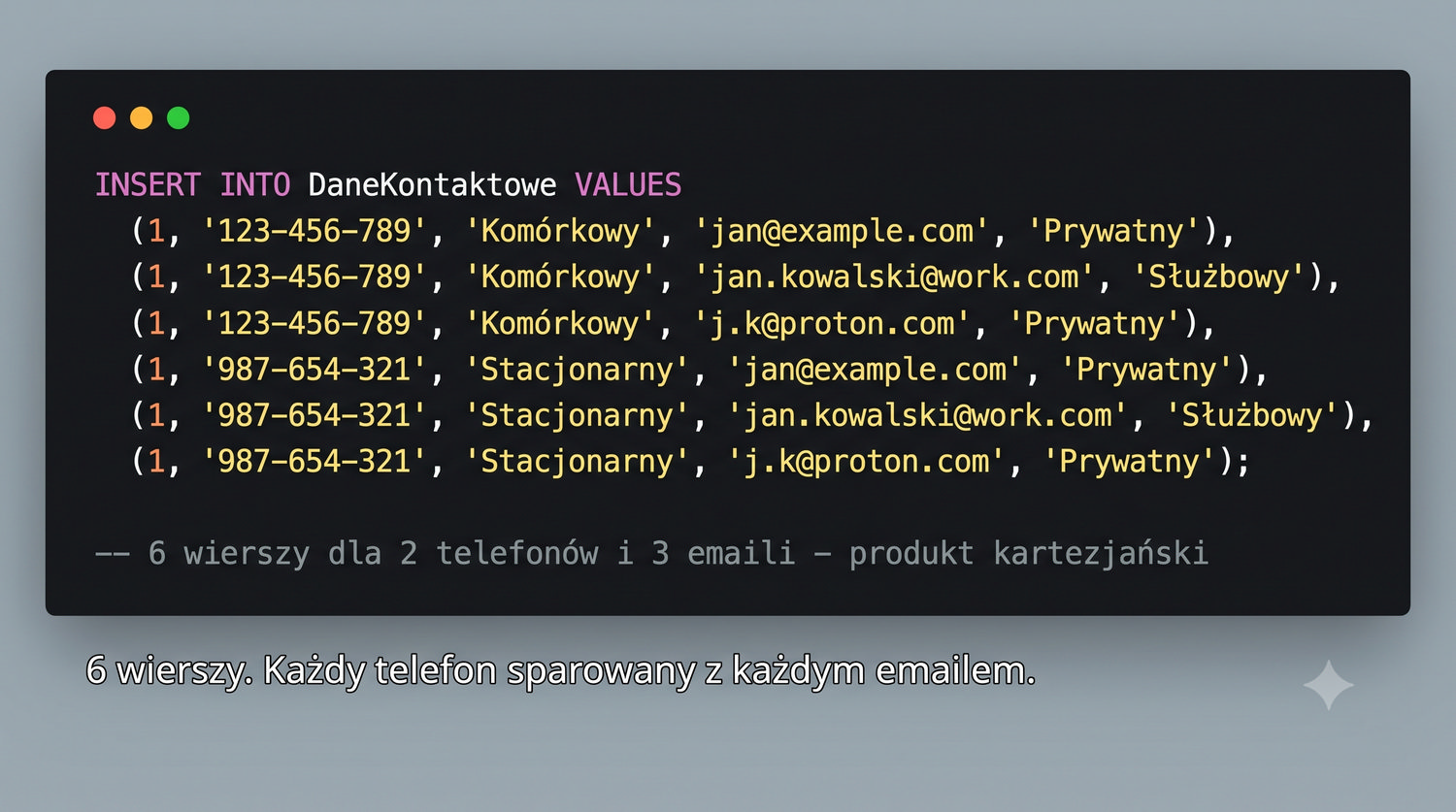
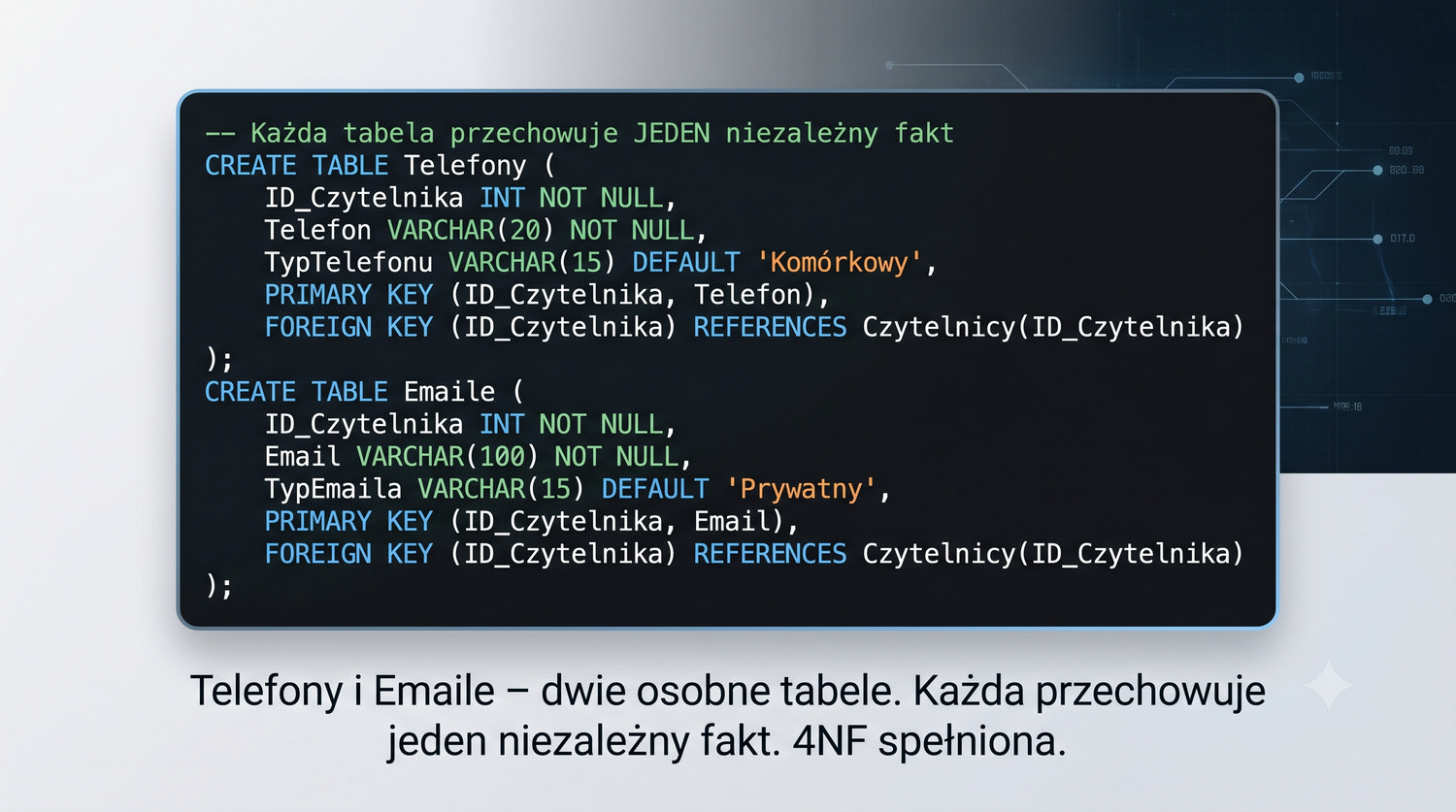
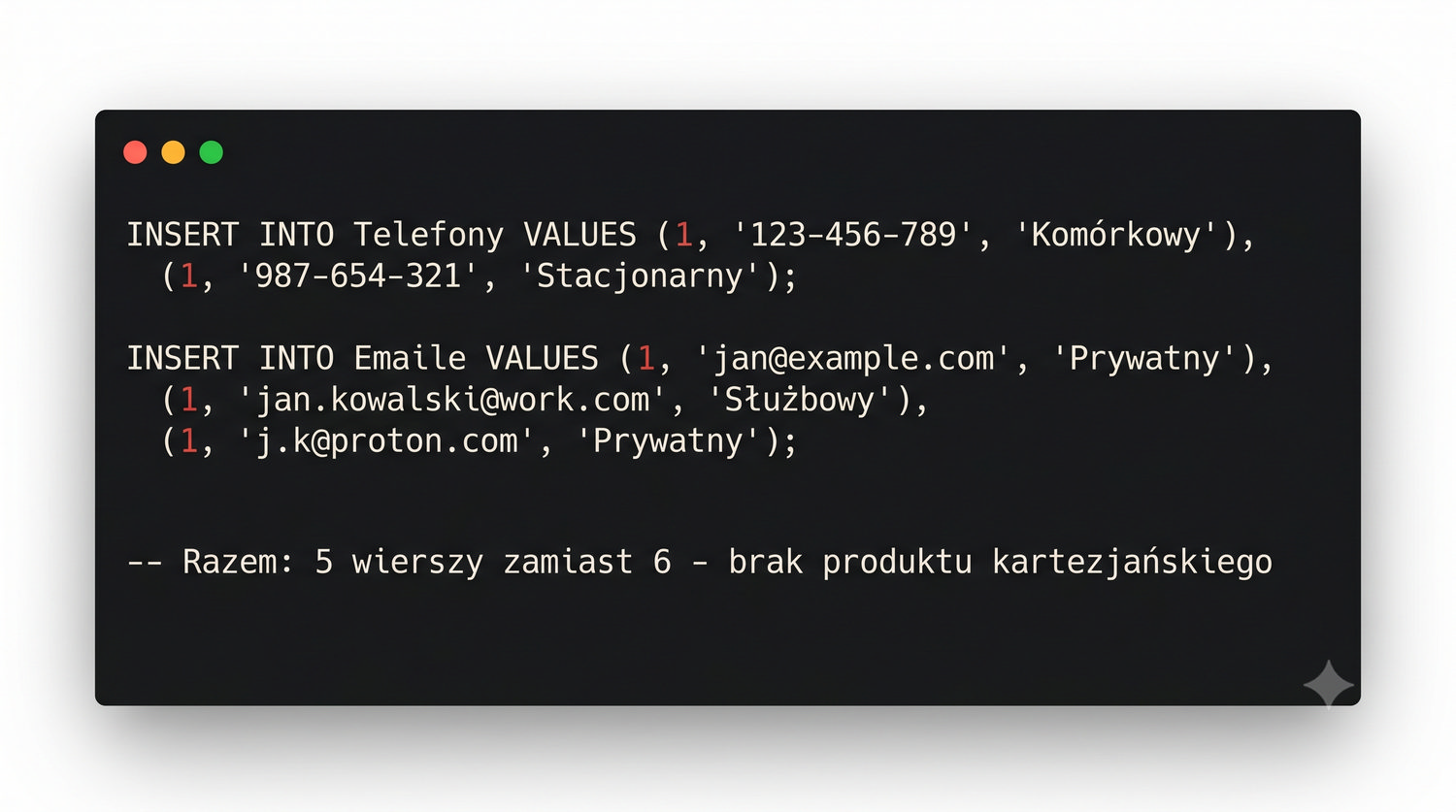
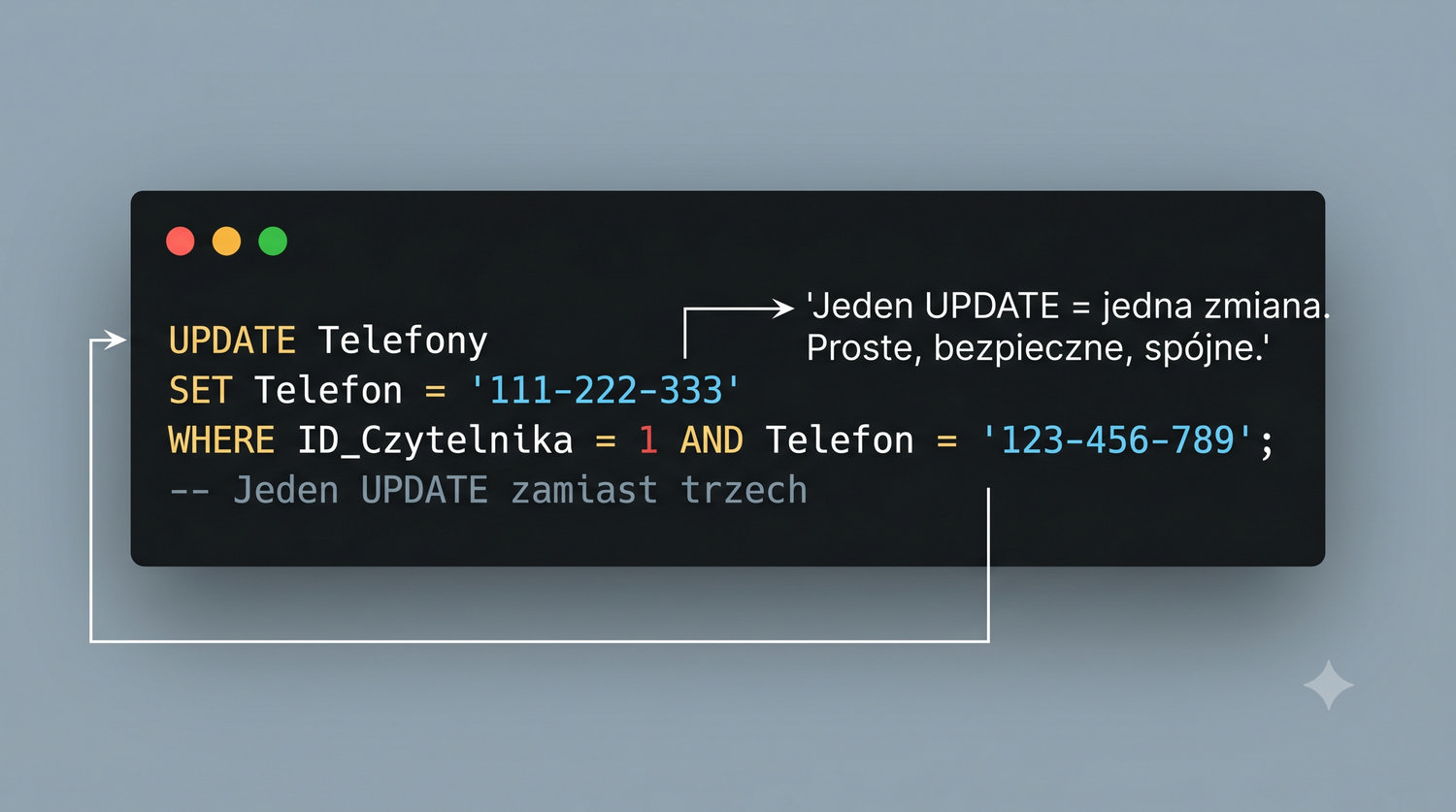
Eliminacja zależności wielowartościowych – gdy BCNF to za mało
Zakładamy znajomość 1NF, 2NF, 3NF i BCNF.
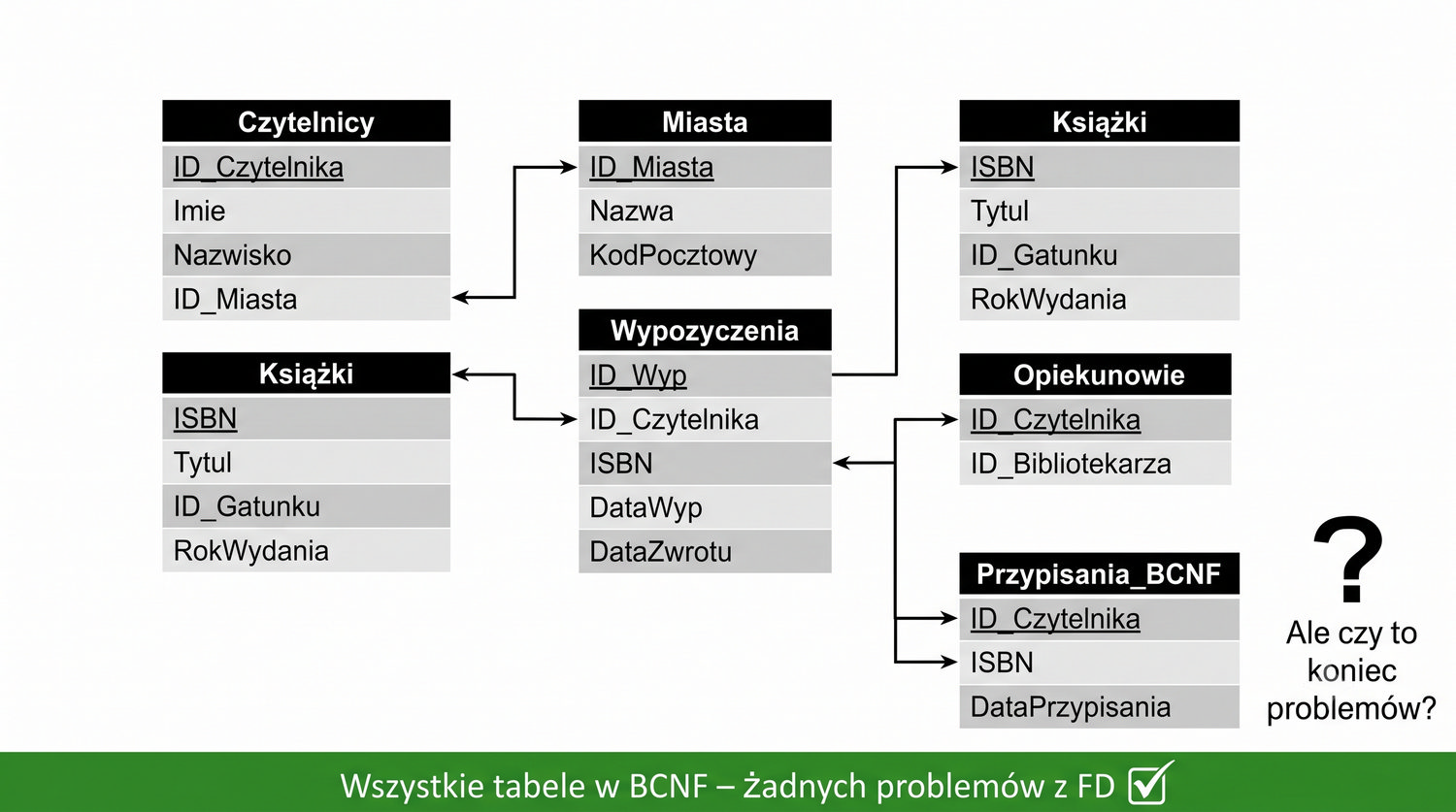
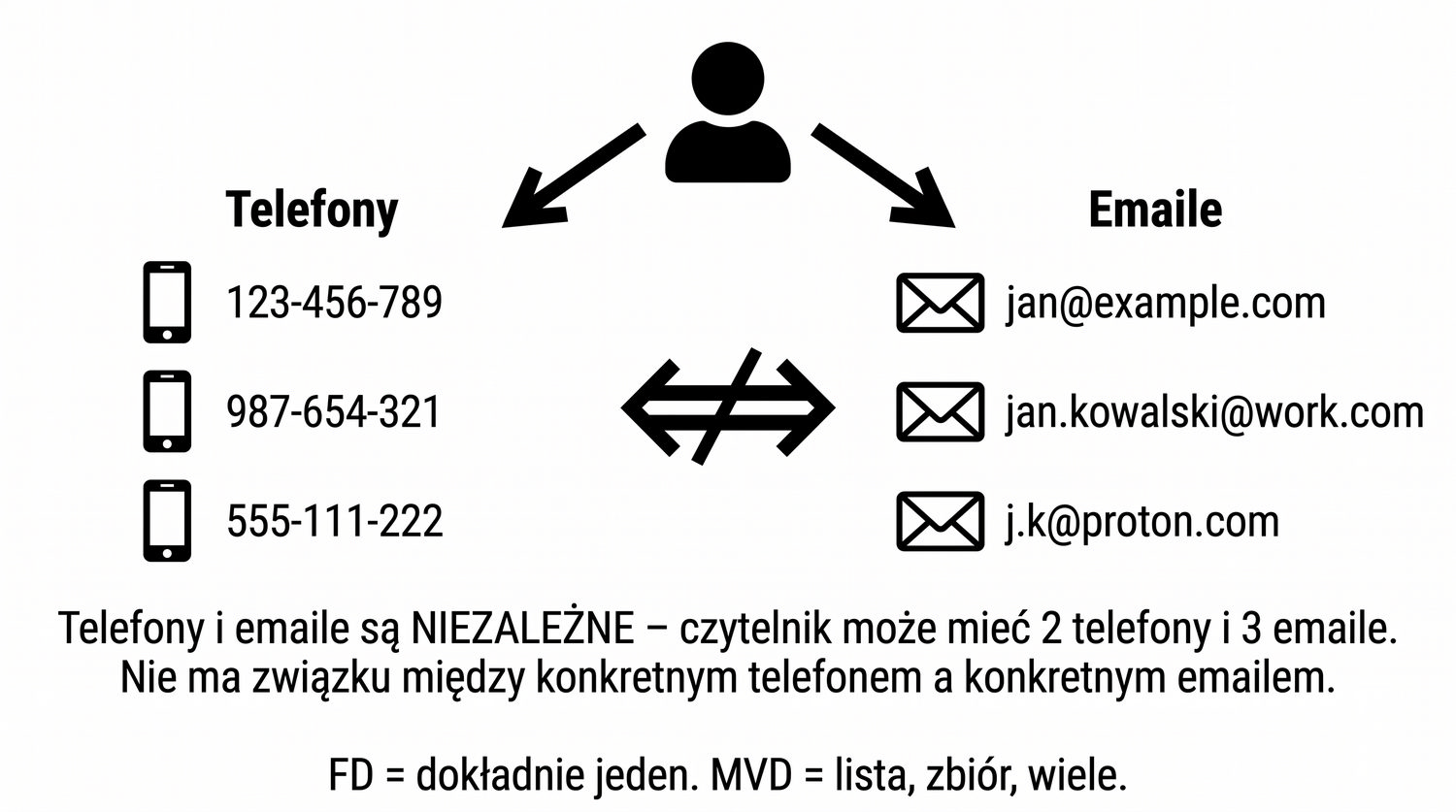
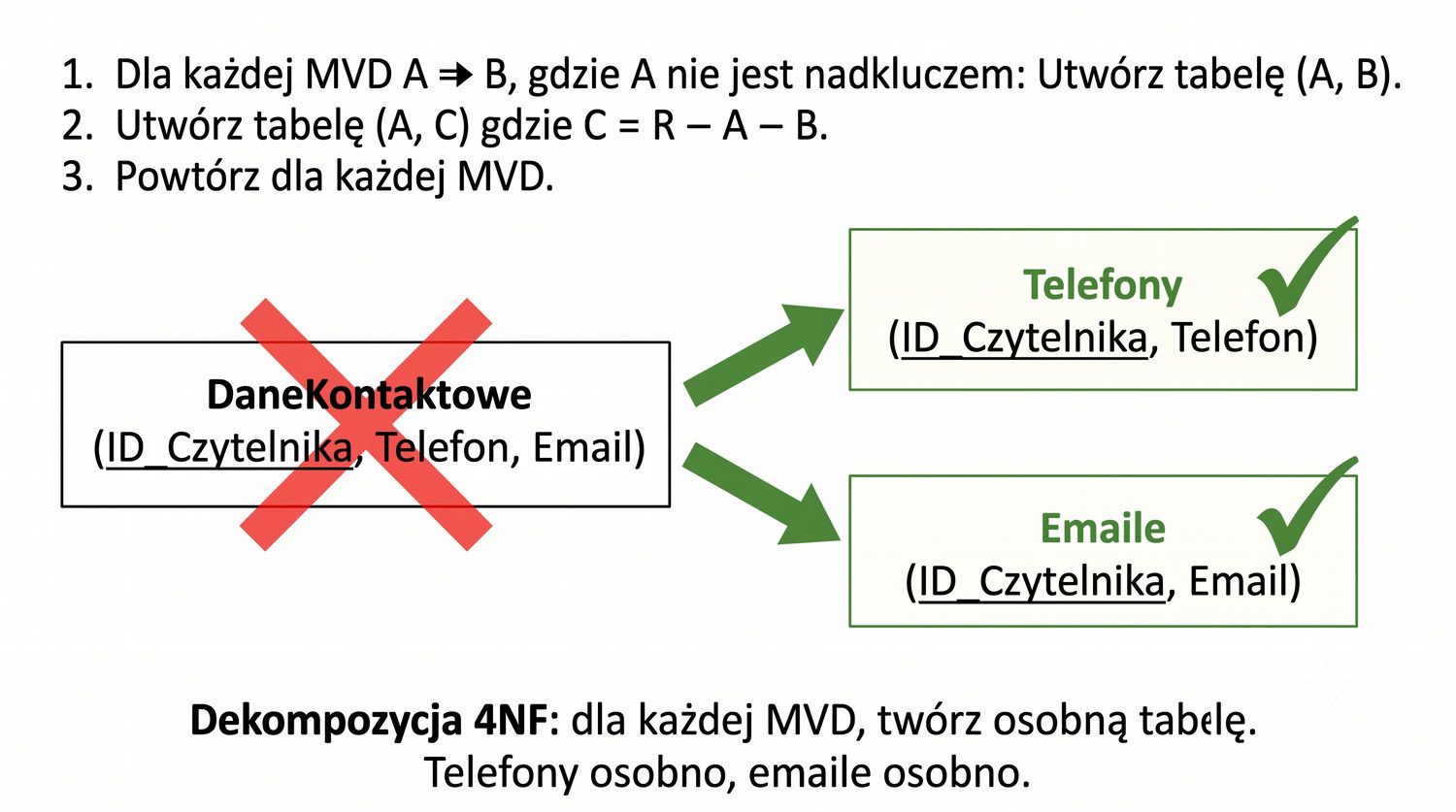
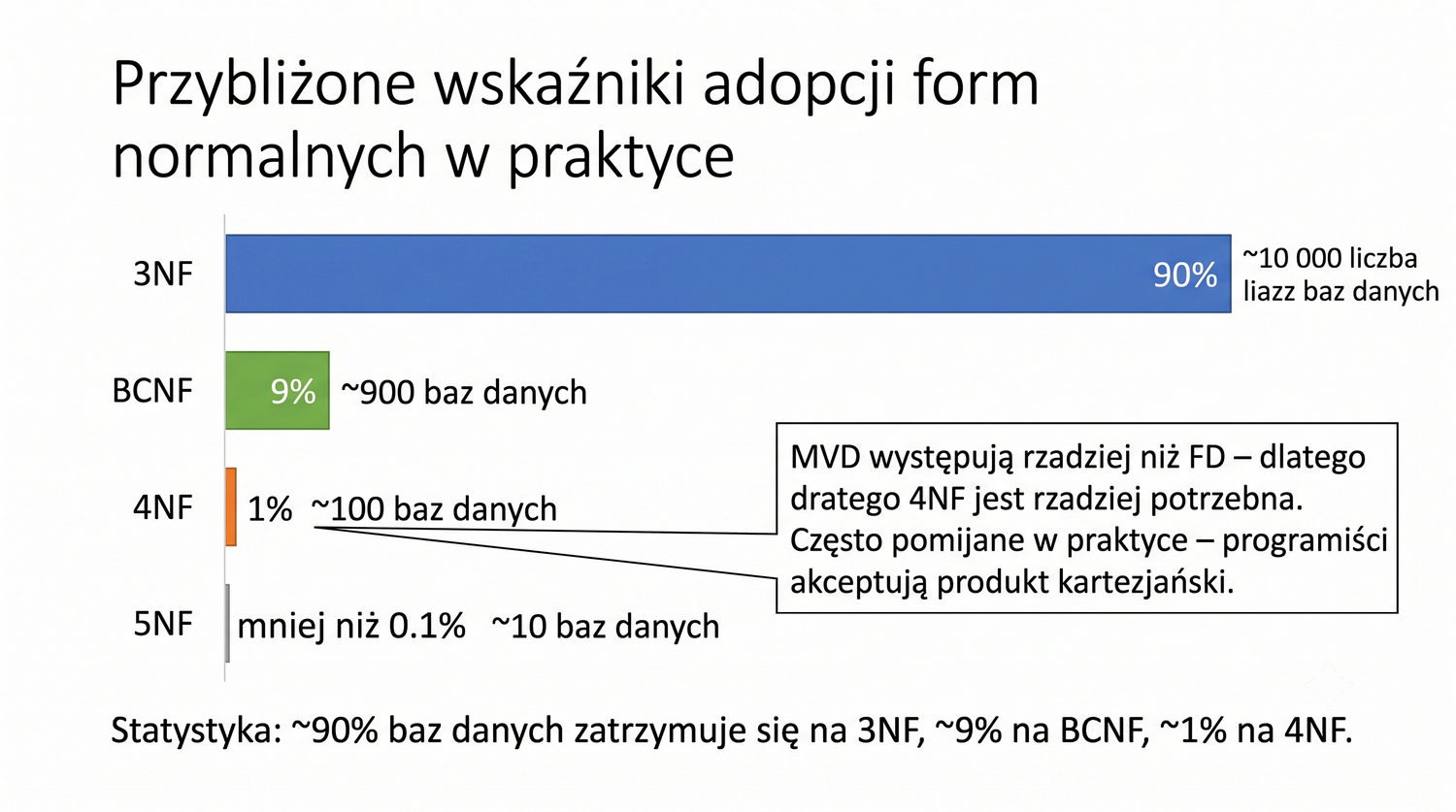
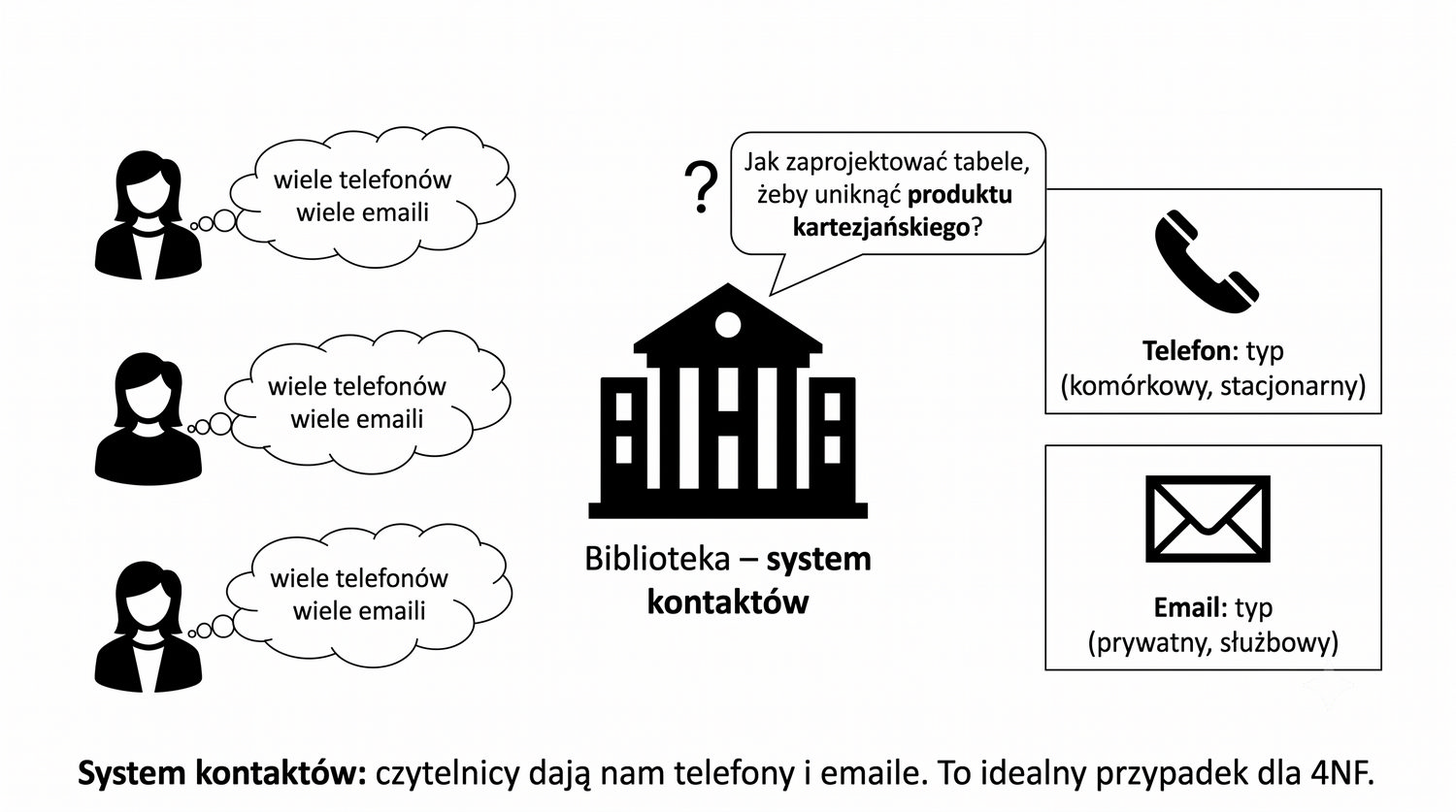
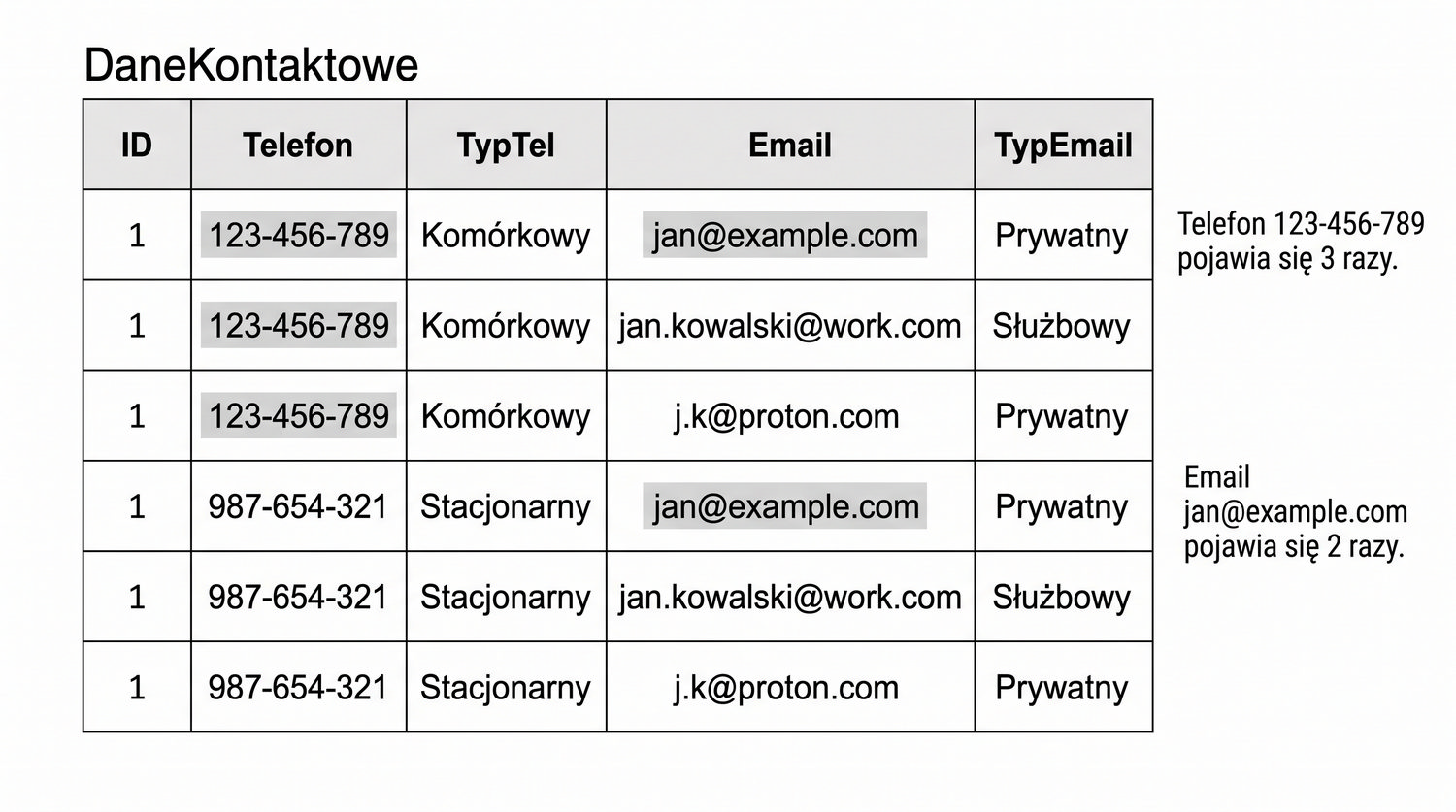
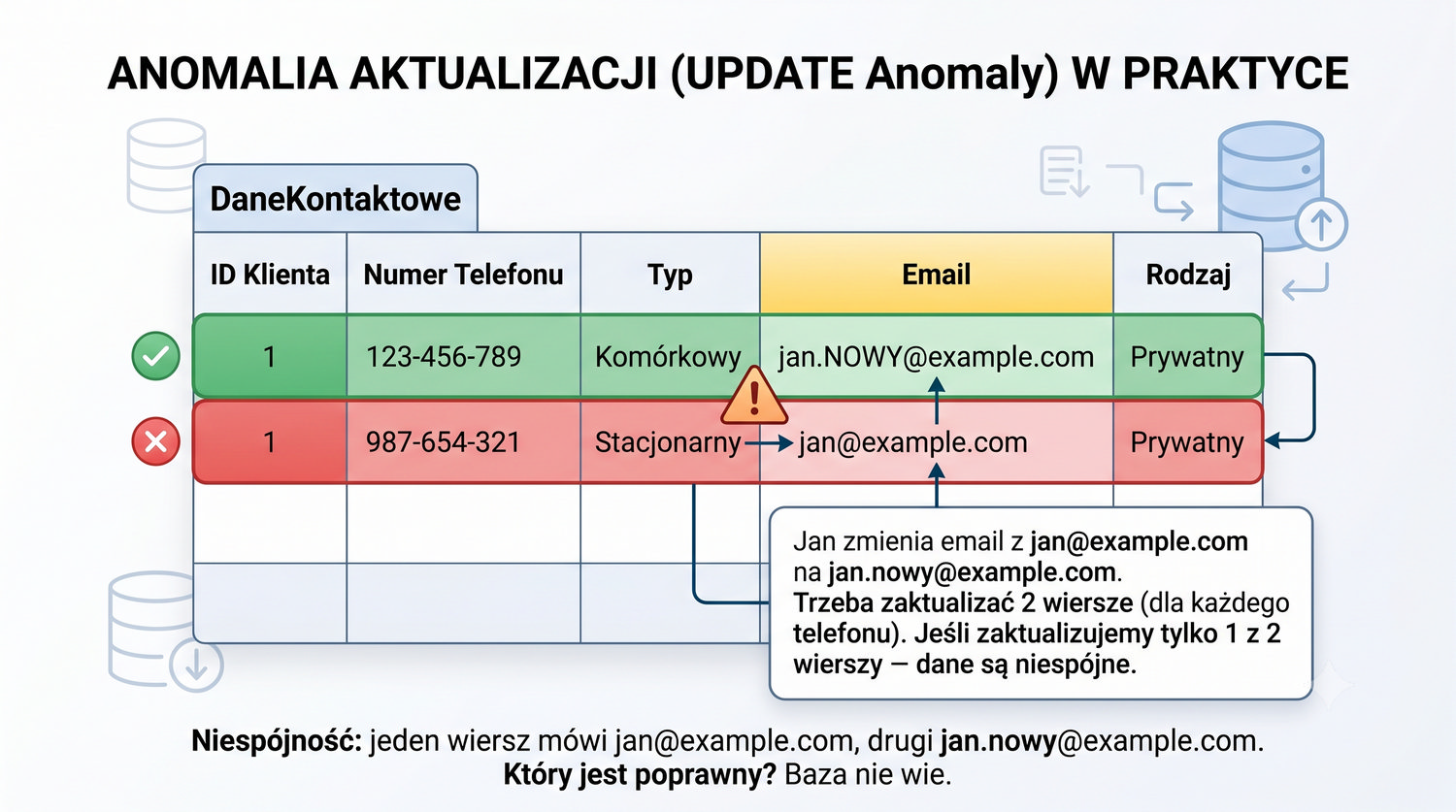
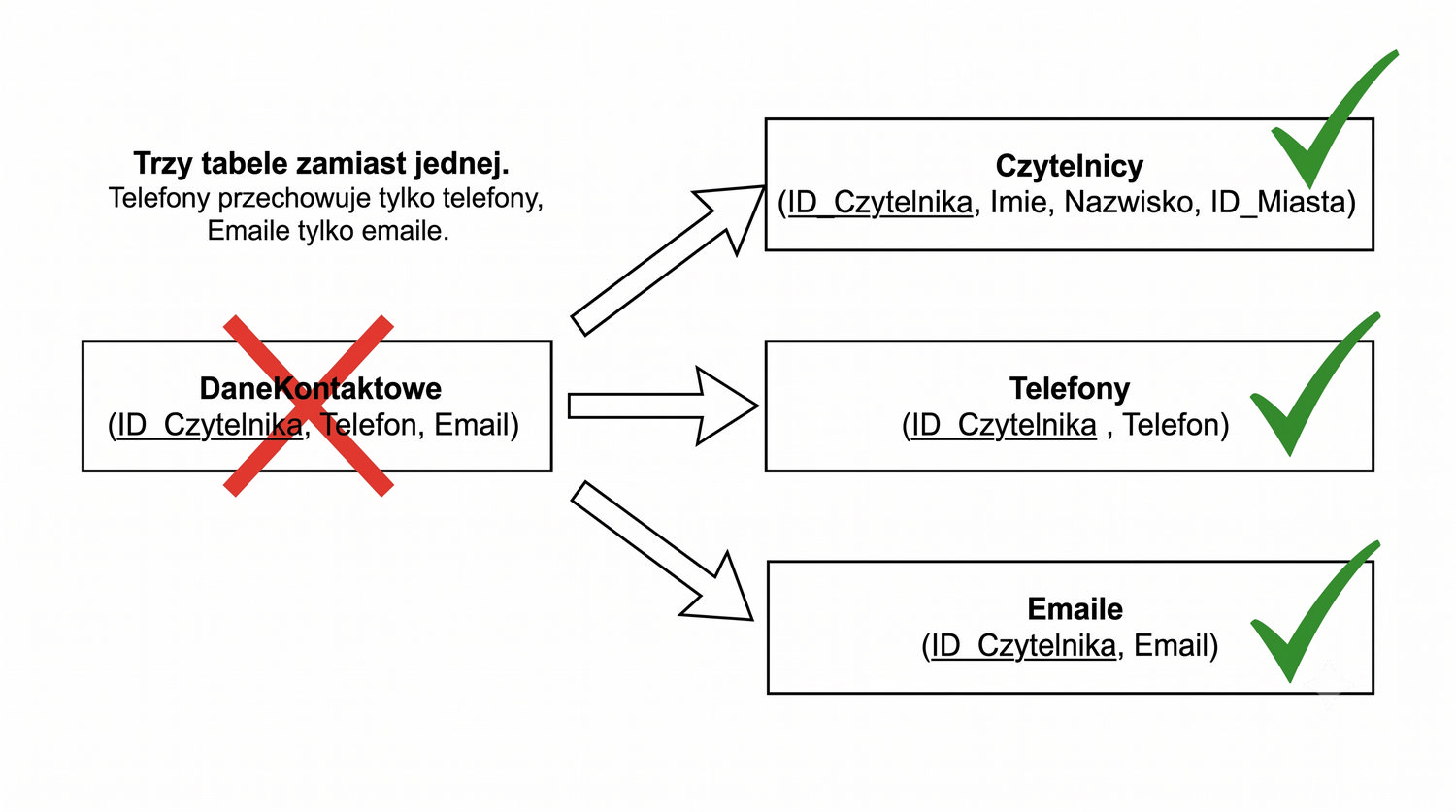
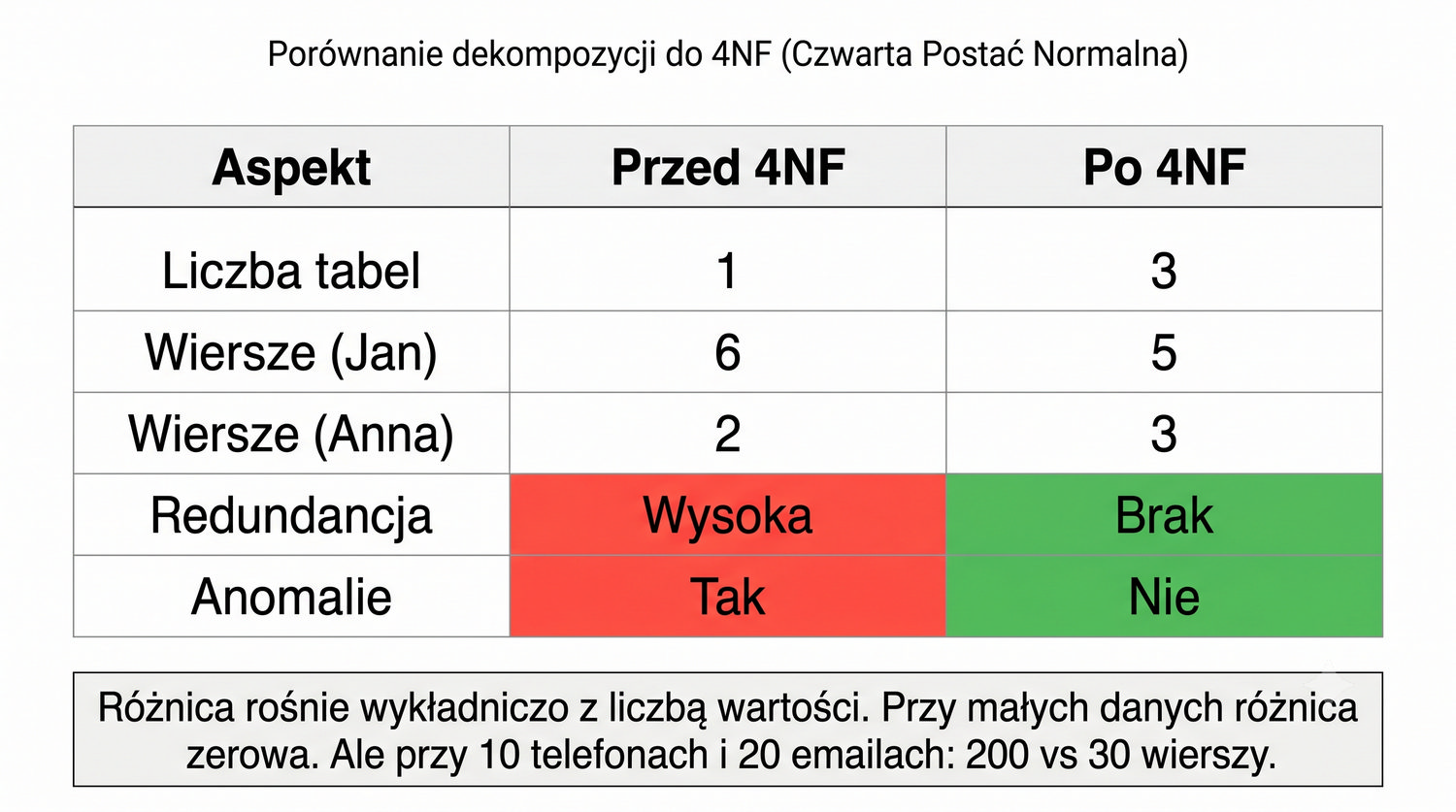
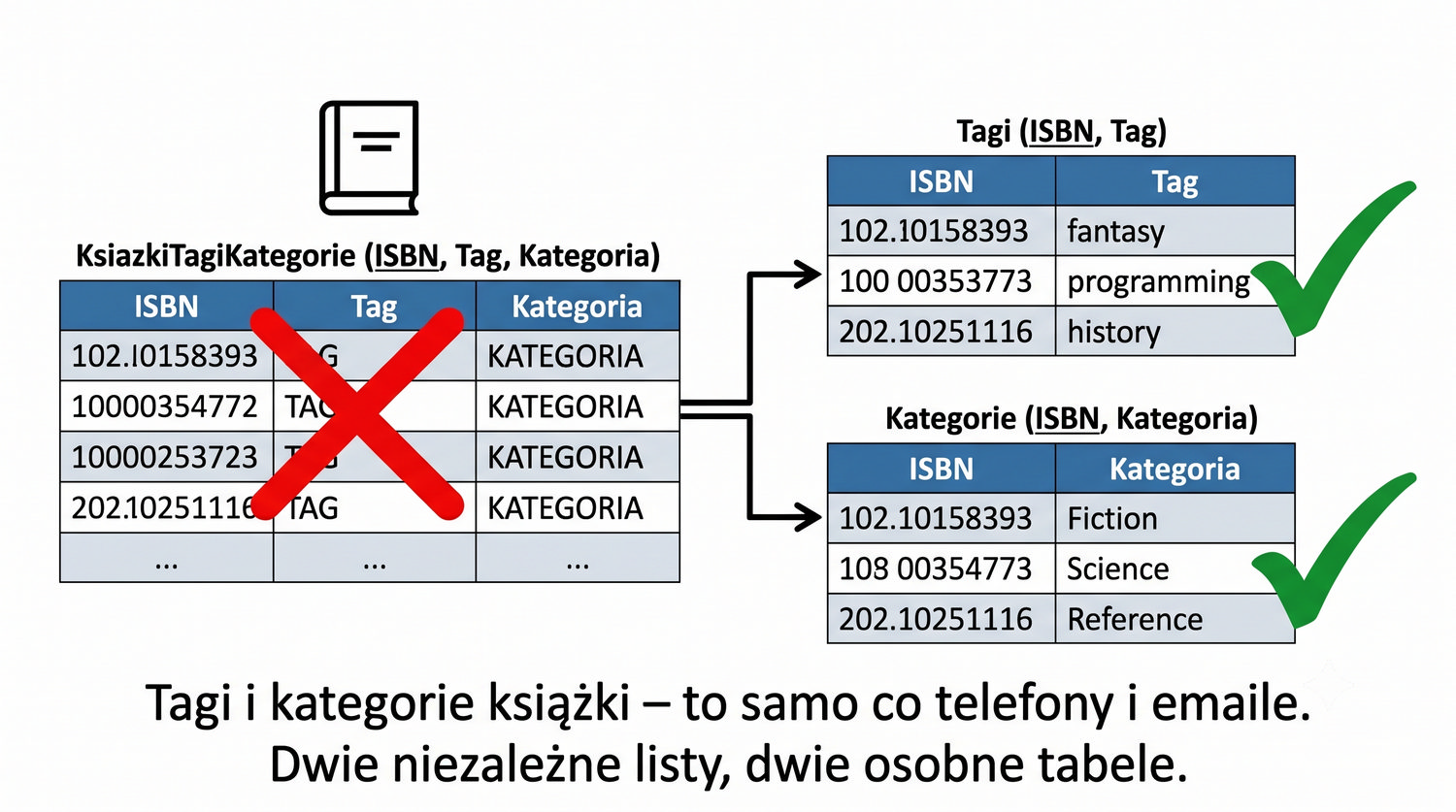
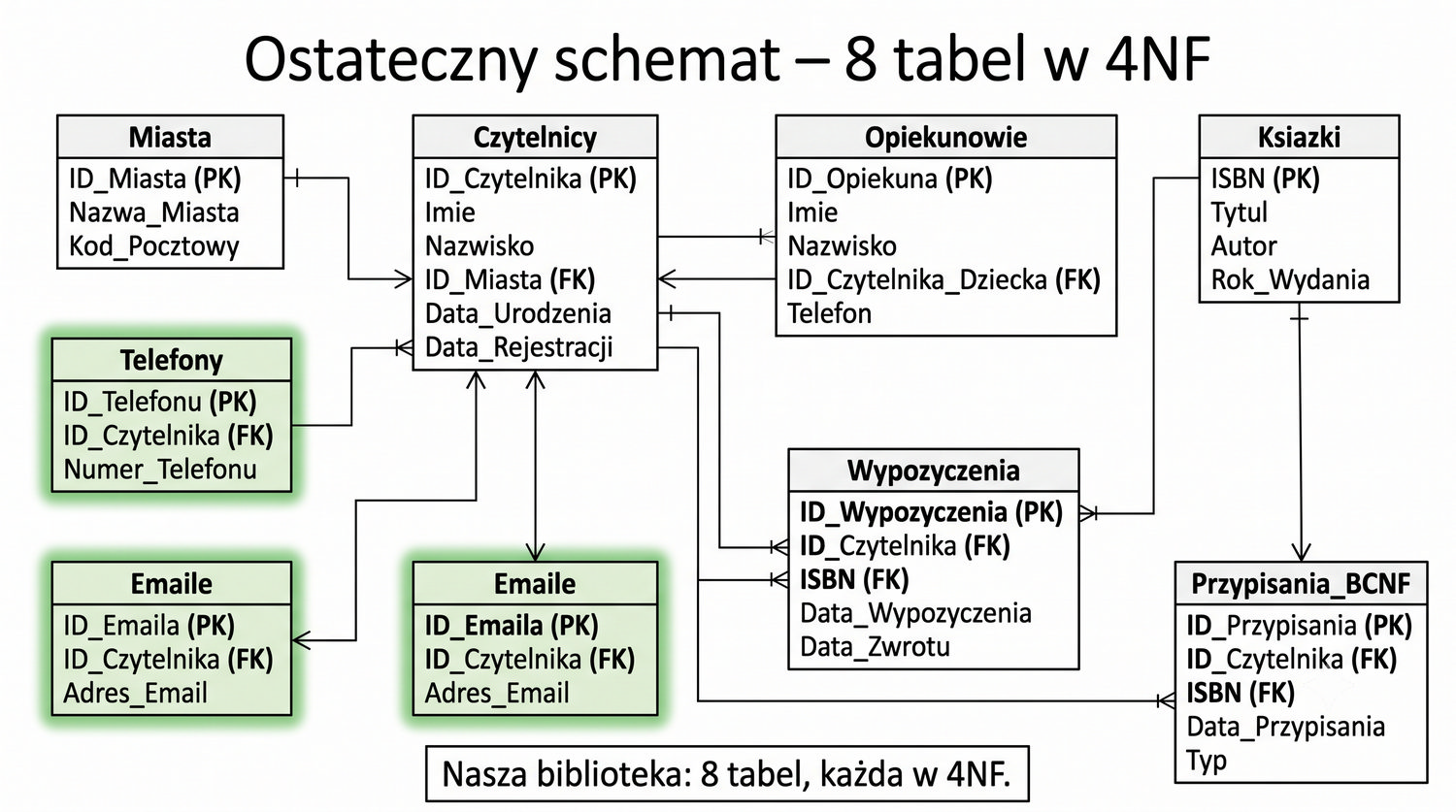
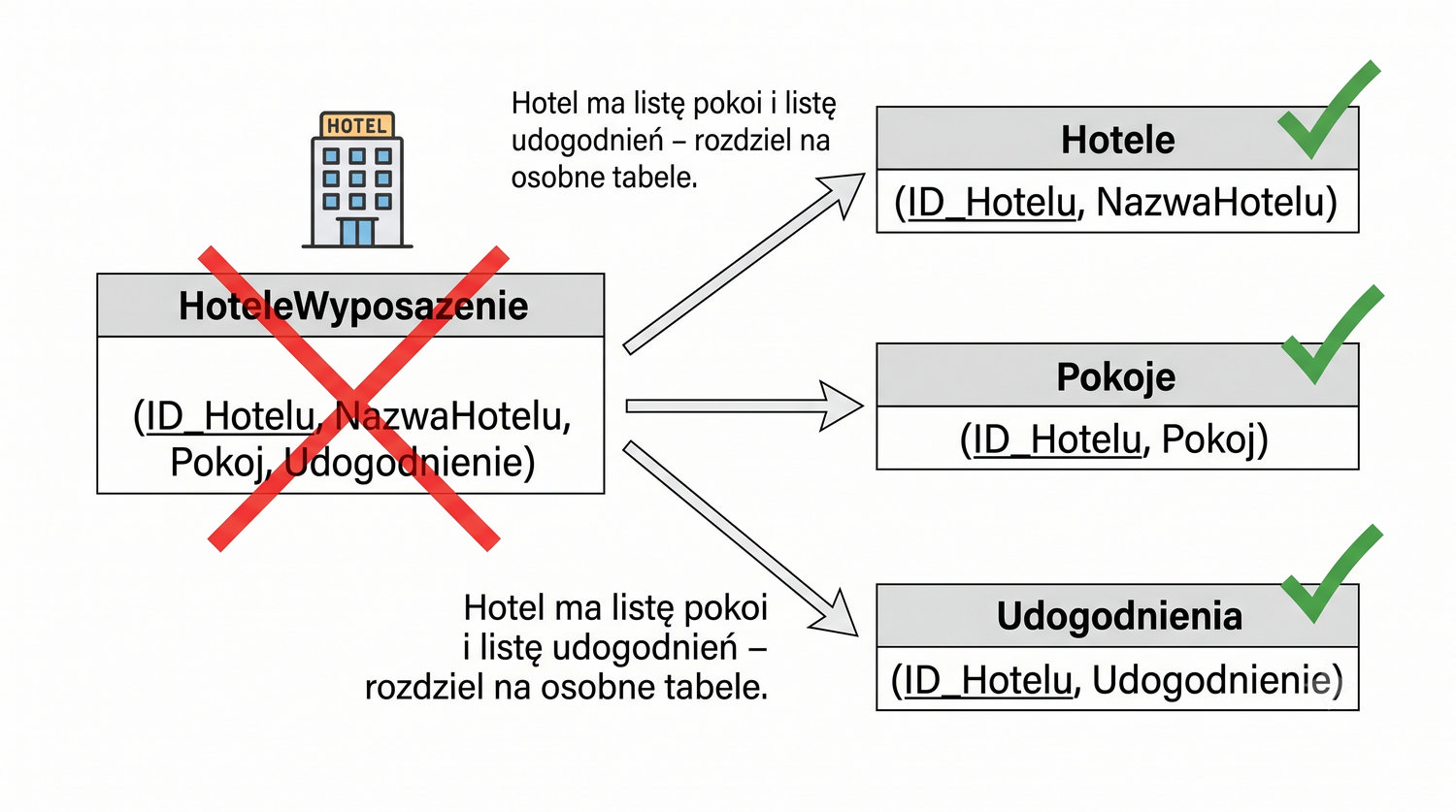
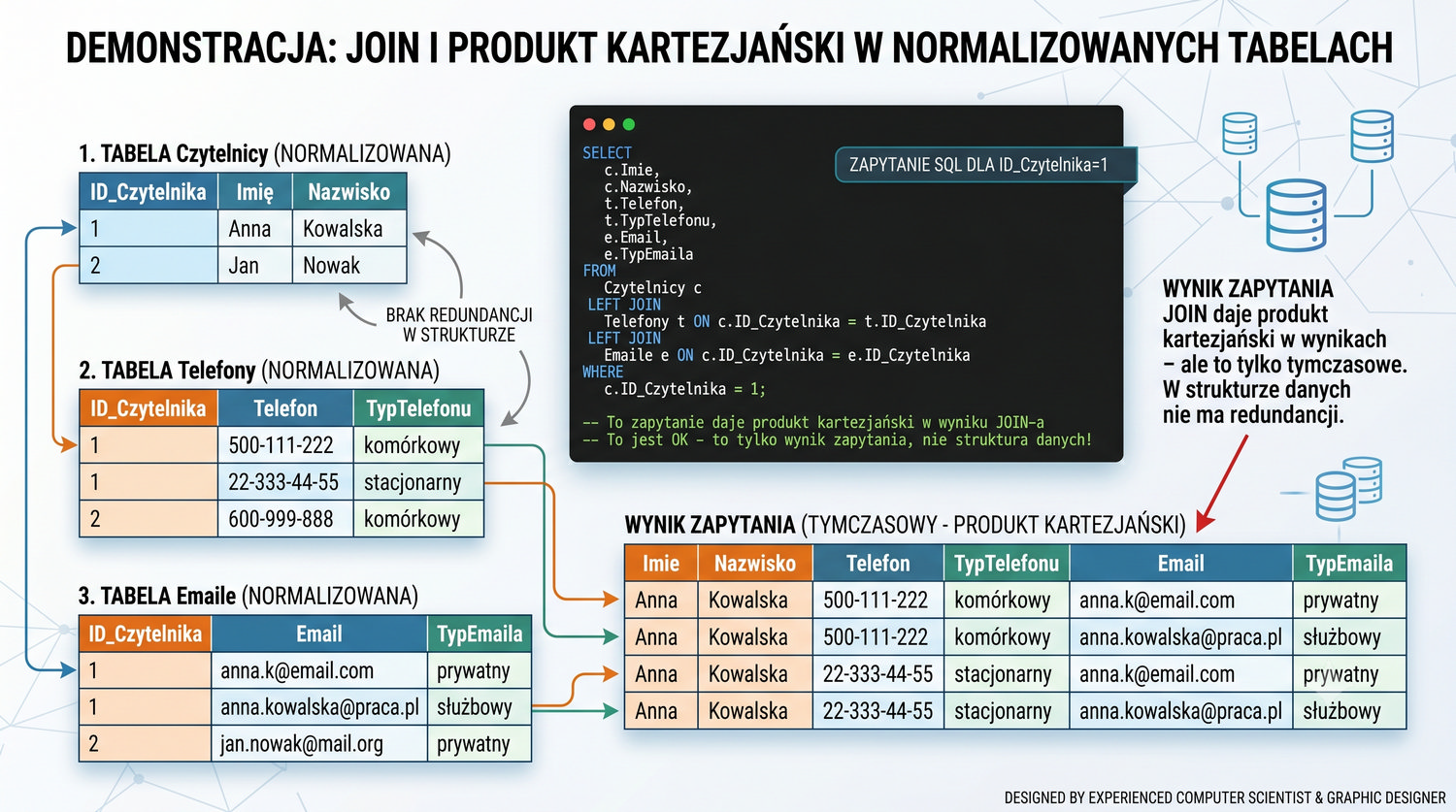
Prezentacja kontynuuje przykład systemu bibliotecznego z poprzednich prezentacji (BD_1NF, BD_2NF, BD_3NF, BCNF).
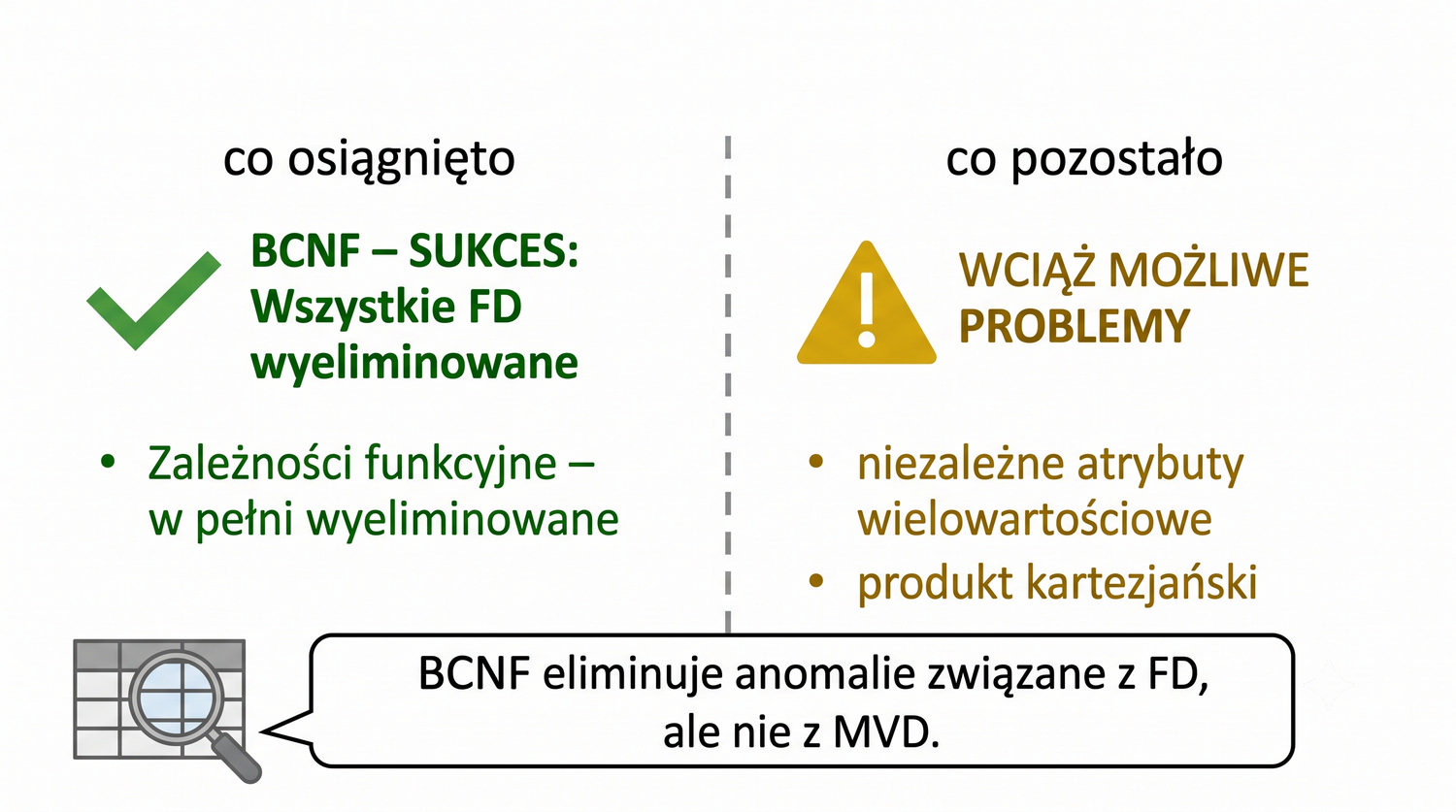
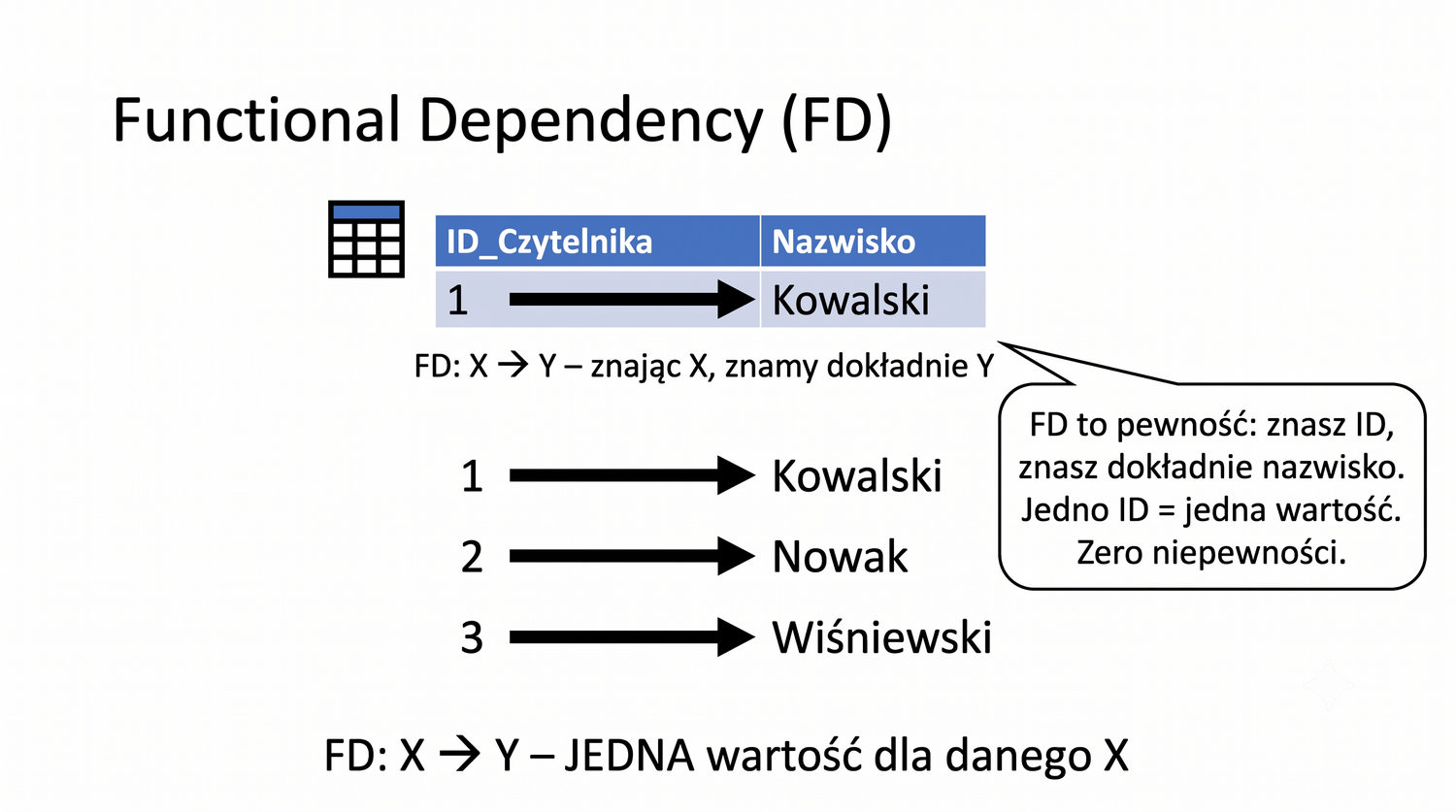
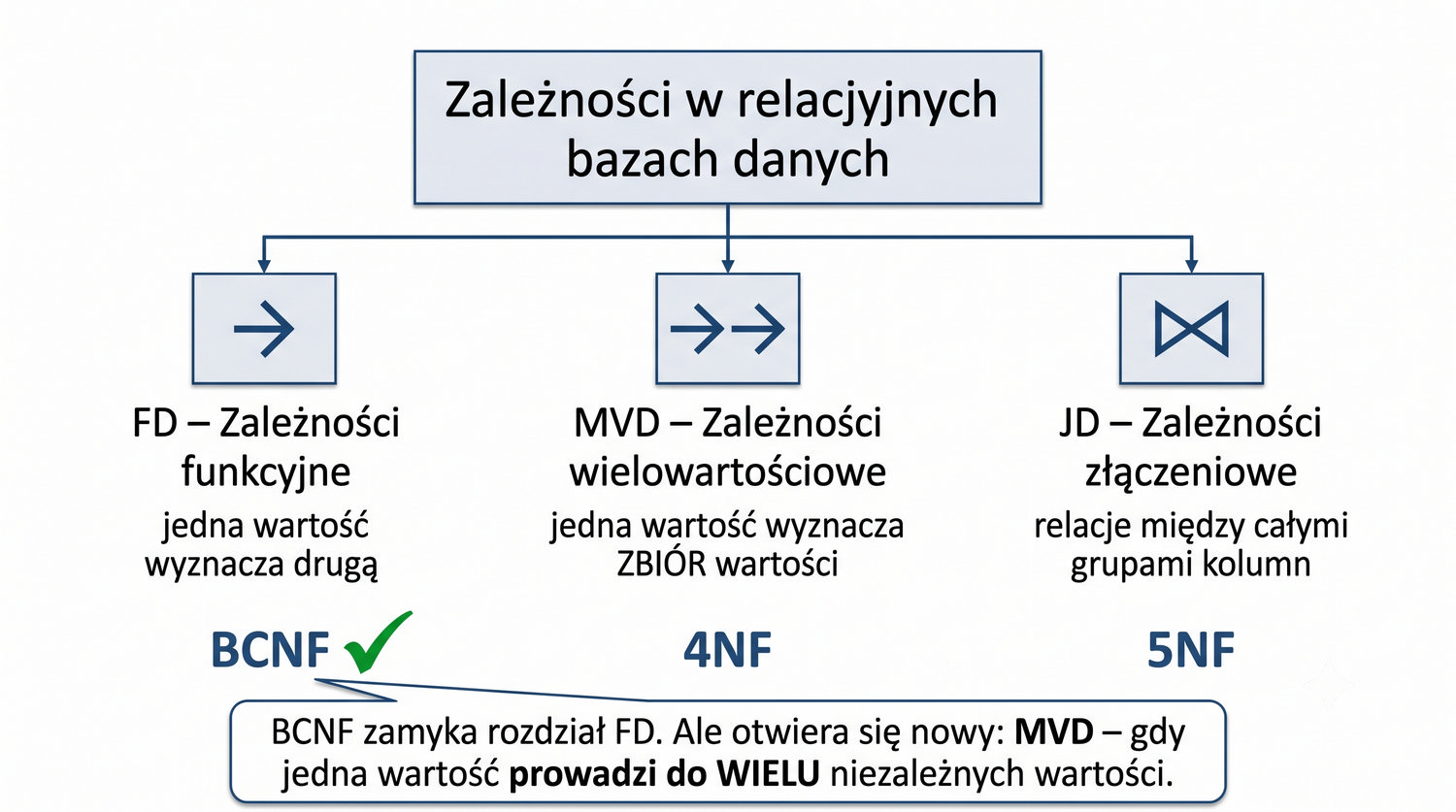
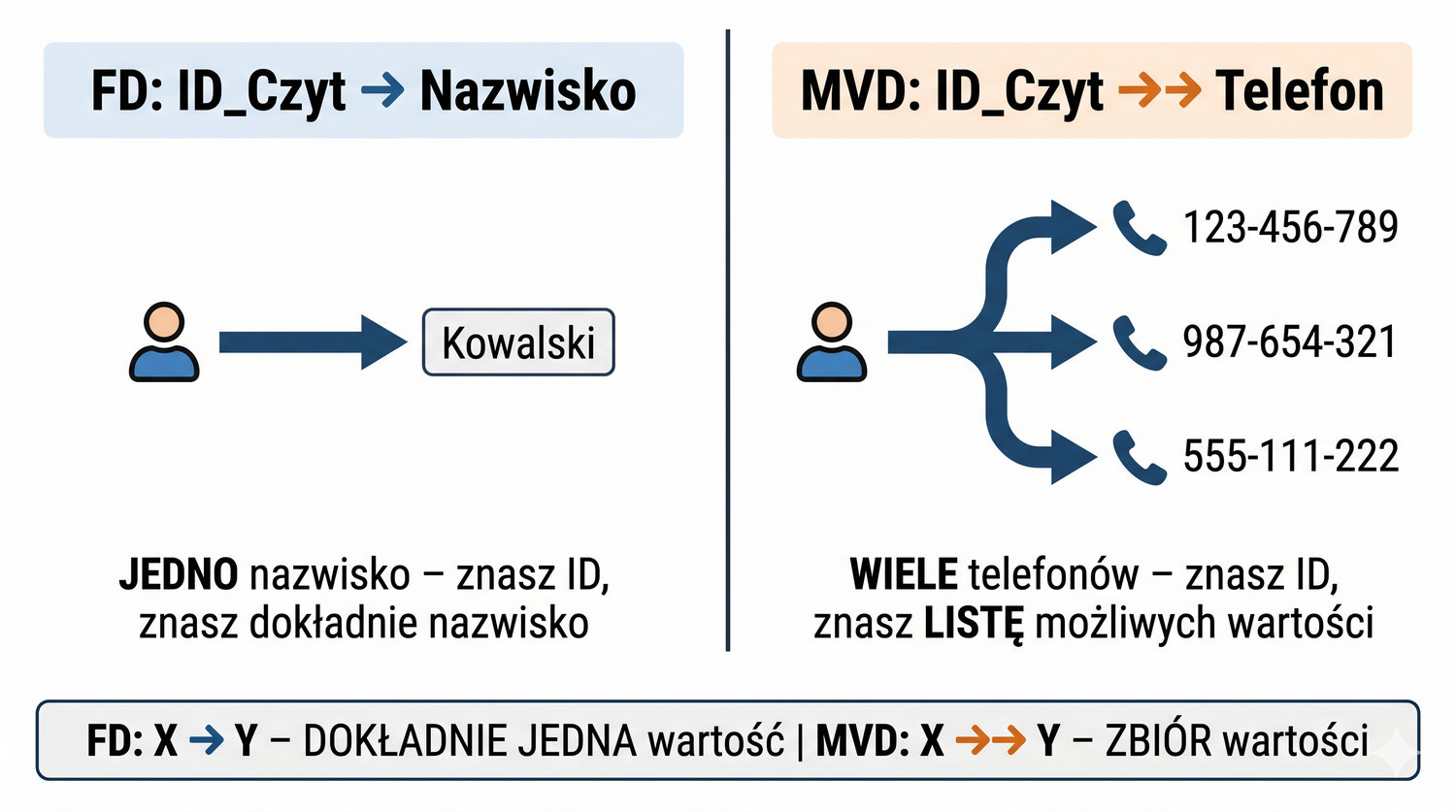
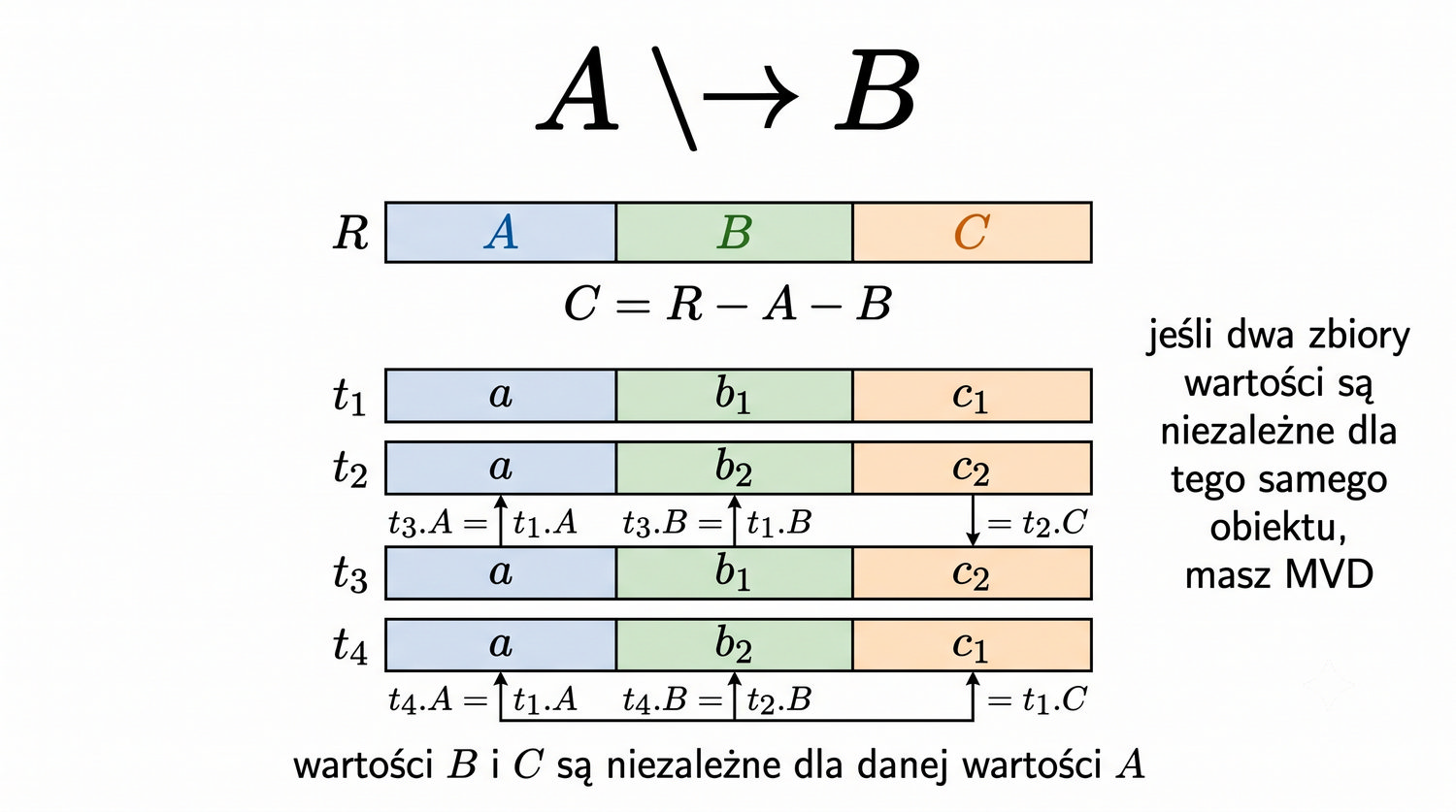
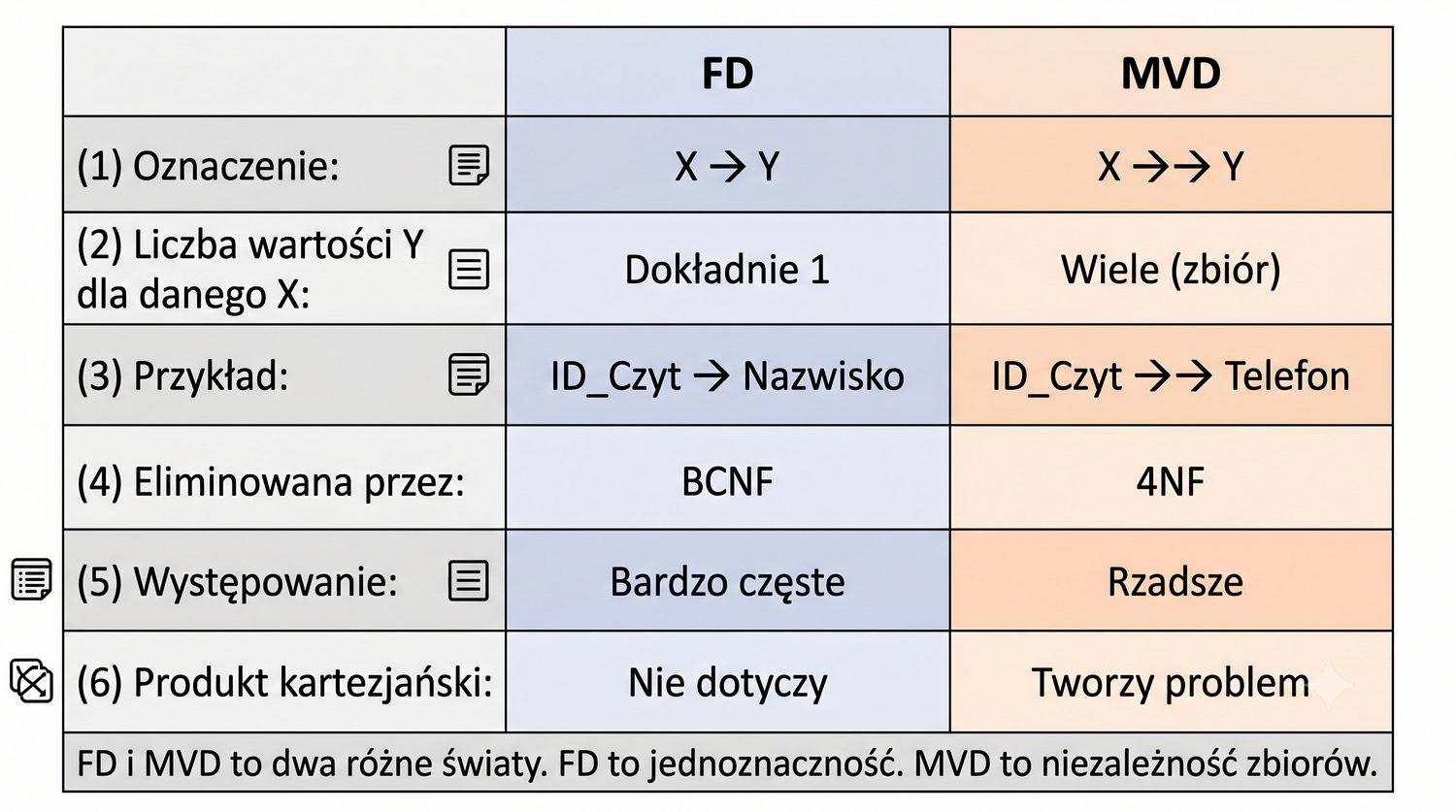
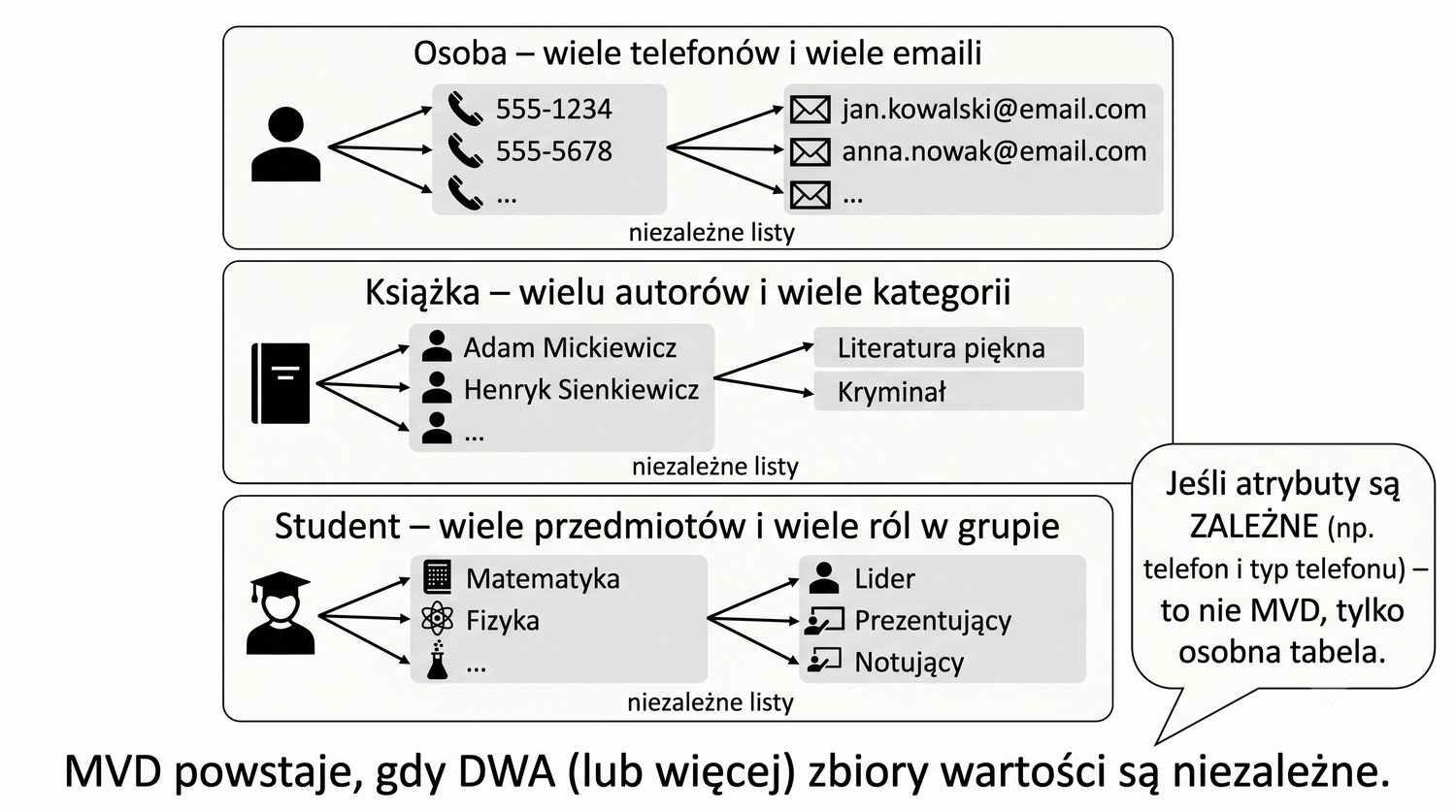
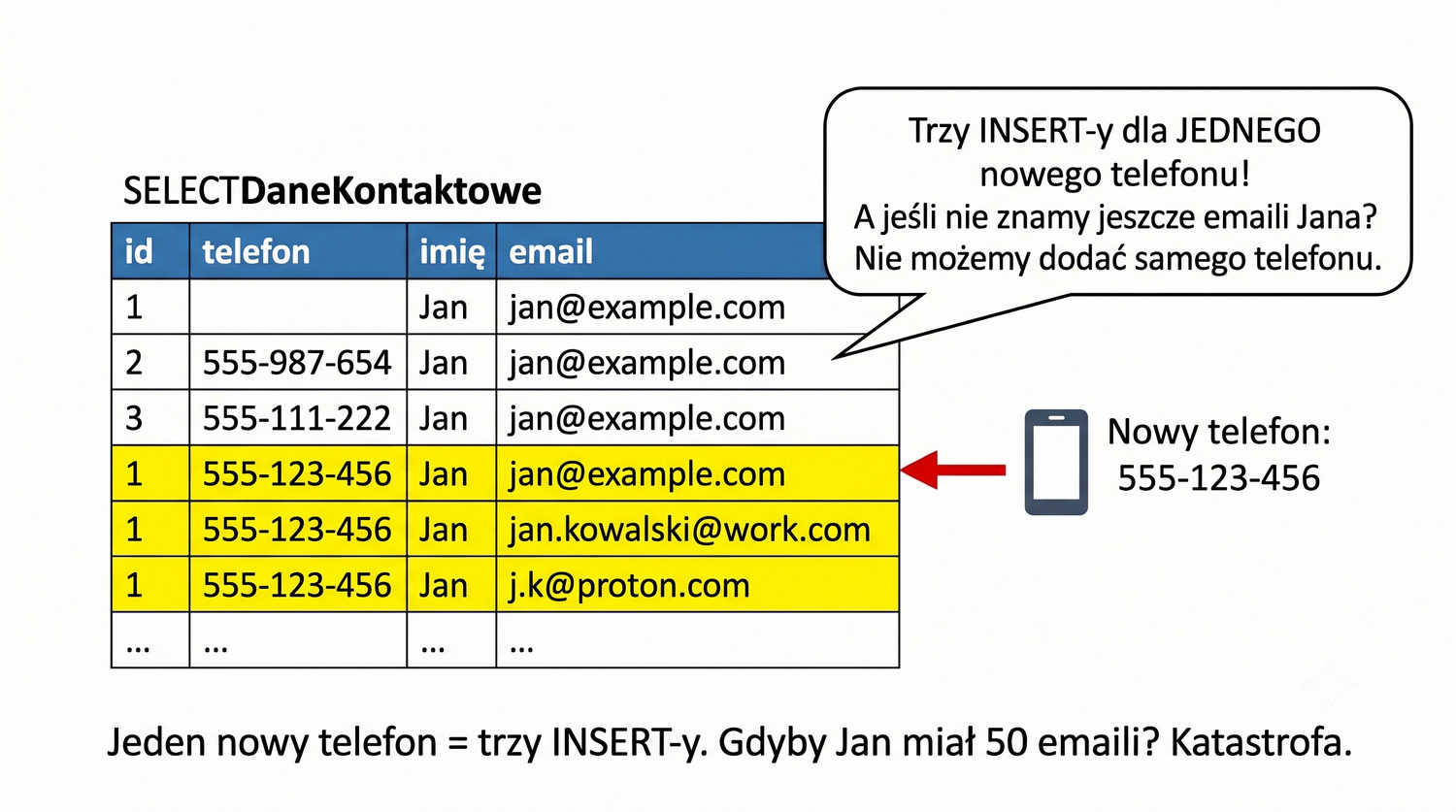
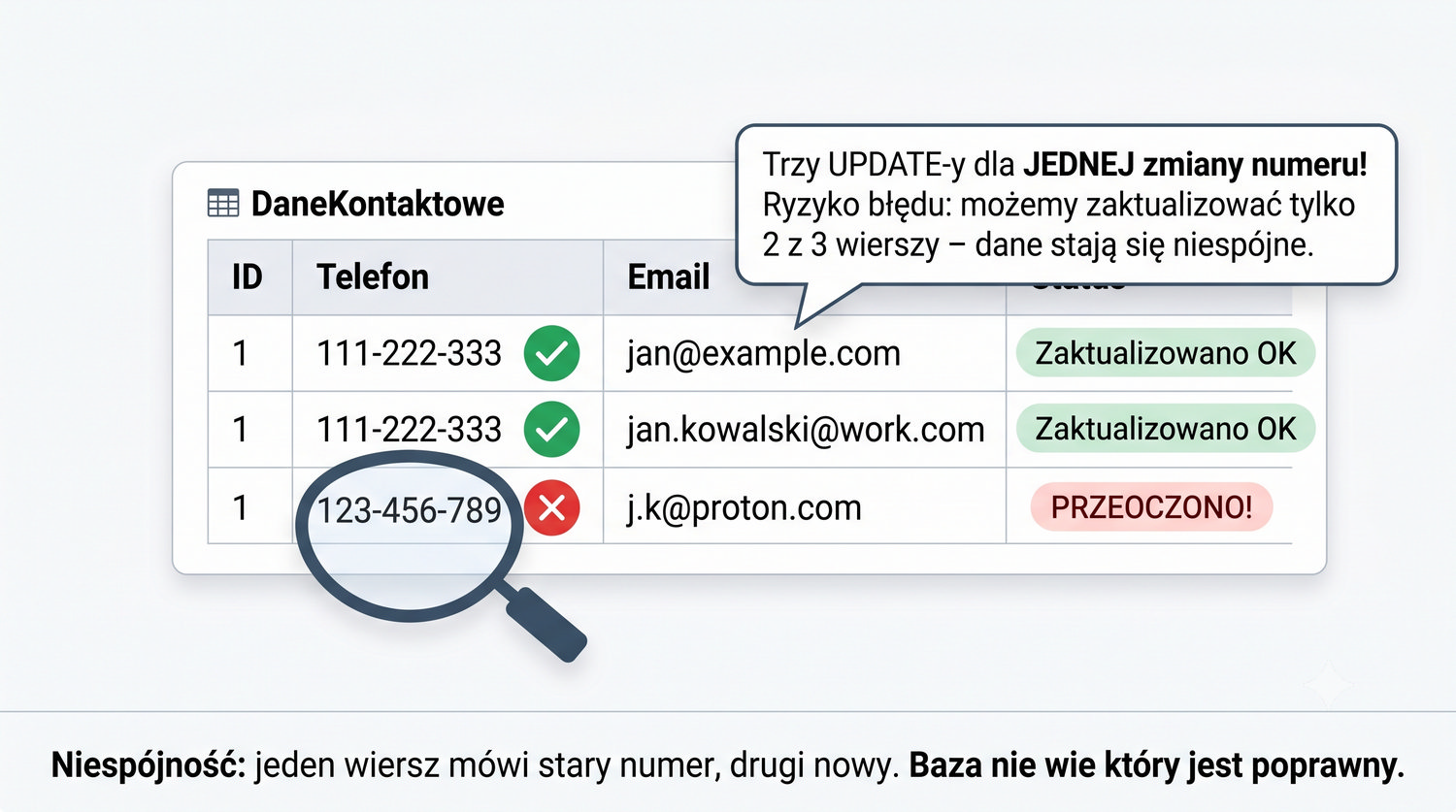
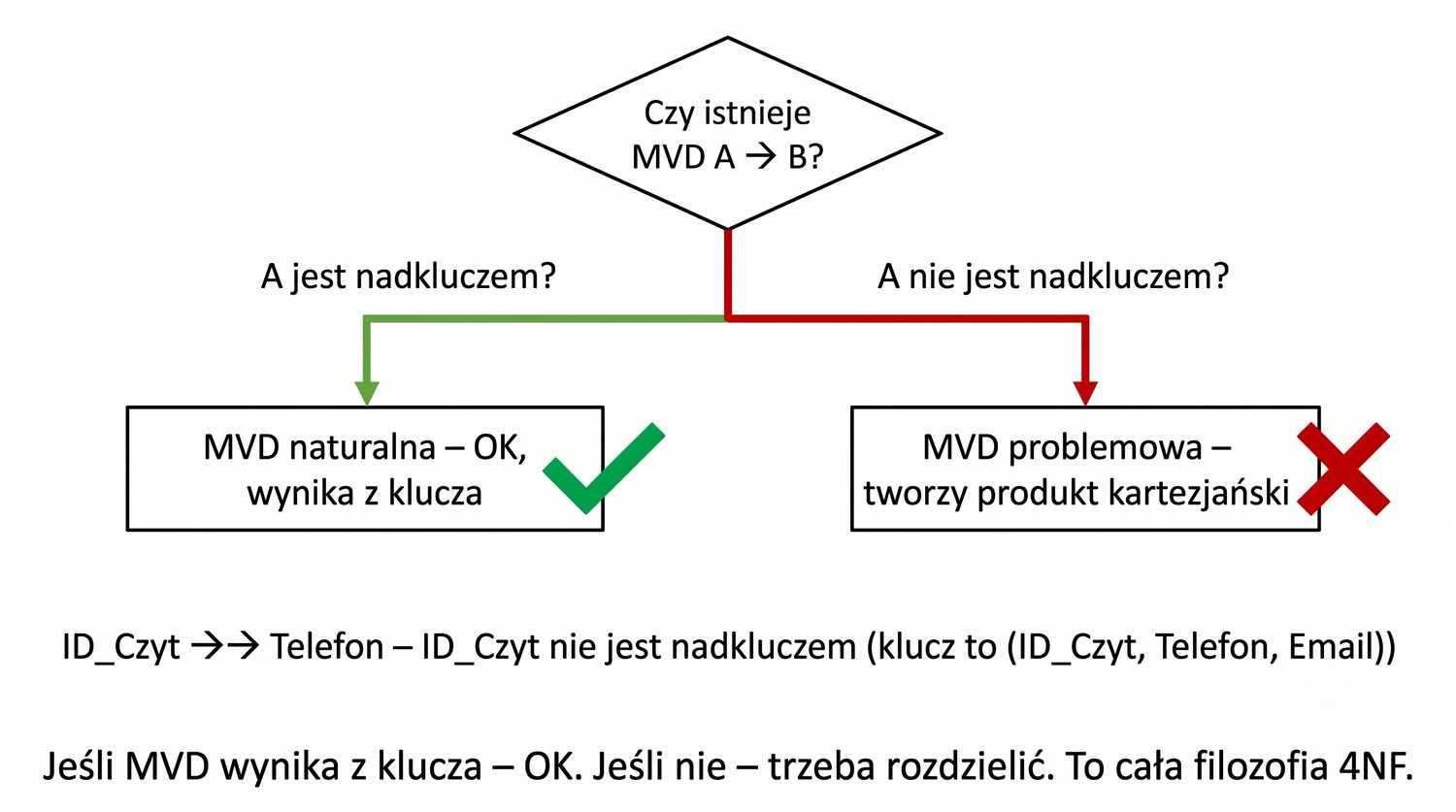
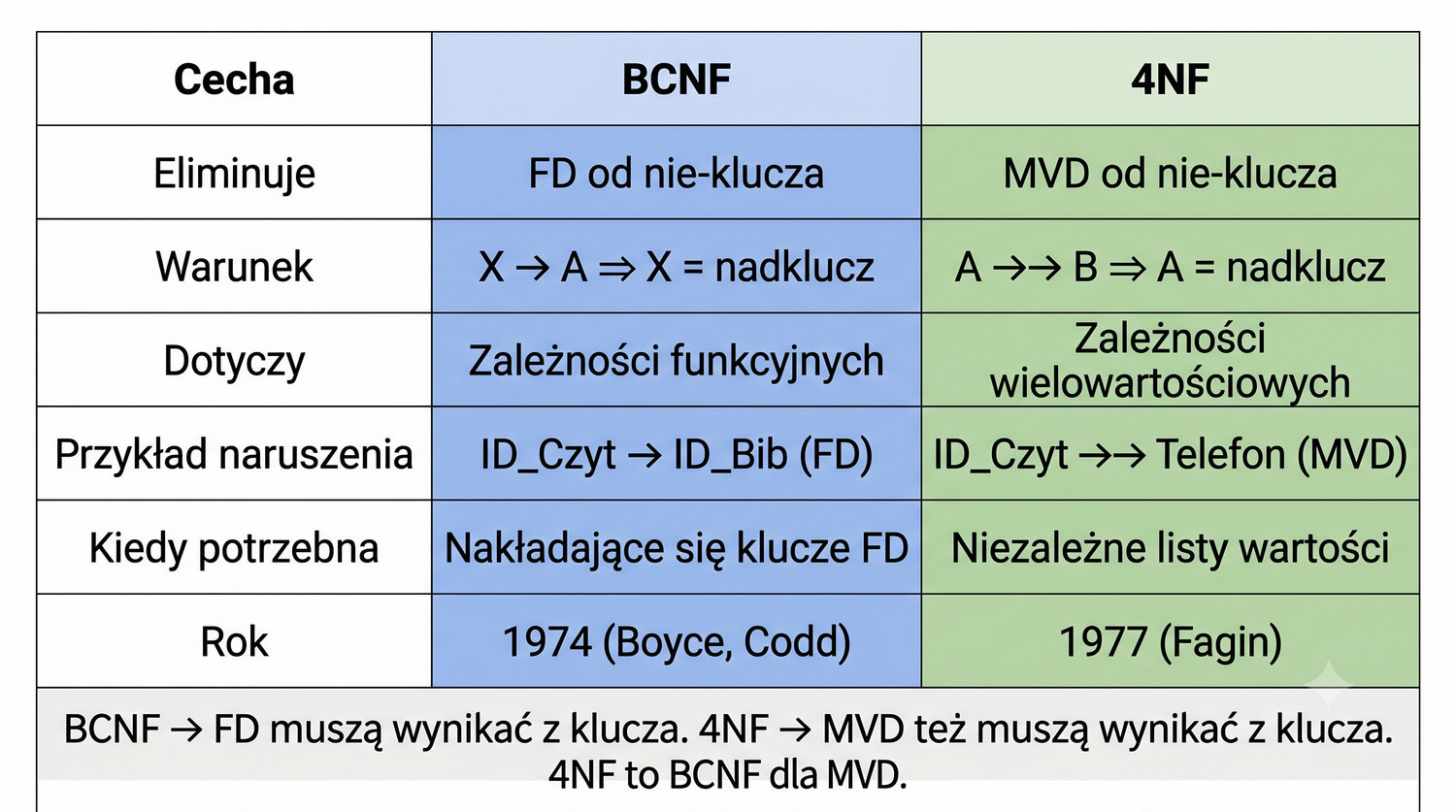
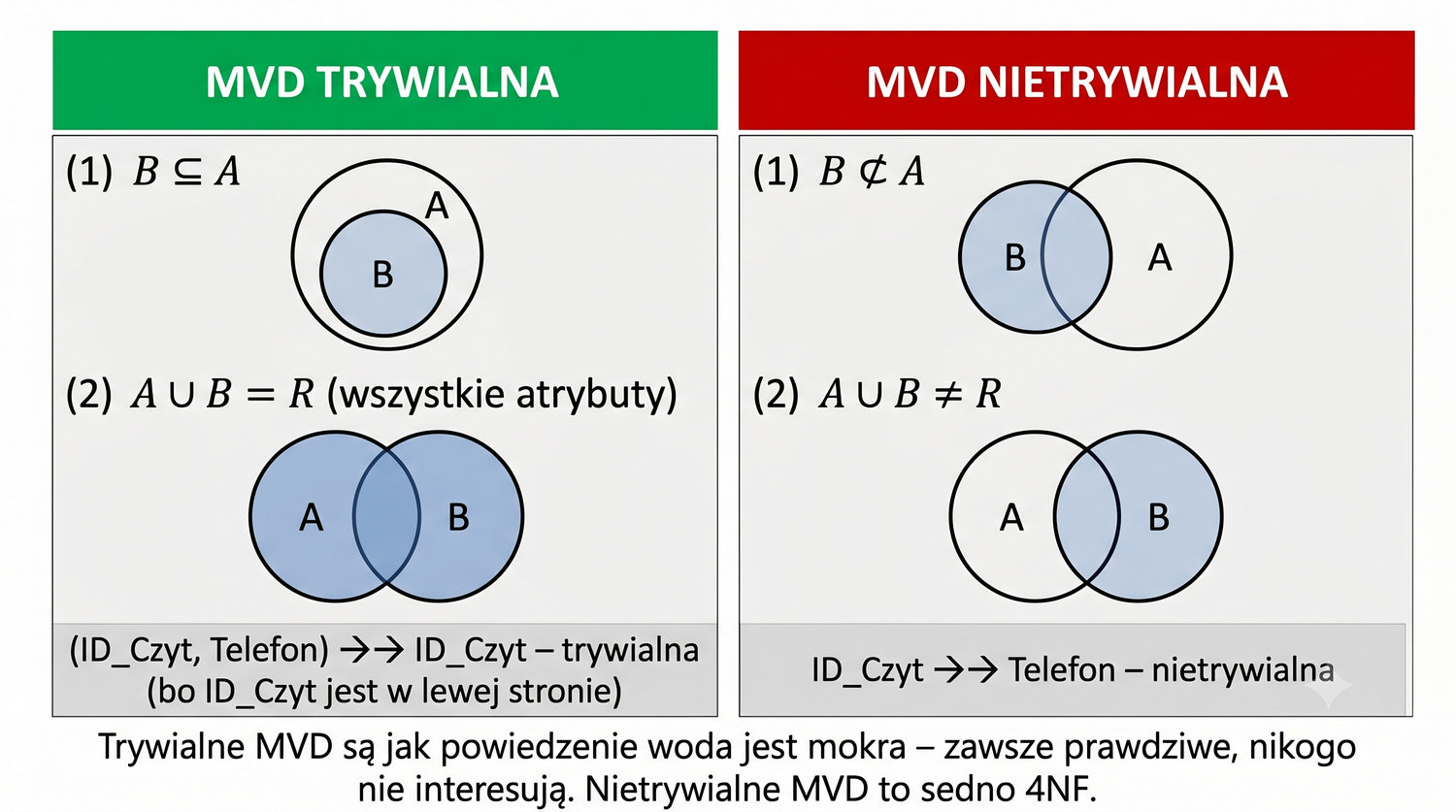
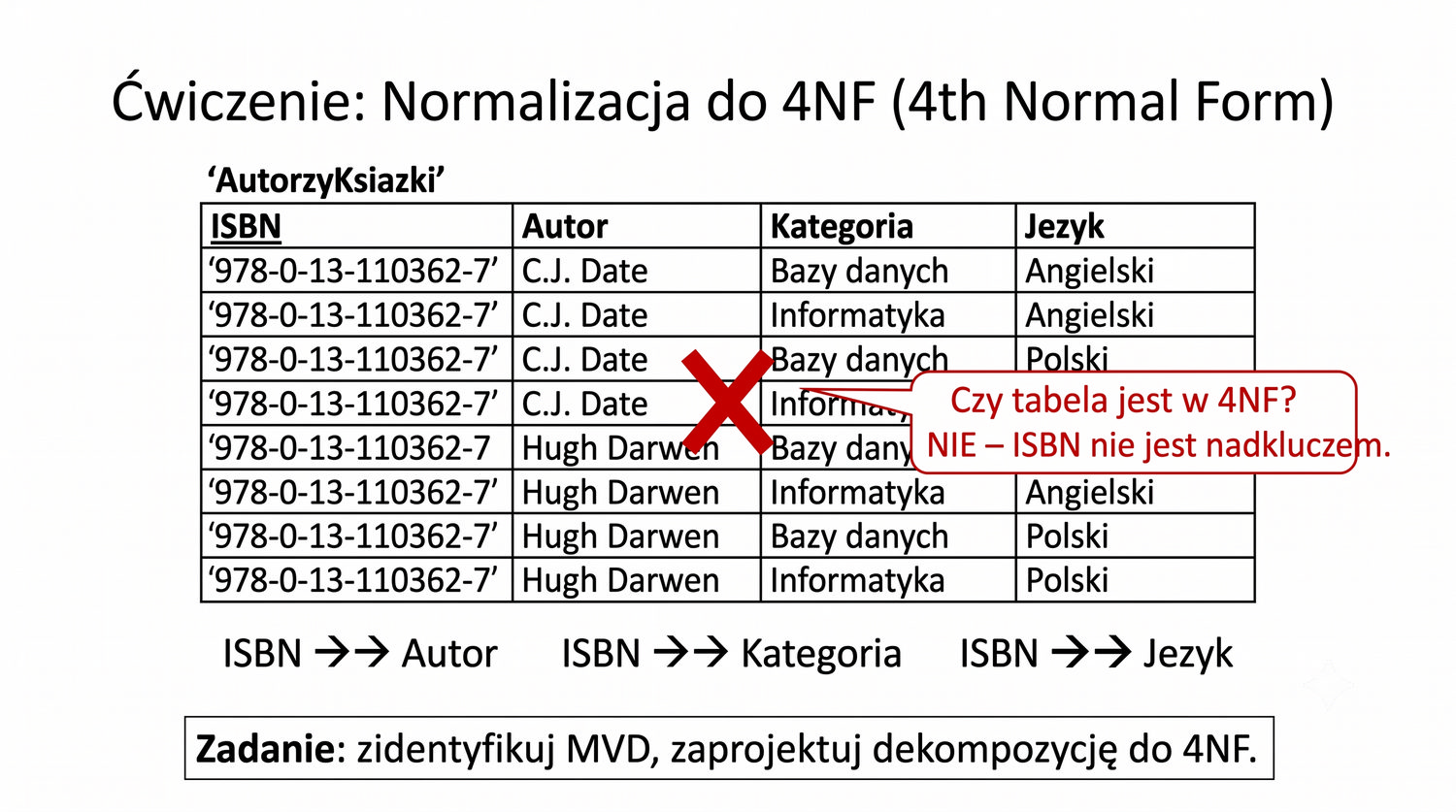
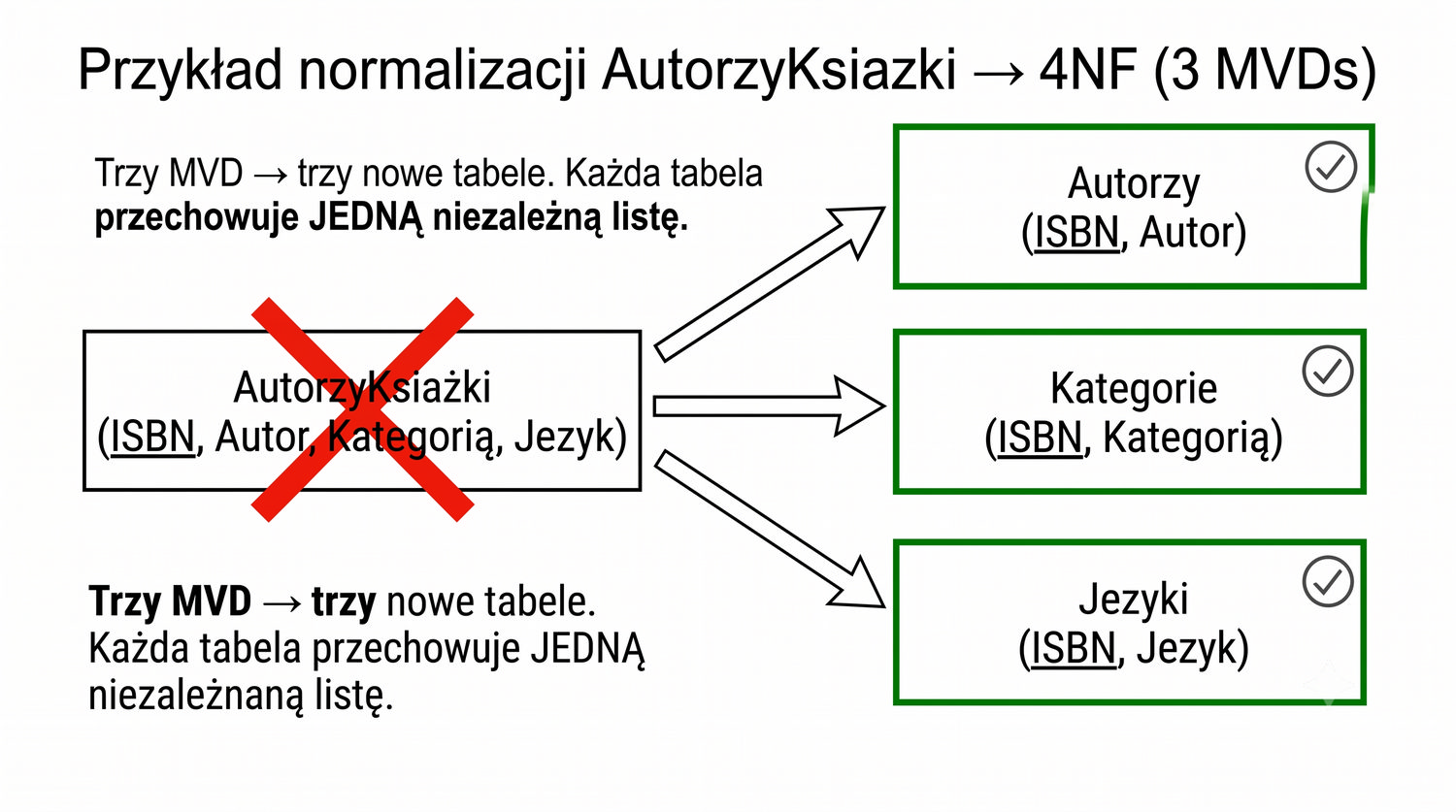
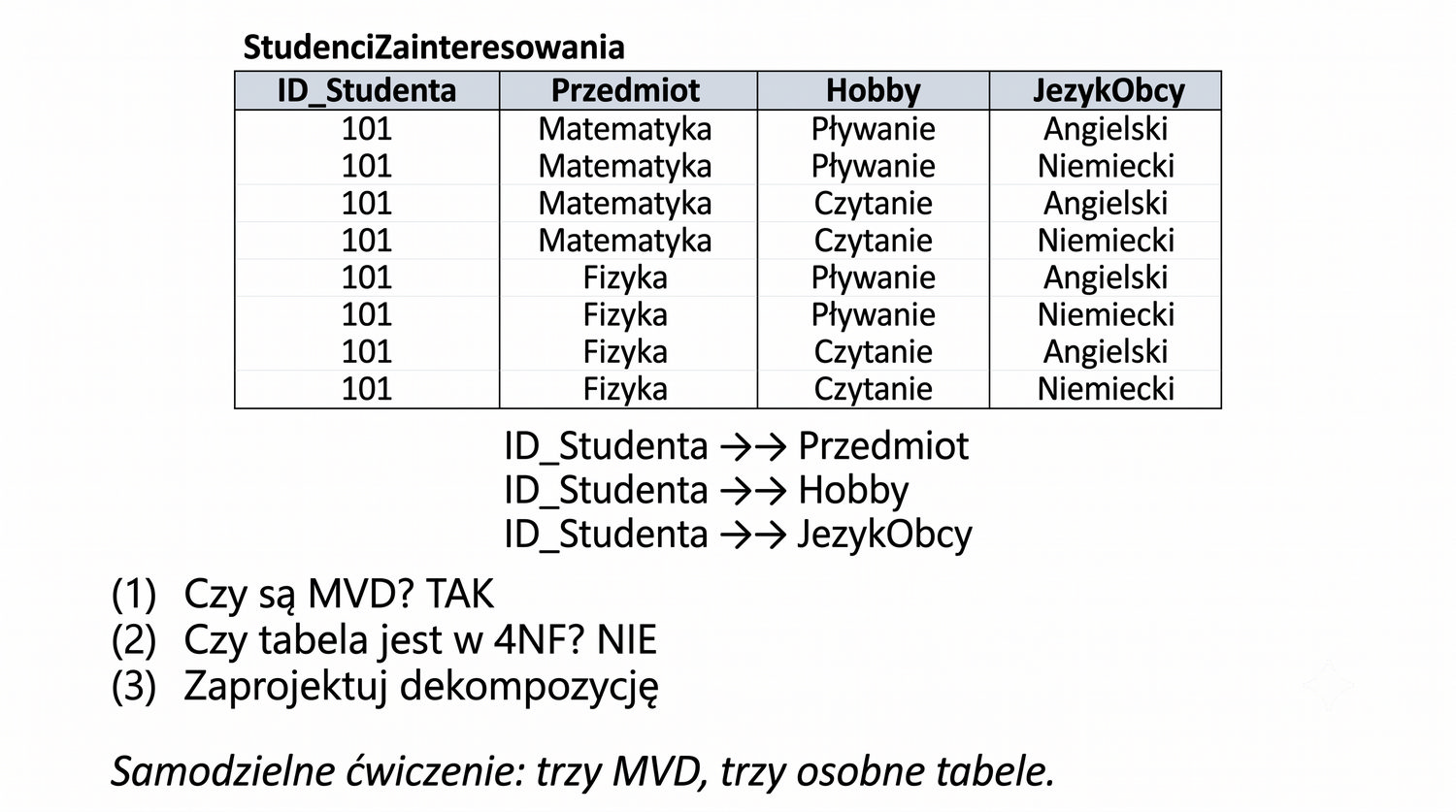
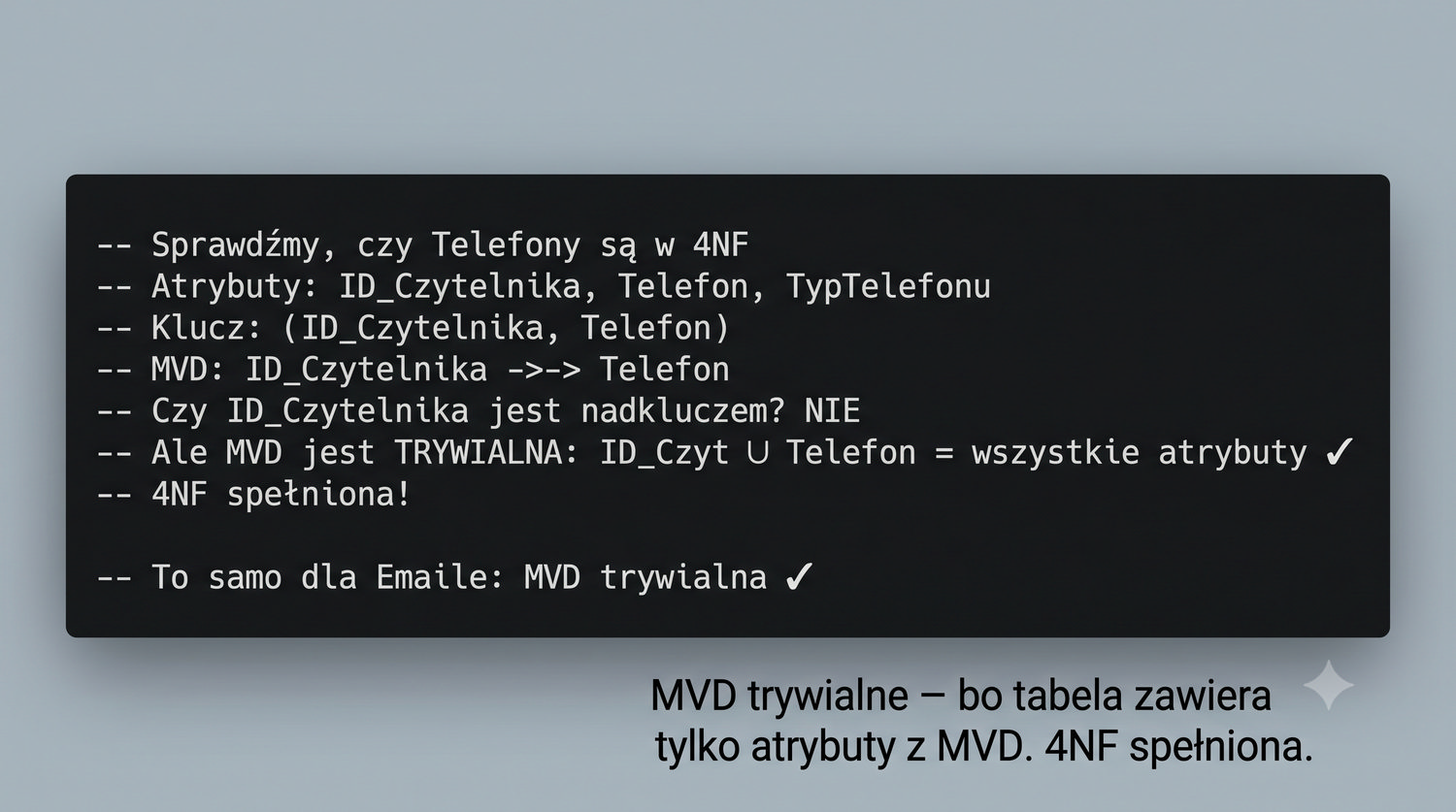
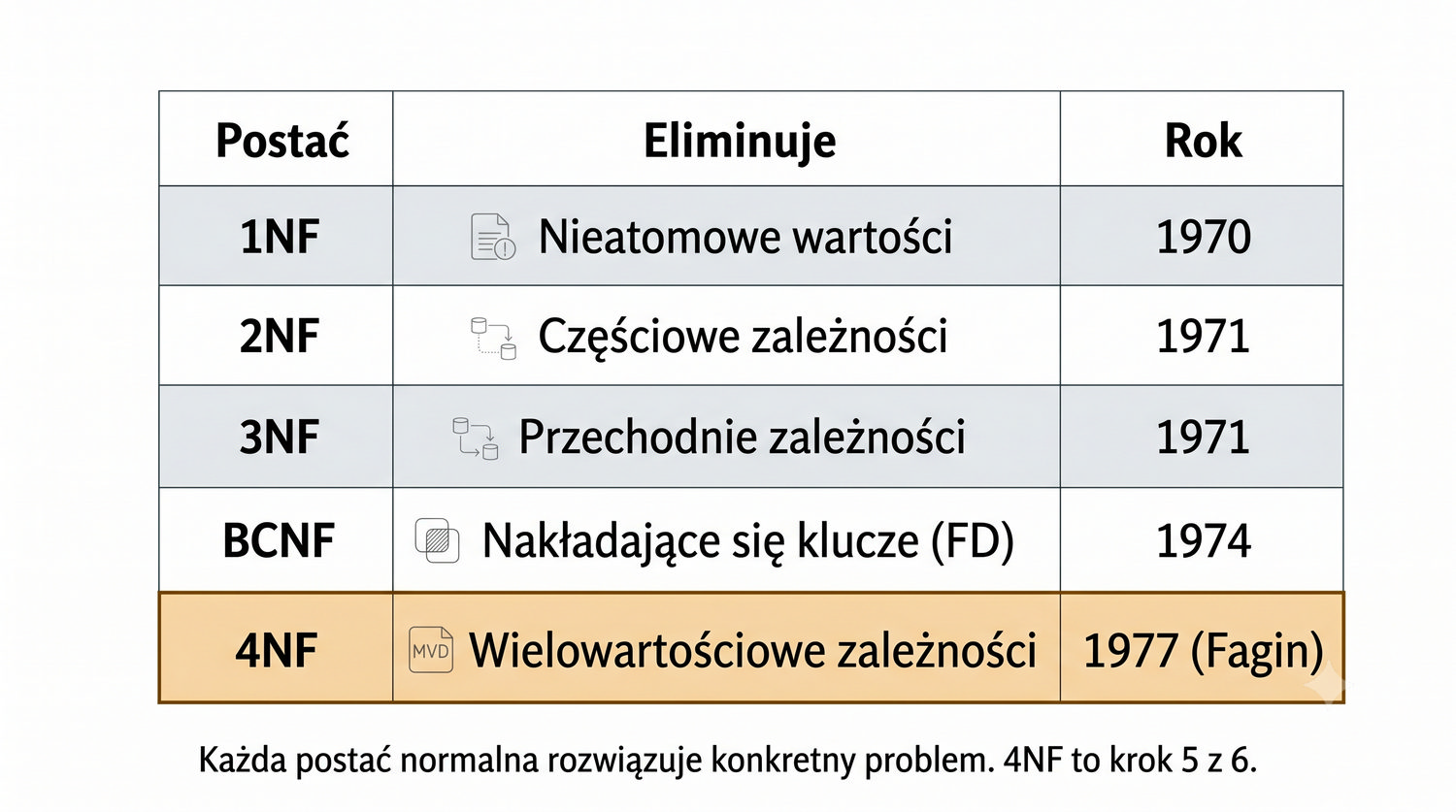
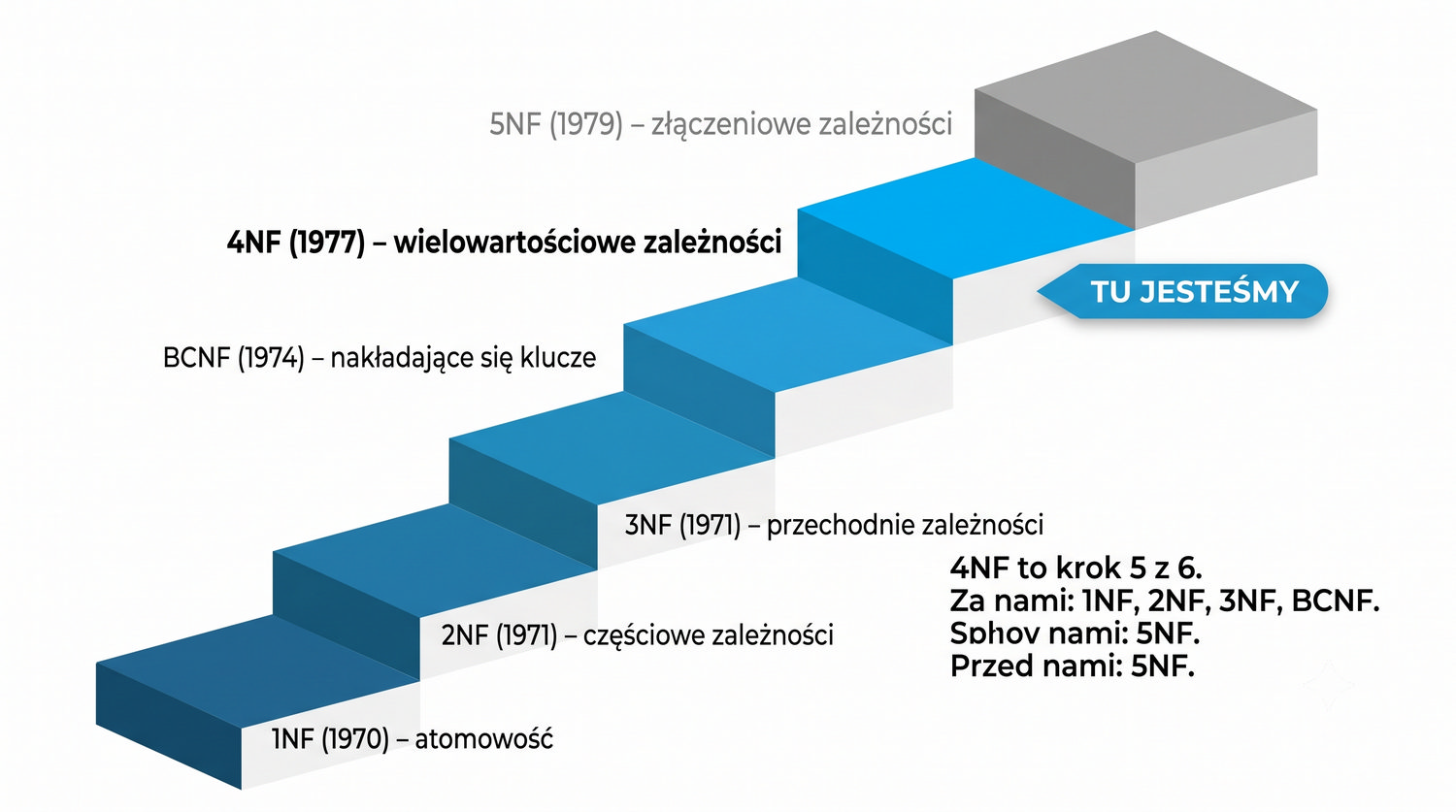
4NF została zdefiniowana przez Ronalda Fagina w 1977 roku – to krok poza zależności funkcyjne, w świat zależności wielowartościowych