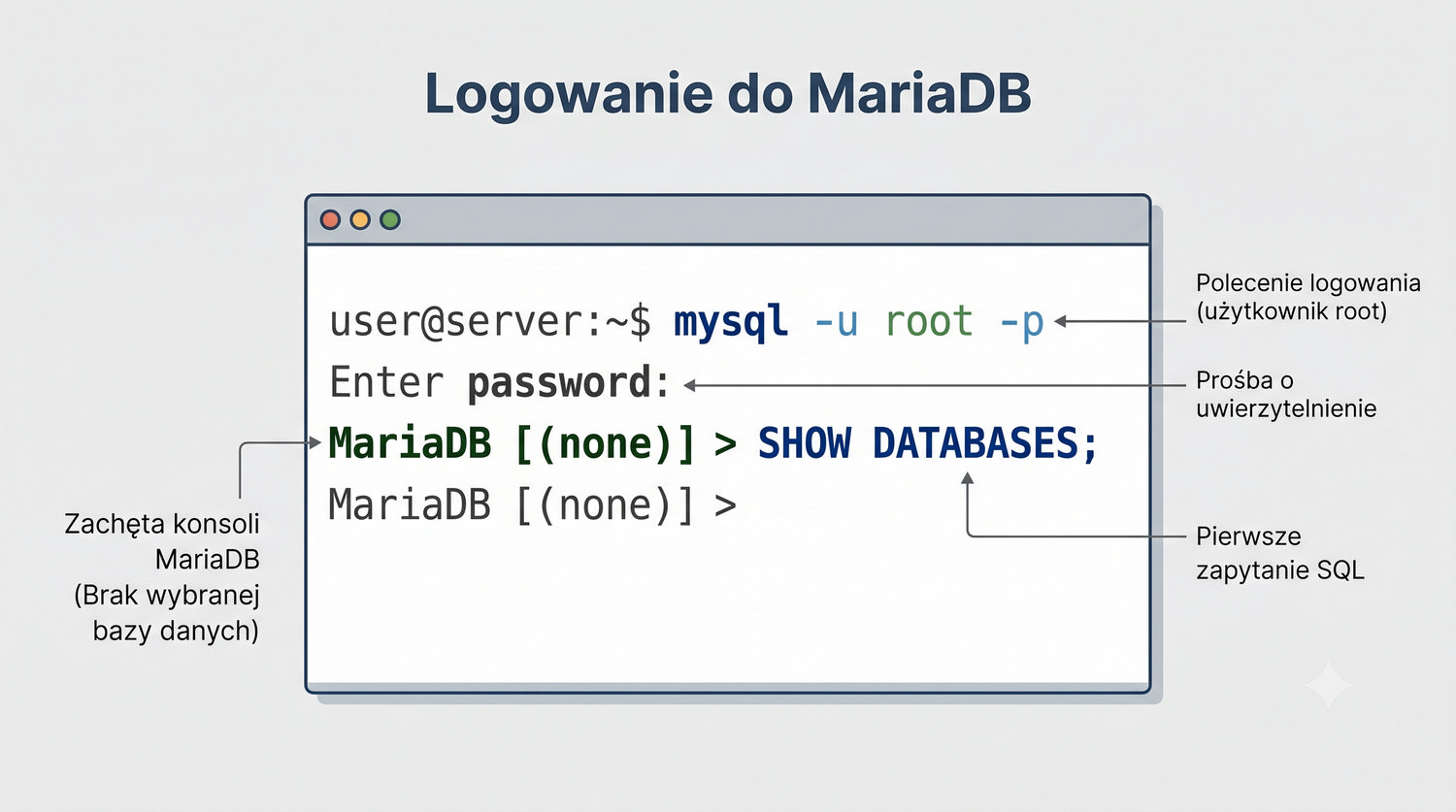
Zakładamy zerowy poziom wiedzy o MariaDB – zaczniemy od instalacji i uruchomienia serwera.
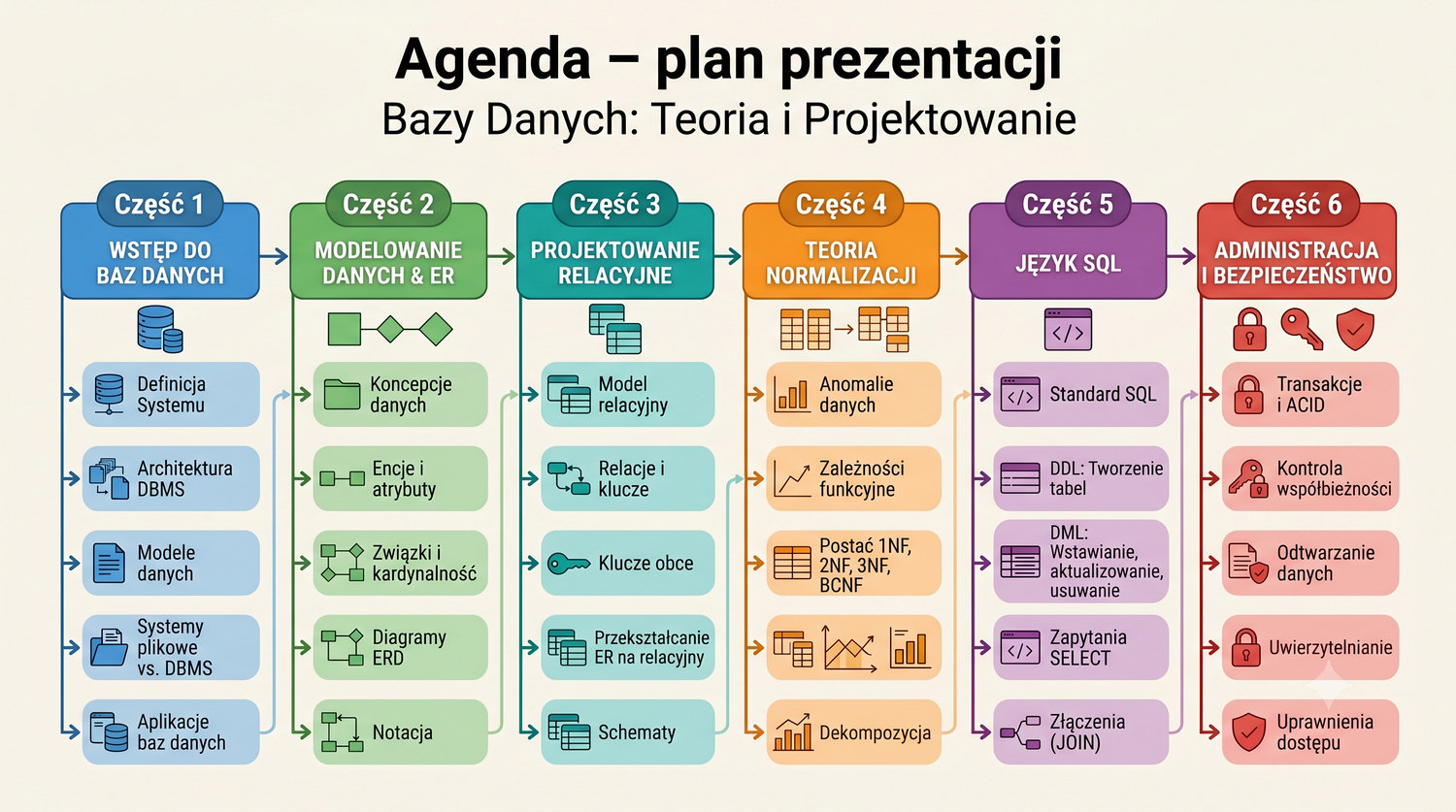
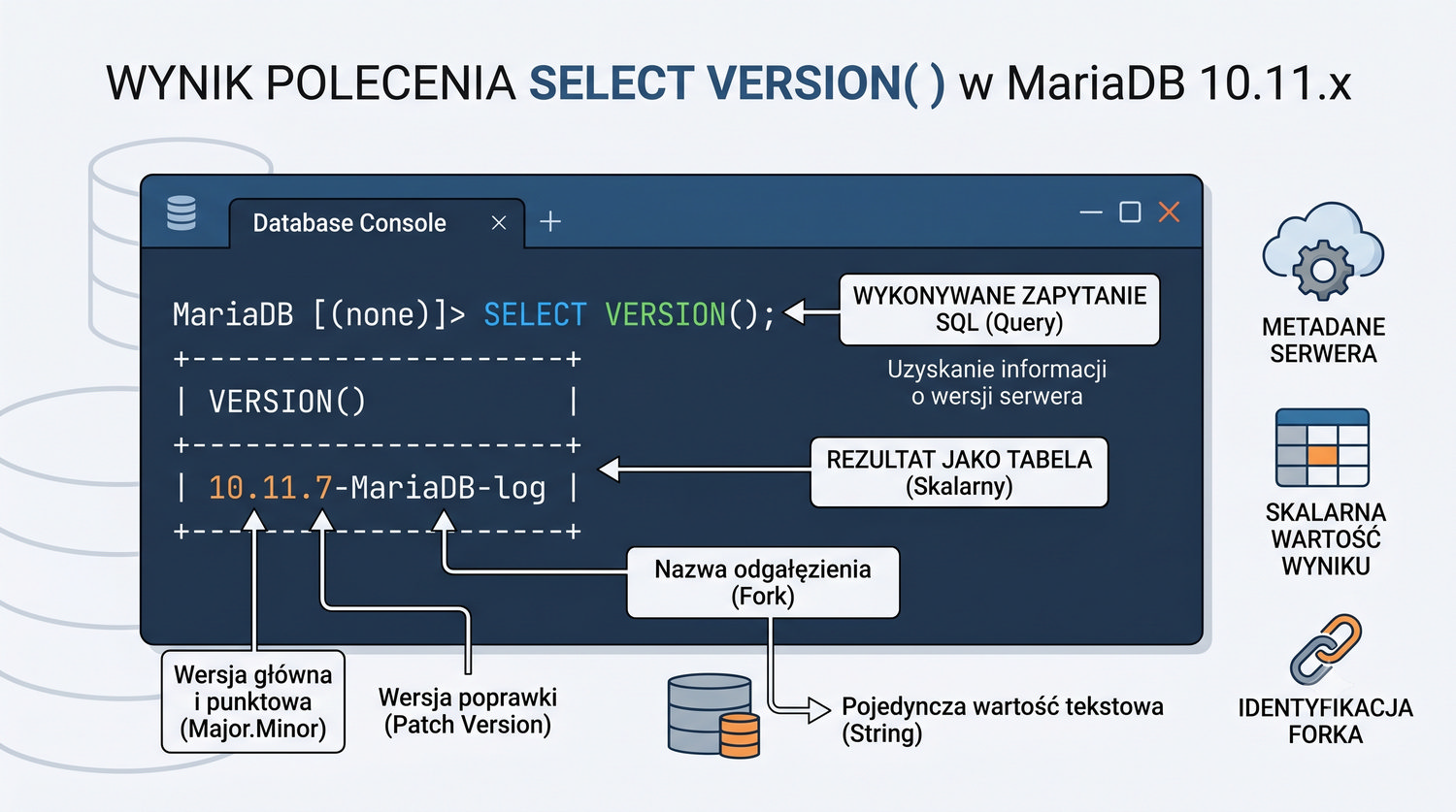
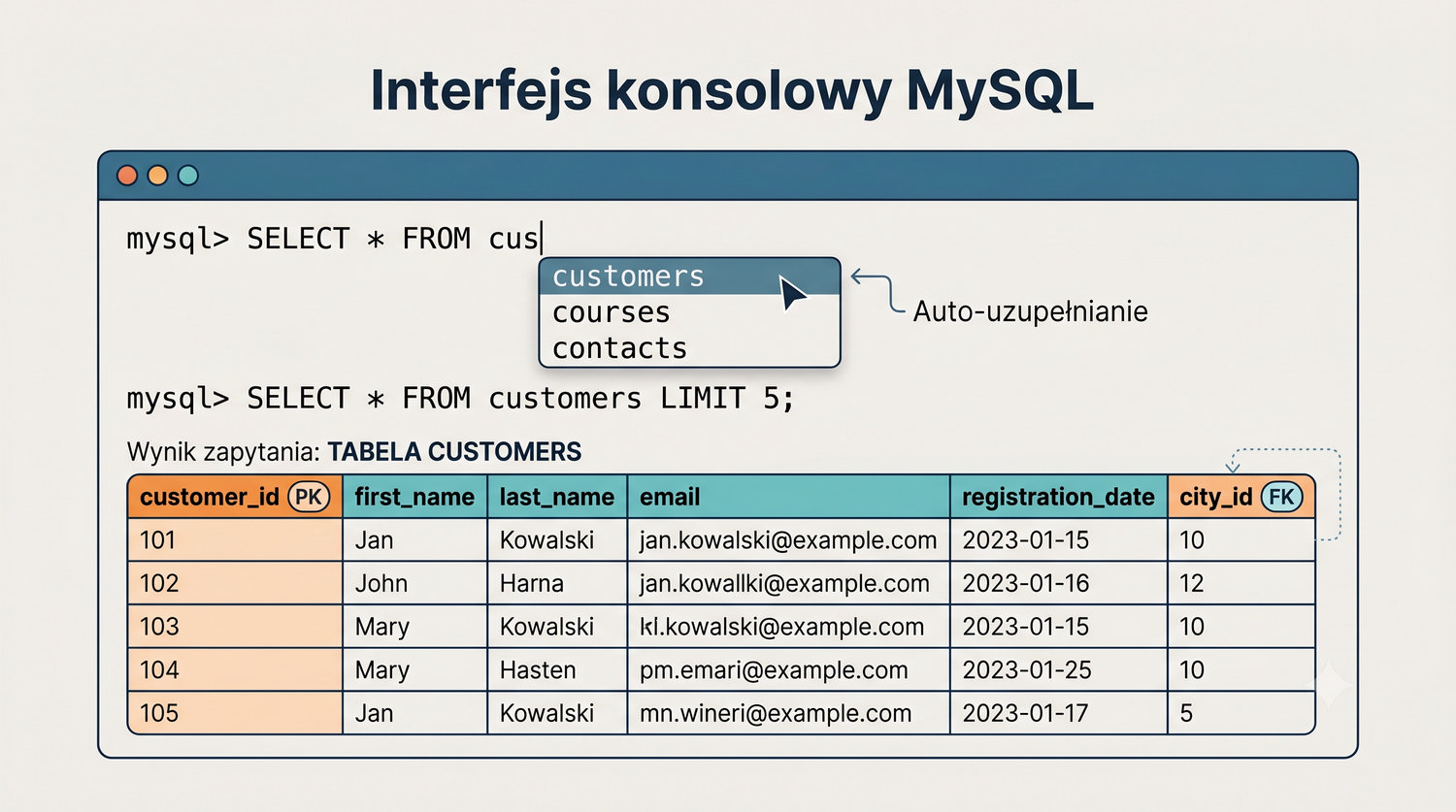
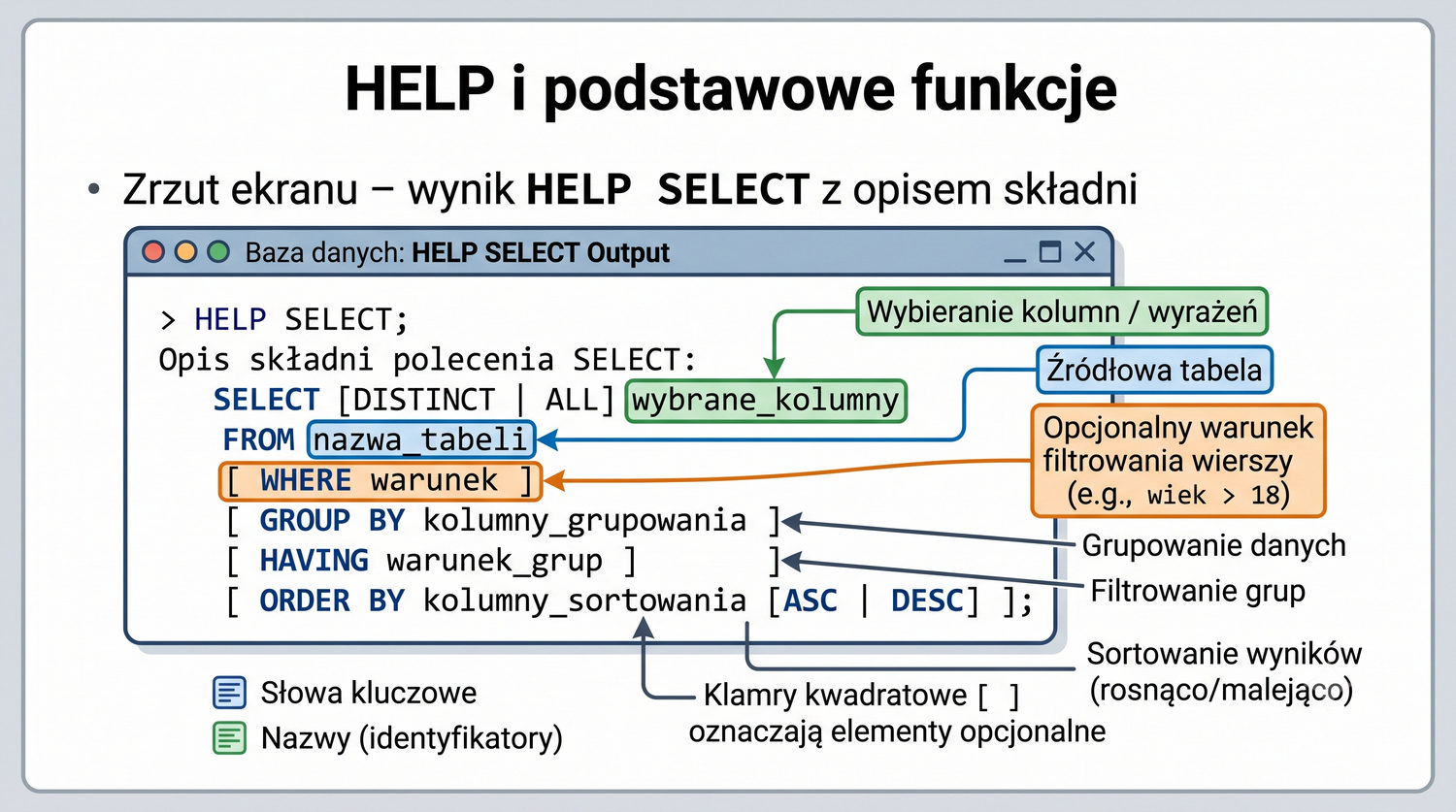
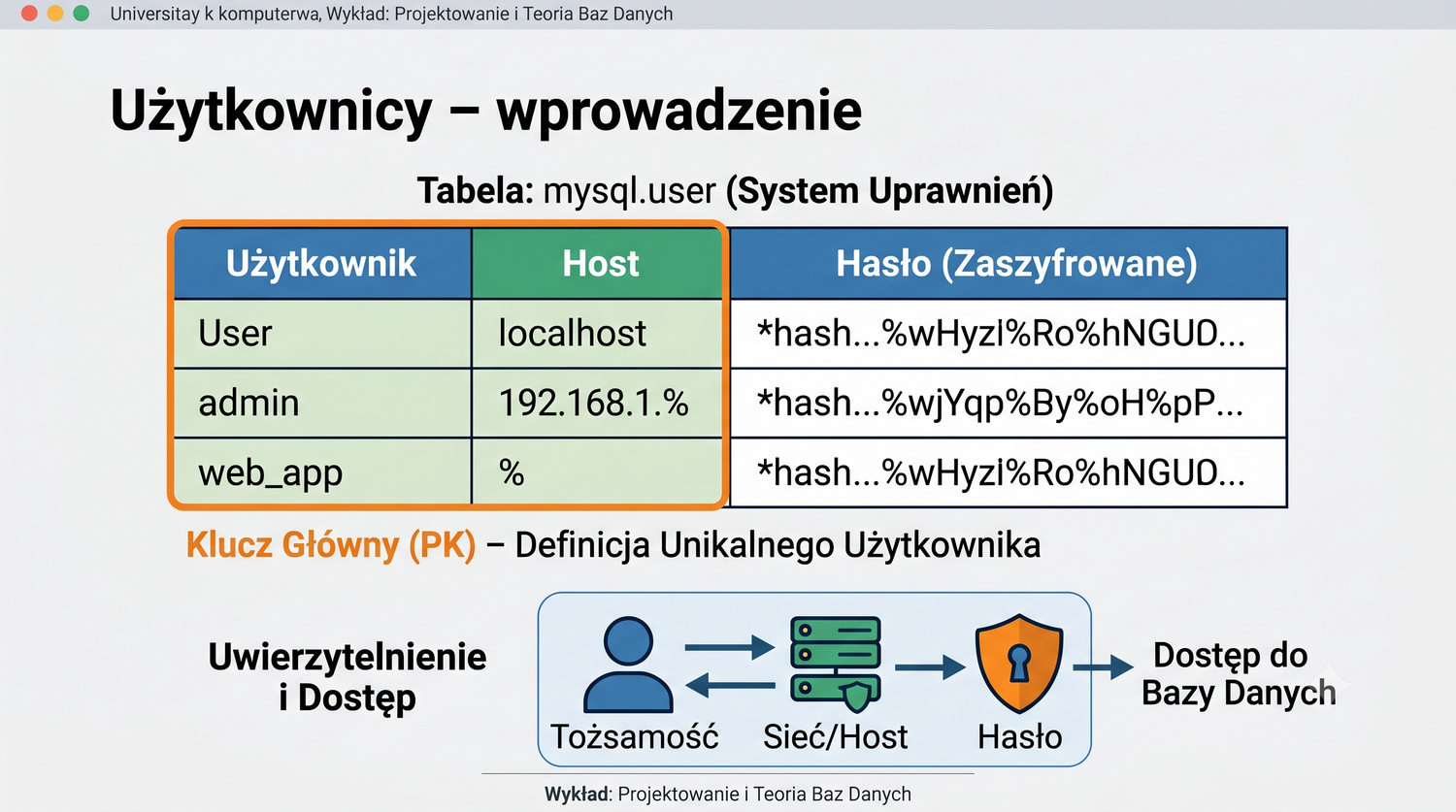
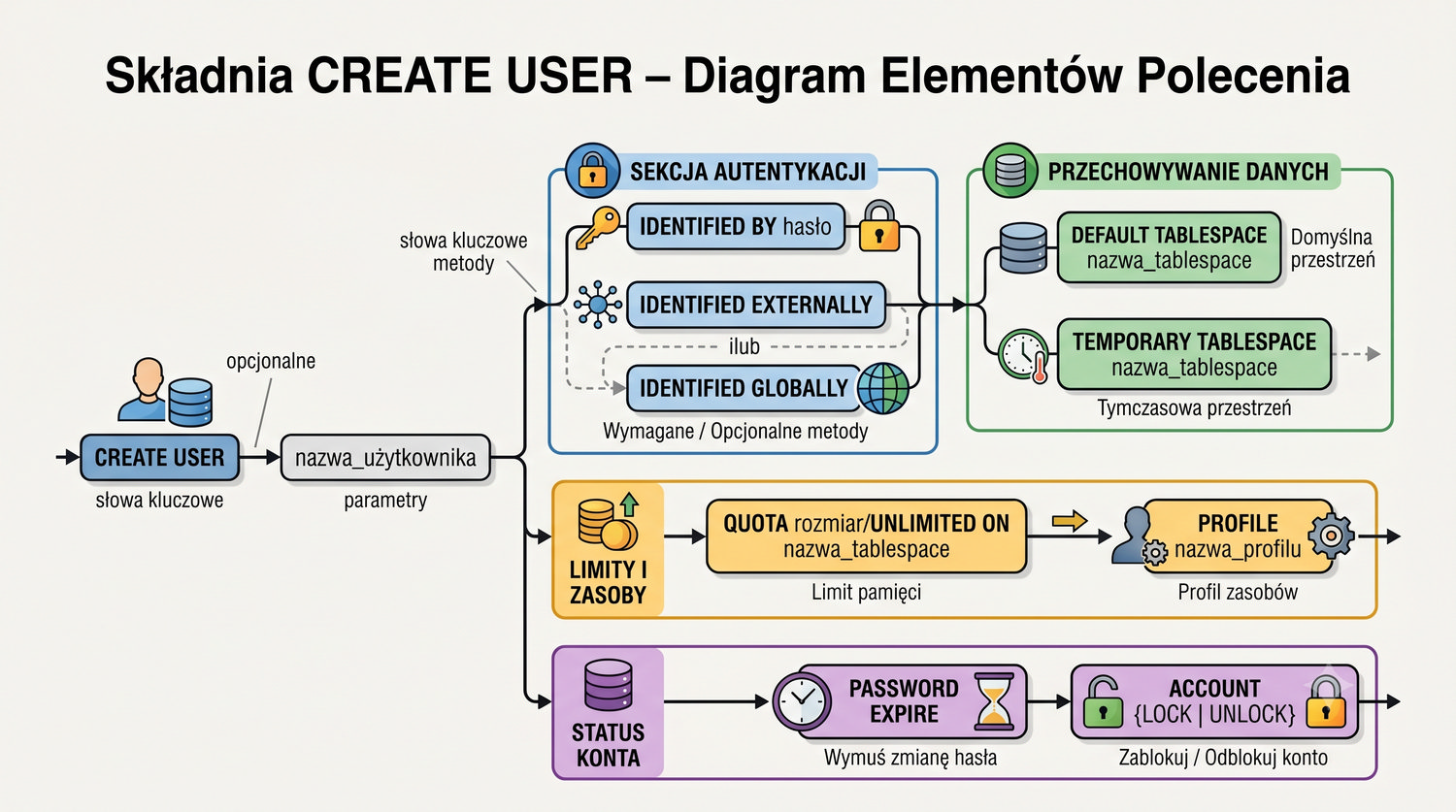
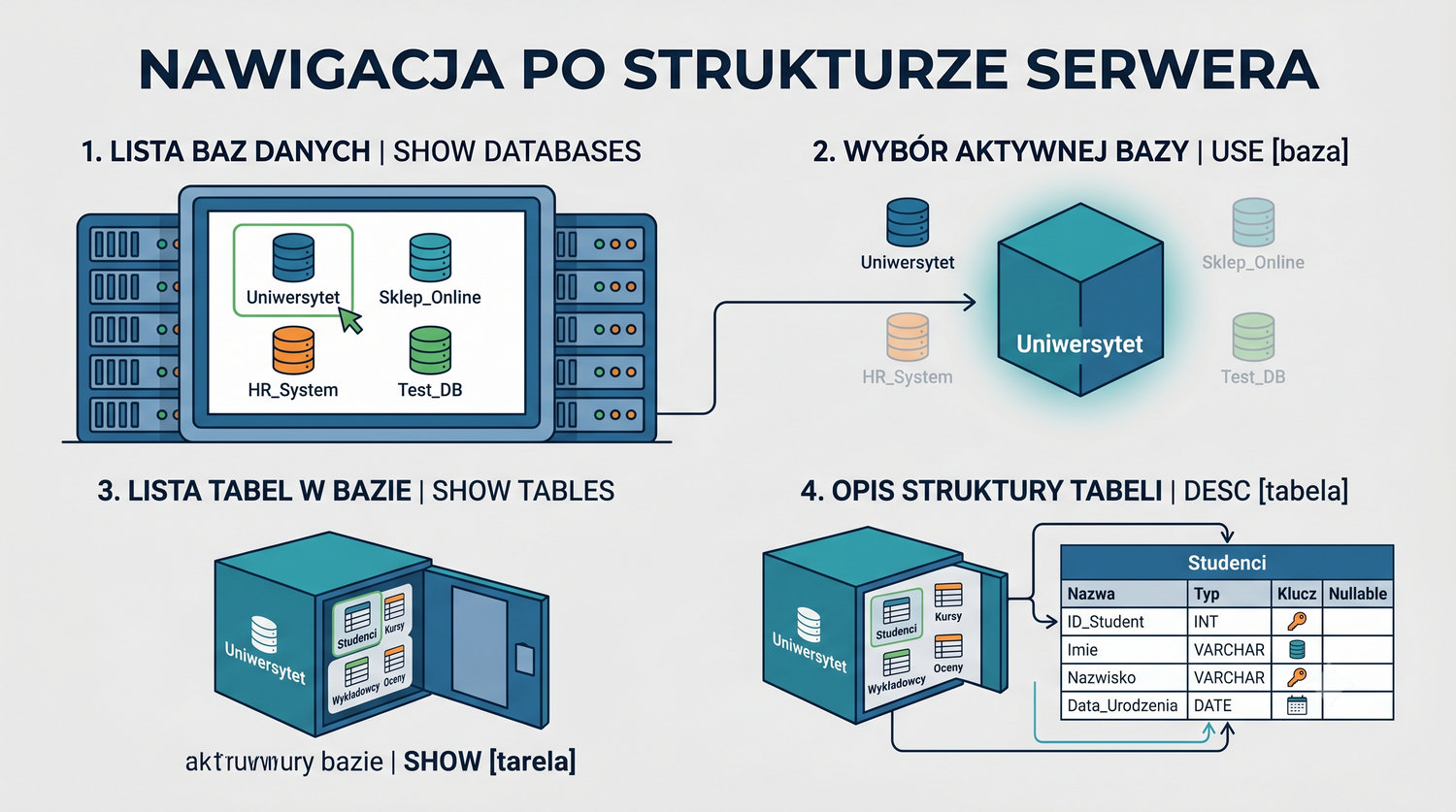
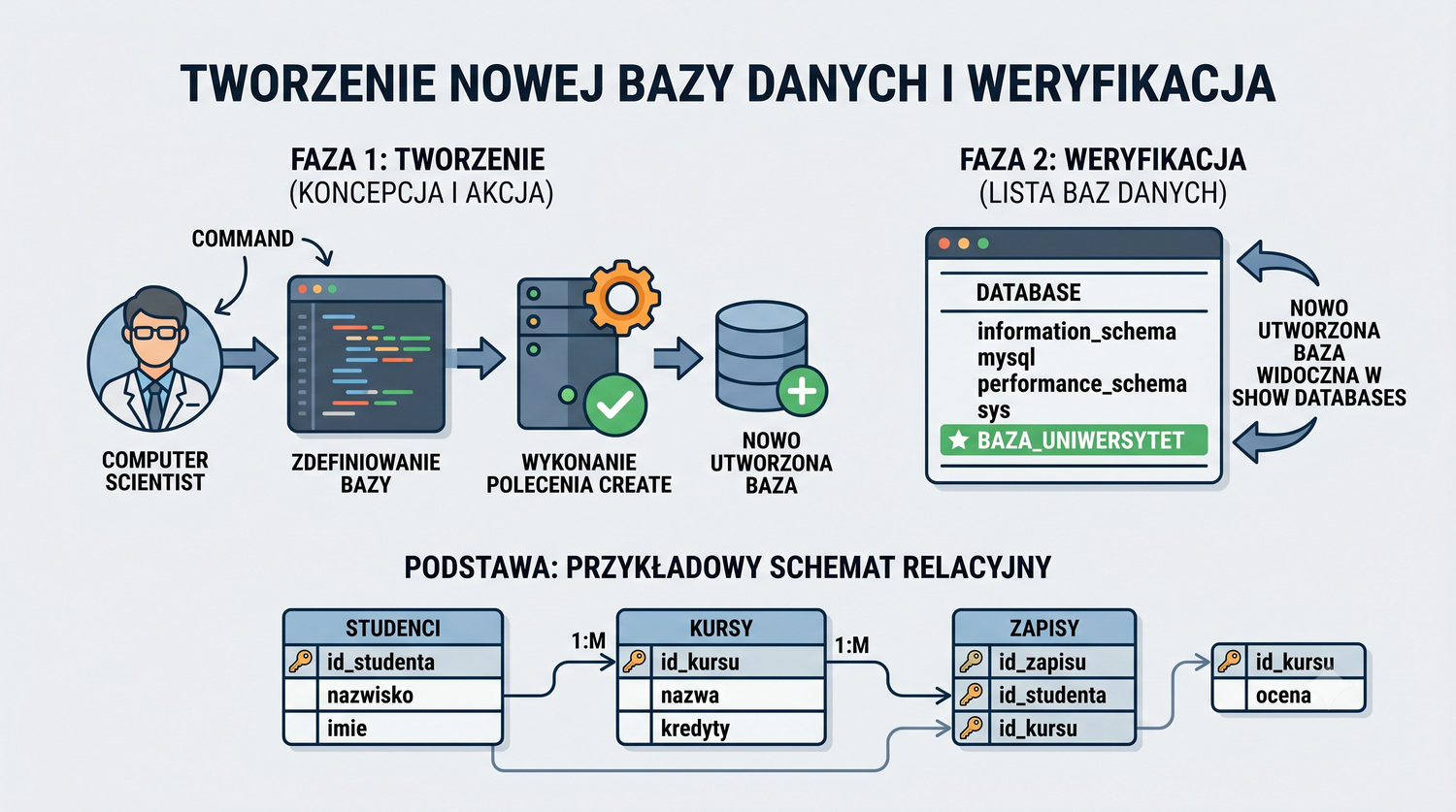
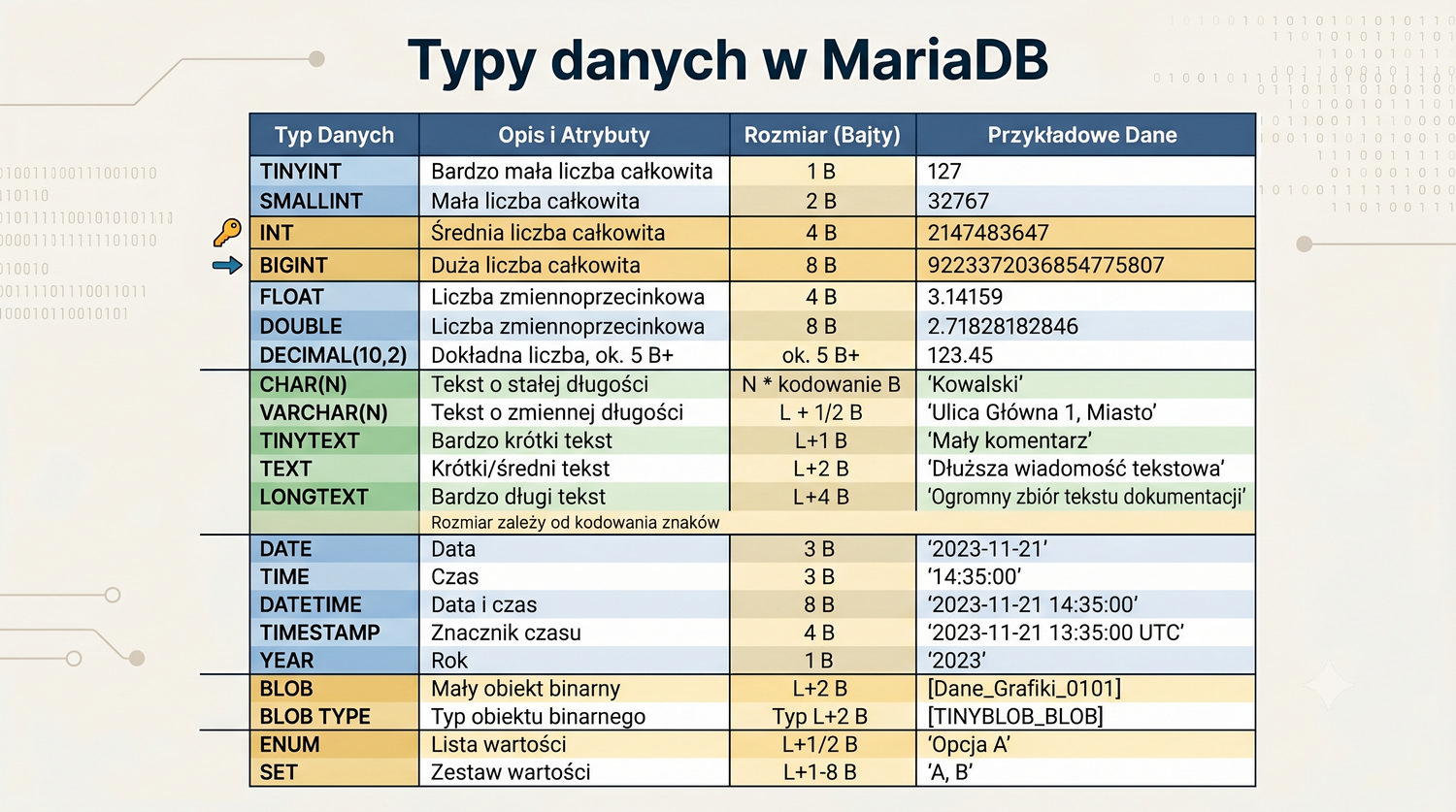
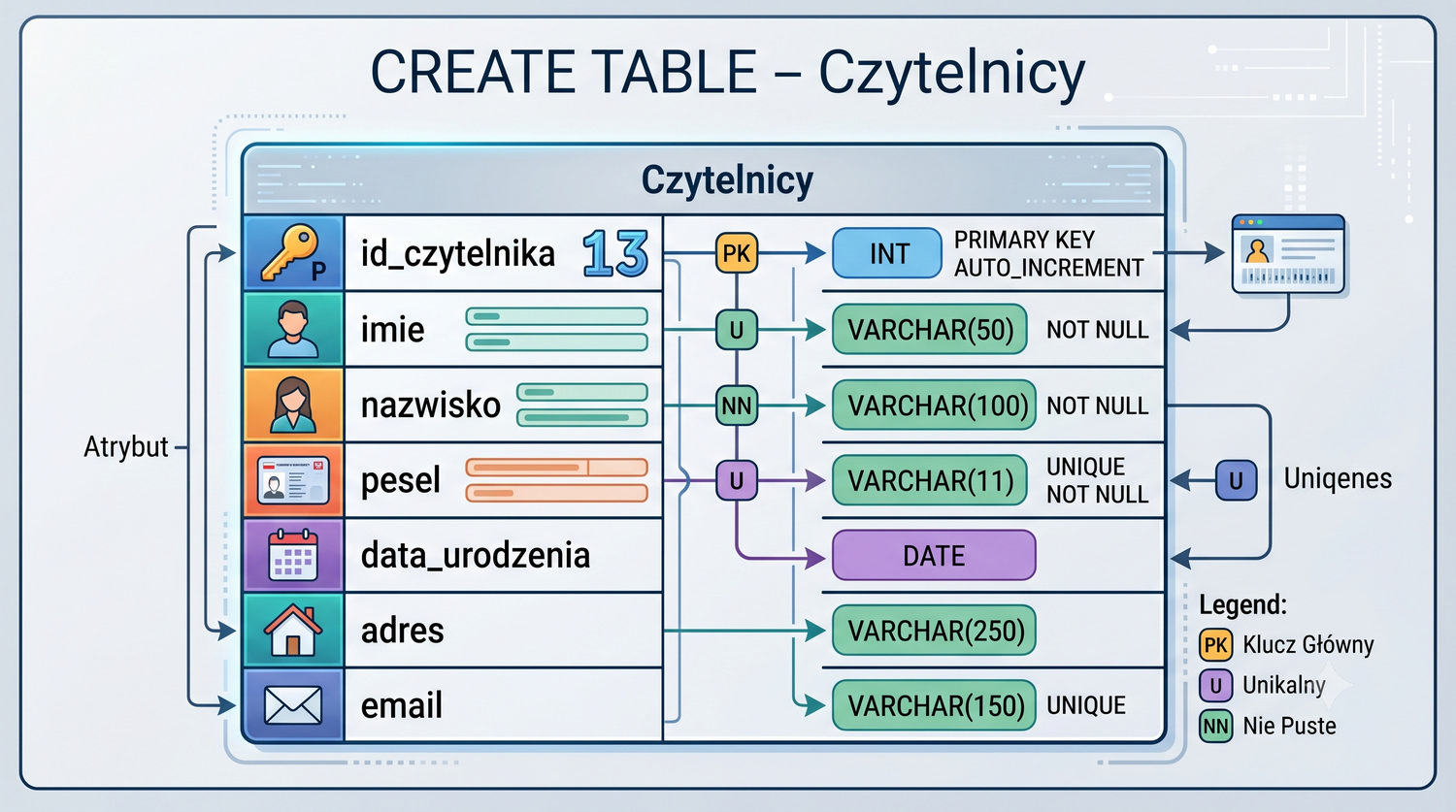
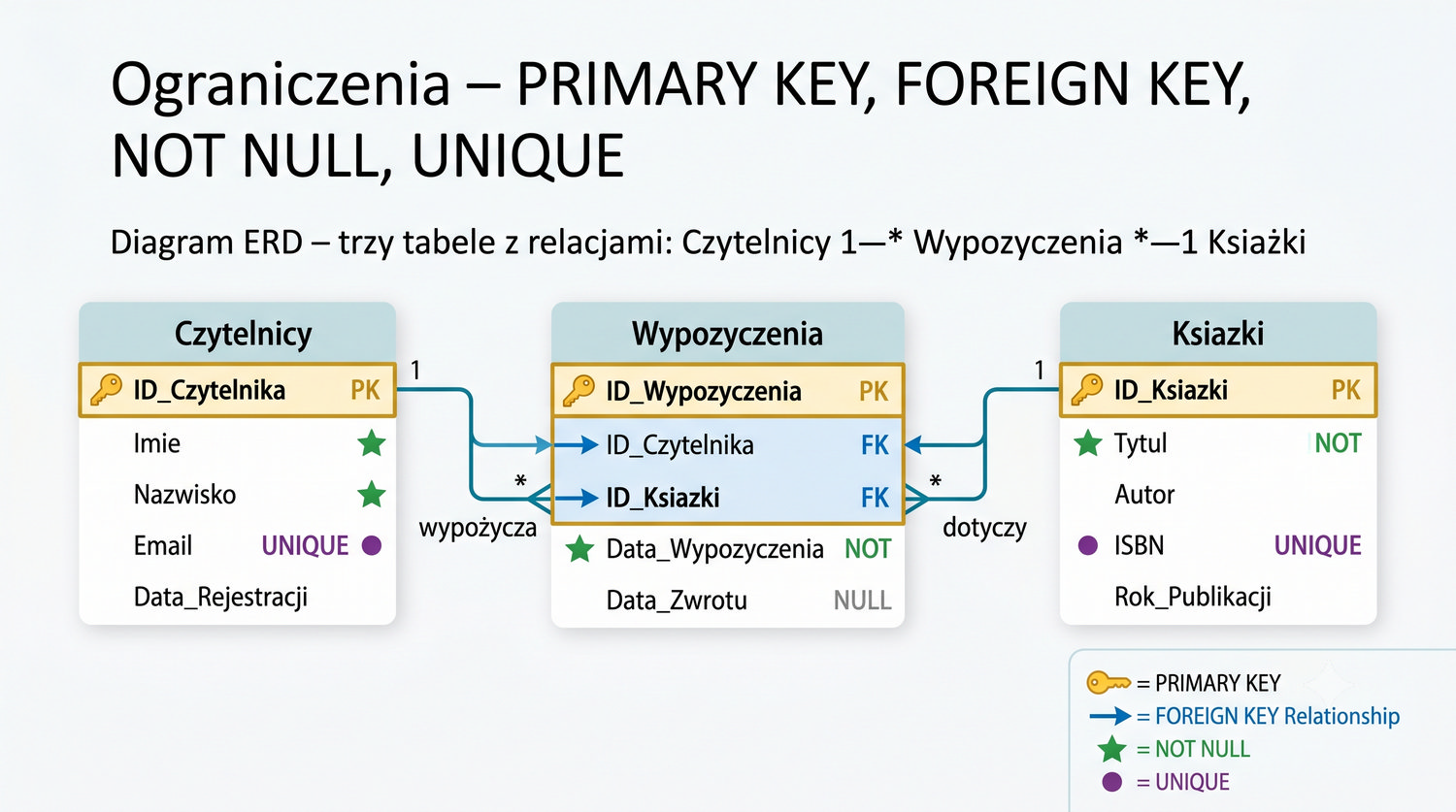
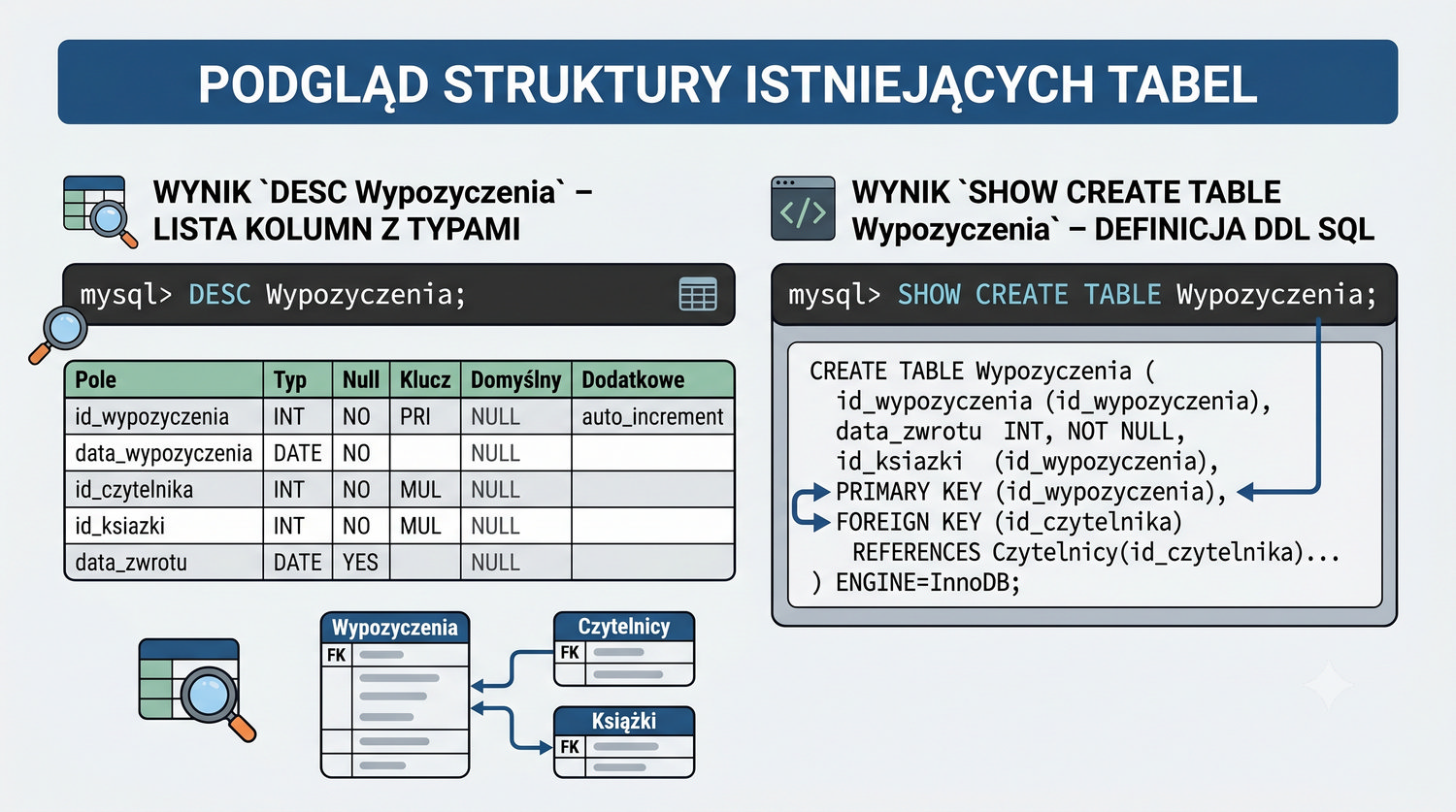
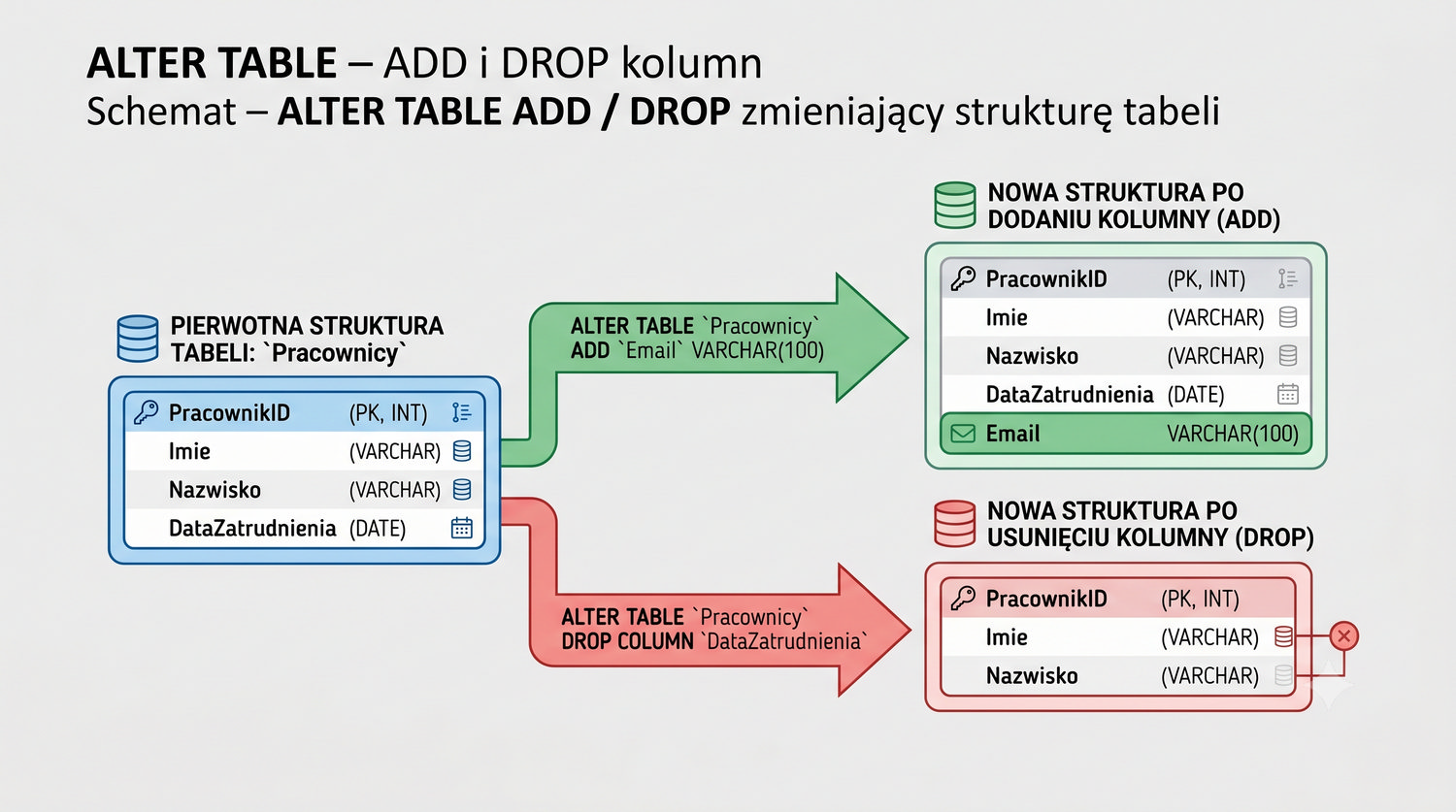
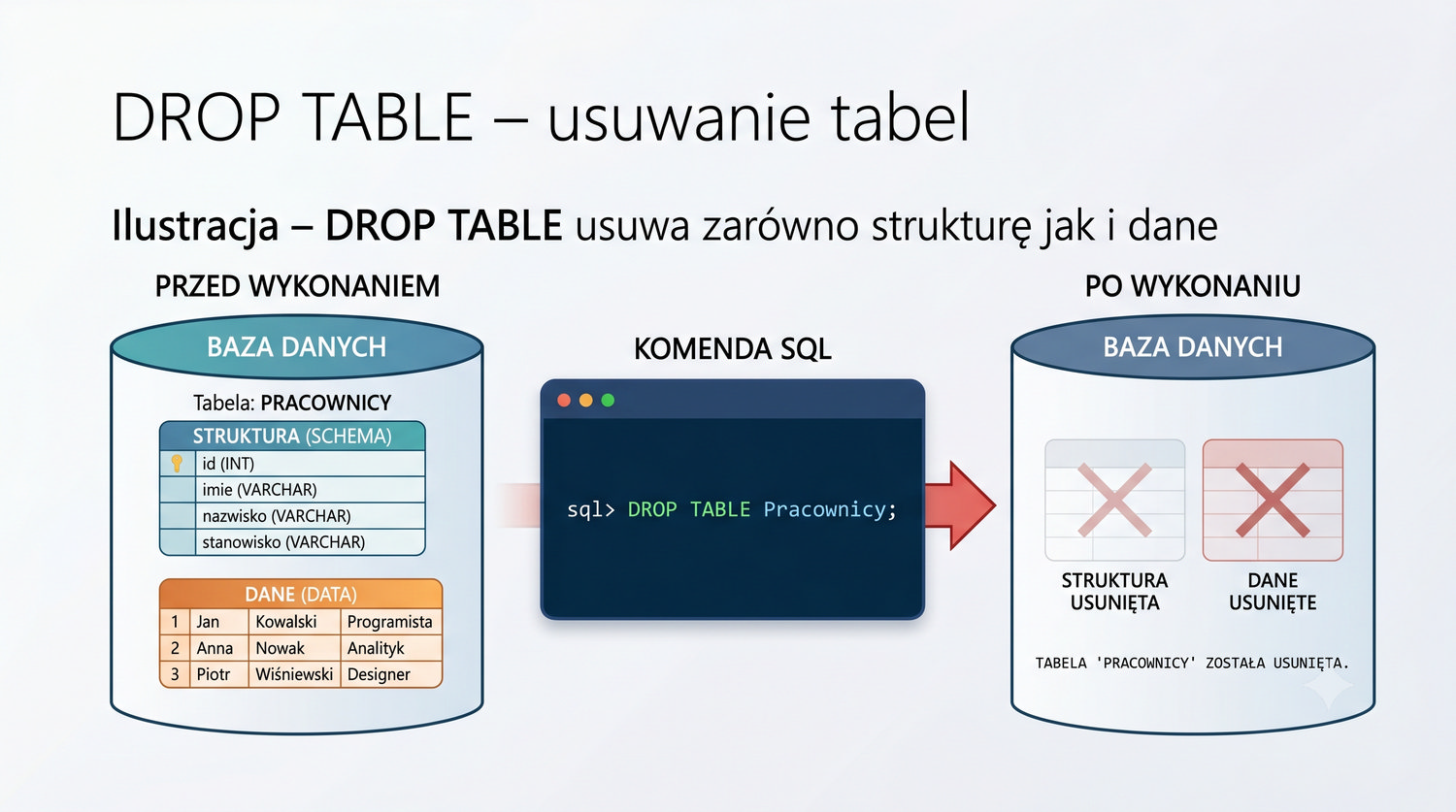
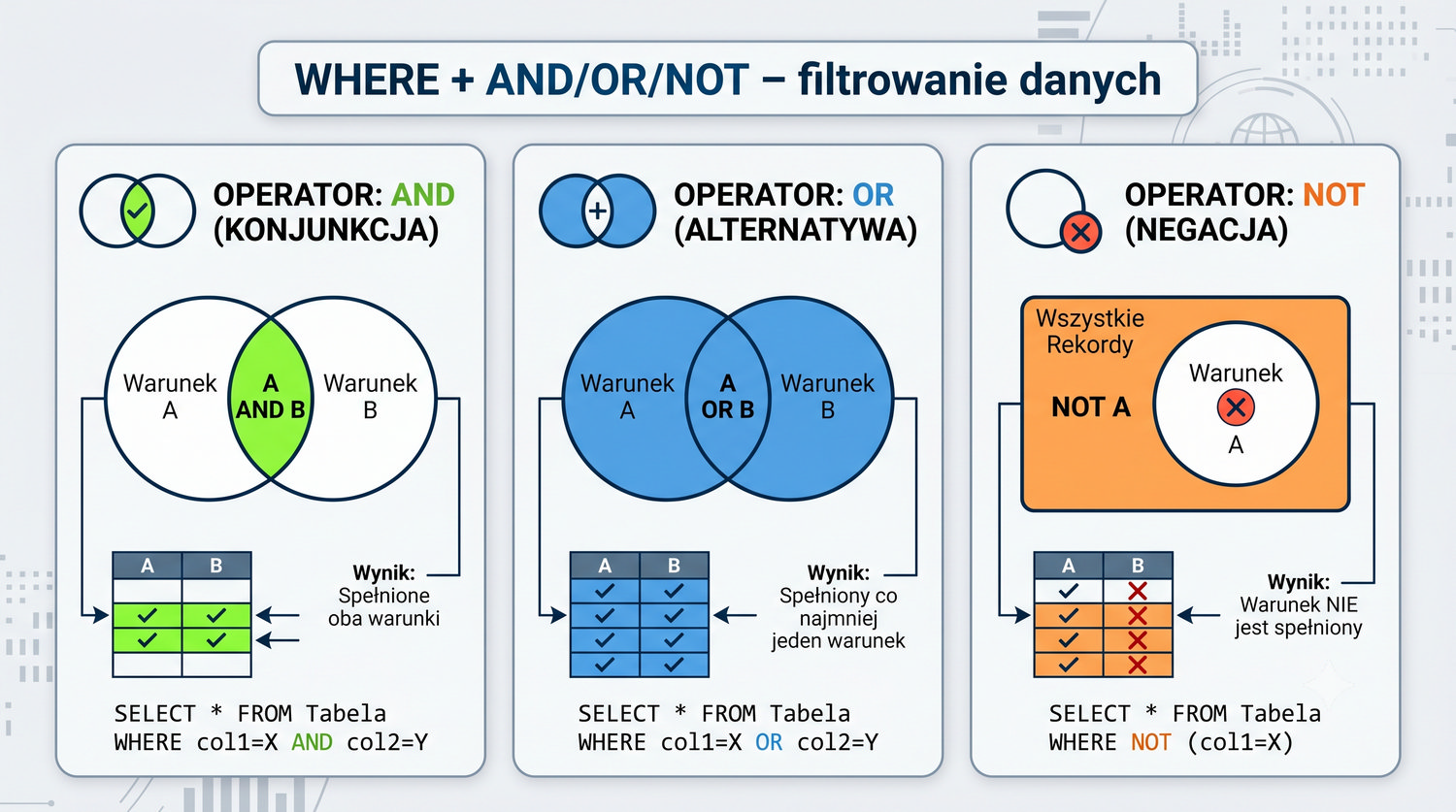
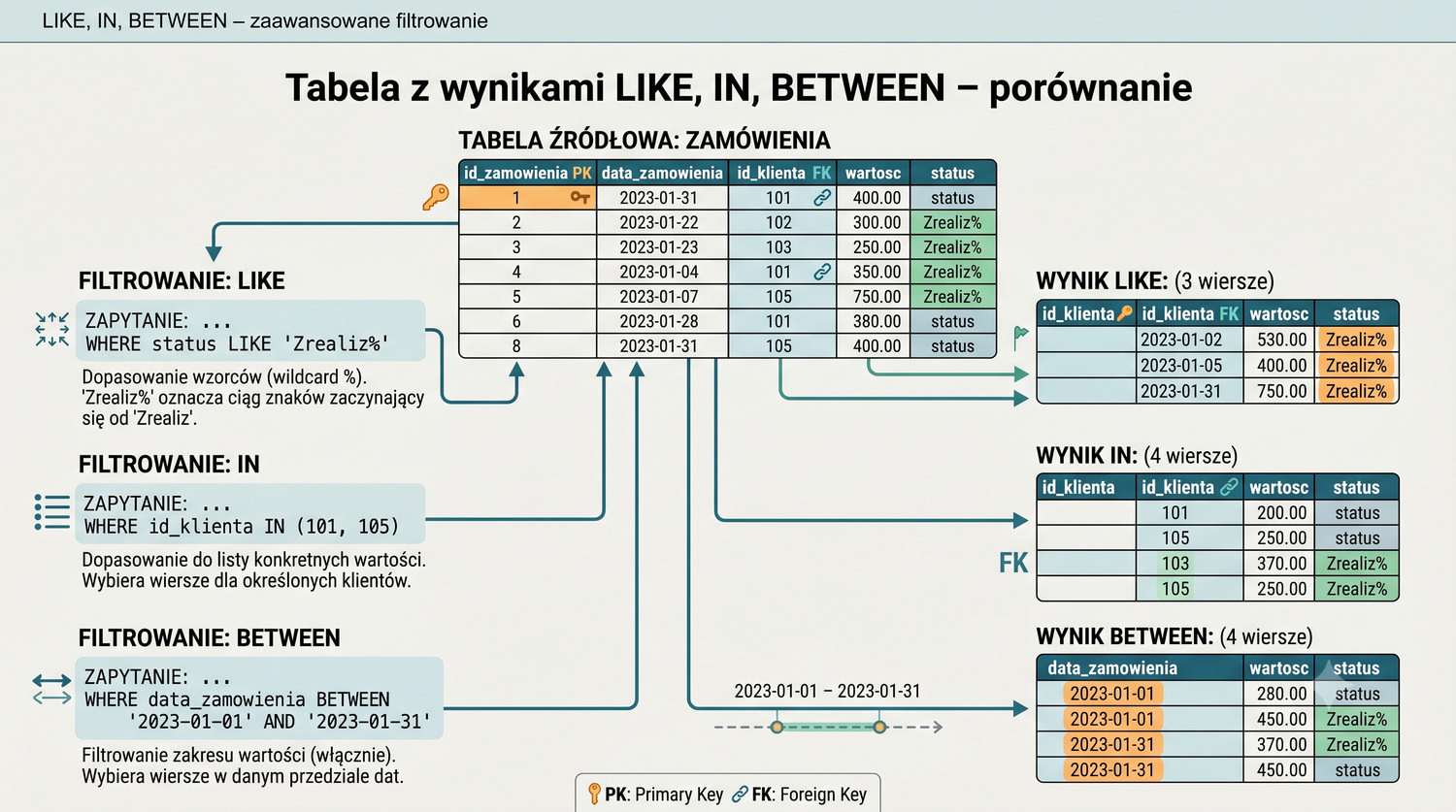
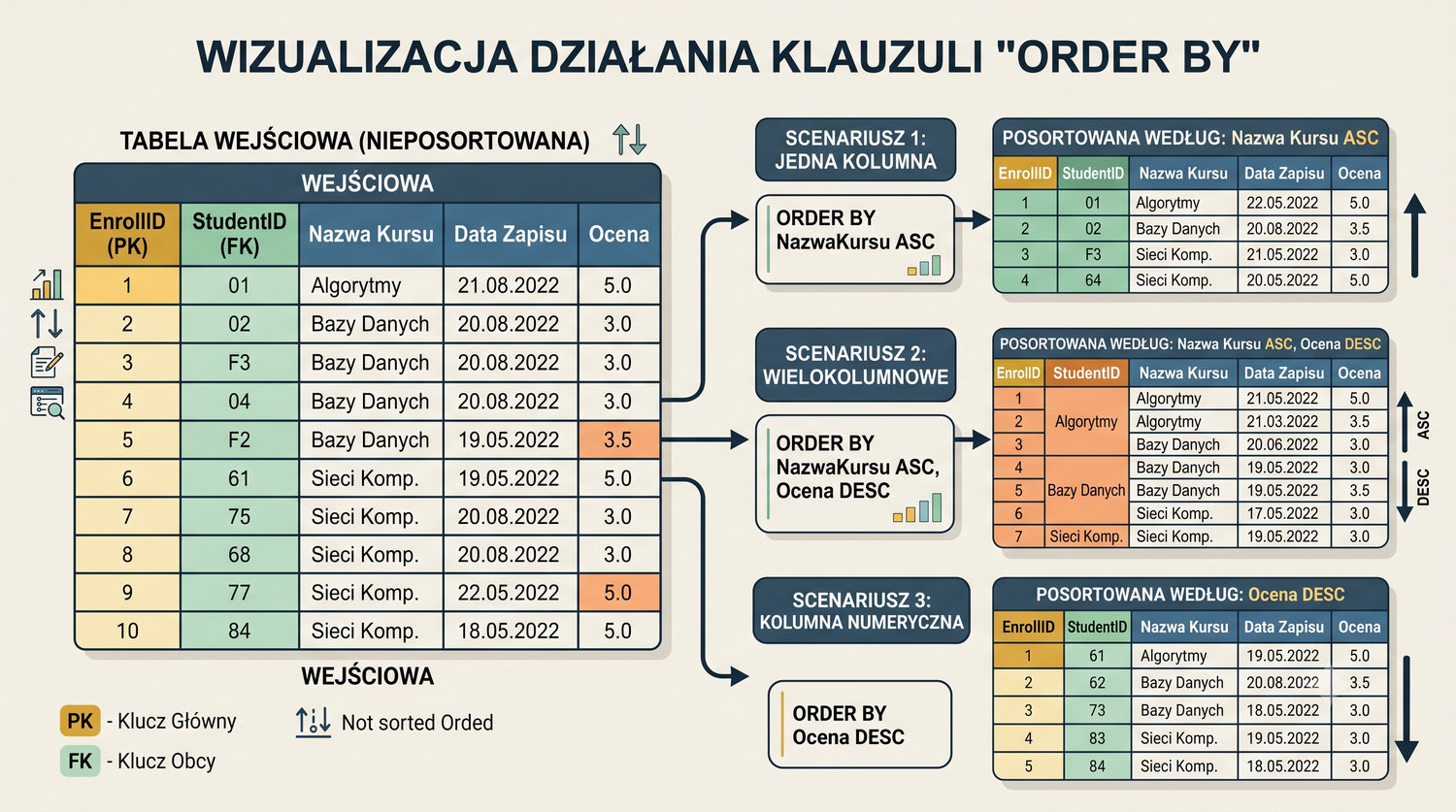
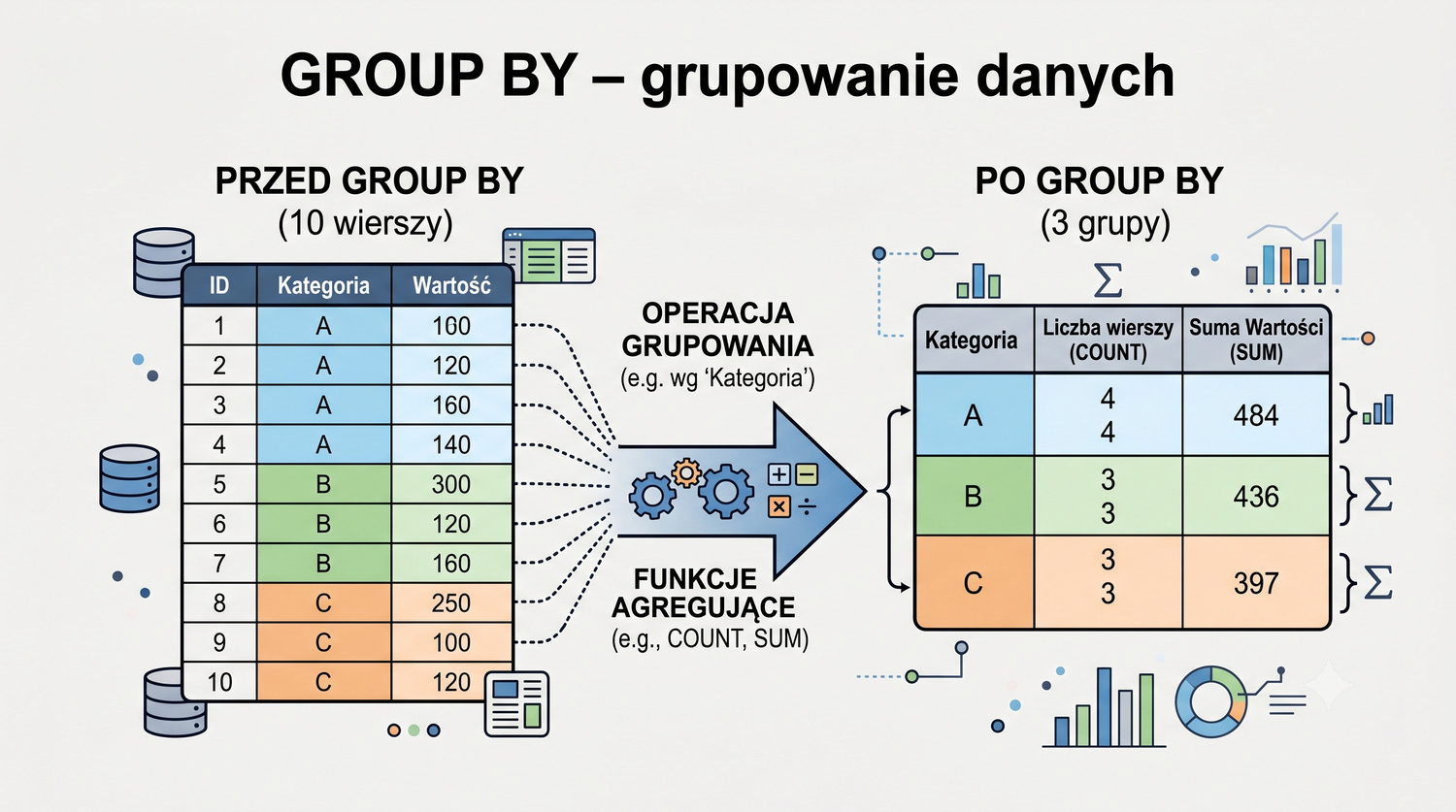
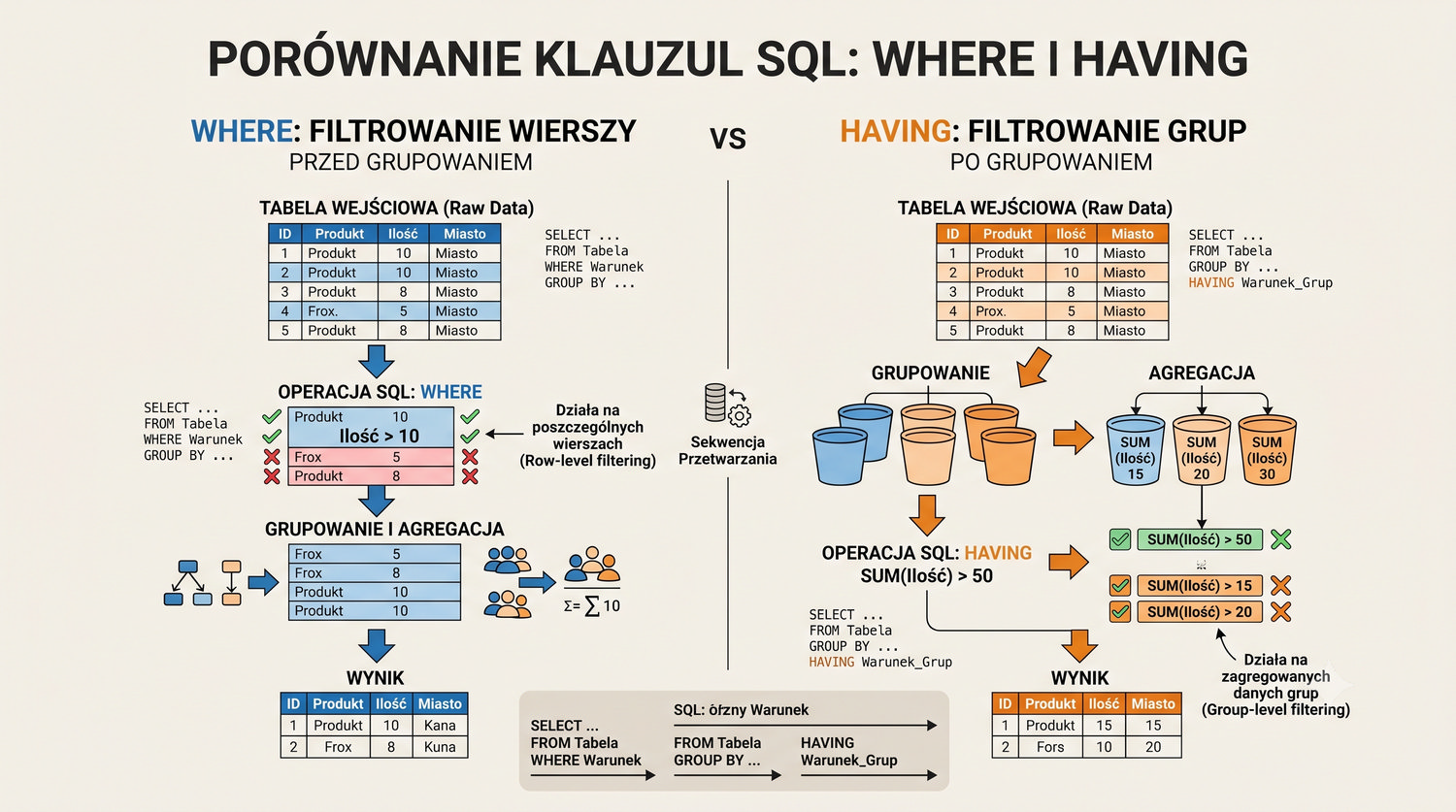
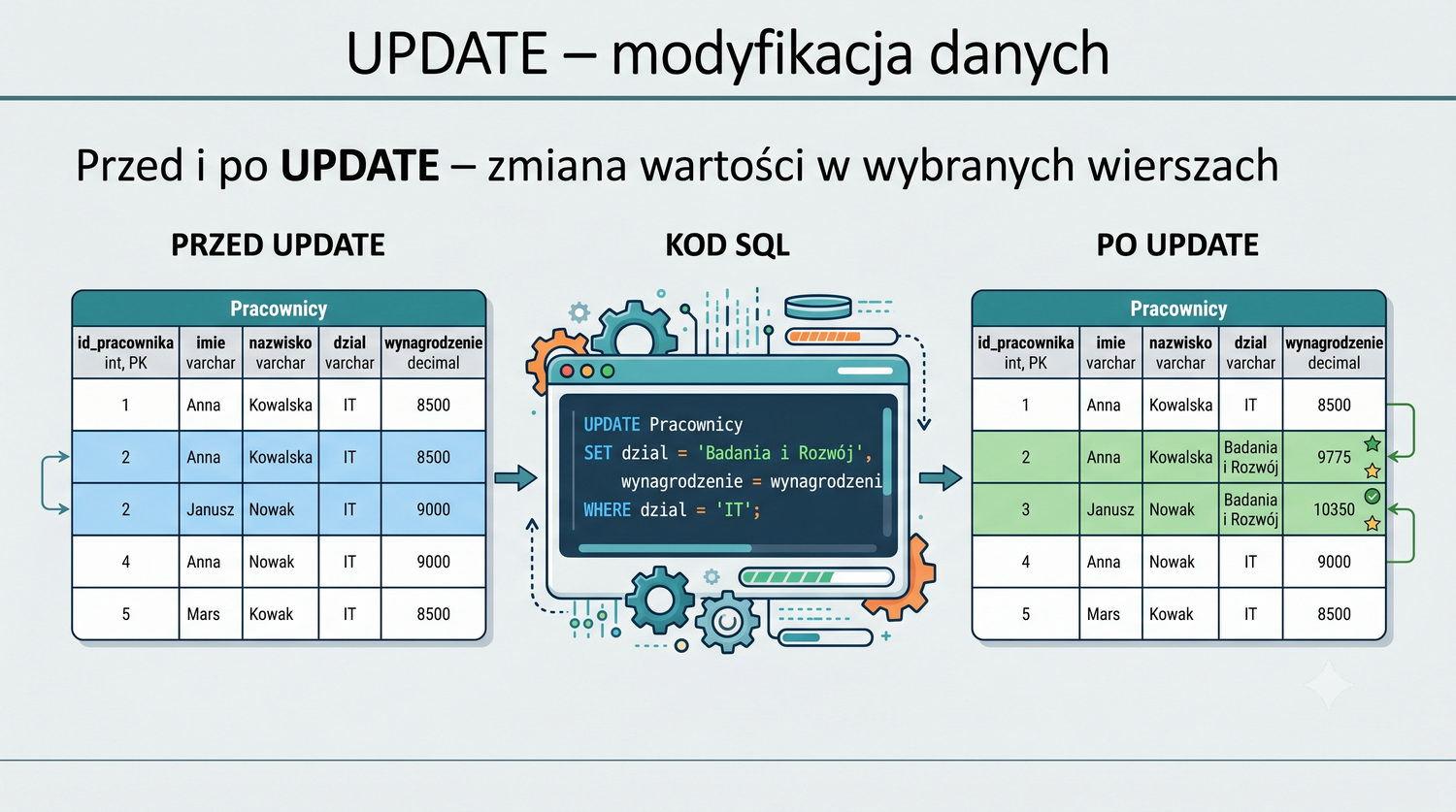
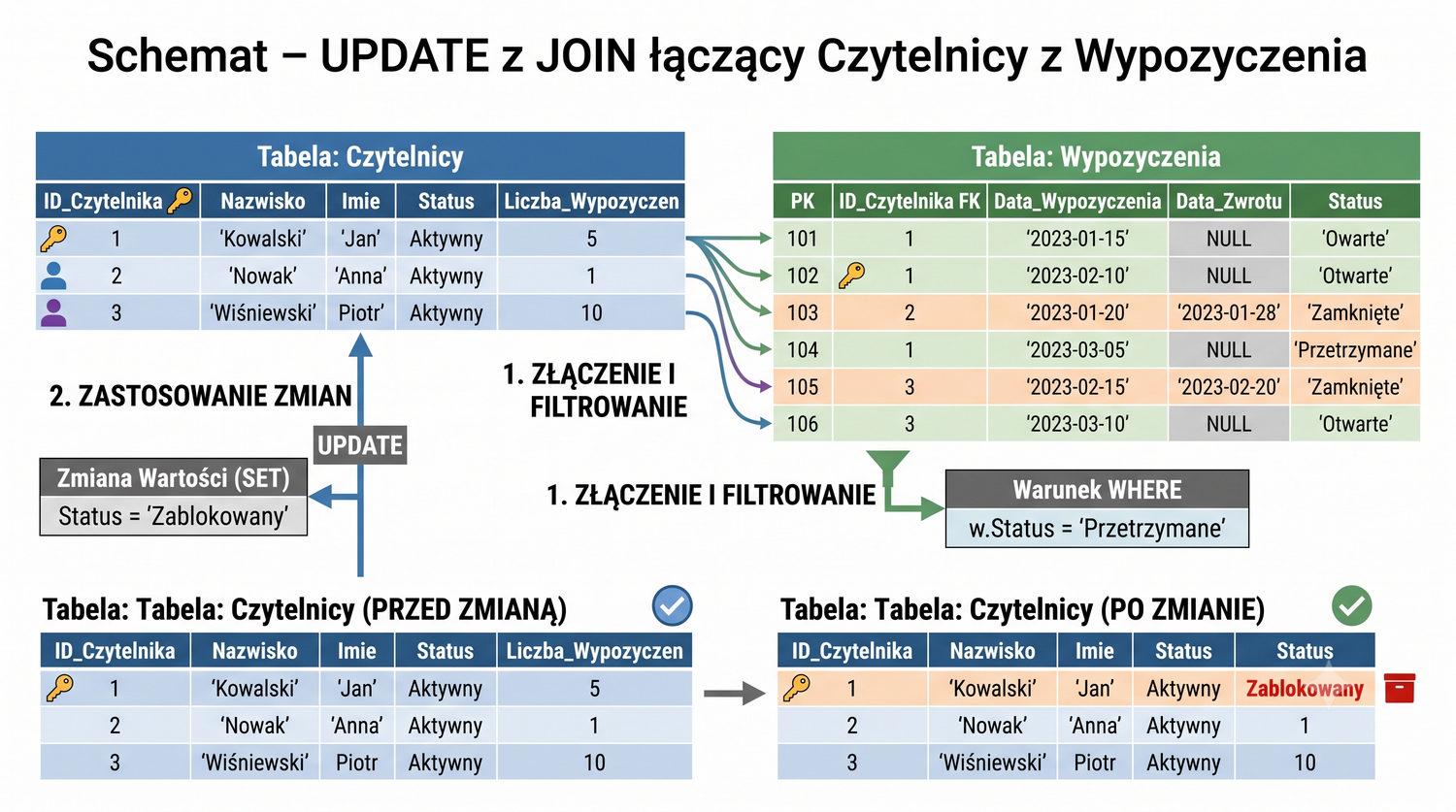
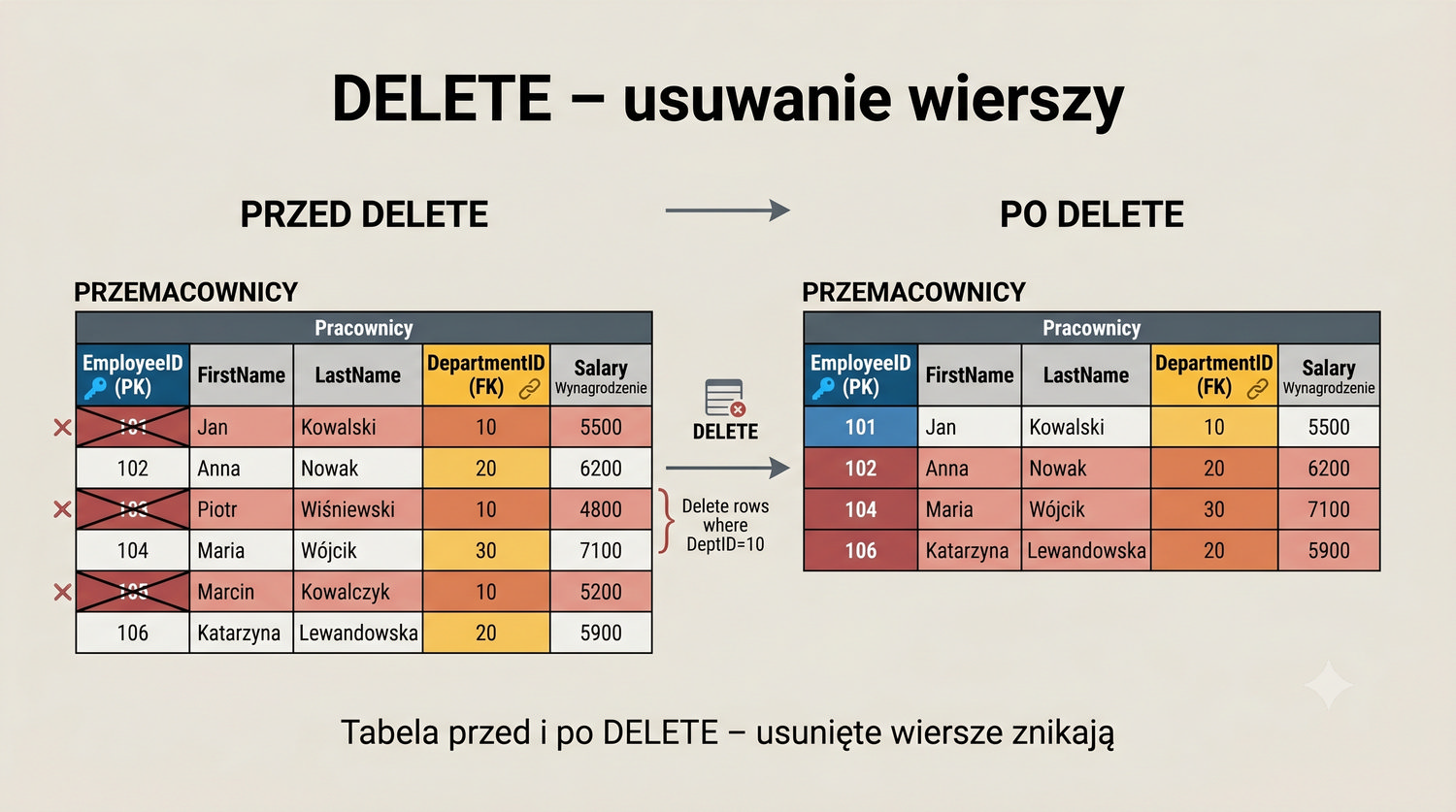
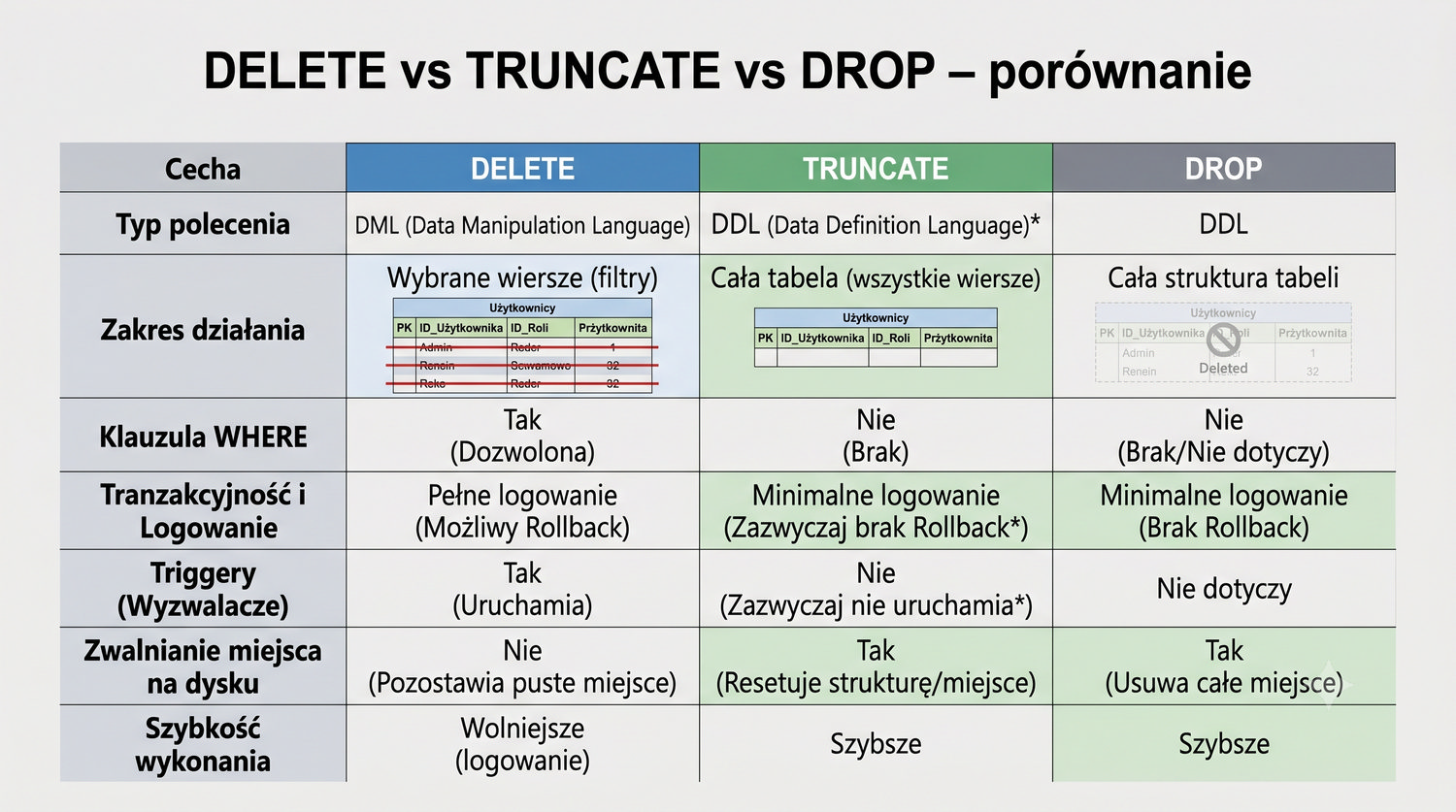
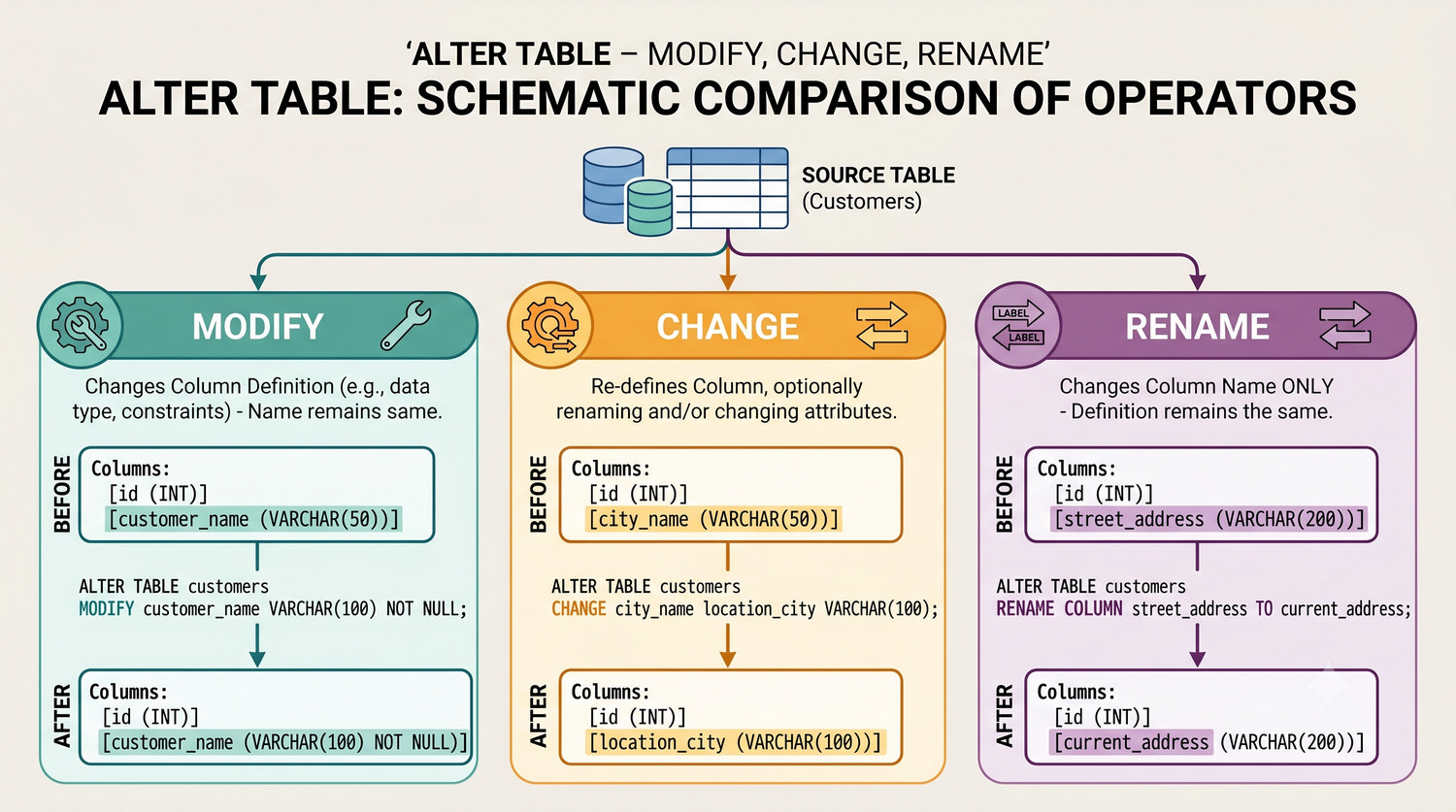
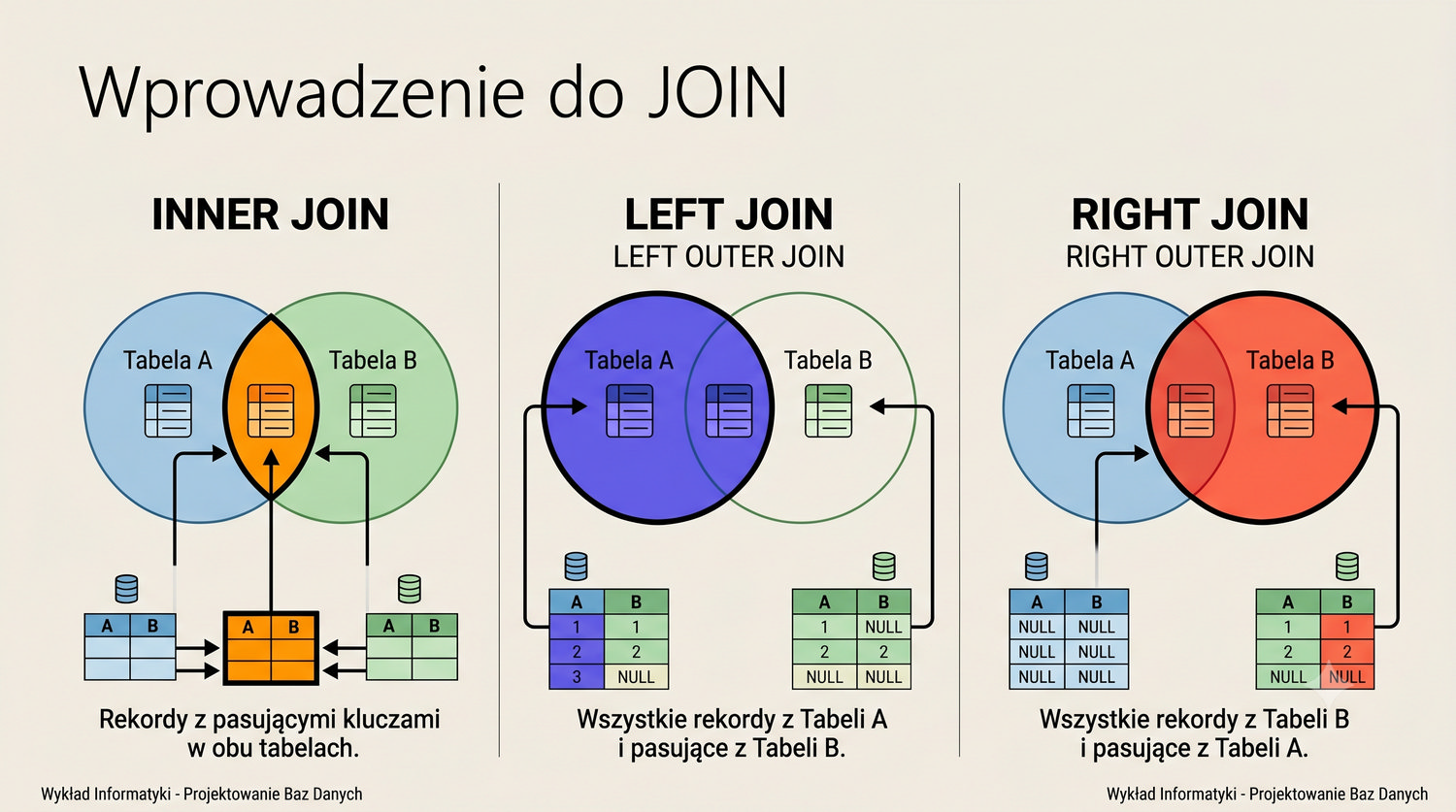
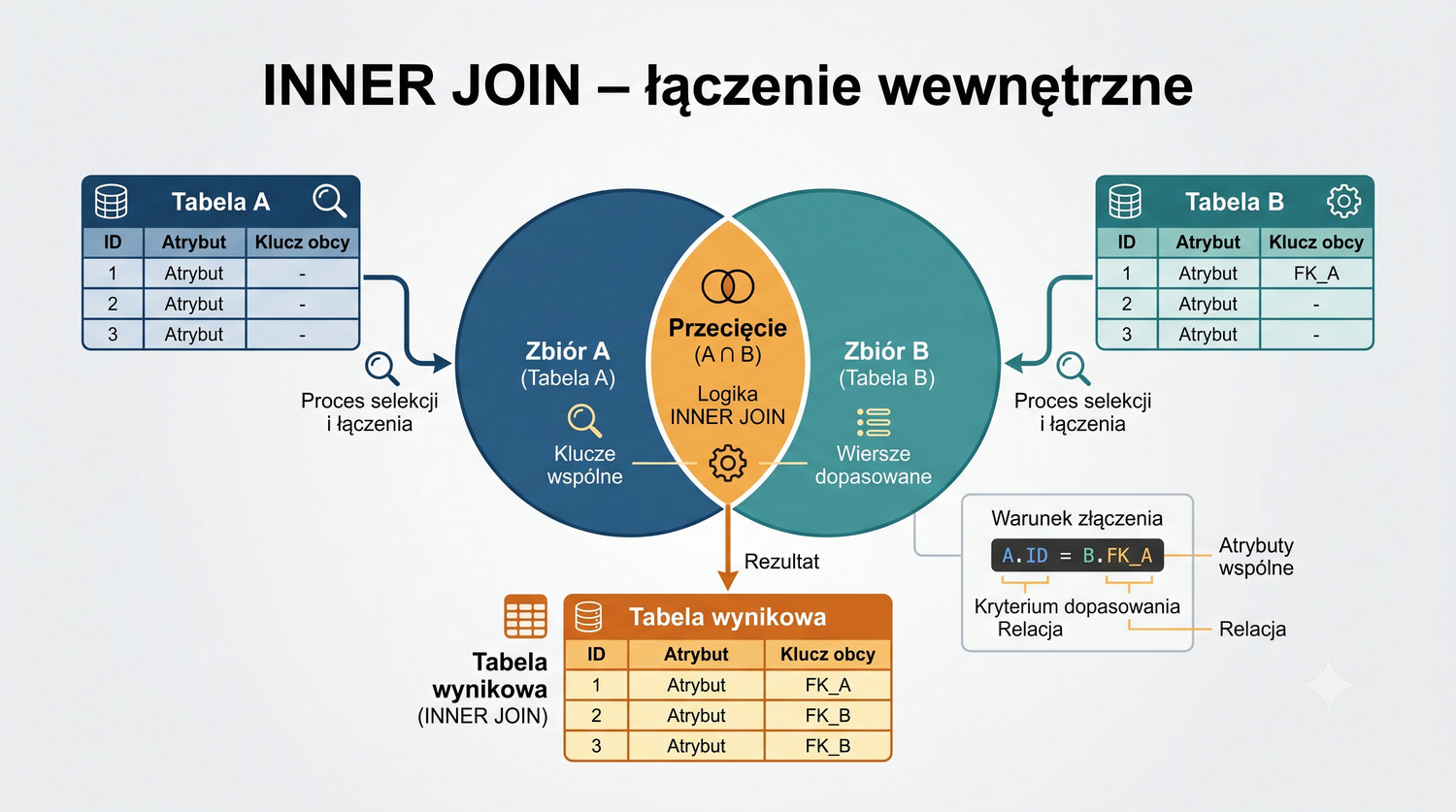
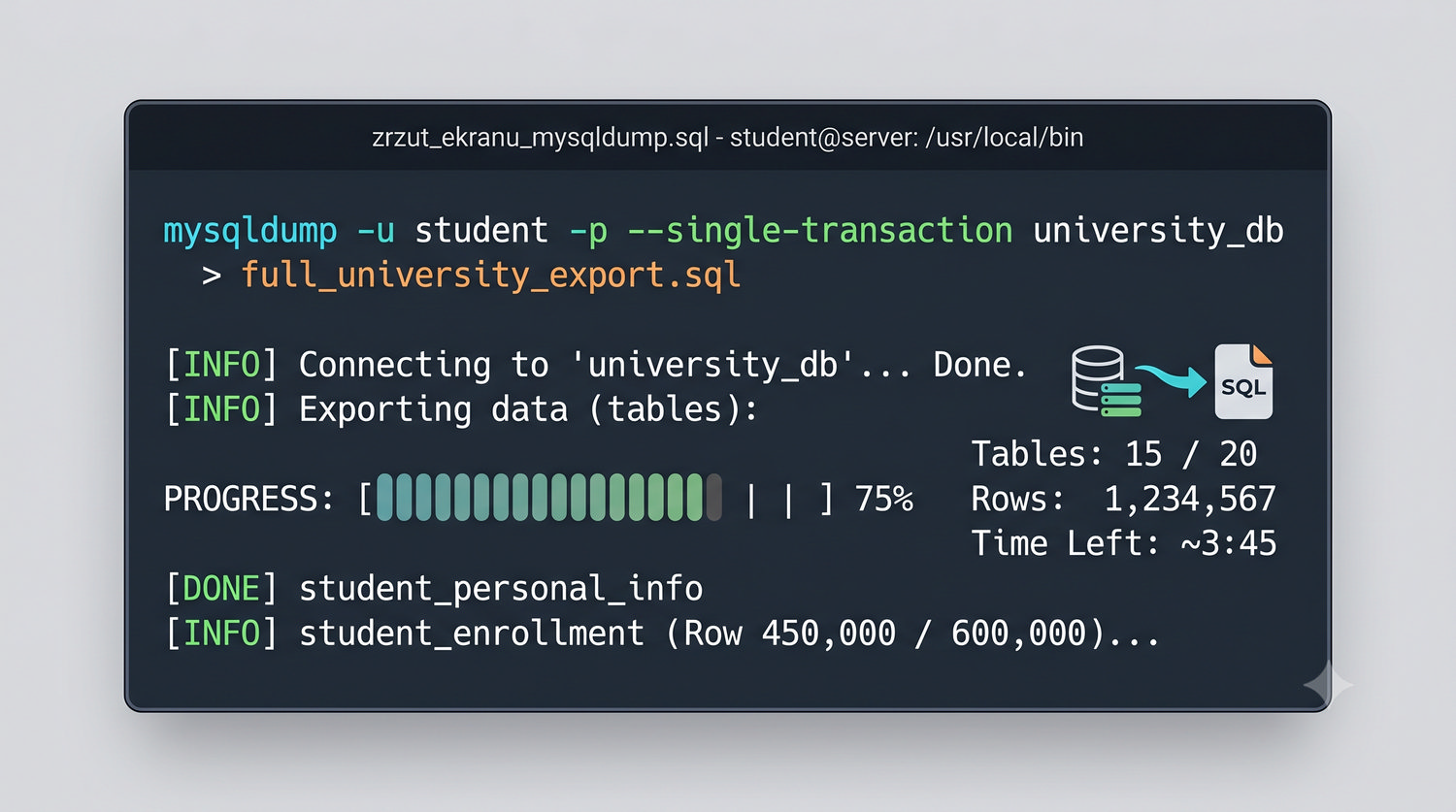
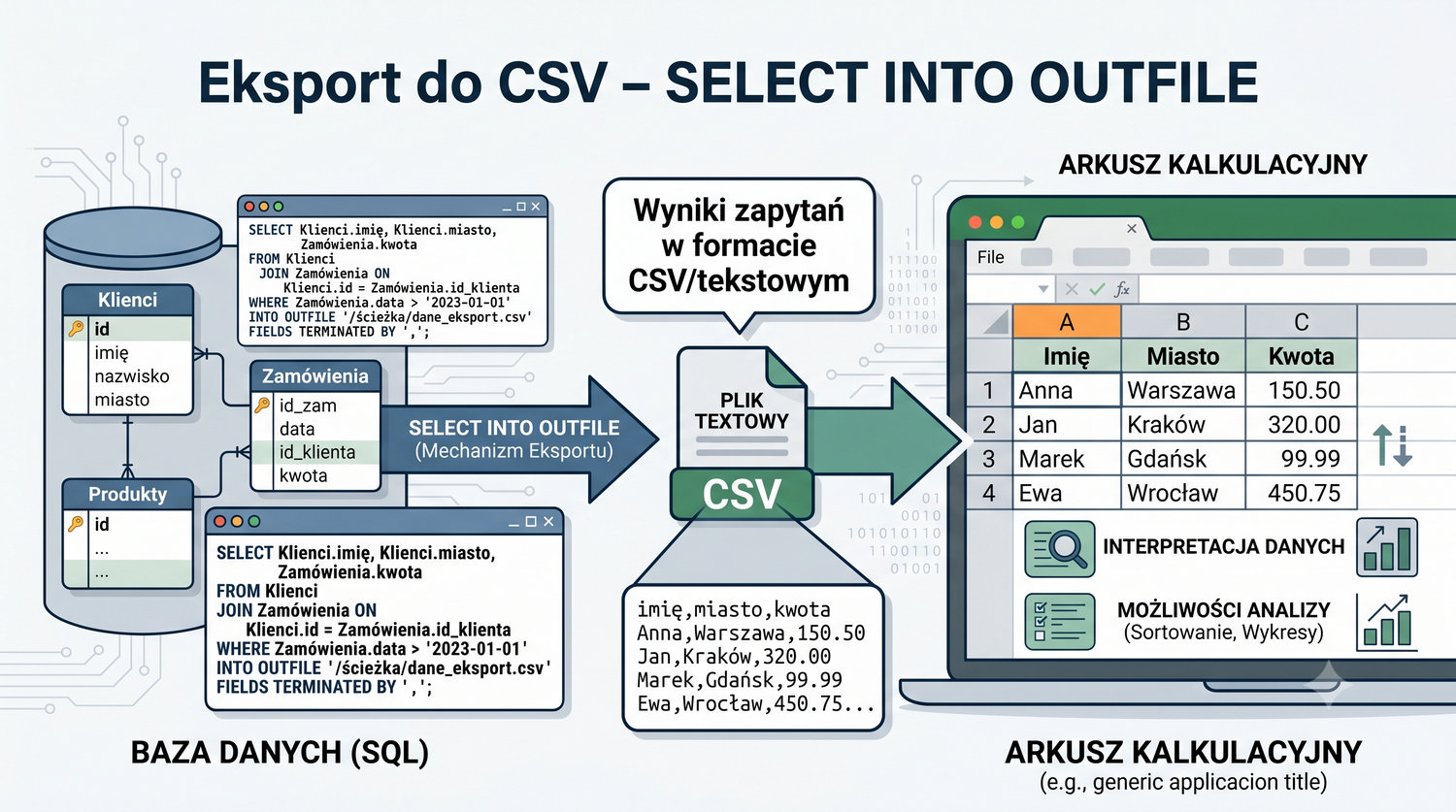
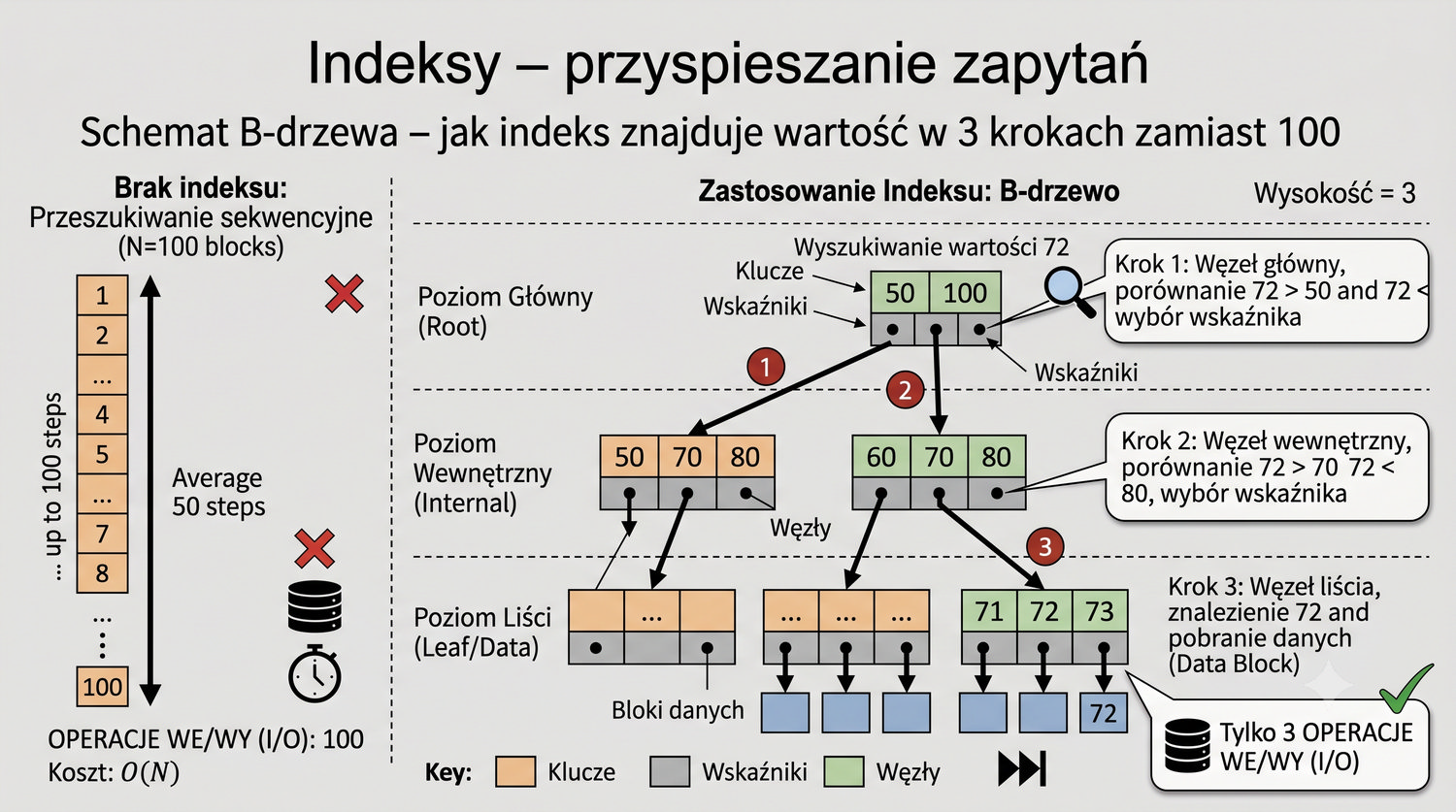
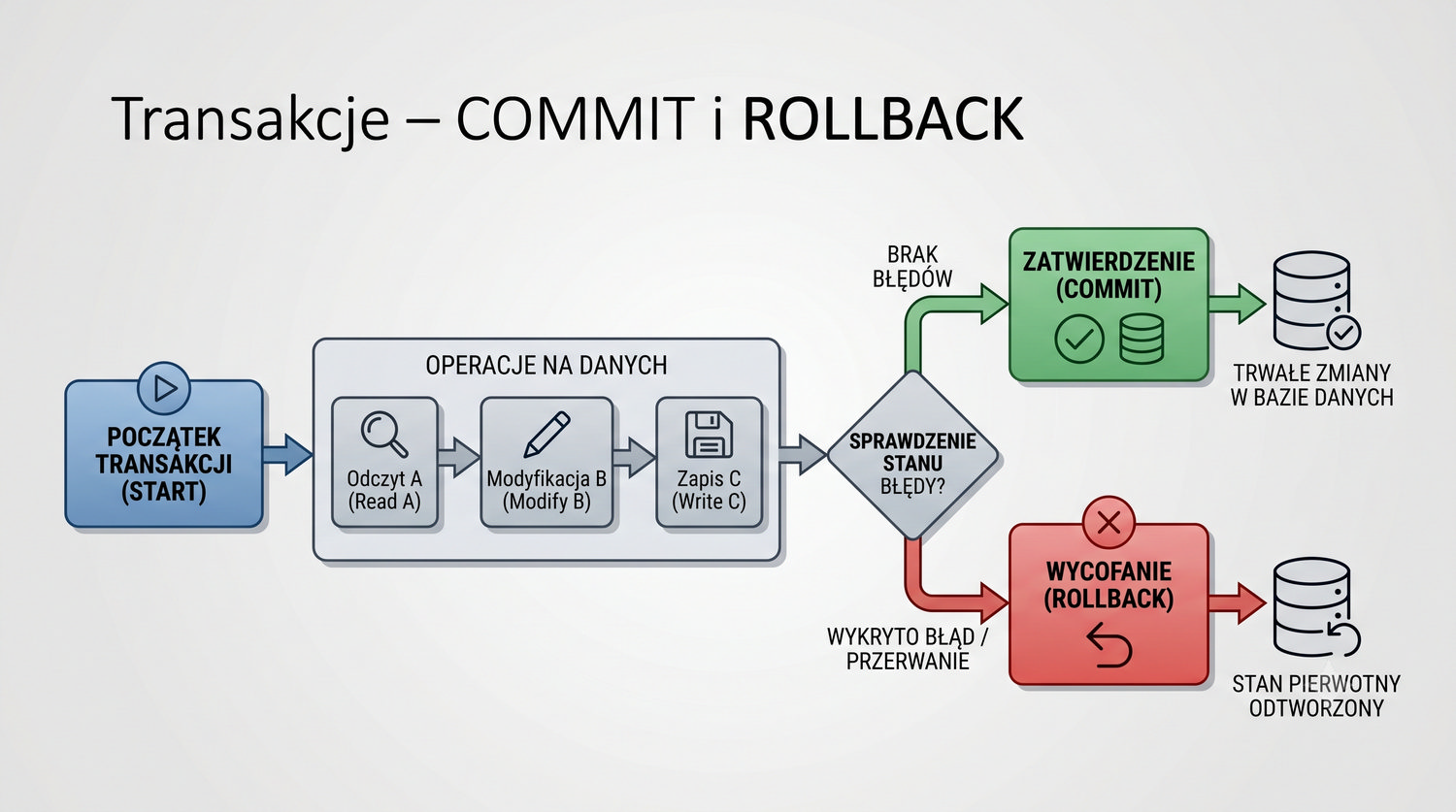
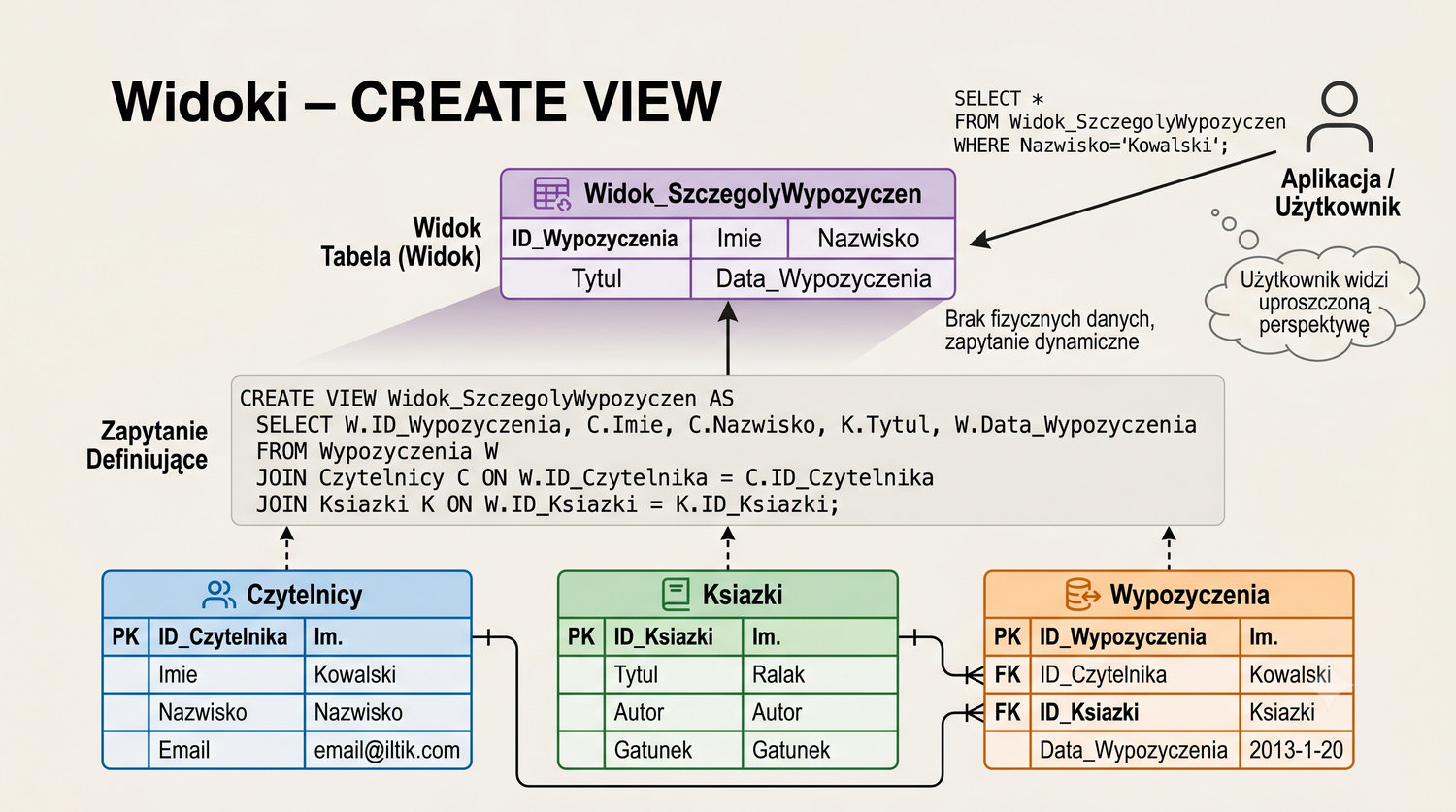
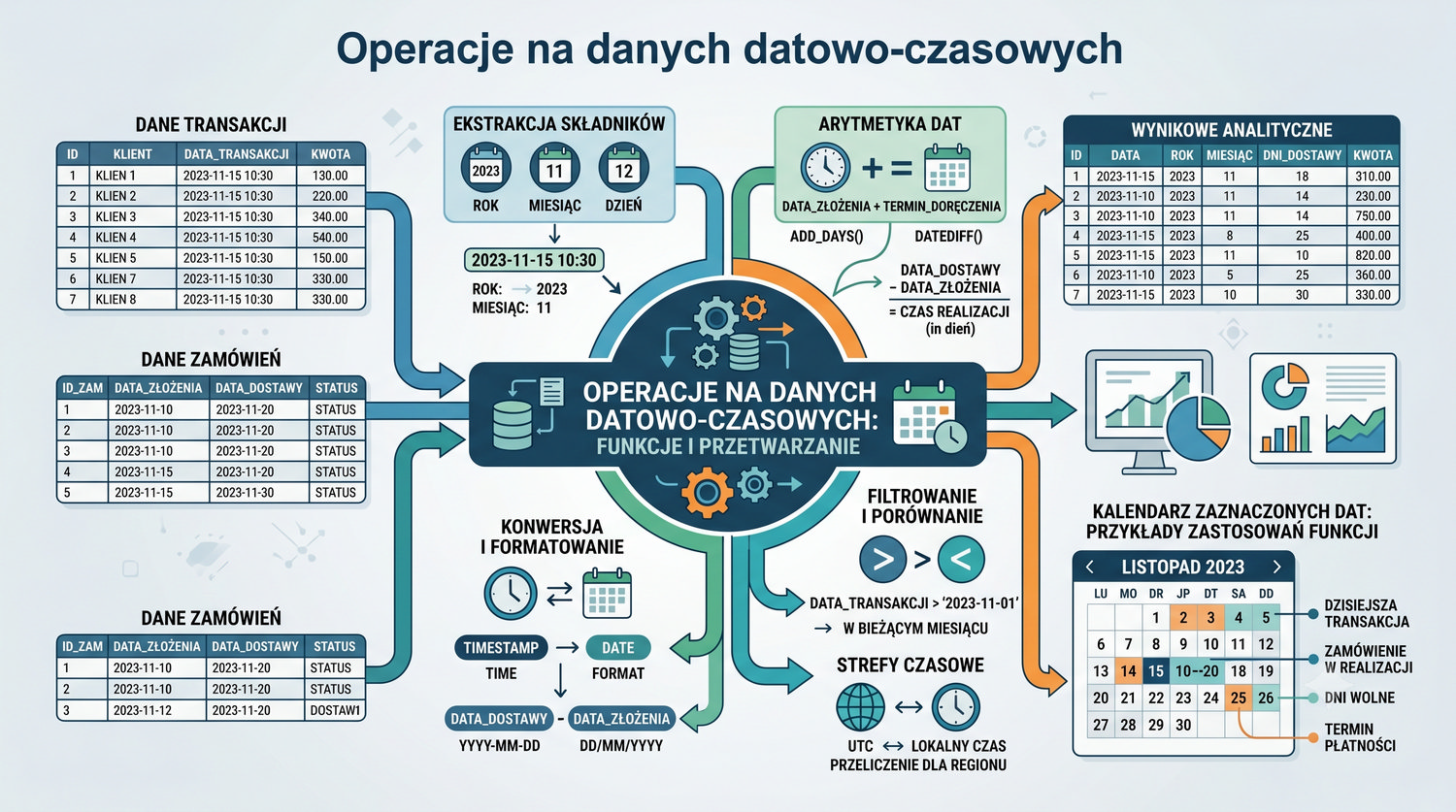
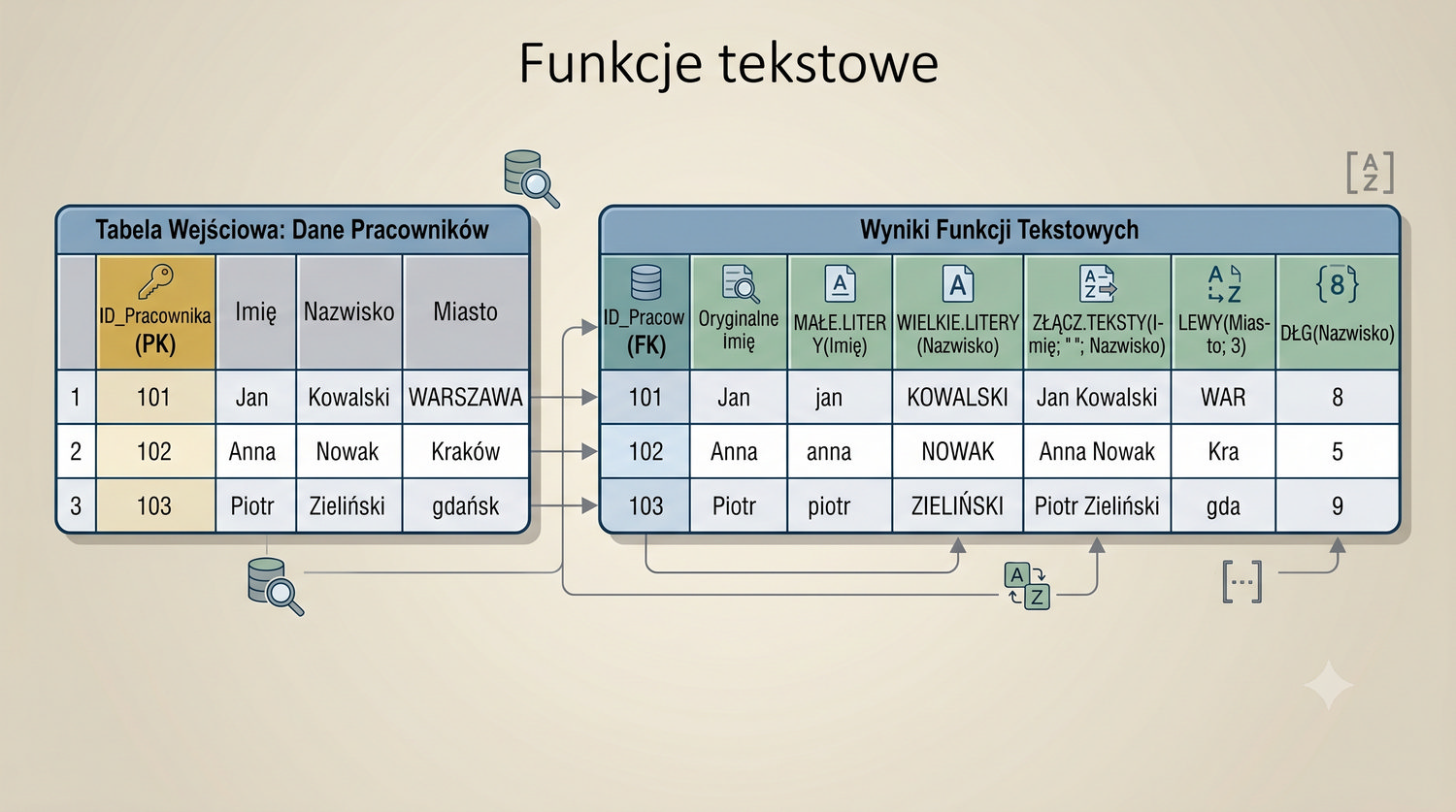
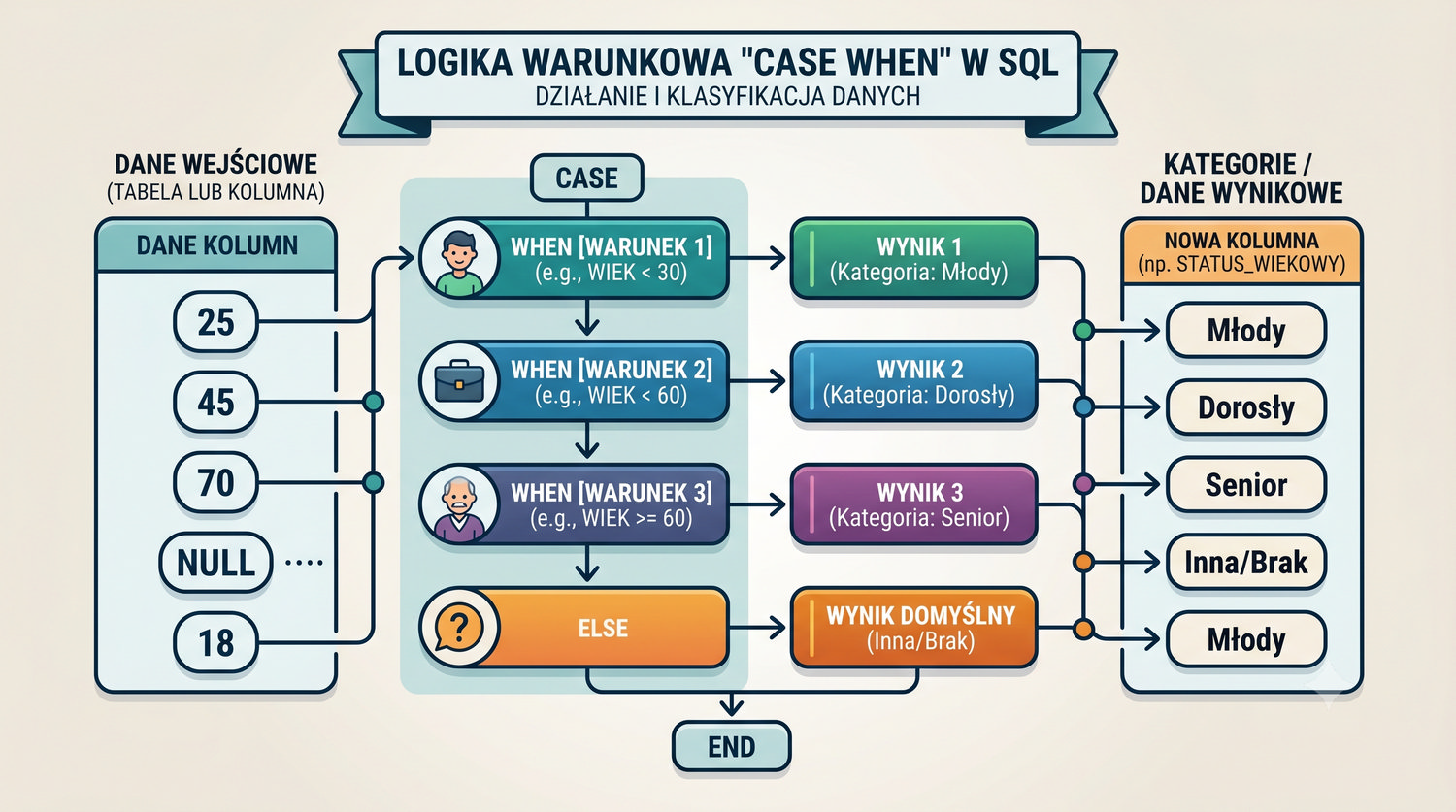
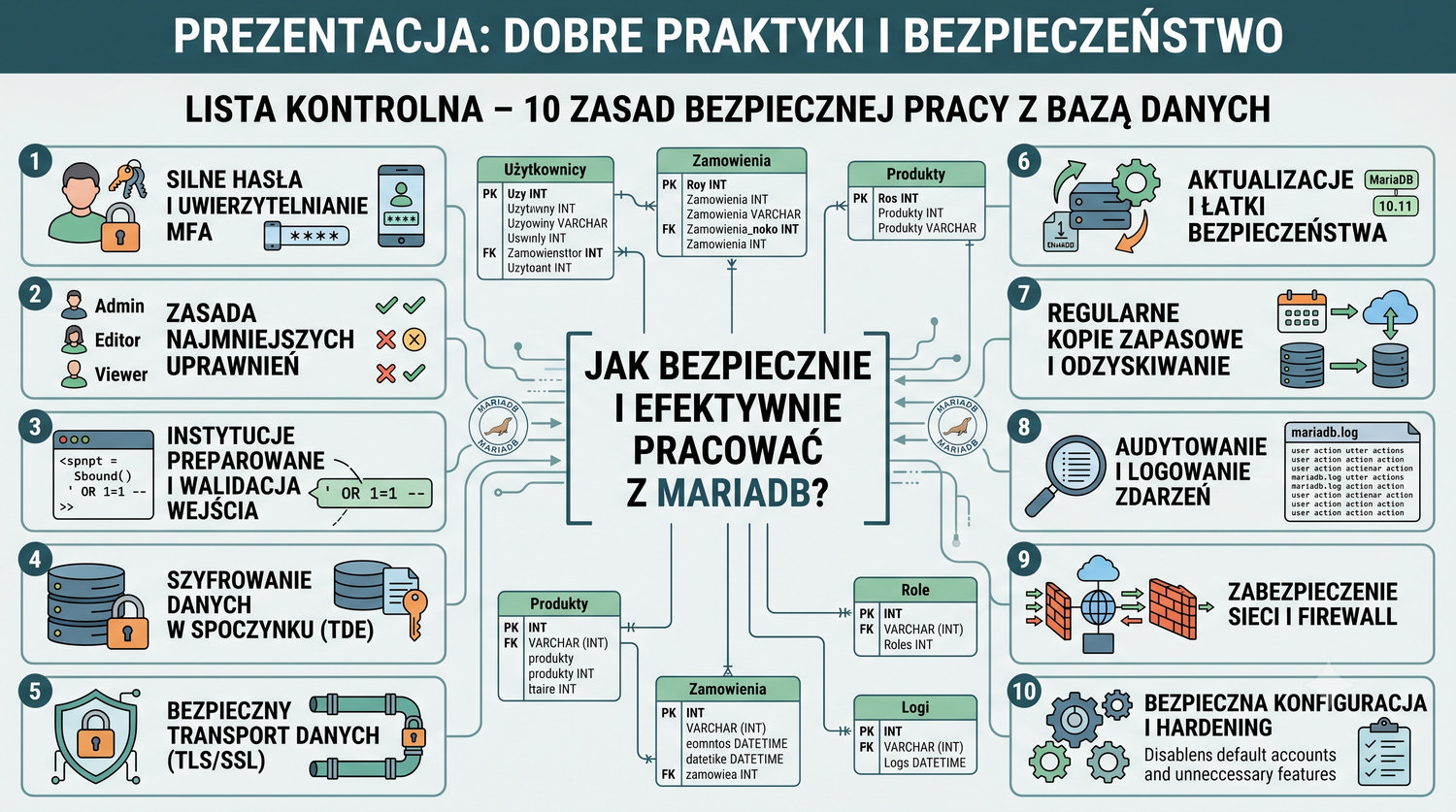
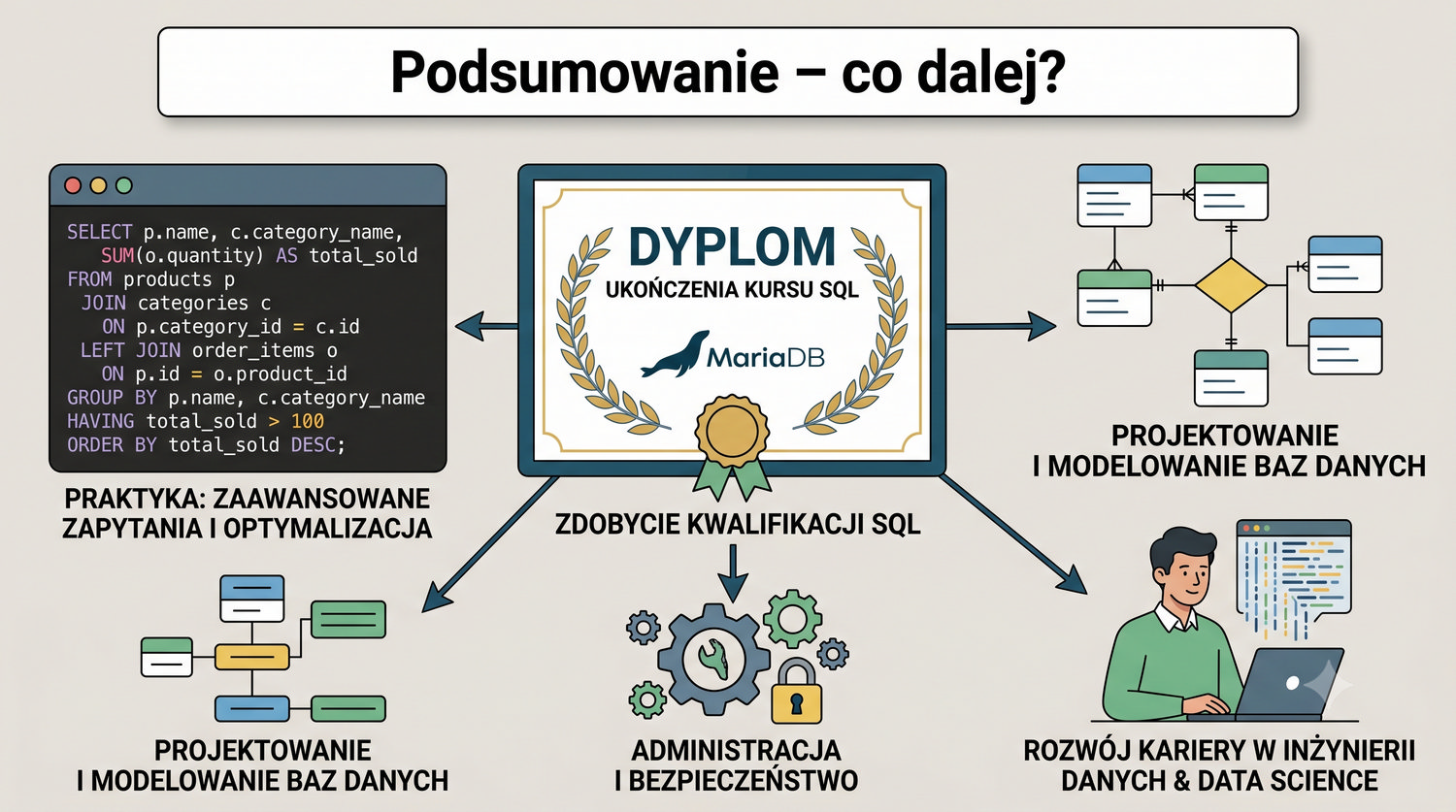
W sześćdziesięciu slajdach opanujesz wszystkie praktyczne umiejętności: od uruchomienia bazy, przez tworzenie tabel i operacje DML, aż po złączenia JOIN i eksport danych. Każde polecenie jest zilustrowane przykładem.
MariaDB to jeden z najpopularniejszych systemów baz danych na świecie – darmowy, open-source i w pełni kompatybilny z MySQL.