Zależności złączeniowe – ostatni krok normalizacji relacyjnej
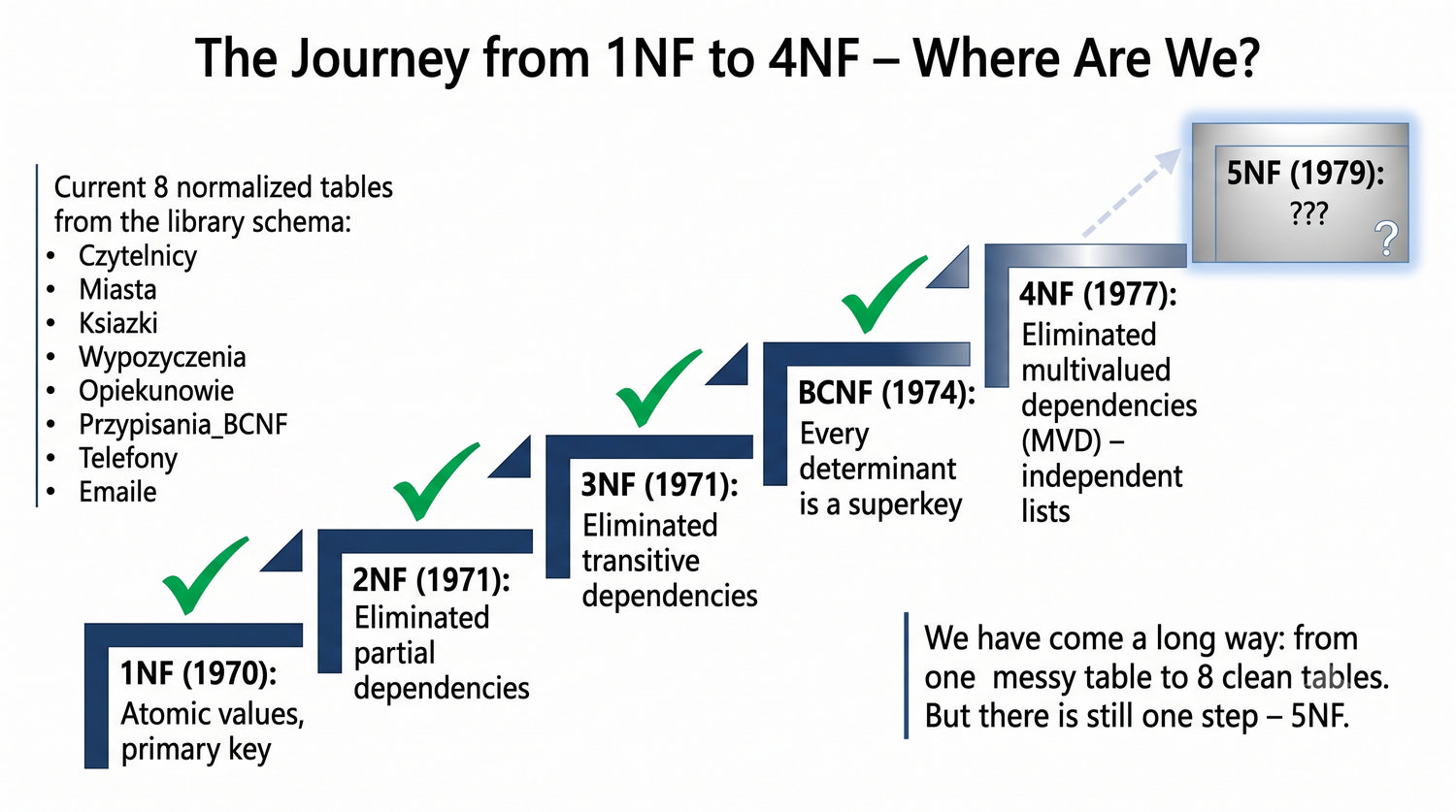
Zakładamy znajomość 1NF, 2NF, 3NF, BCNF i 4NF.
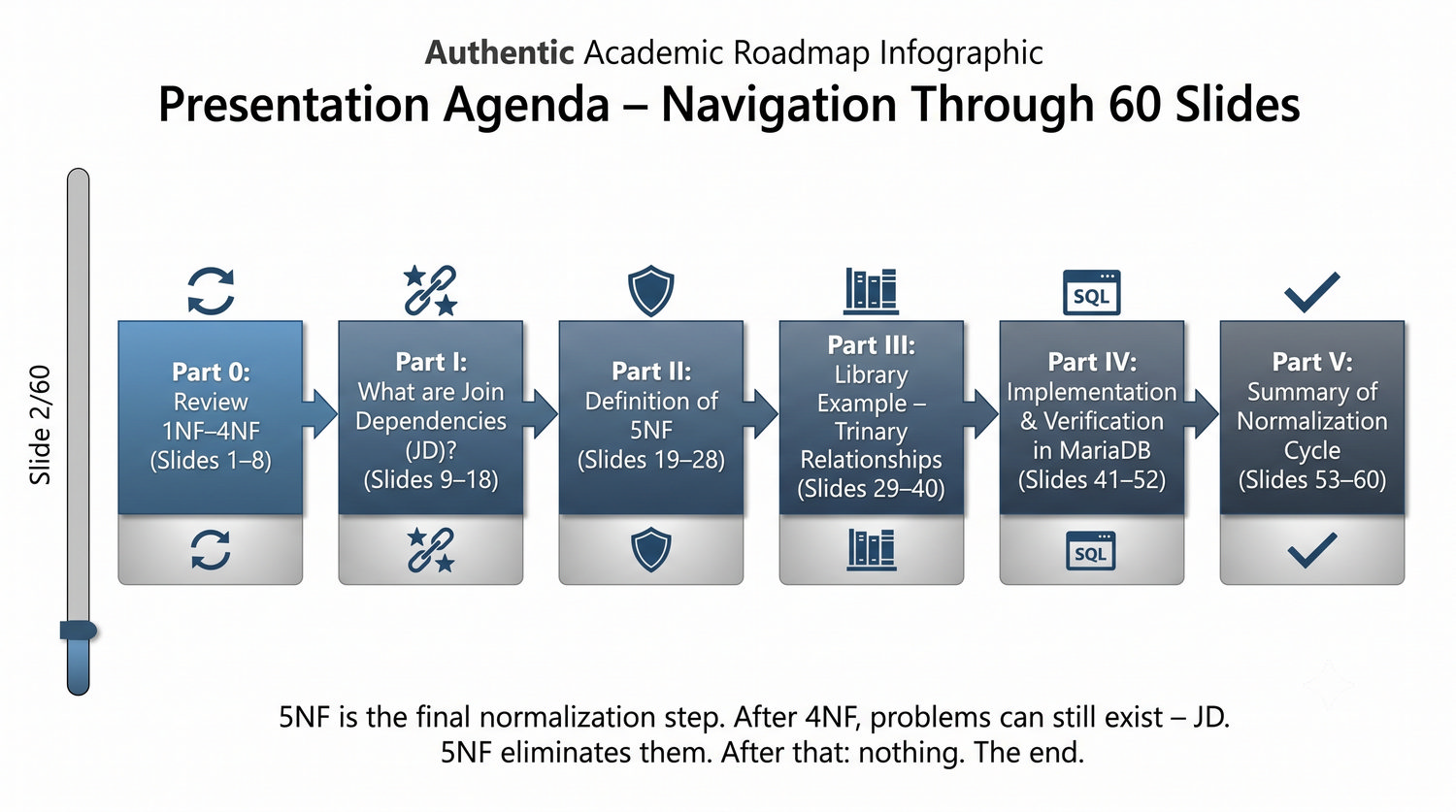
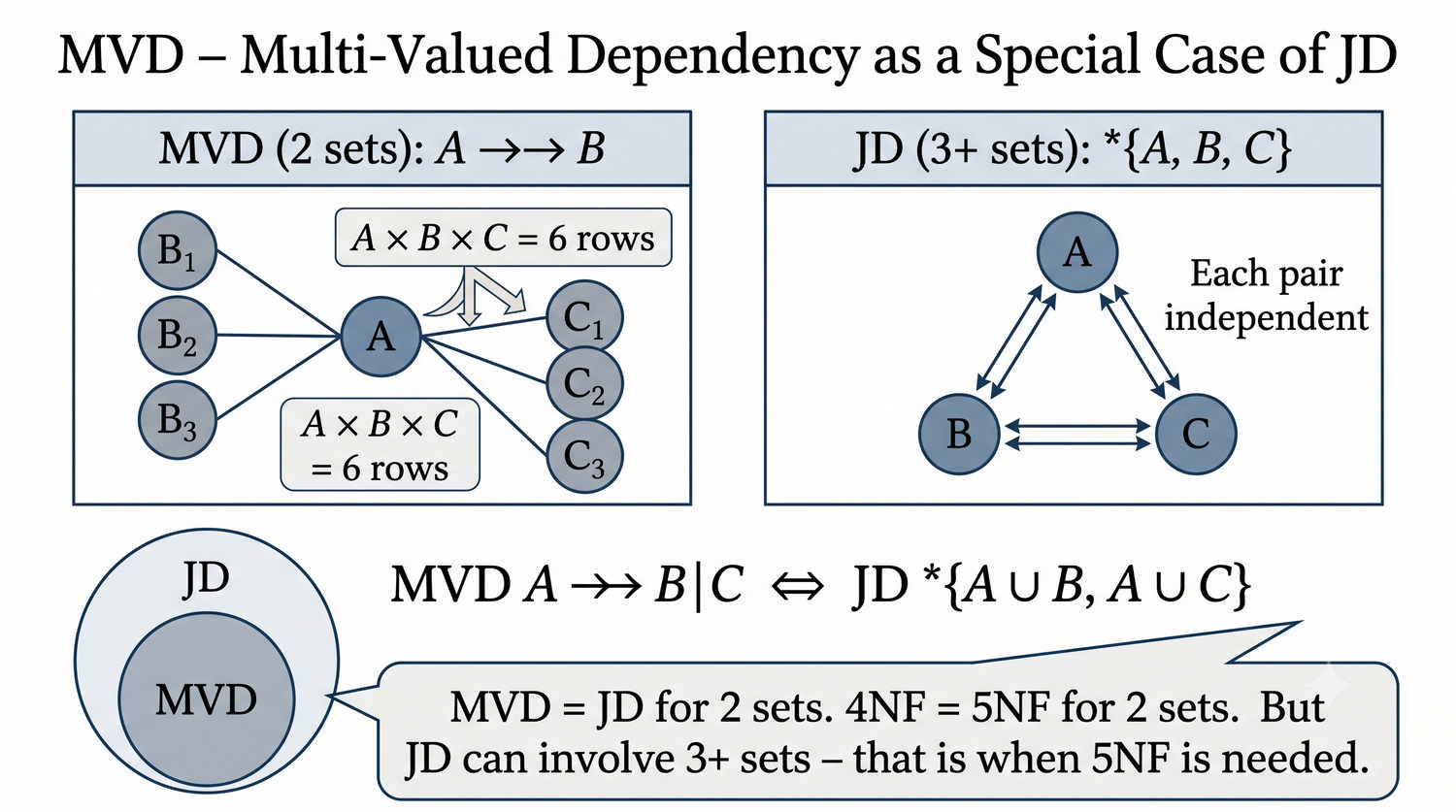
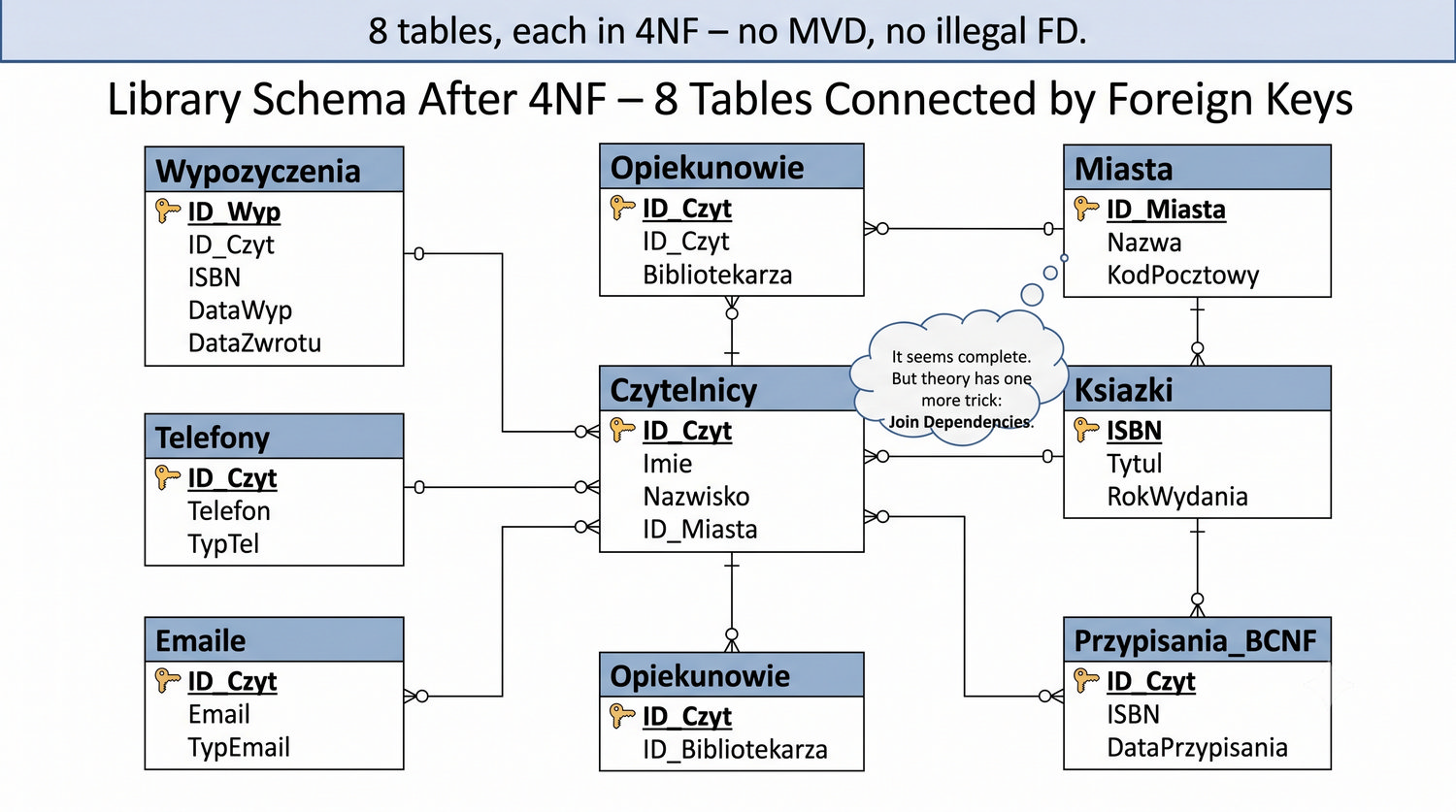
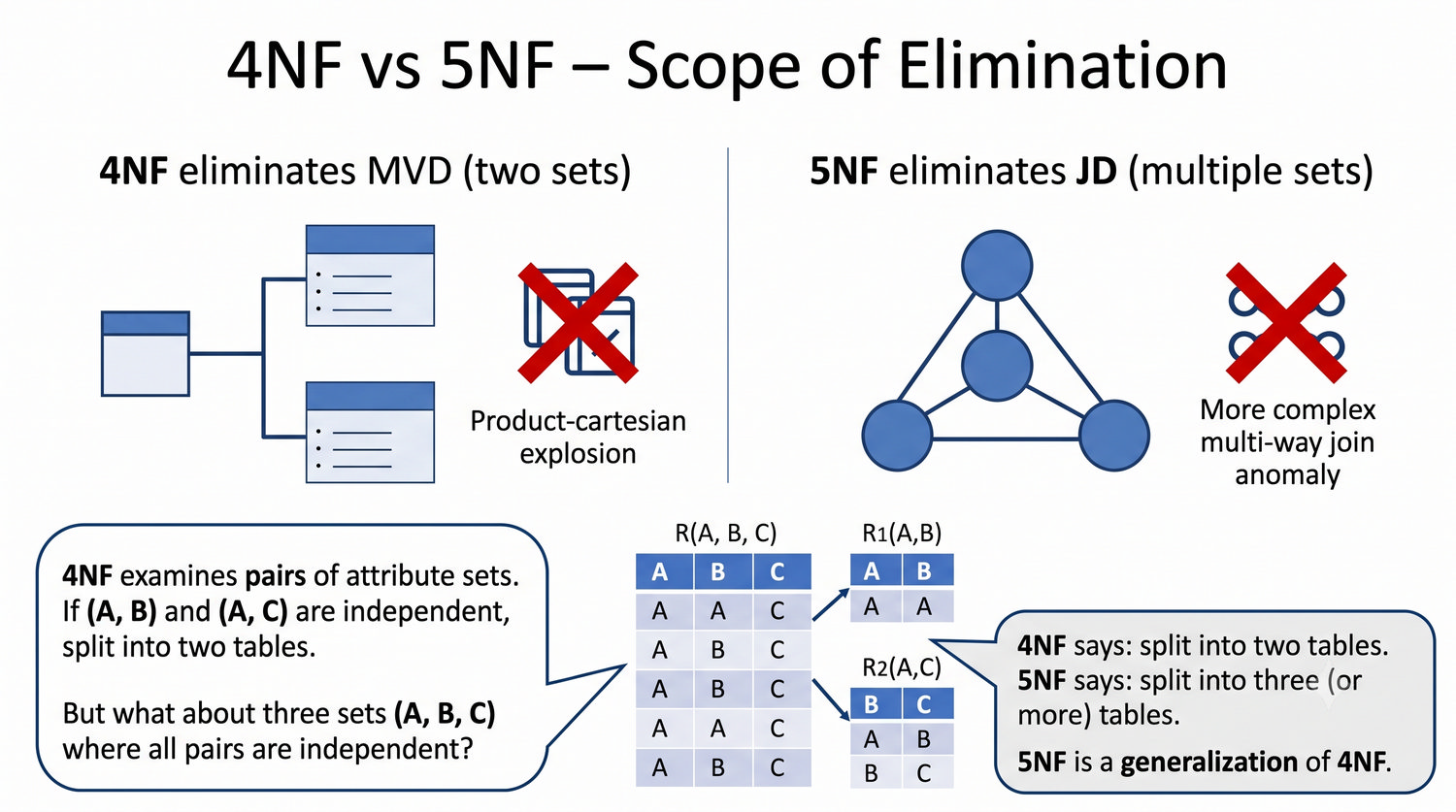
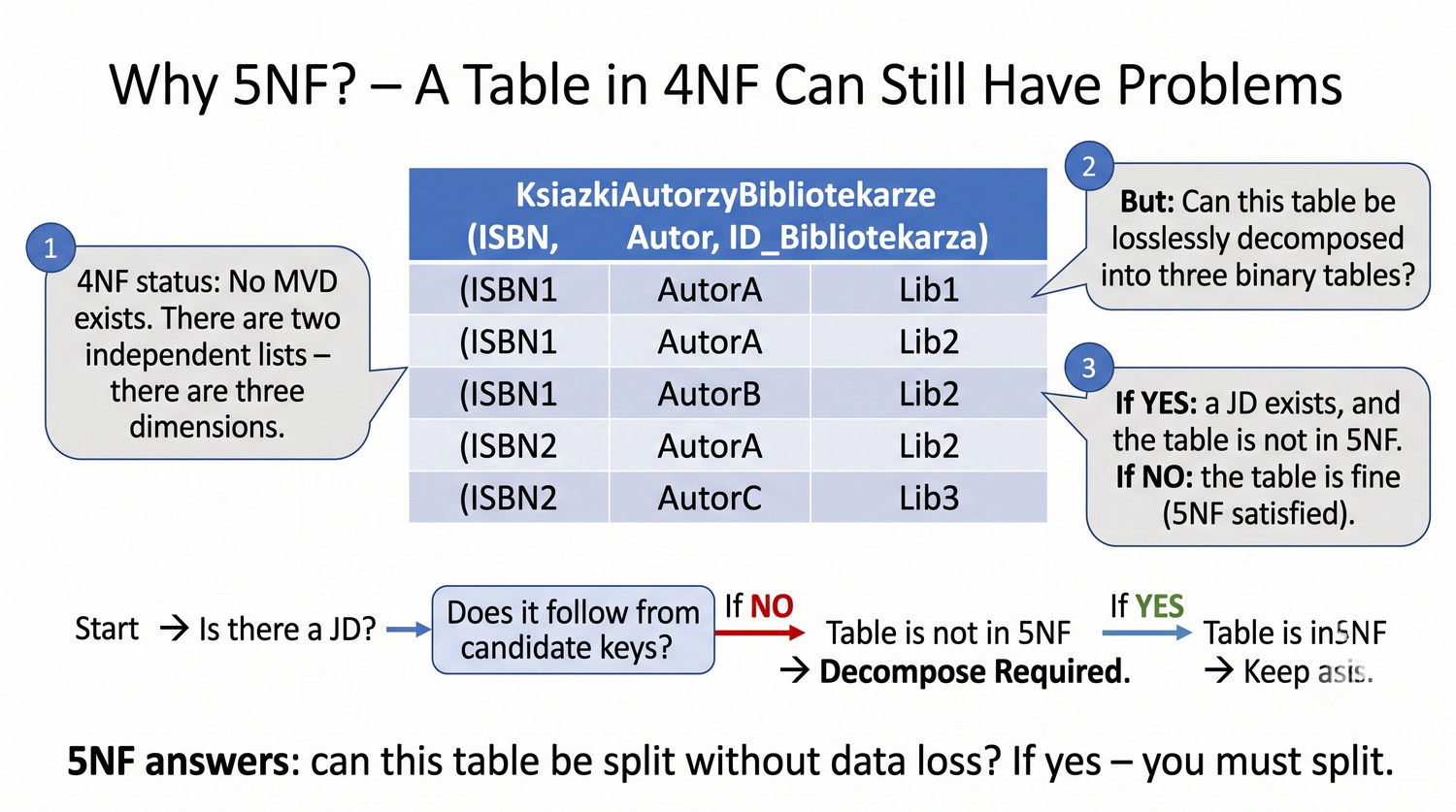
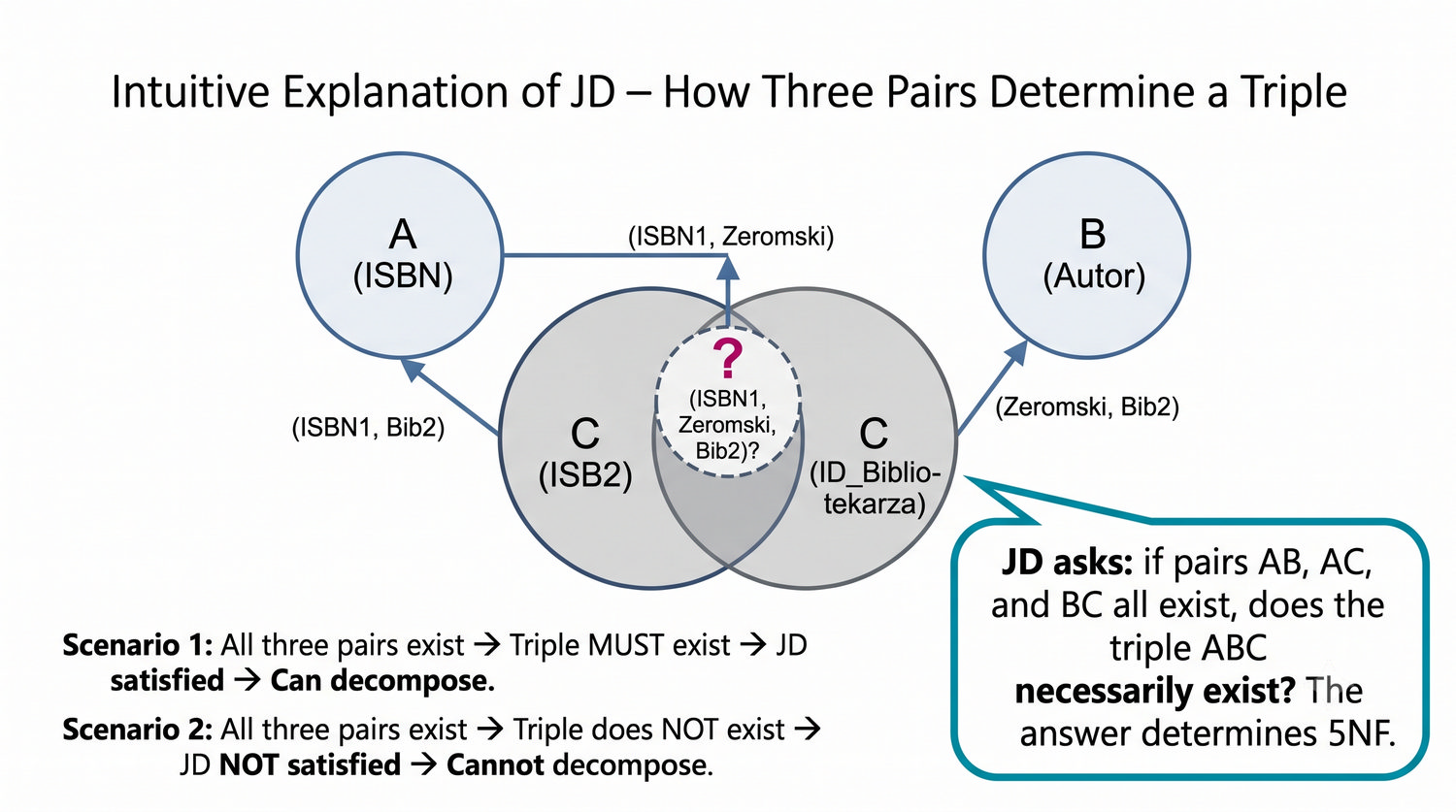
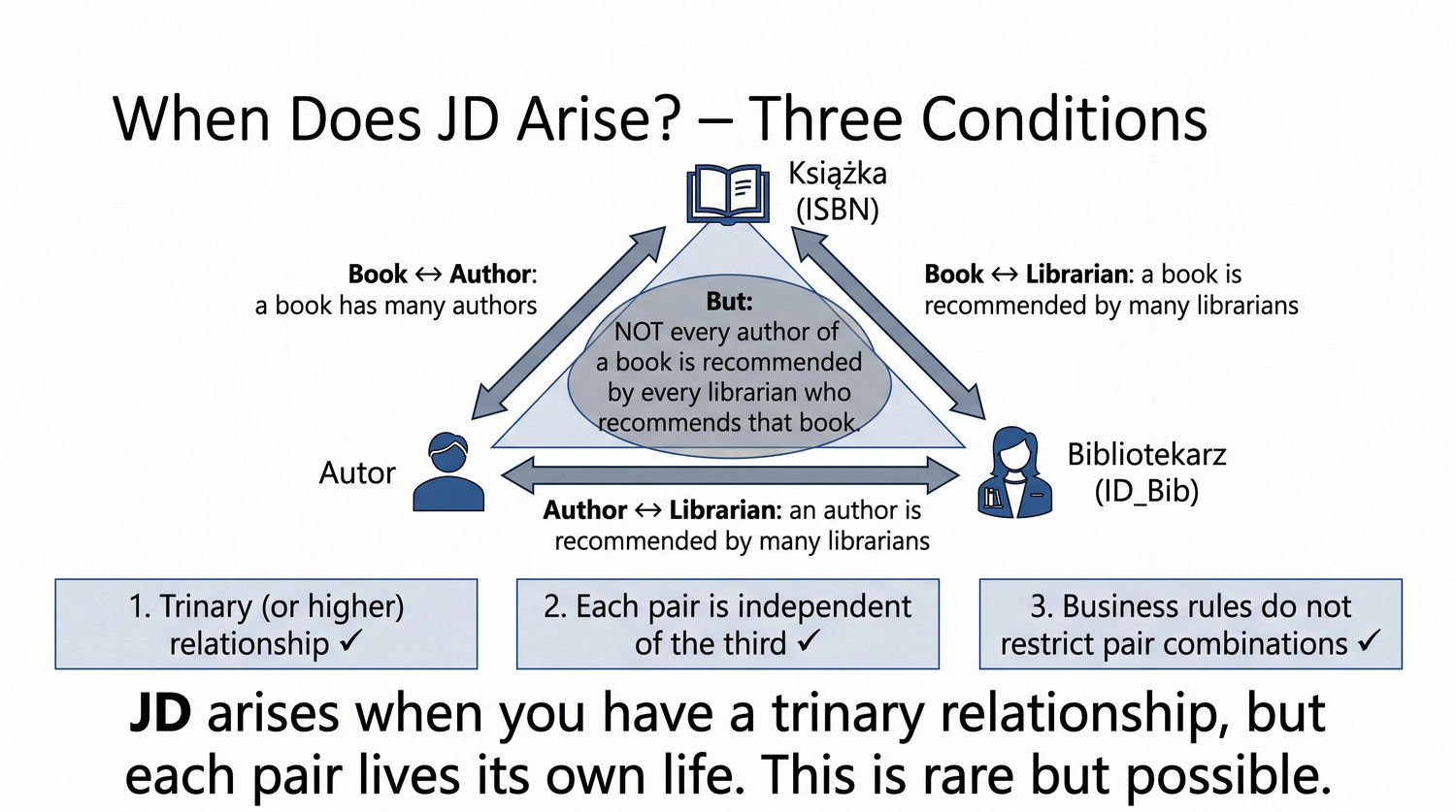
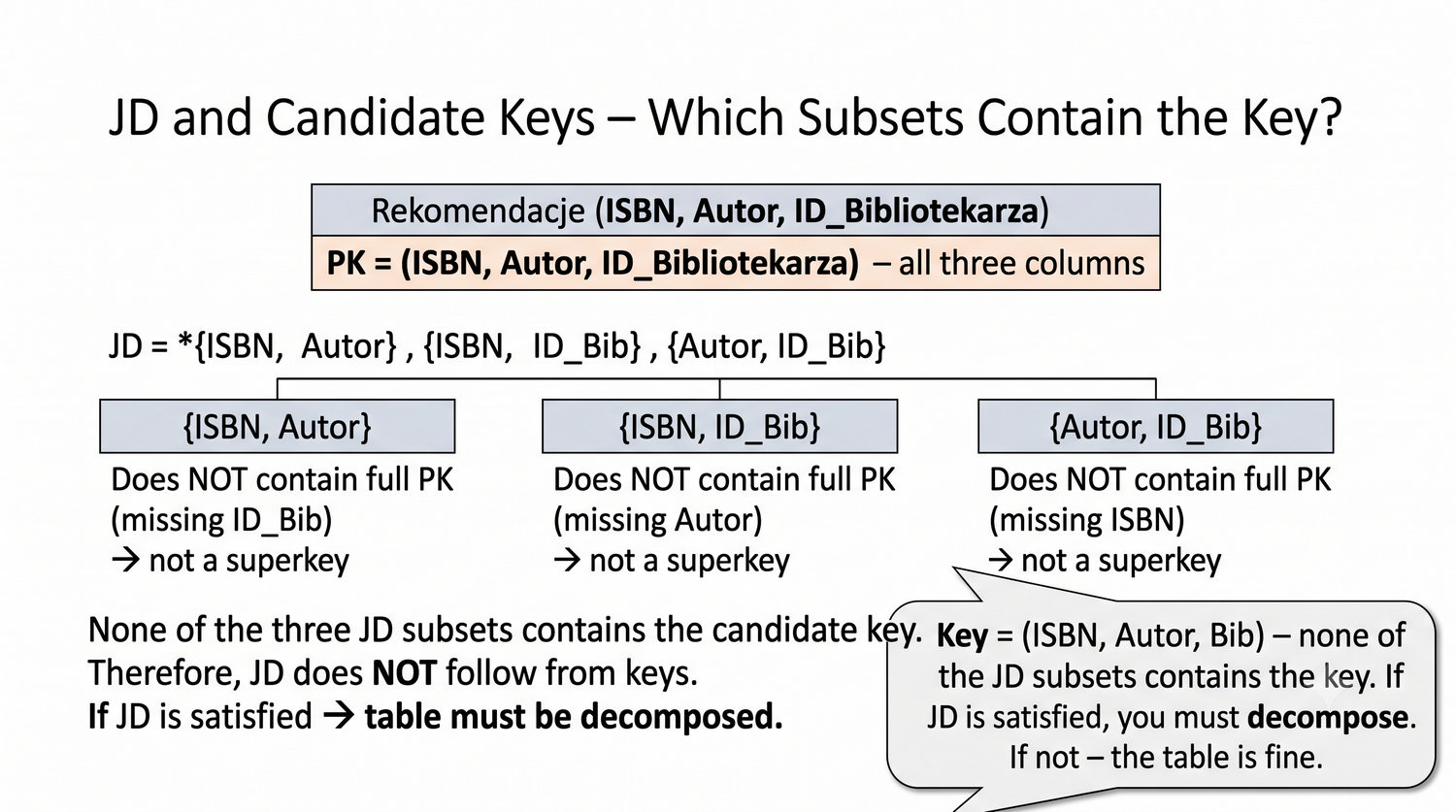
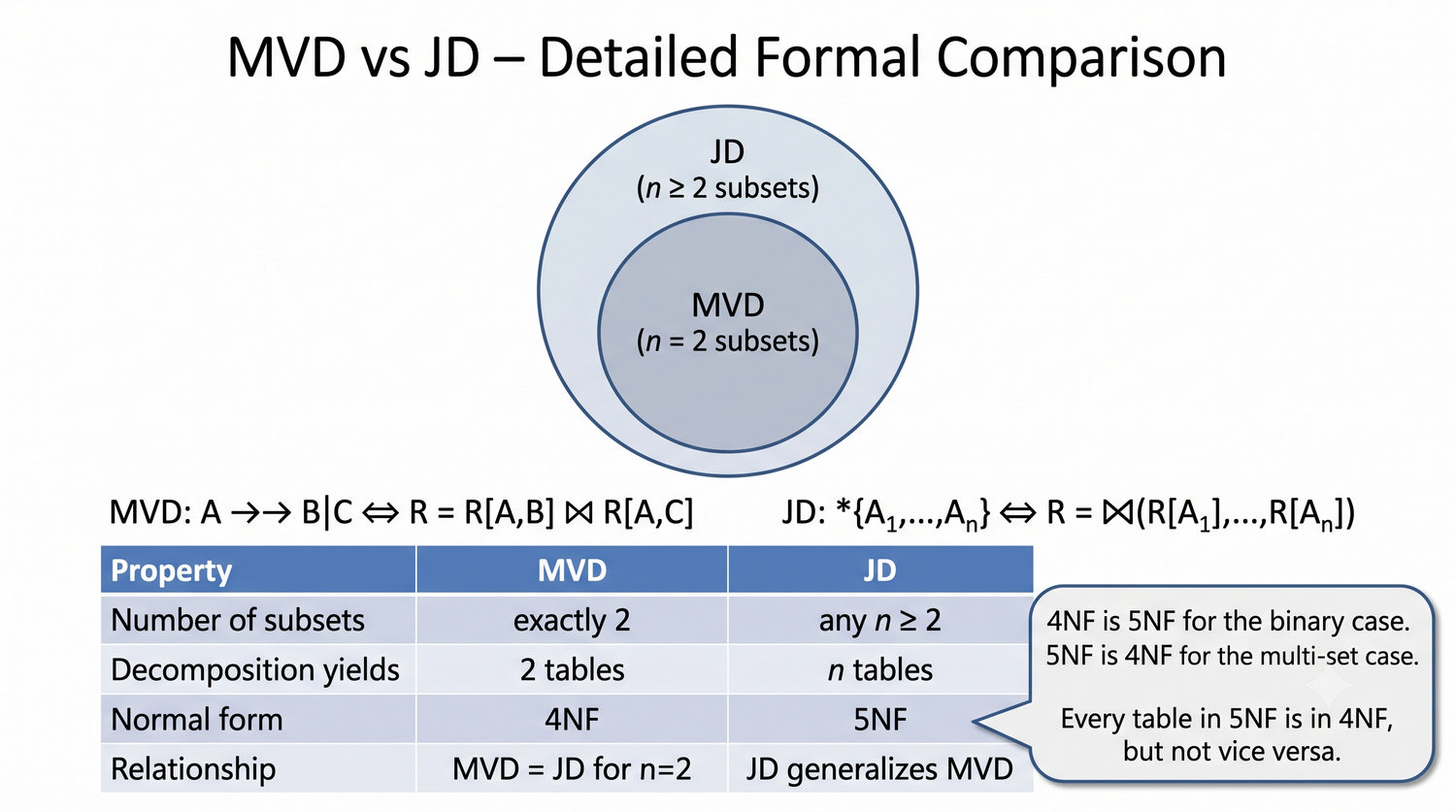
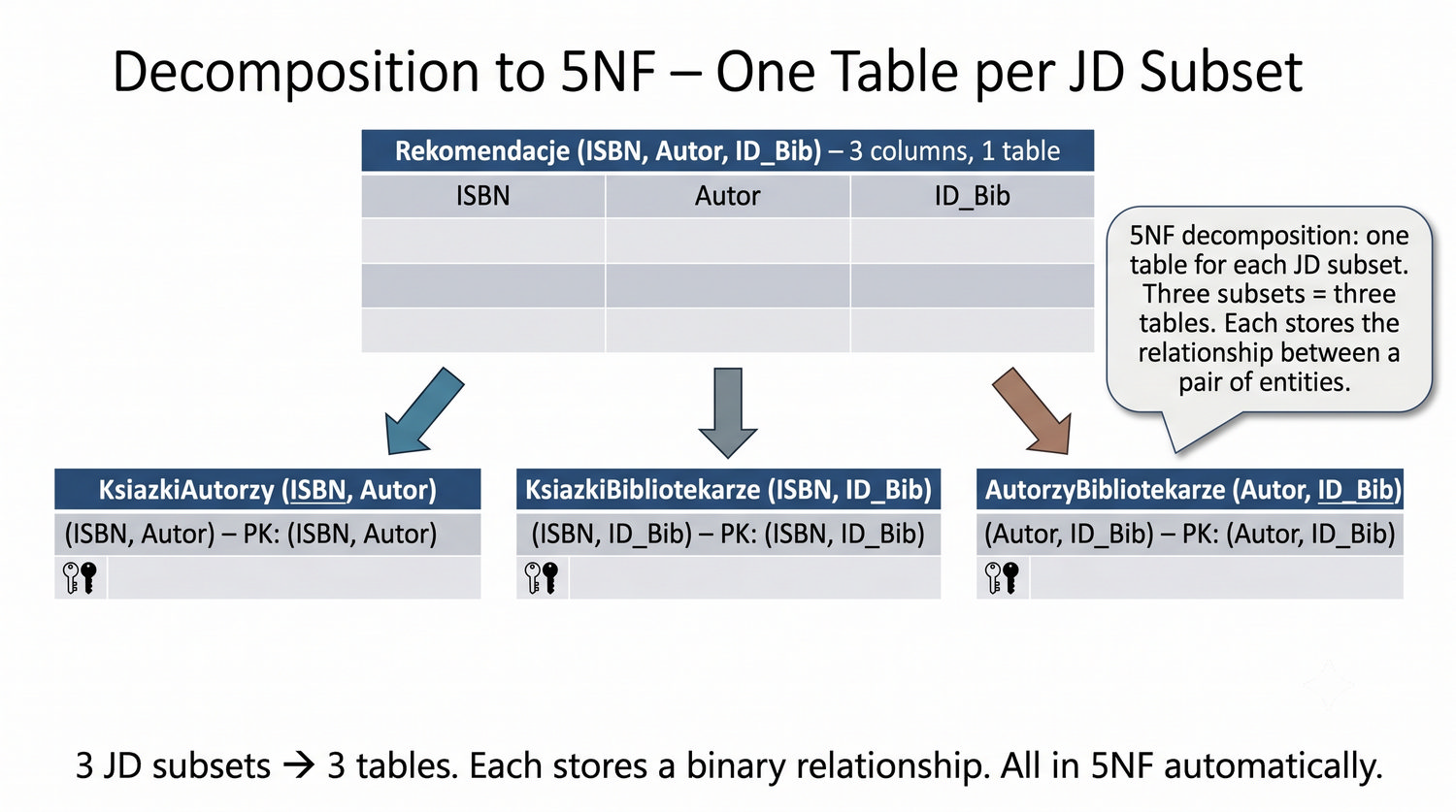
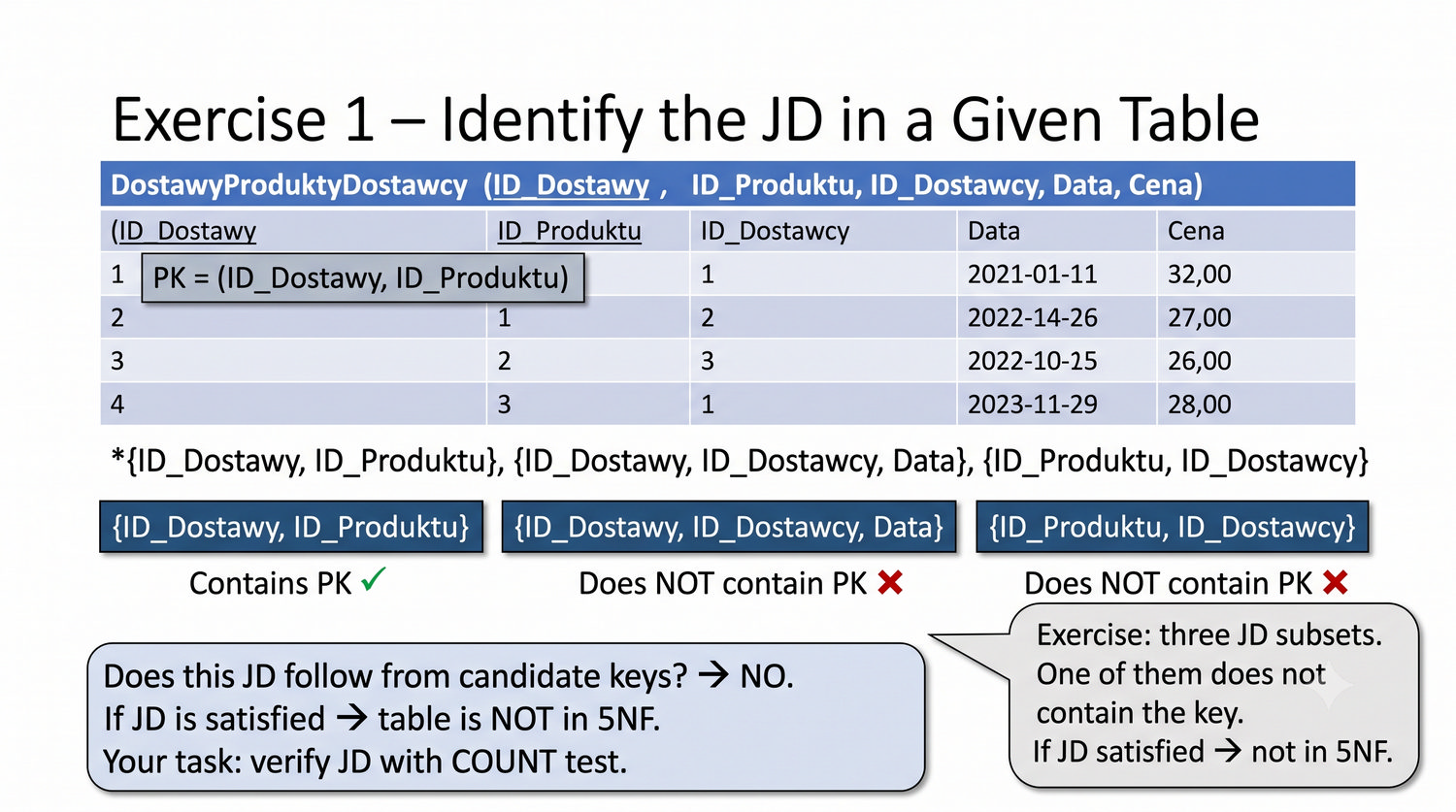
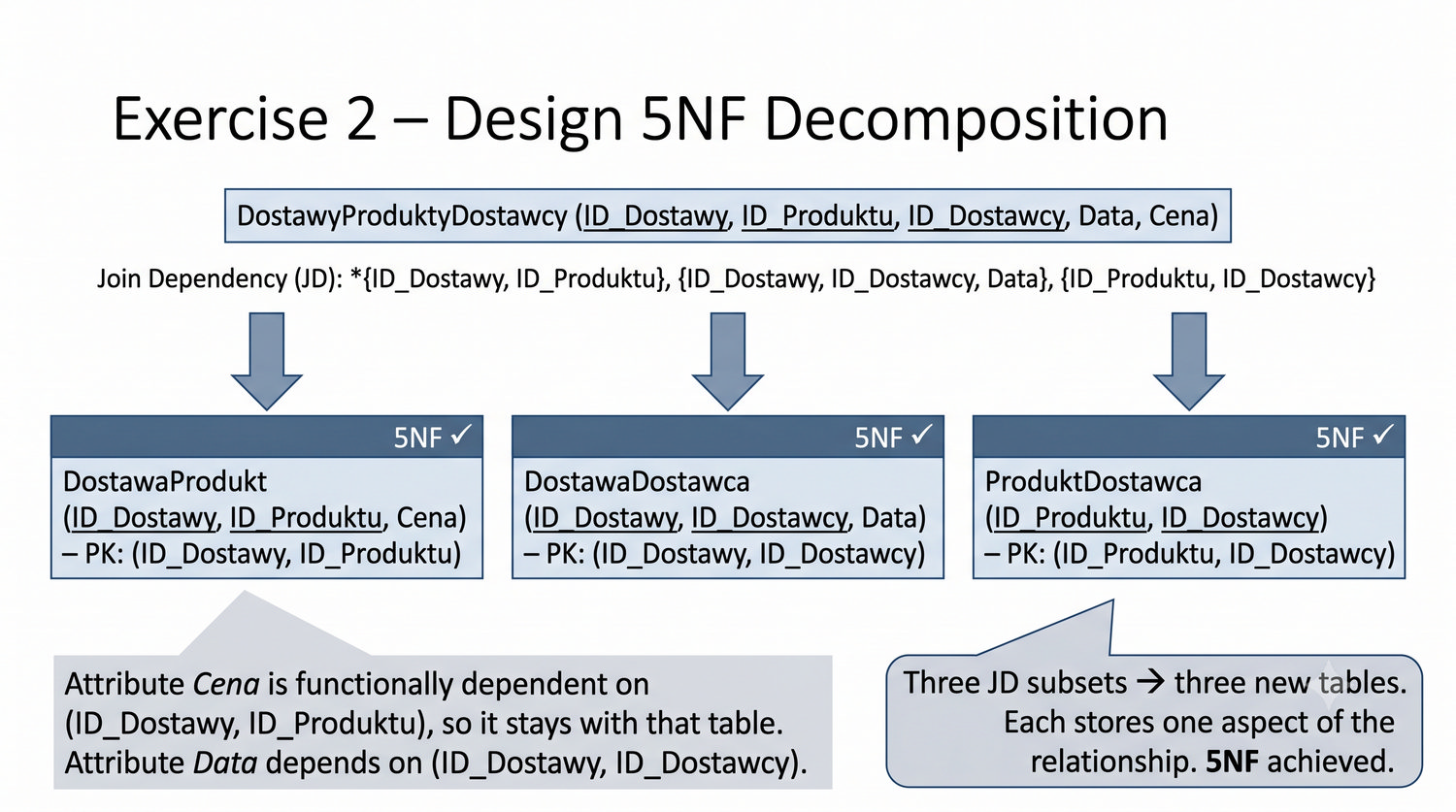
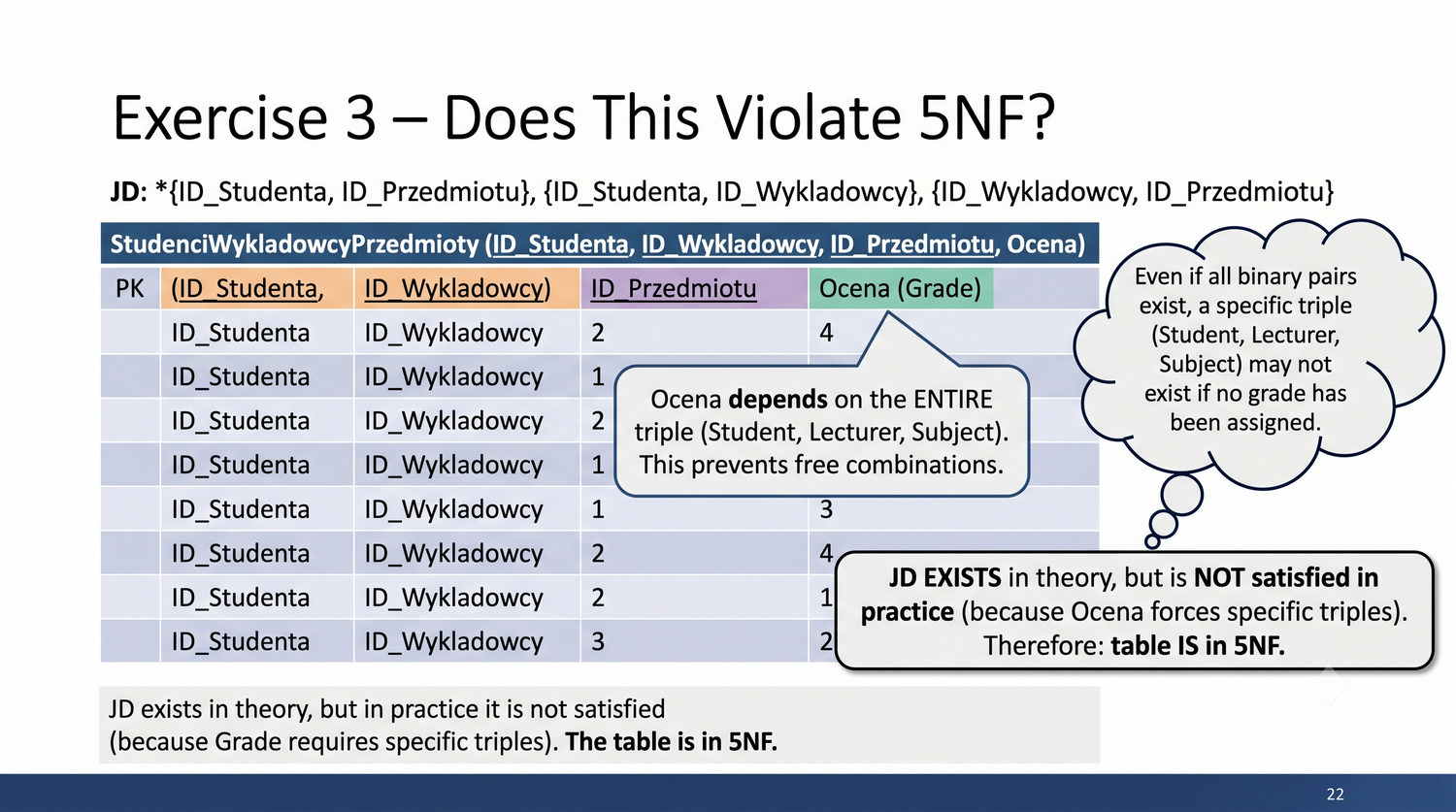
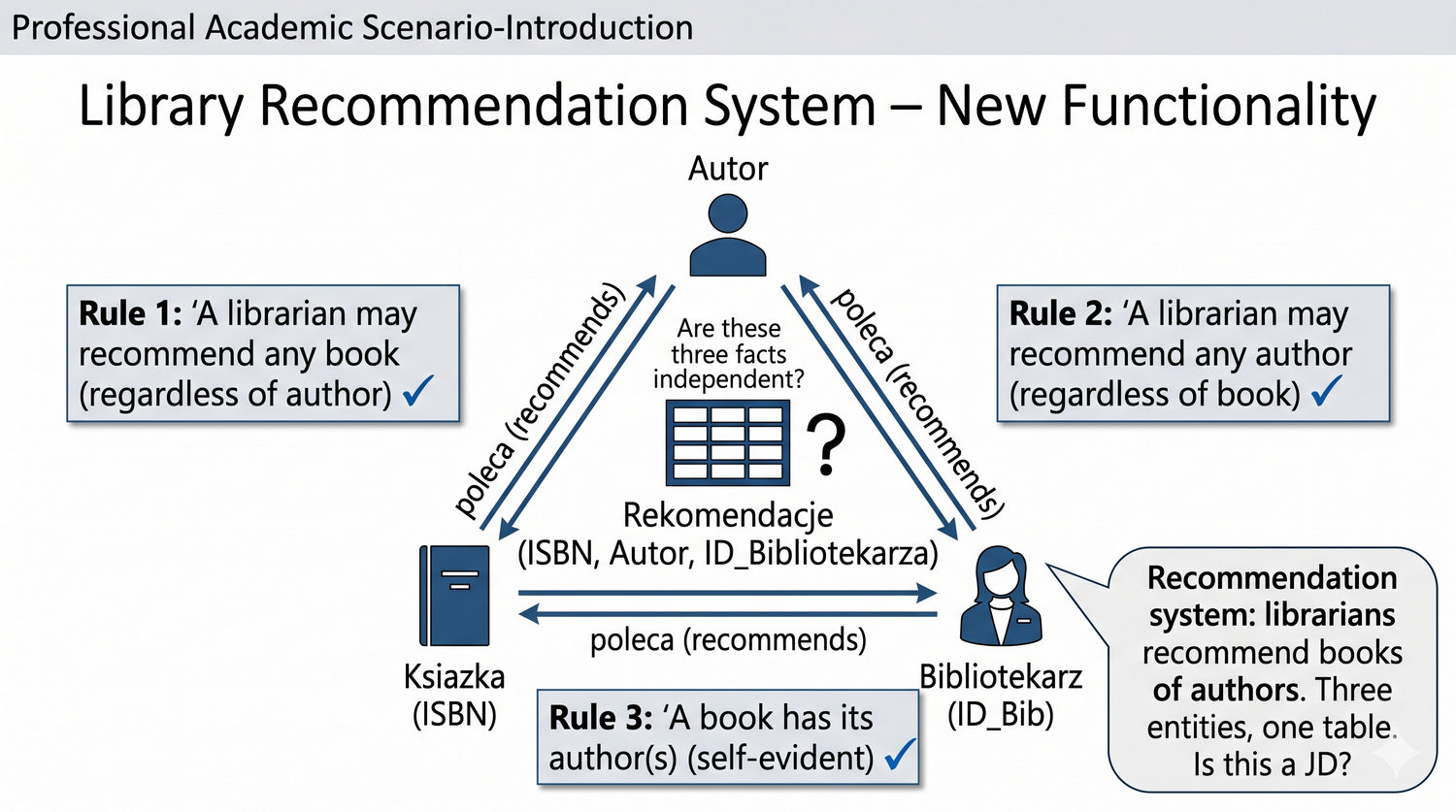
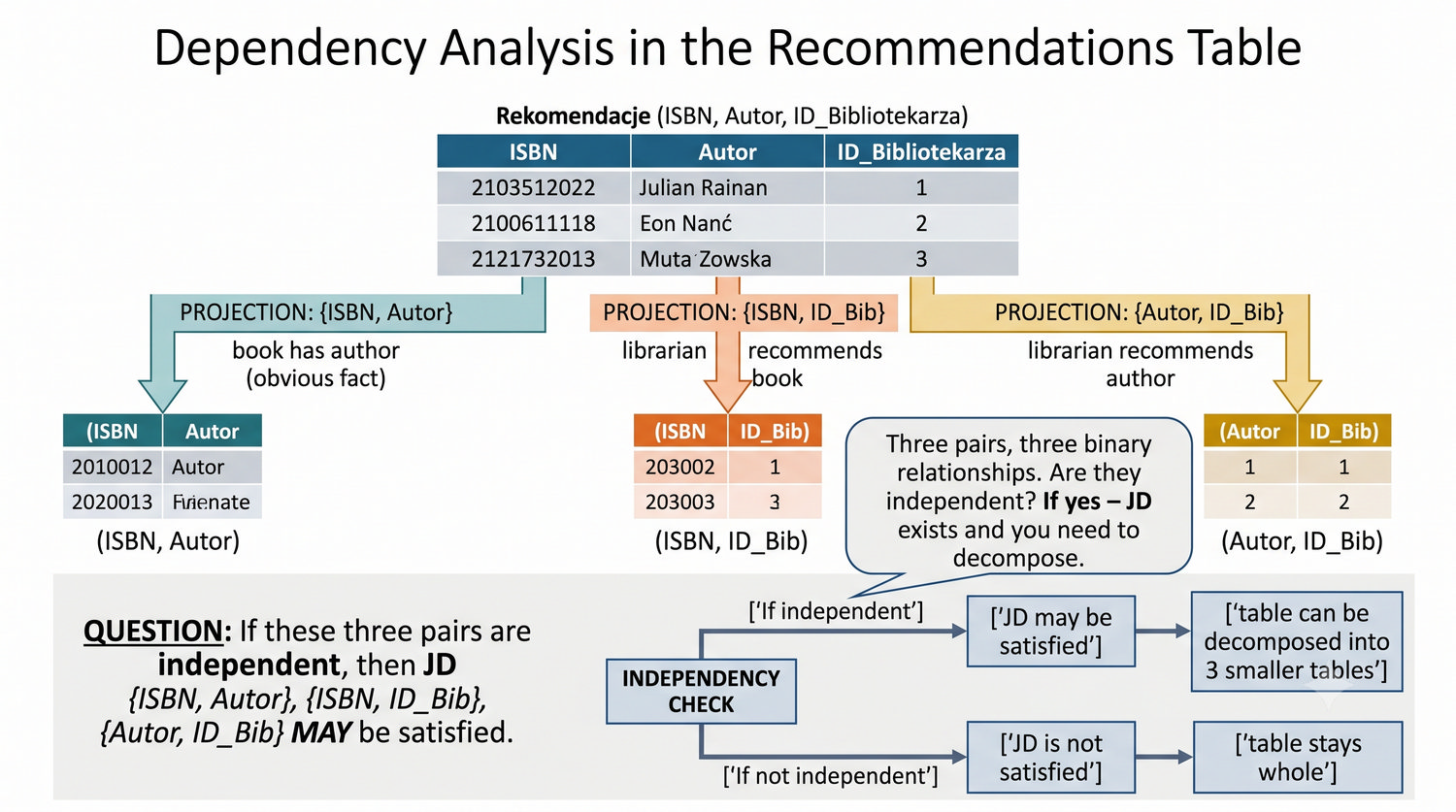
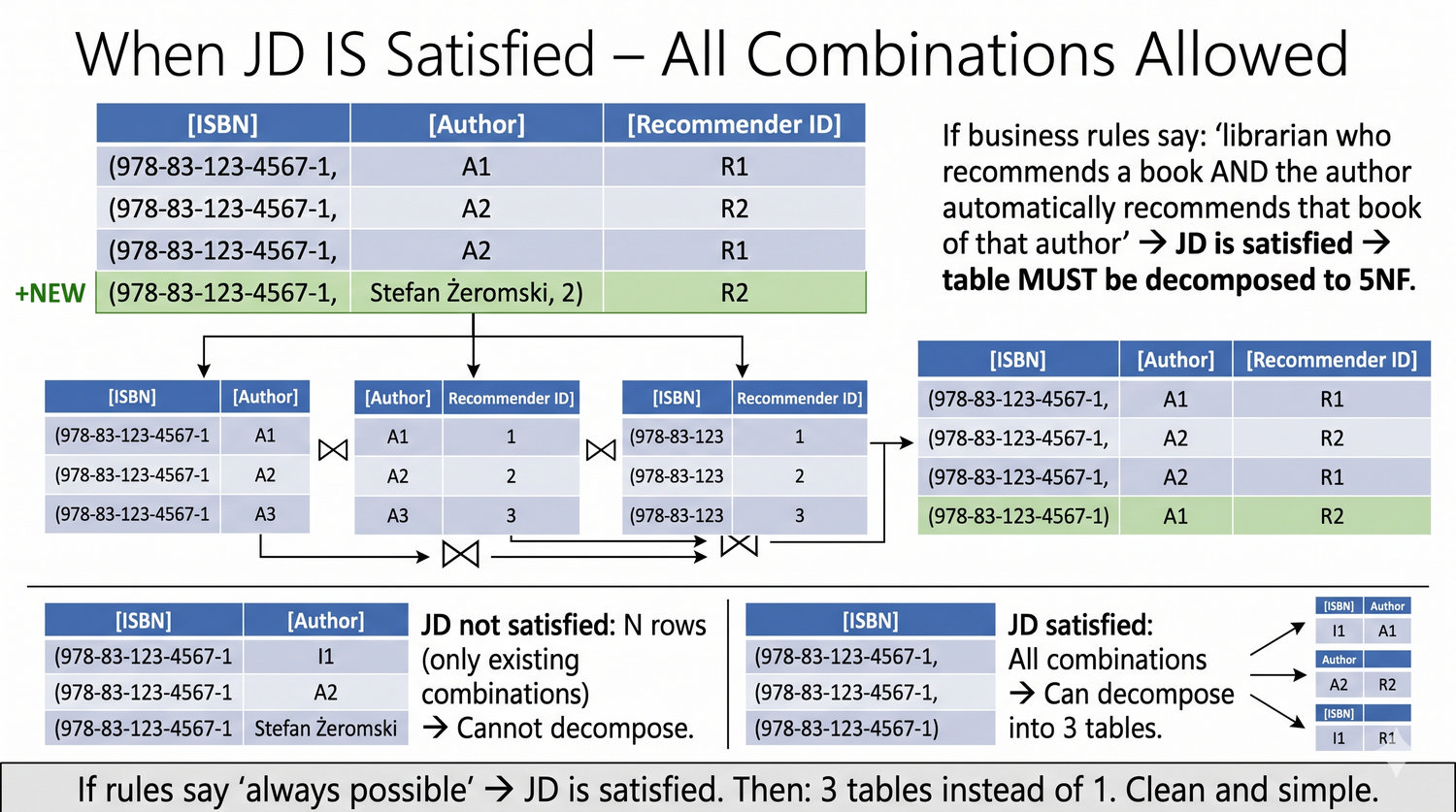
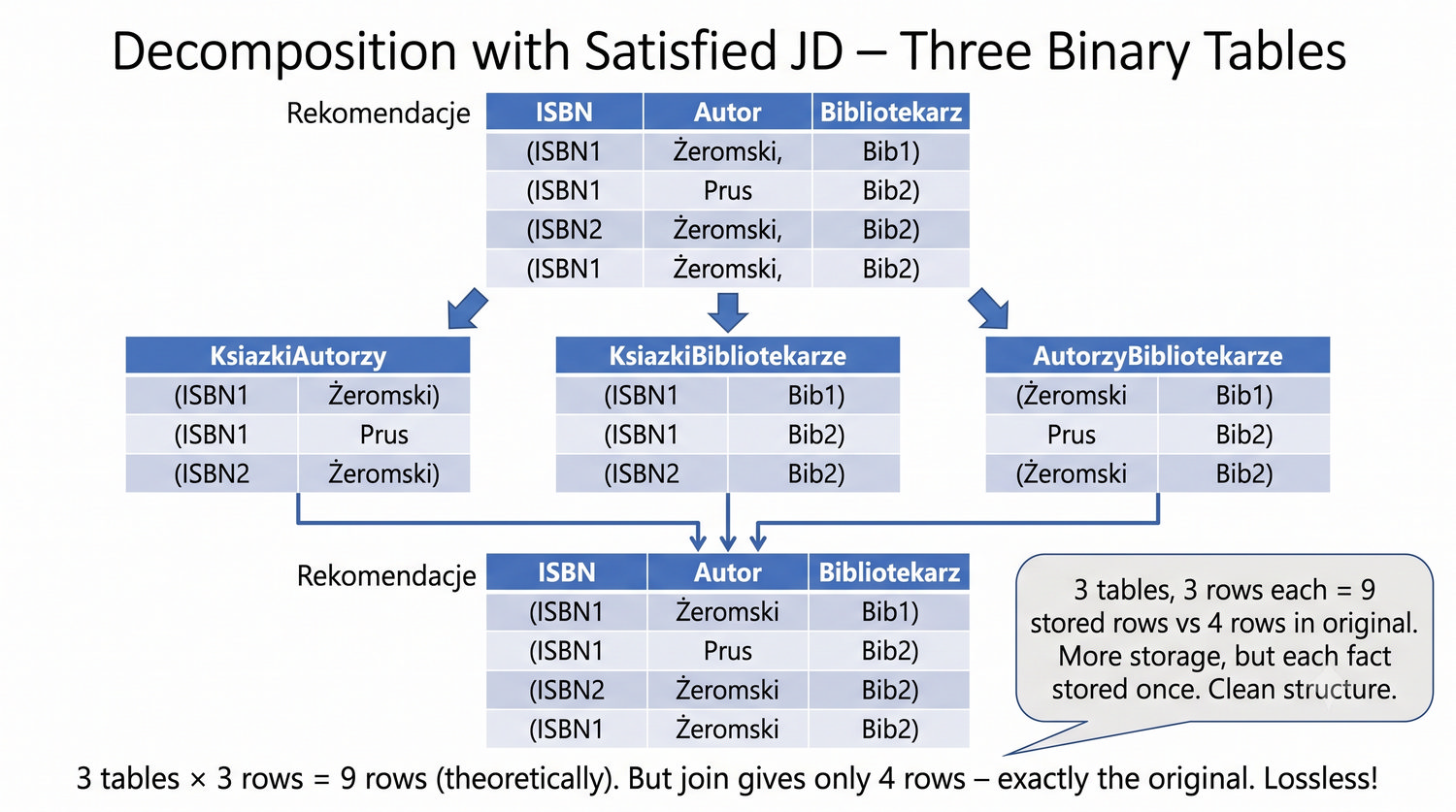
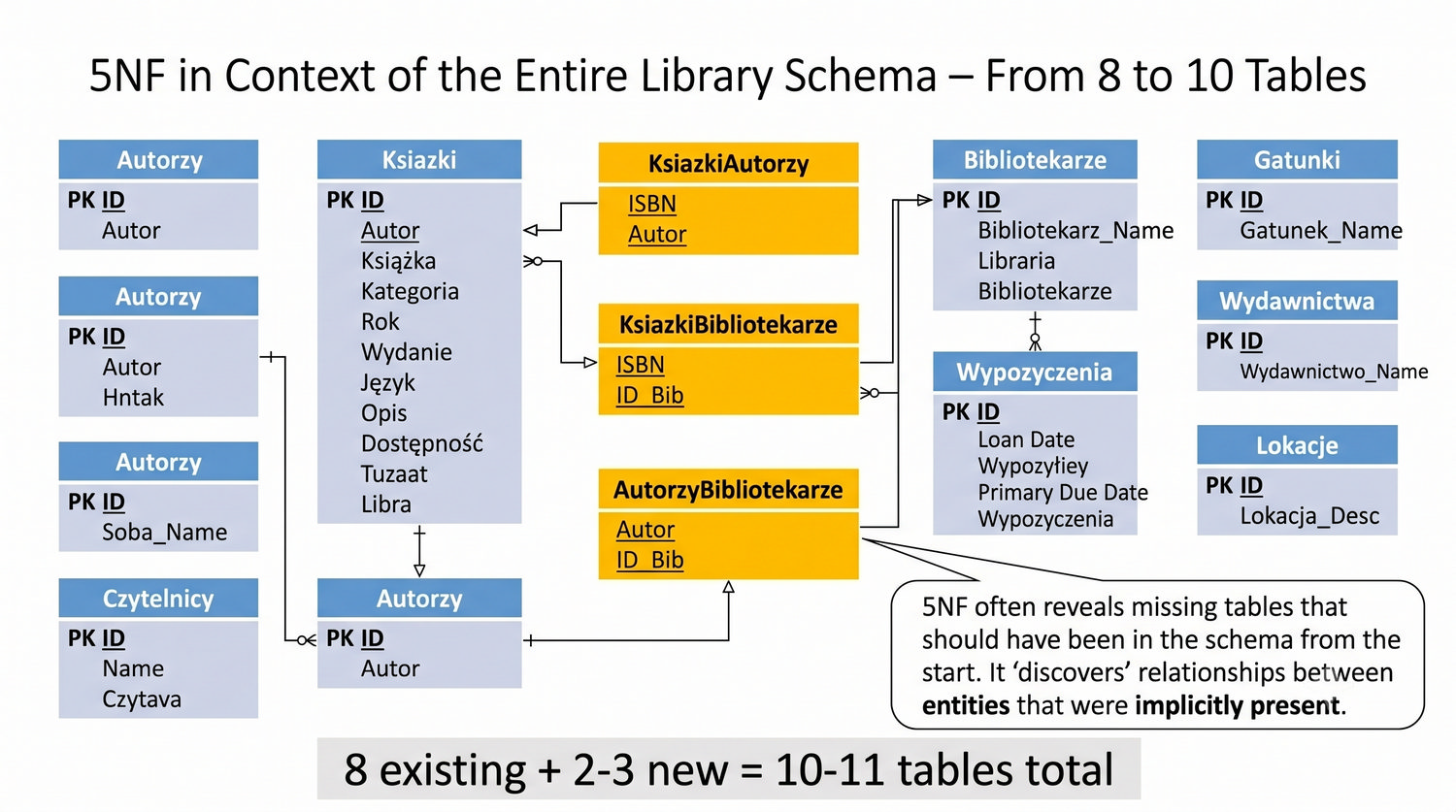
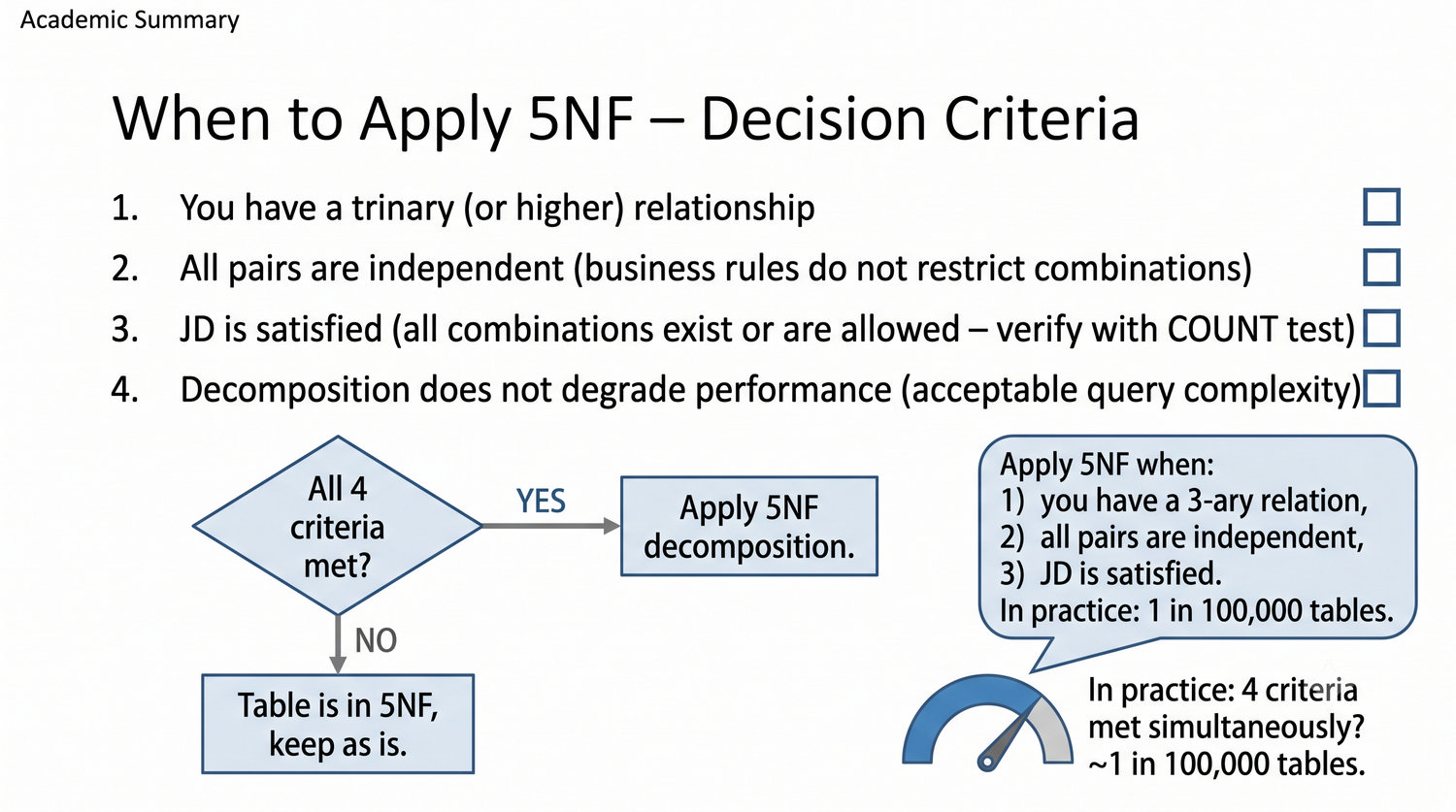
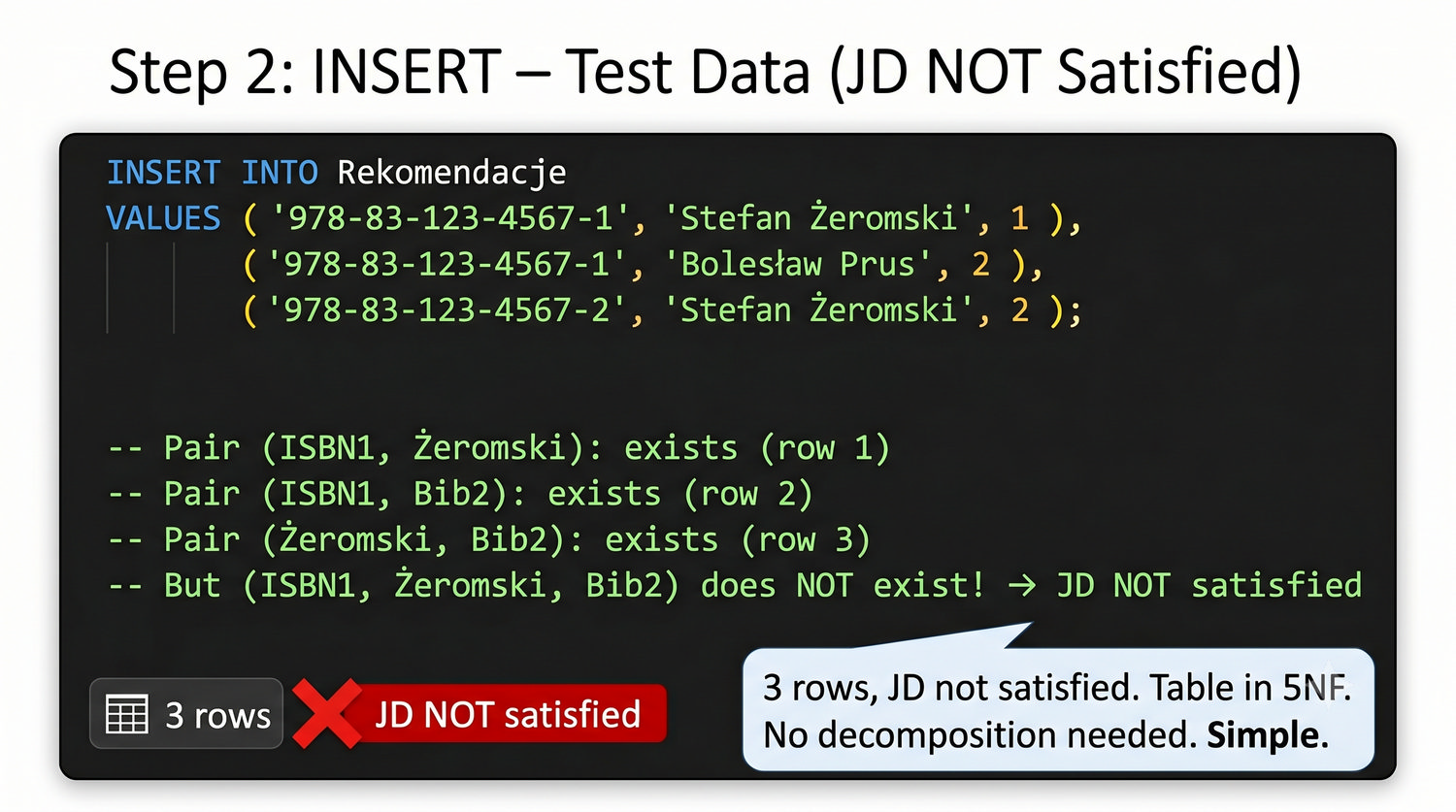
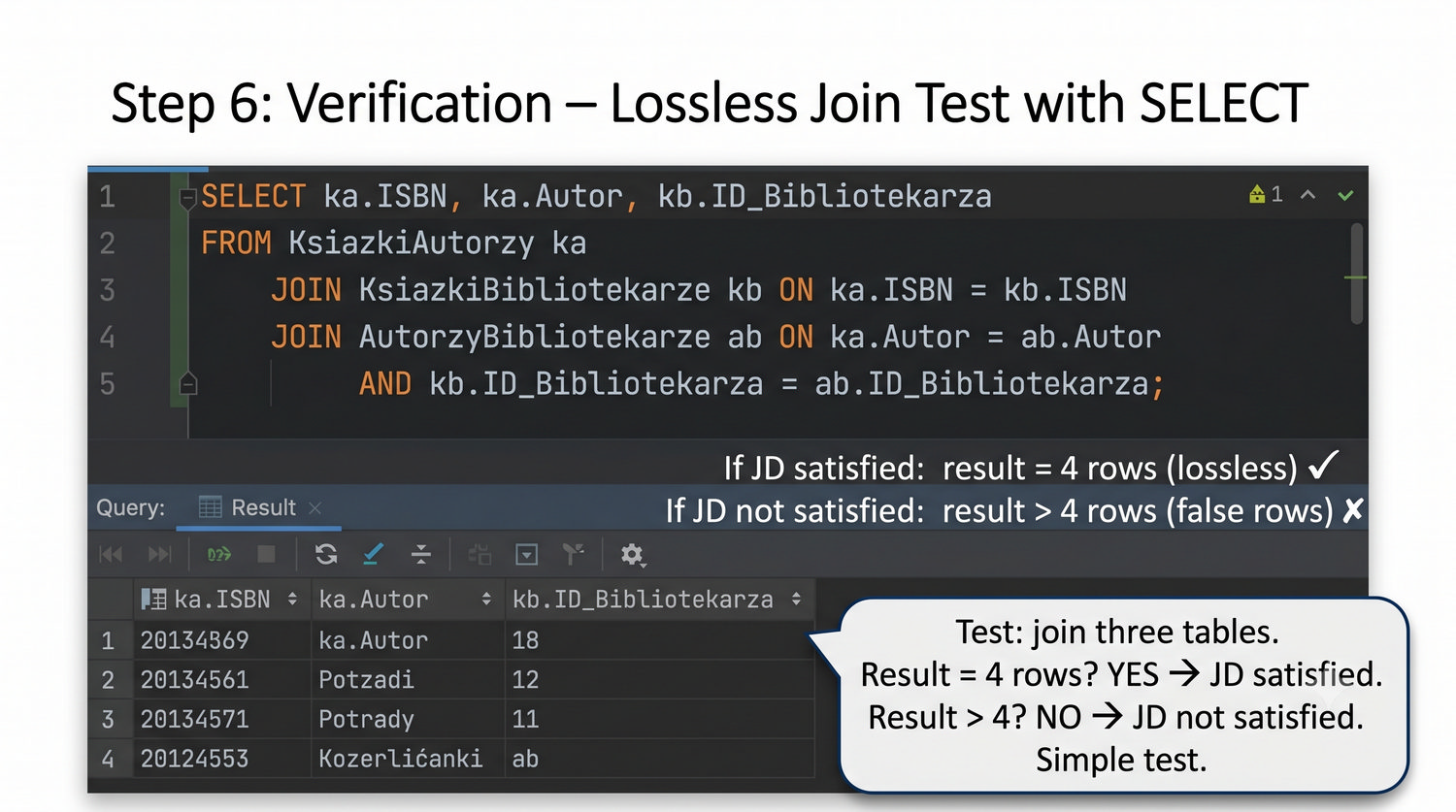
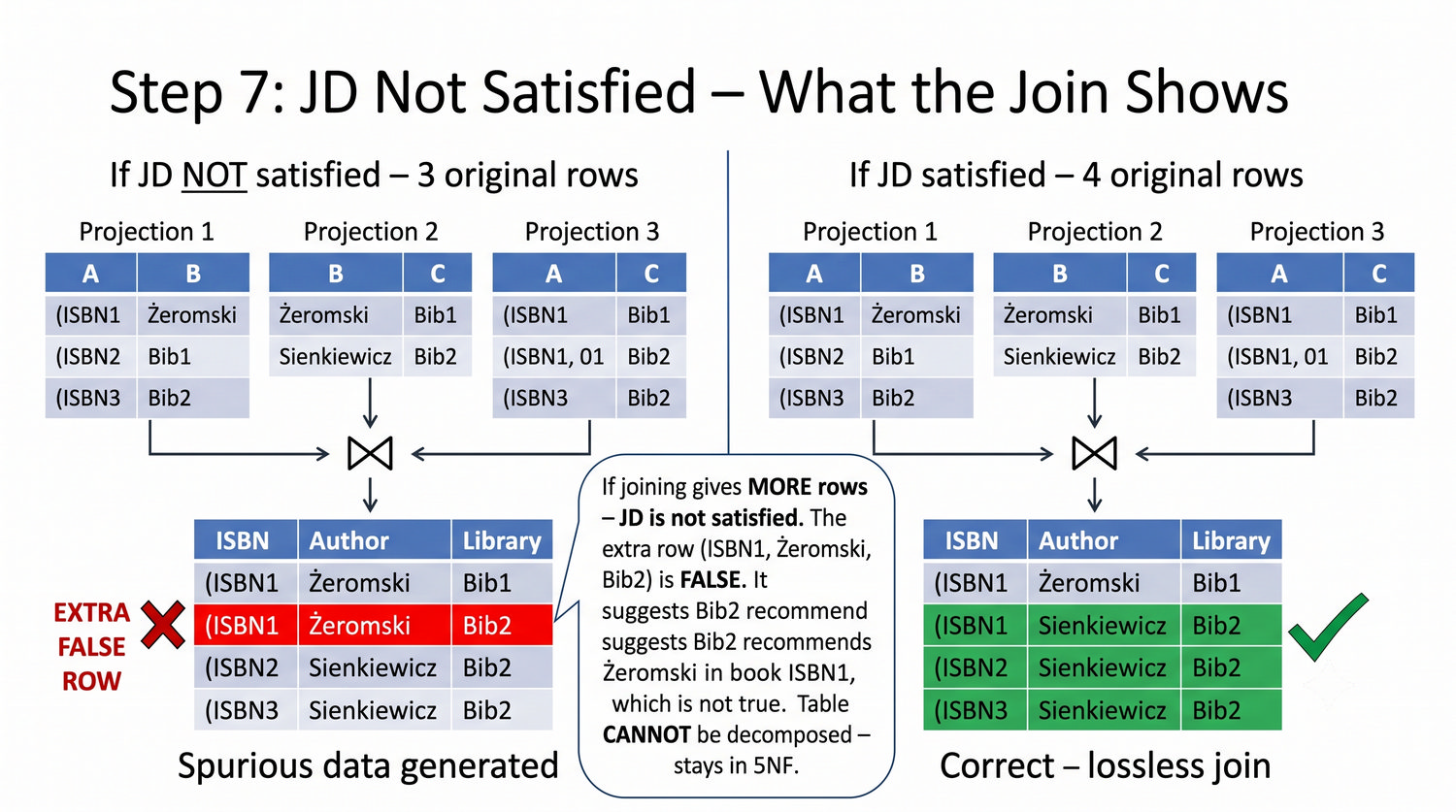
Ta prezentacja kończy cykl normalizacji na przykładzie systemu bibliotecznego. Wprowadza zależności złączeniowe (JD) – ostatnią i najrzadszą formę normalizacji w modelu relacyjnym.
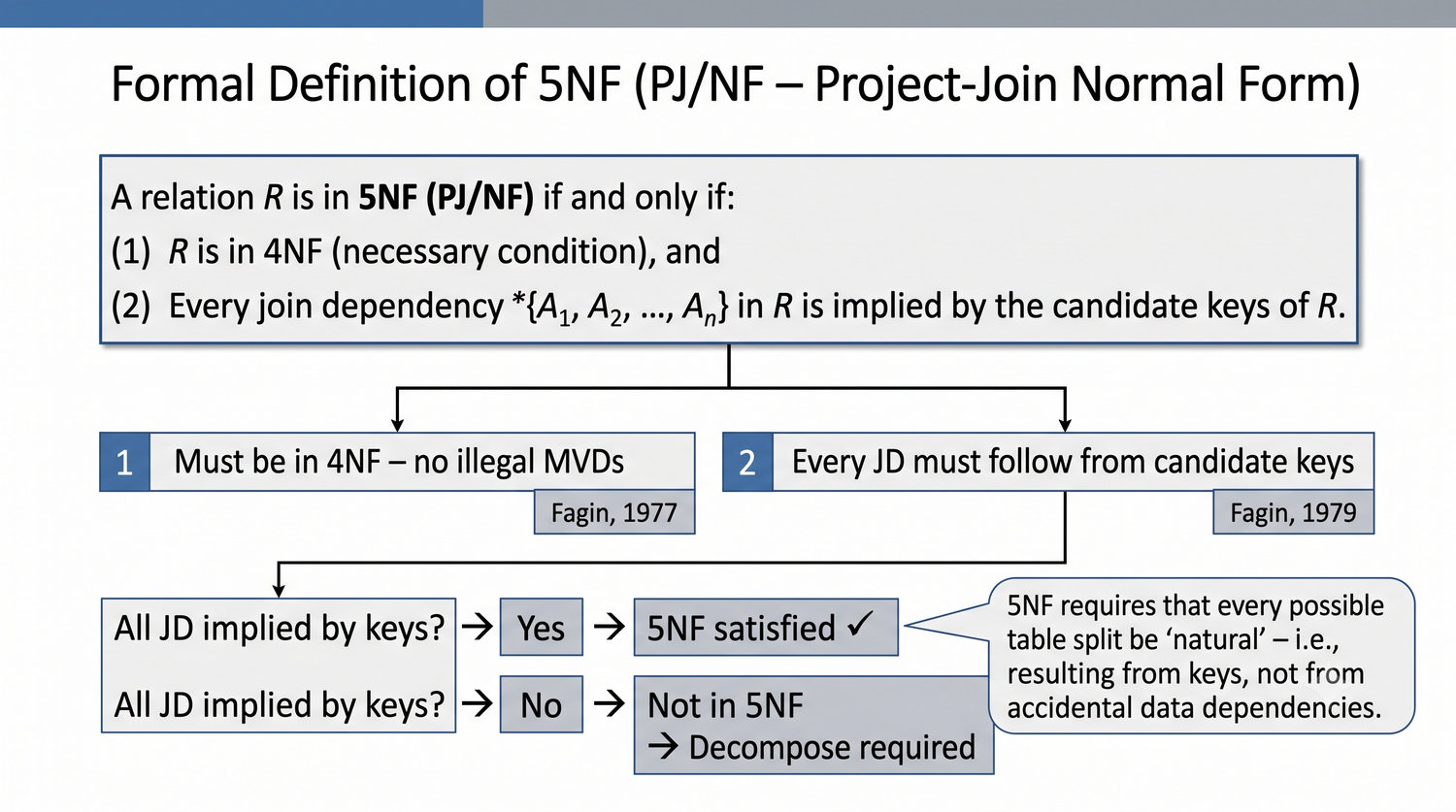
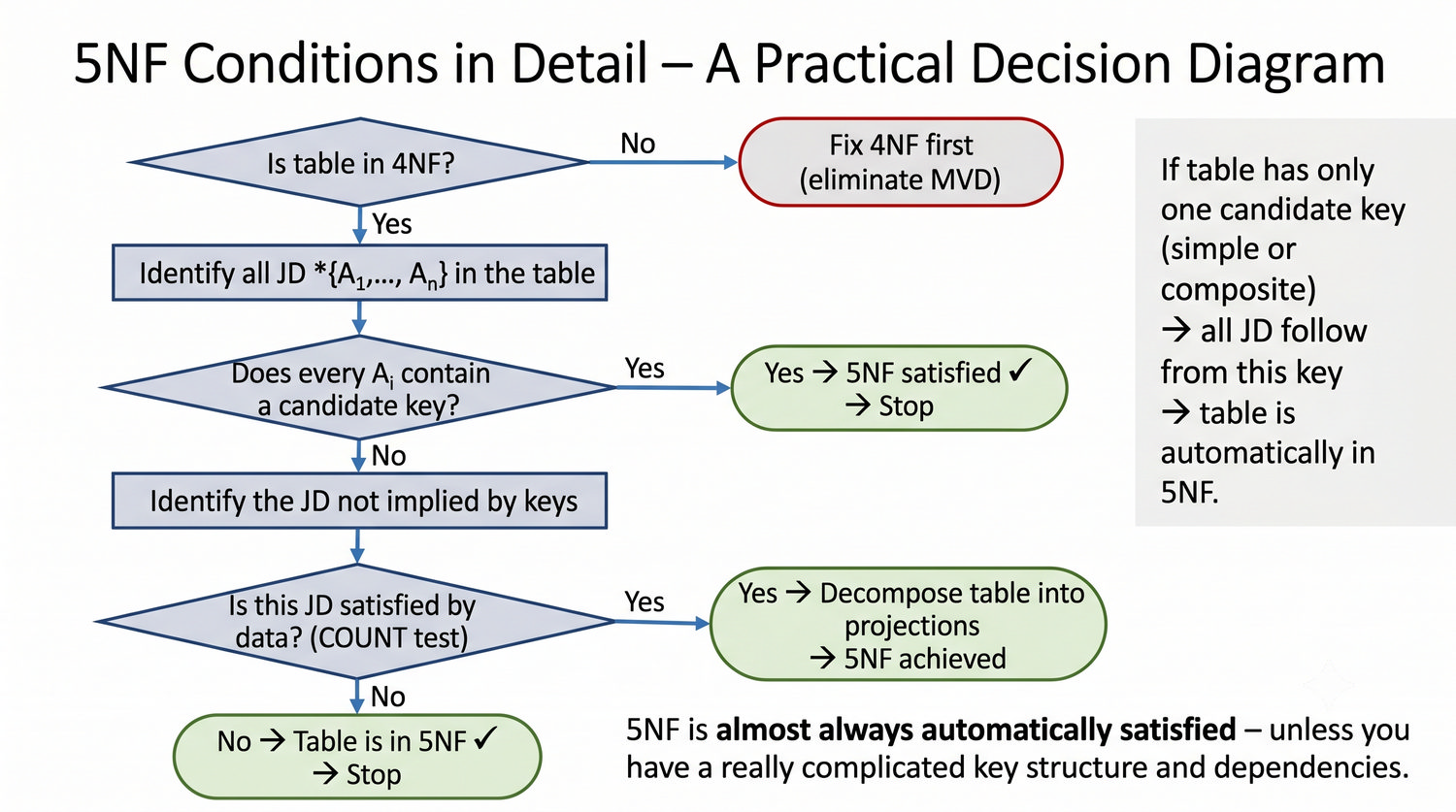
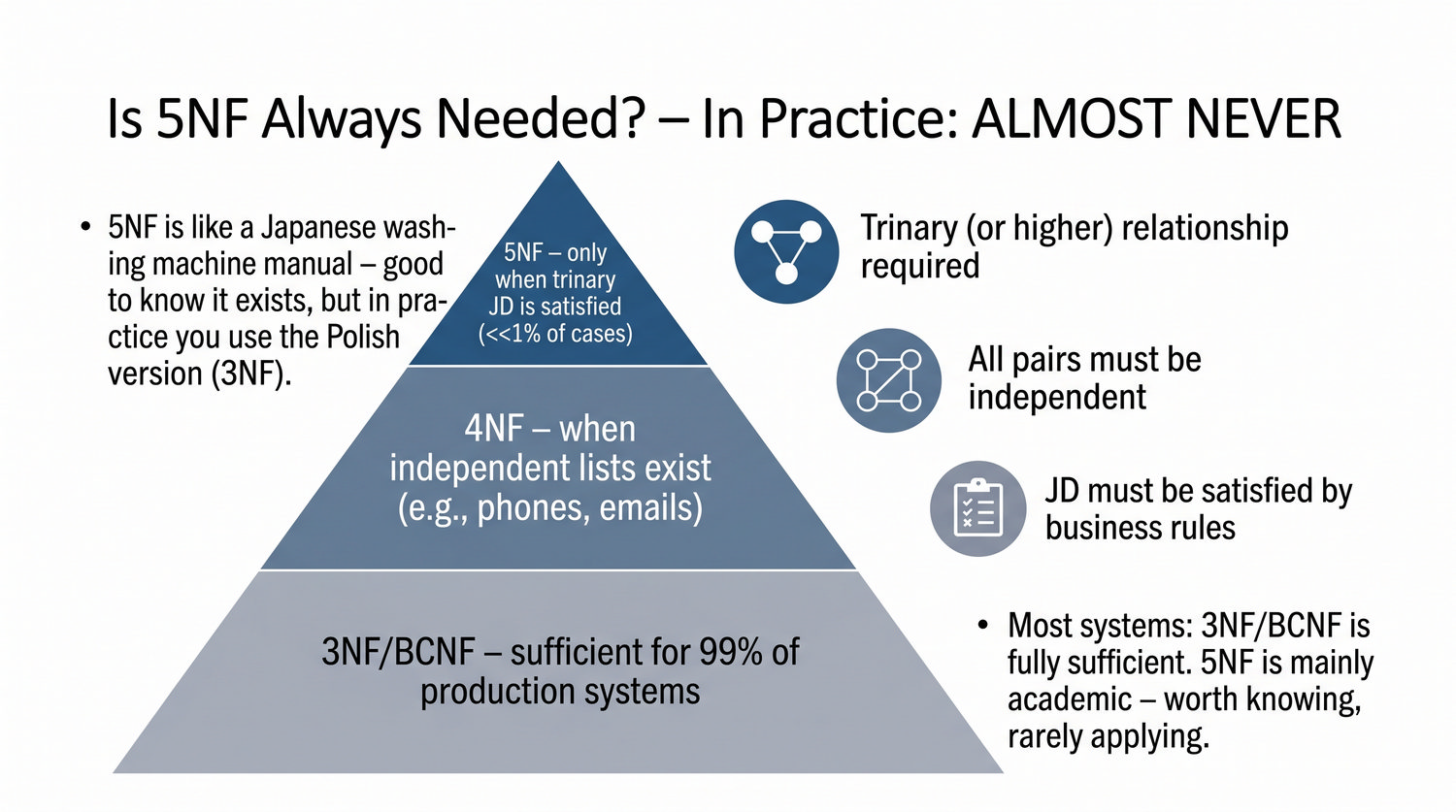
5NF została zdefiniowana przez Ronalda Fagina w 1979 roku. To najwyższa forma normalizacji w modelu relacyjnym – kropka nad 'i'.