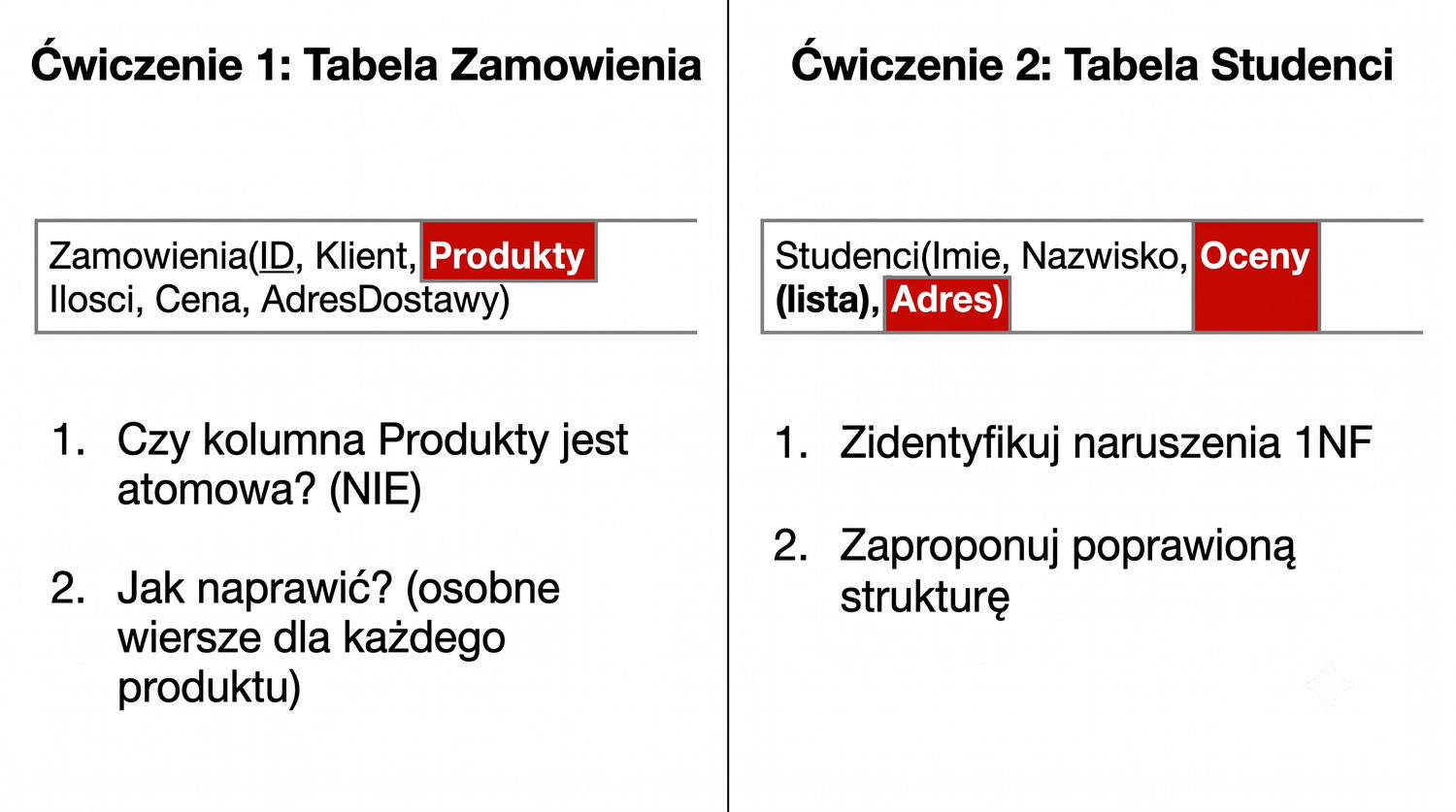
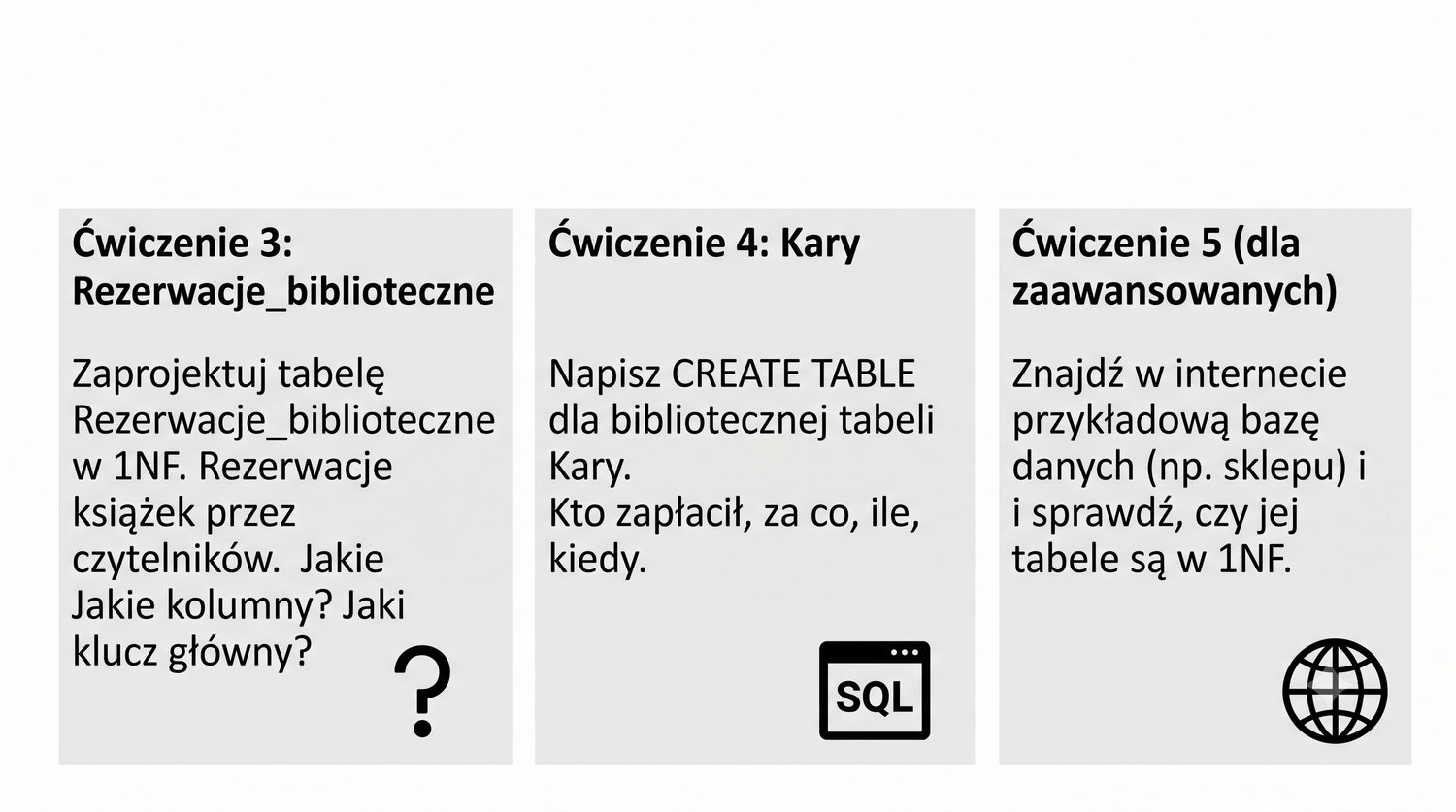
Od danych surowych do dobrze zorganizowanej struktury – krok pierwszy
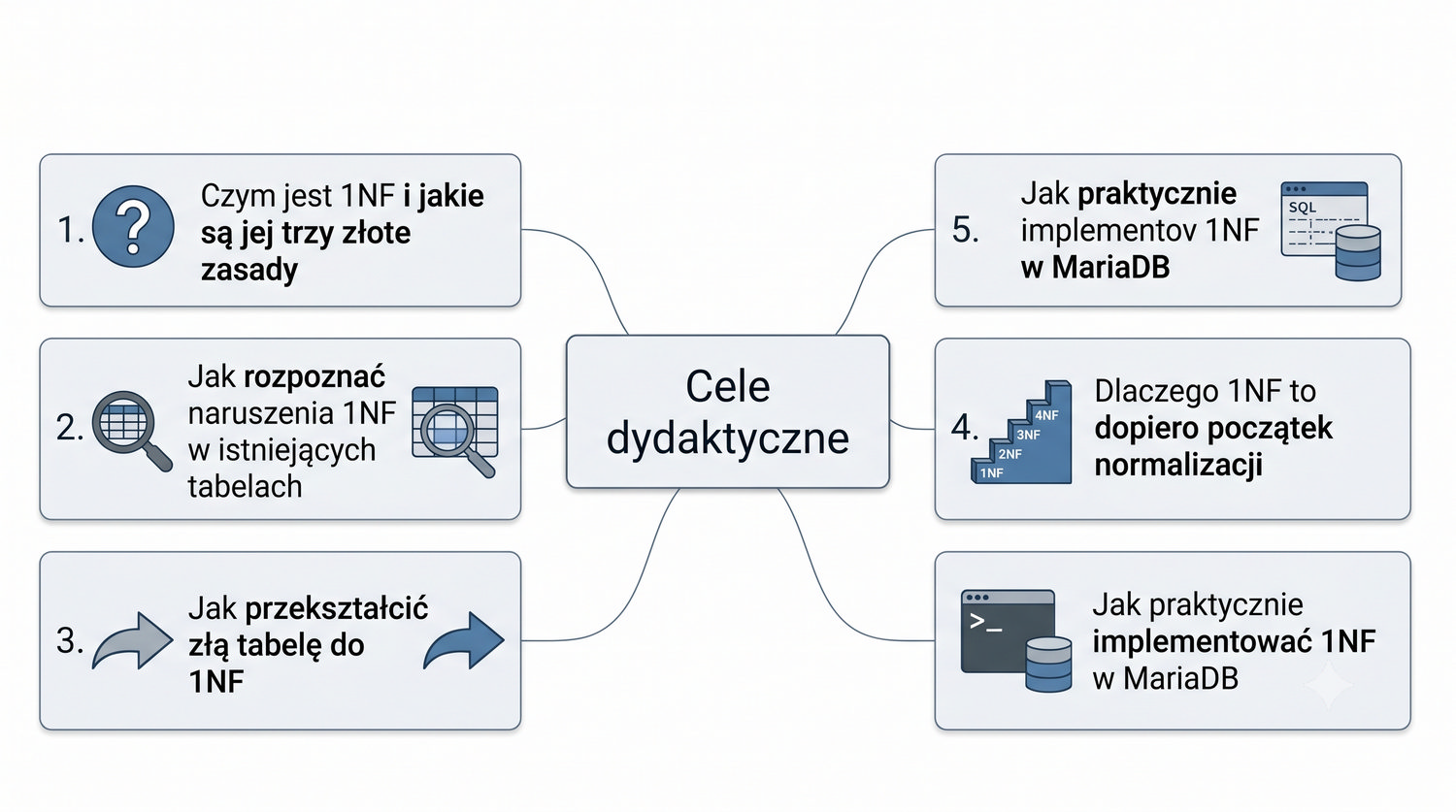
Prezentacja przeznaczona dla studentów I roku kierunków IT. Zakładamy zerowy poziom wiedzy o bazach danych – zaczniemy od absolutnych podstaw.
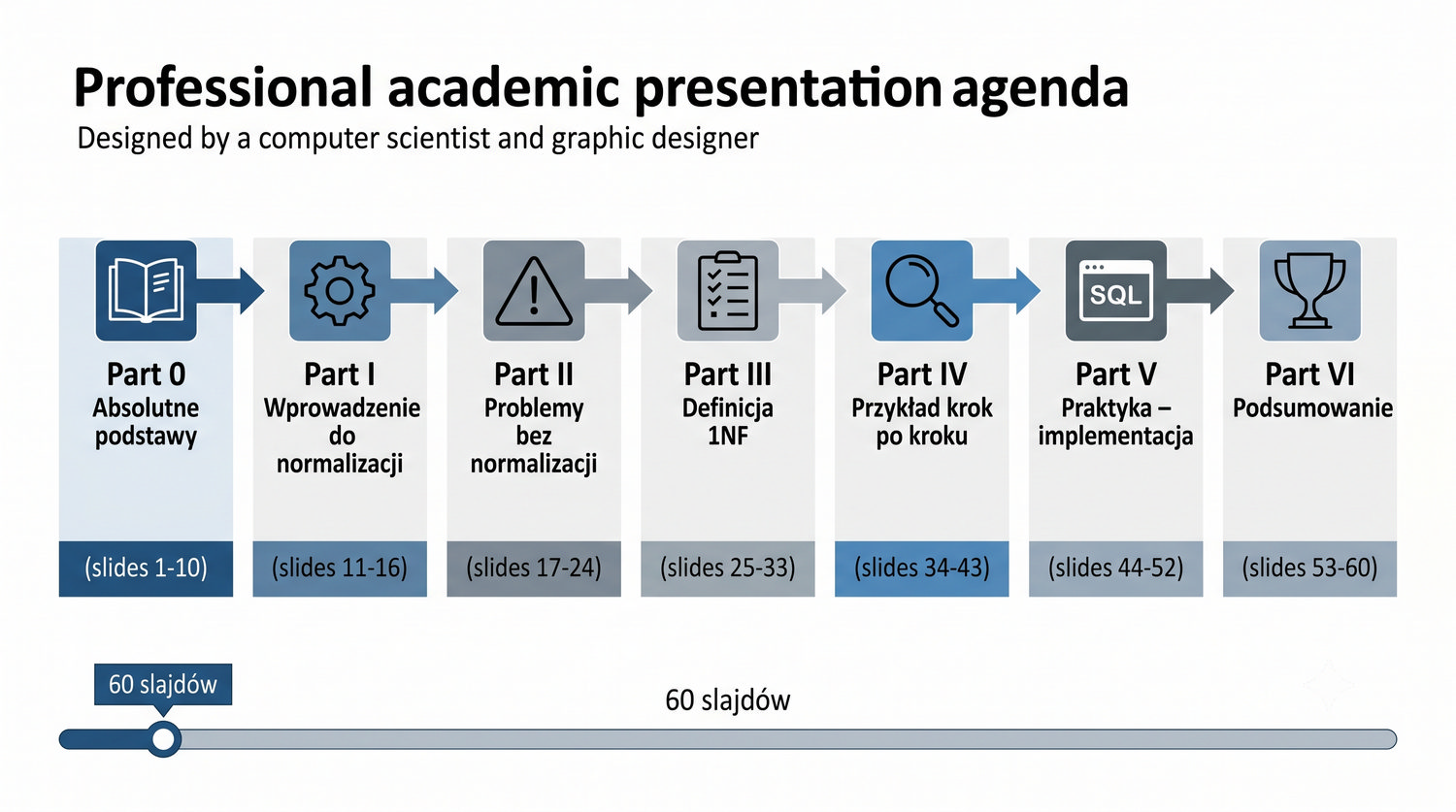
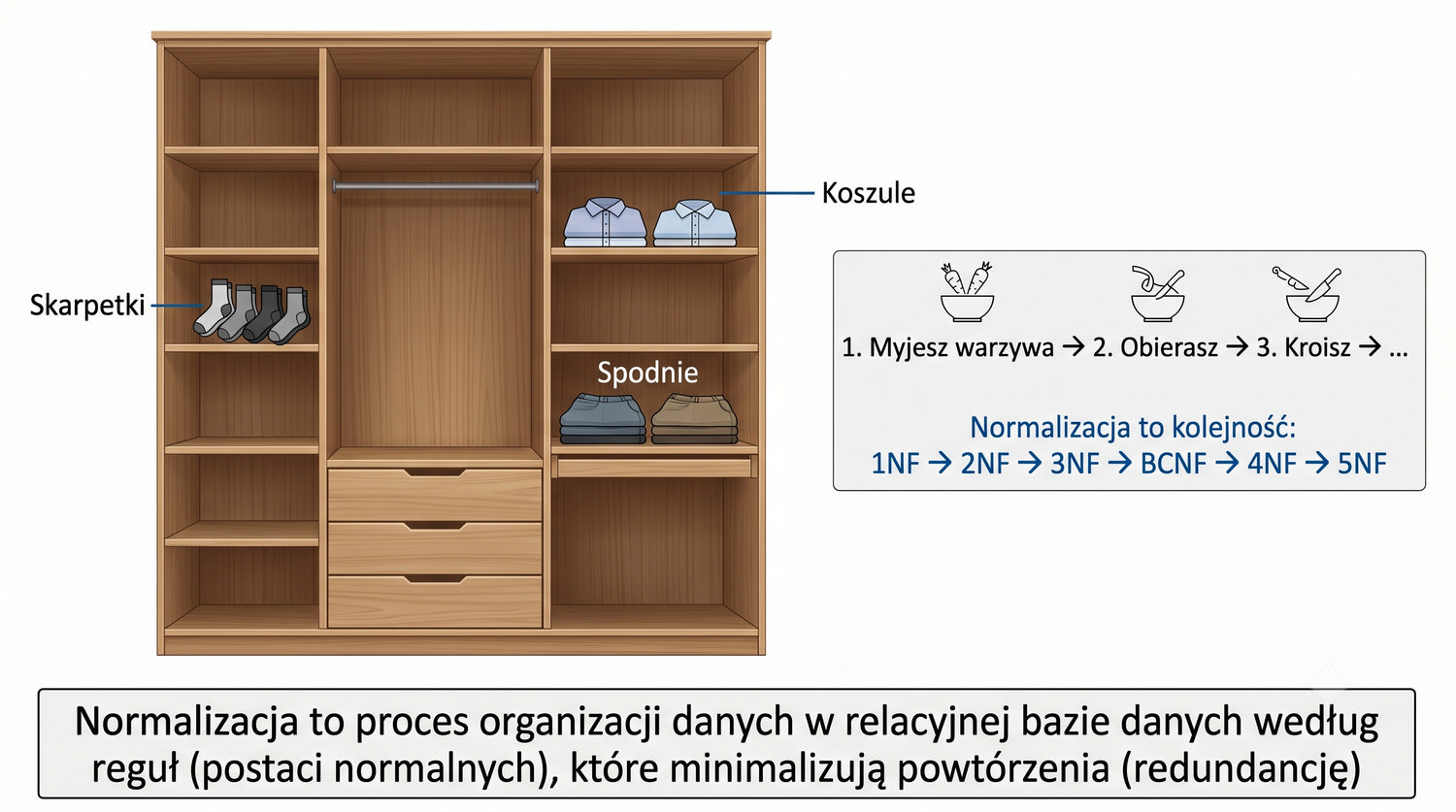
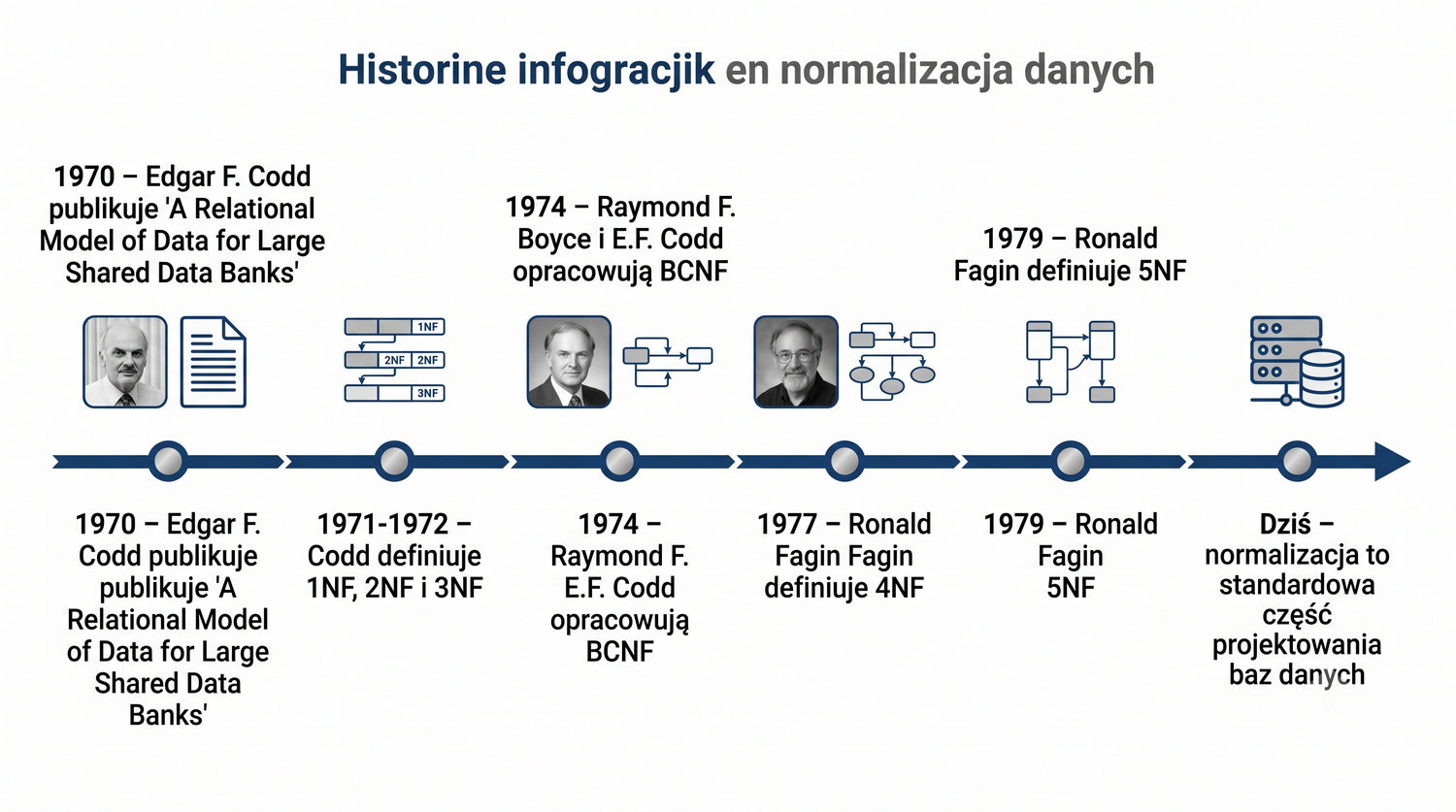
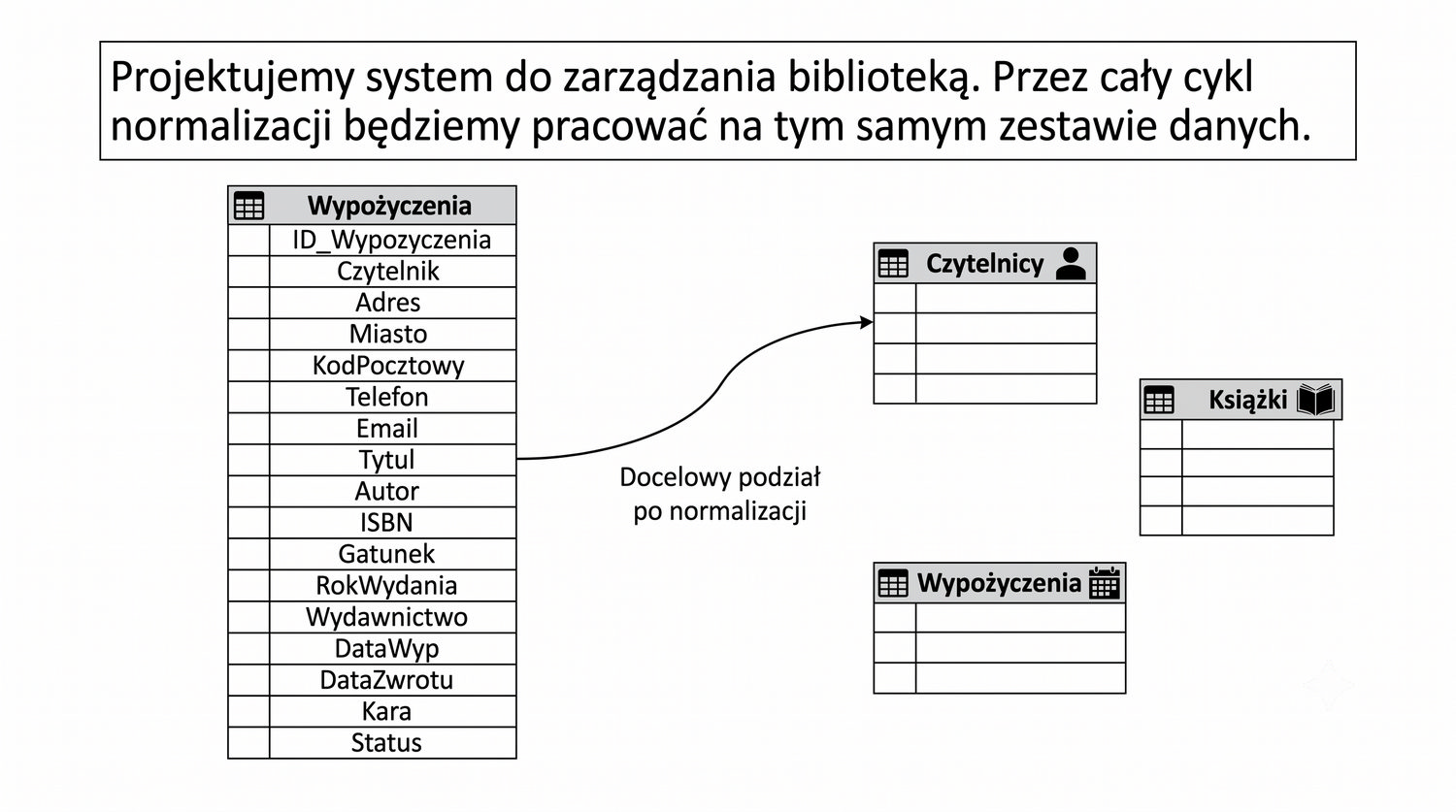
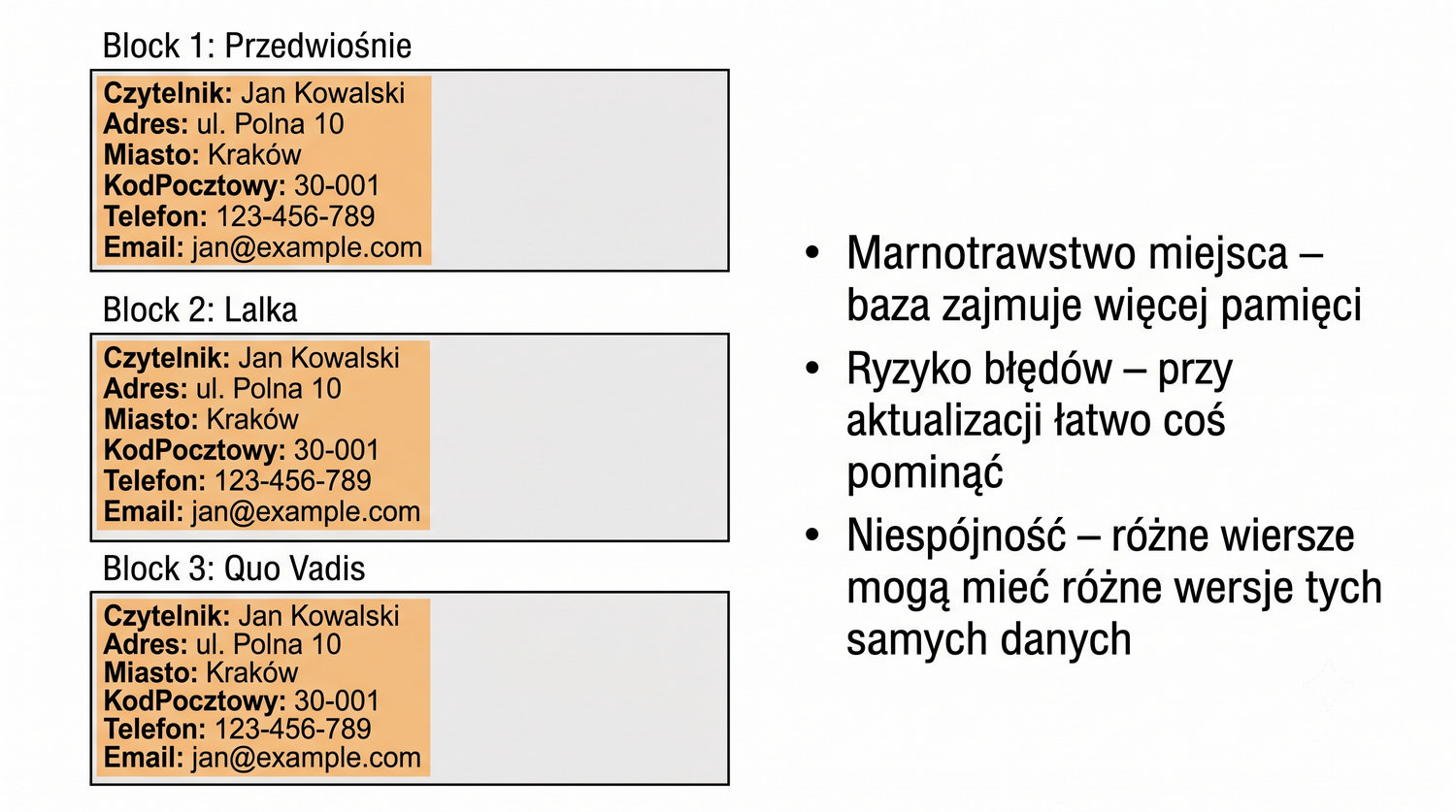
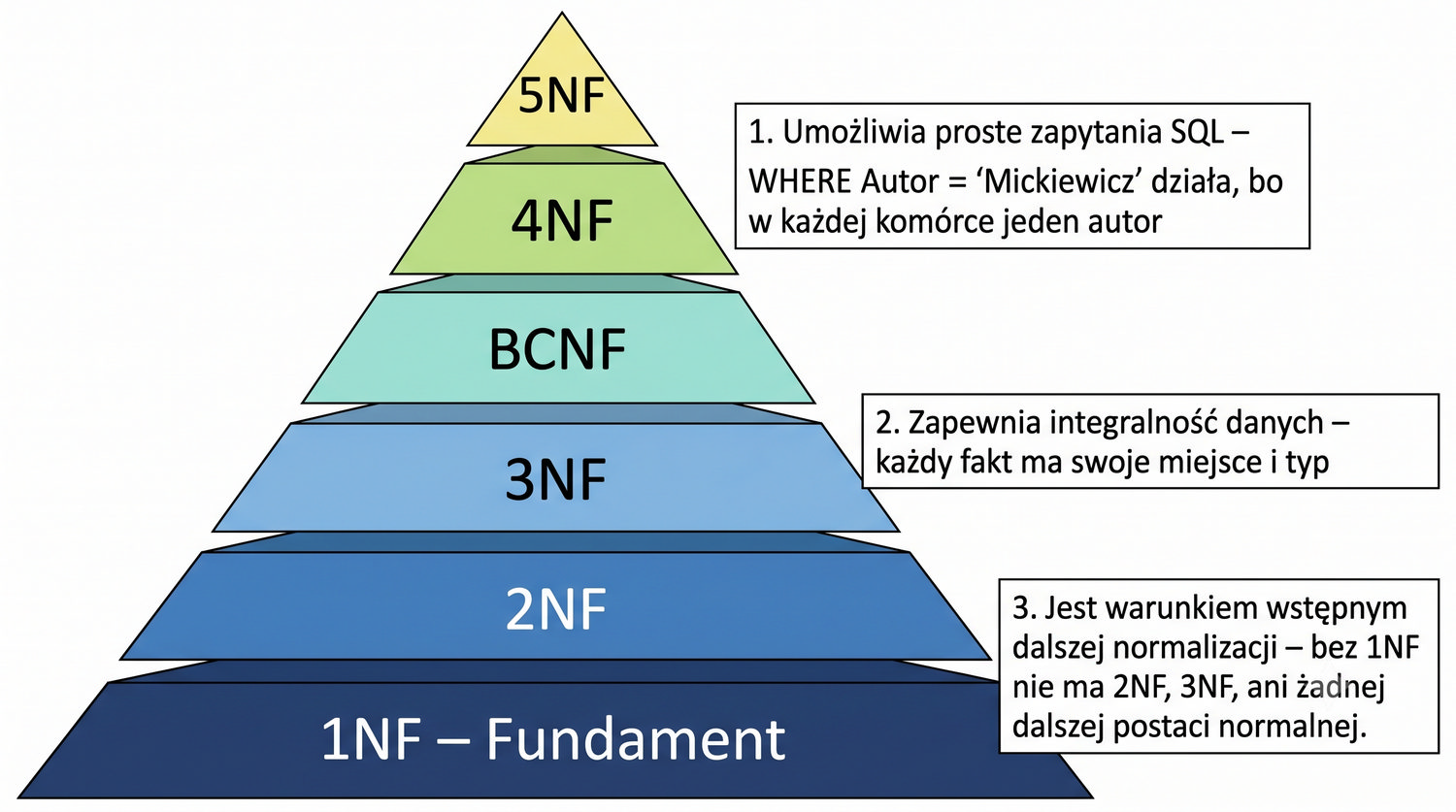
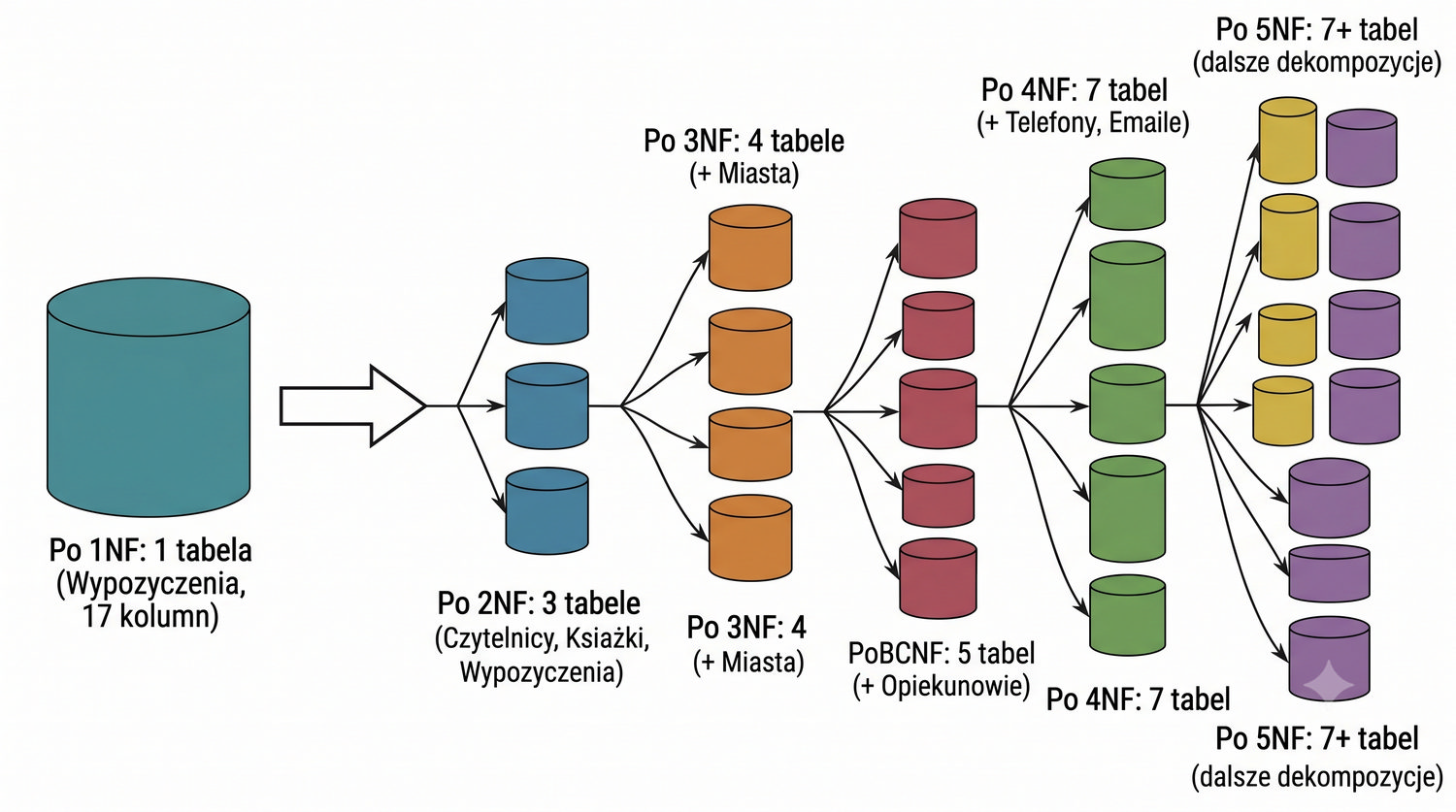
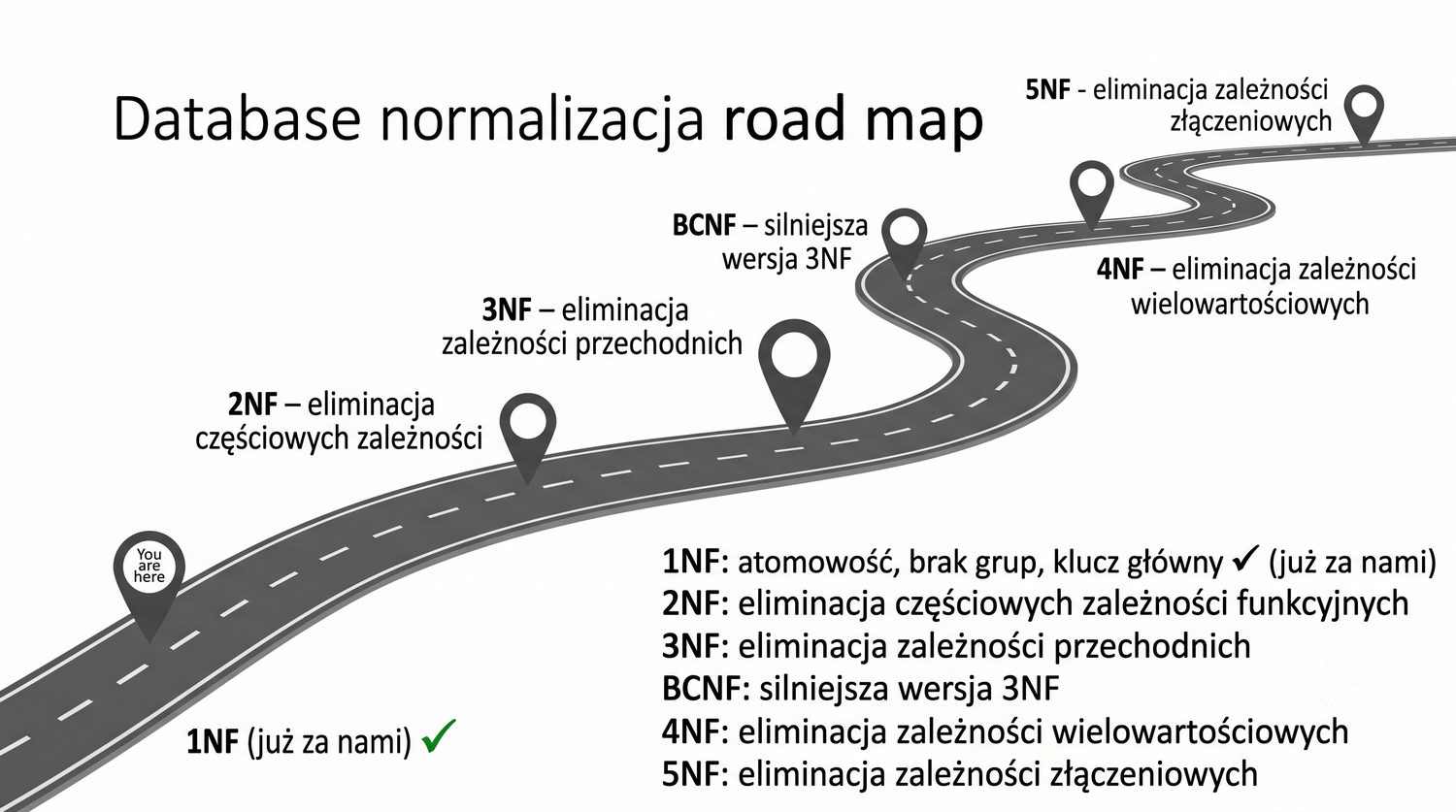
Ta prezentacja jest pierwszą z cyklu o normalizacji. W kolejnych częściach omówimy 2NF, 3NF, BCNF, 4NF i 5NF – wszystkie na tym samym przykładzie systemu bibliotecznego.
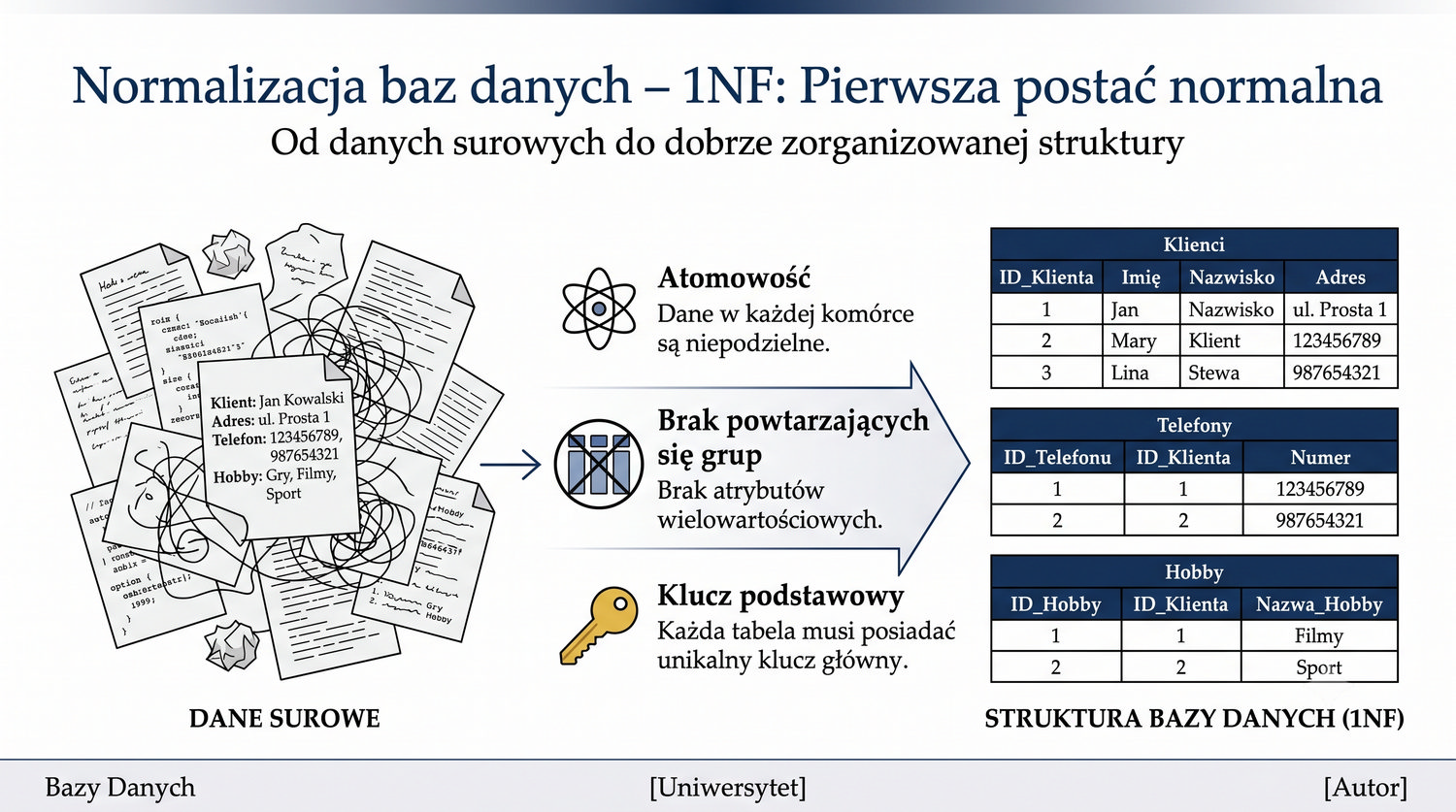
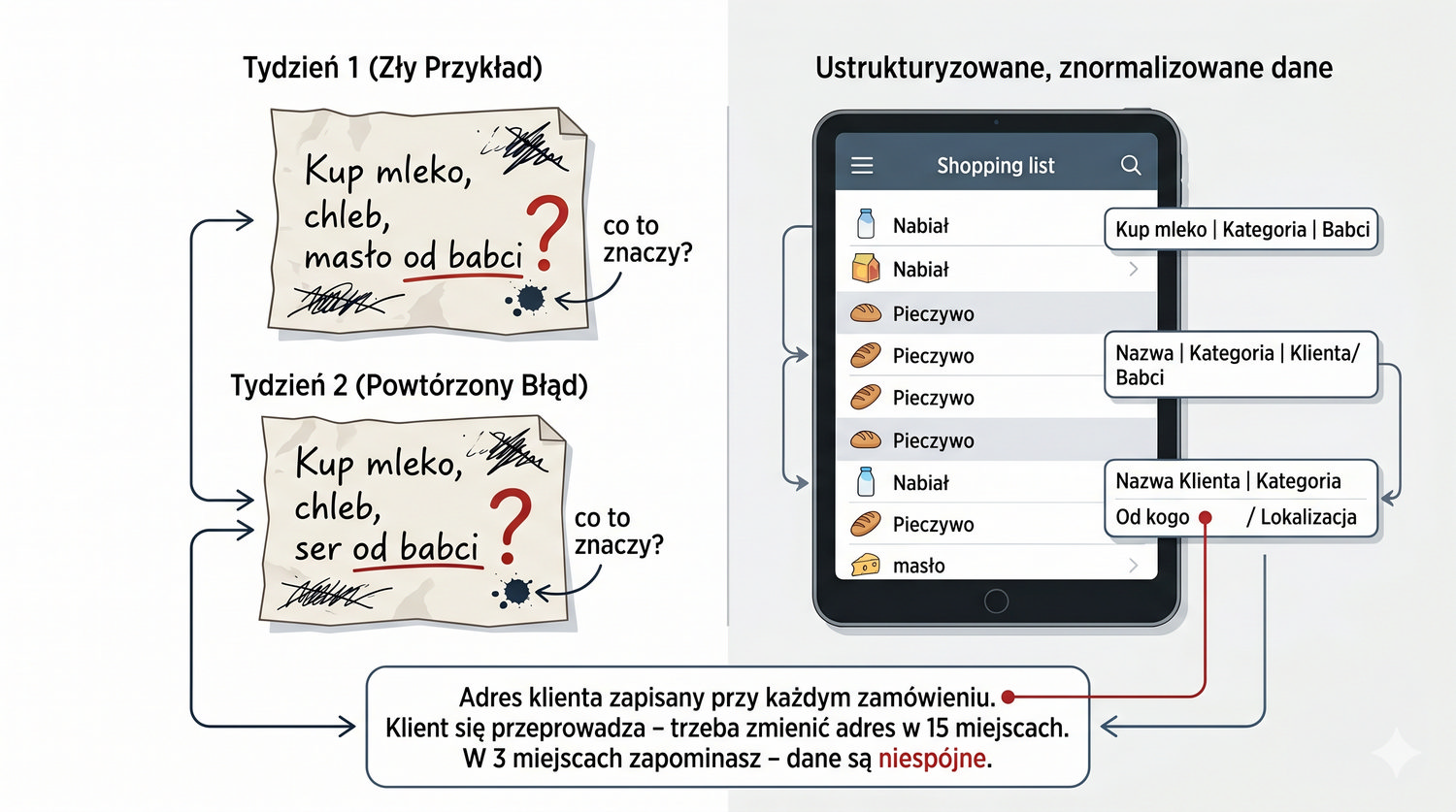
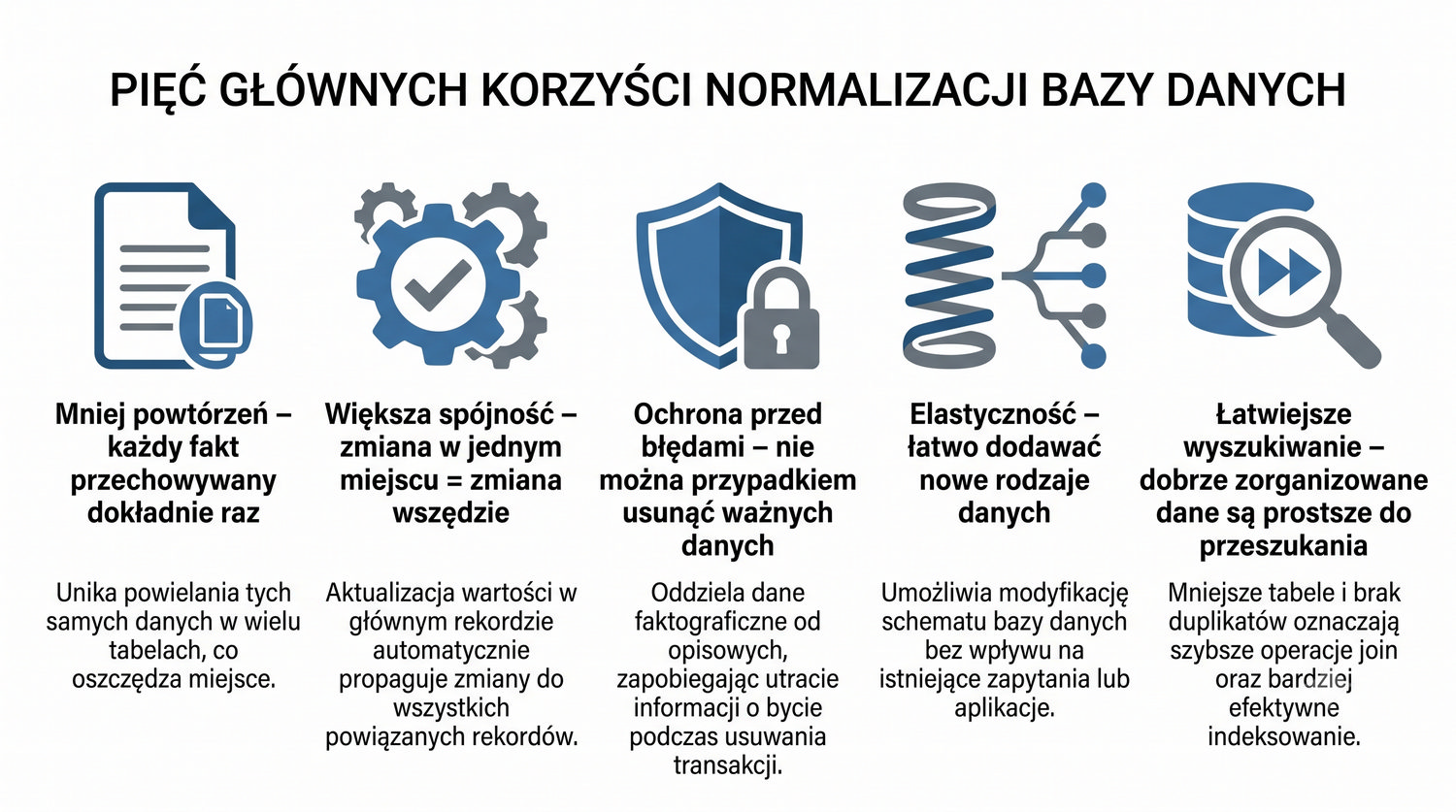
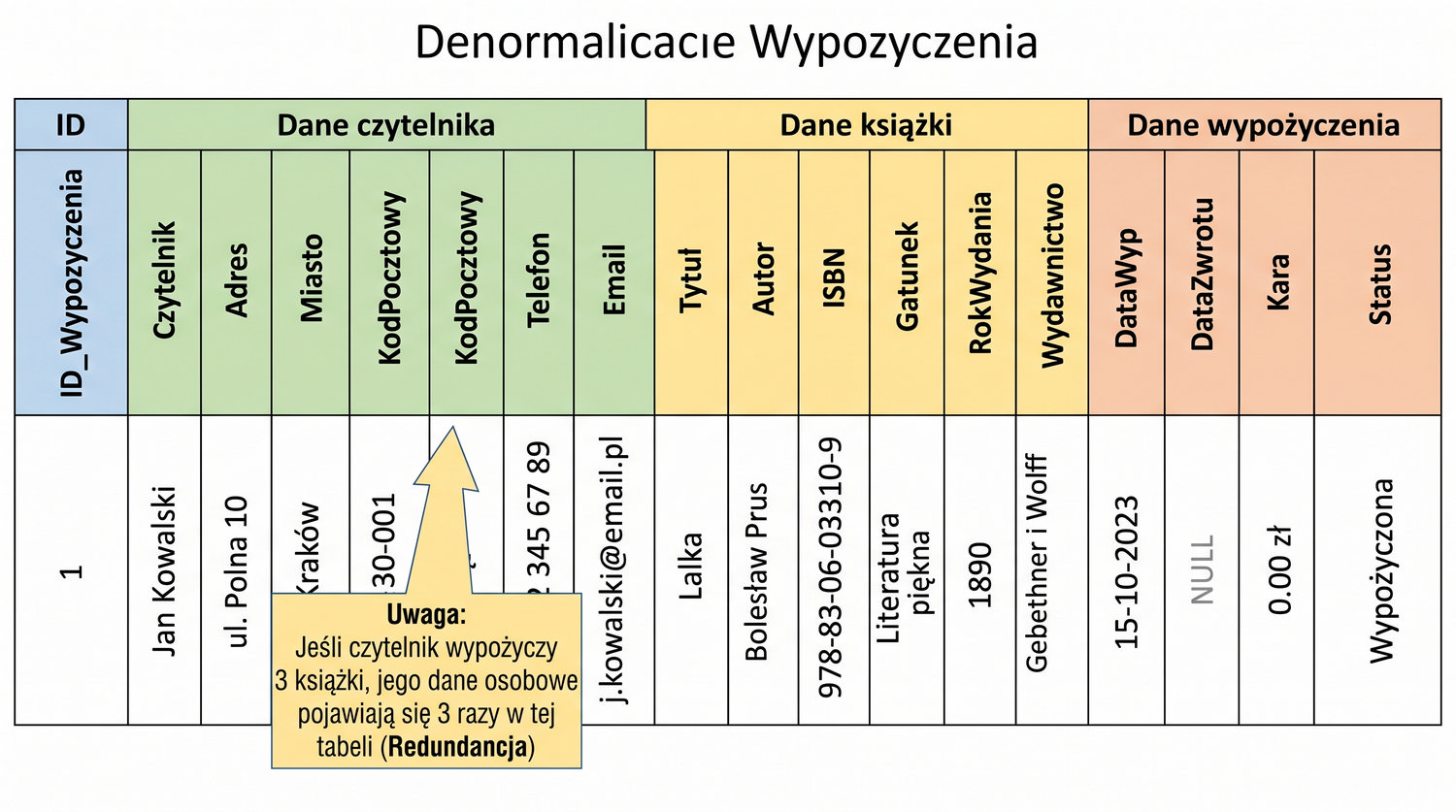
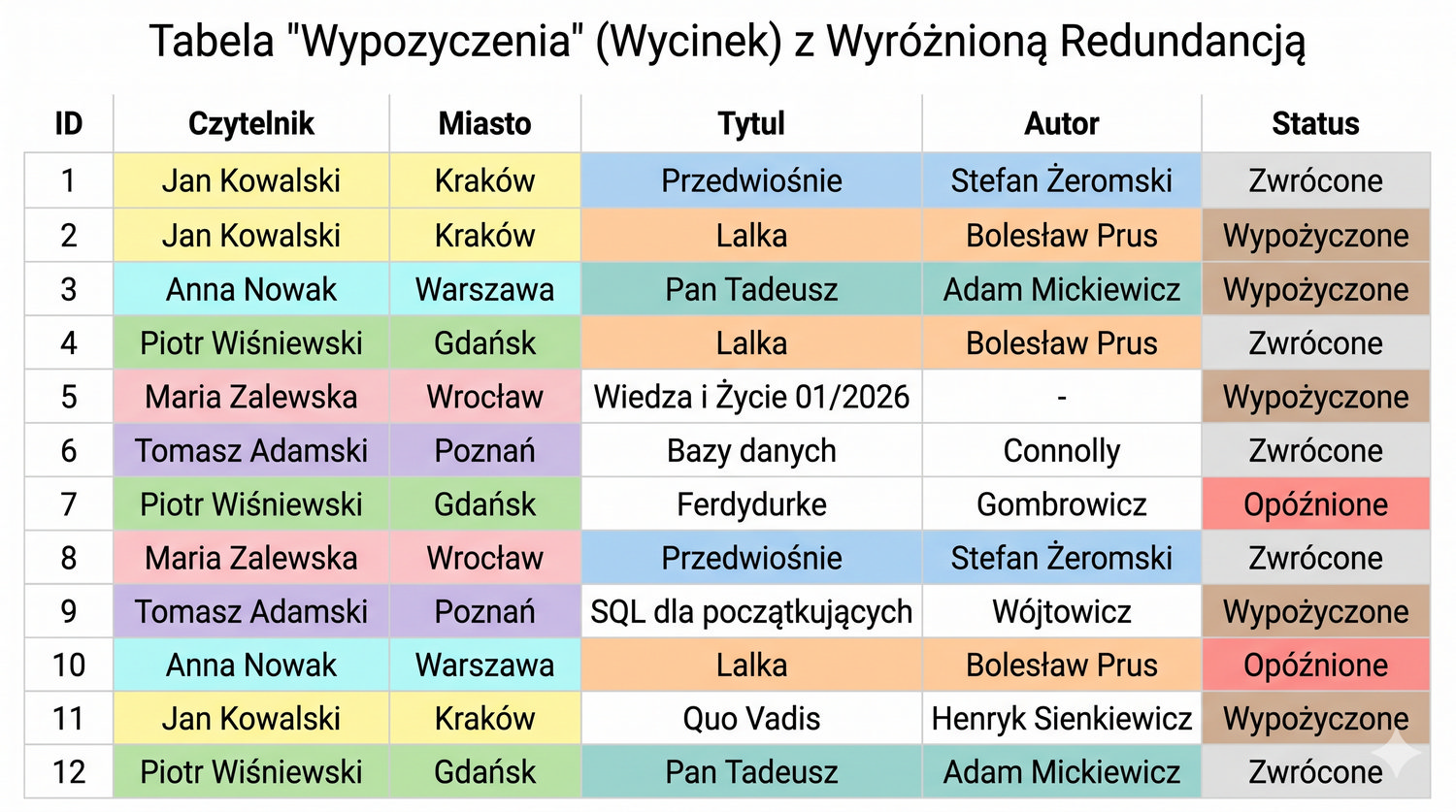
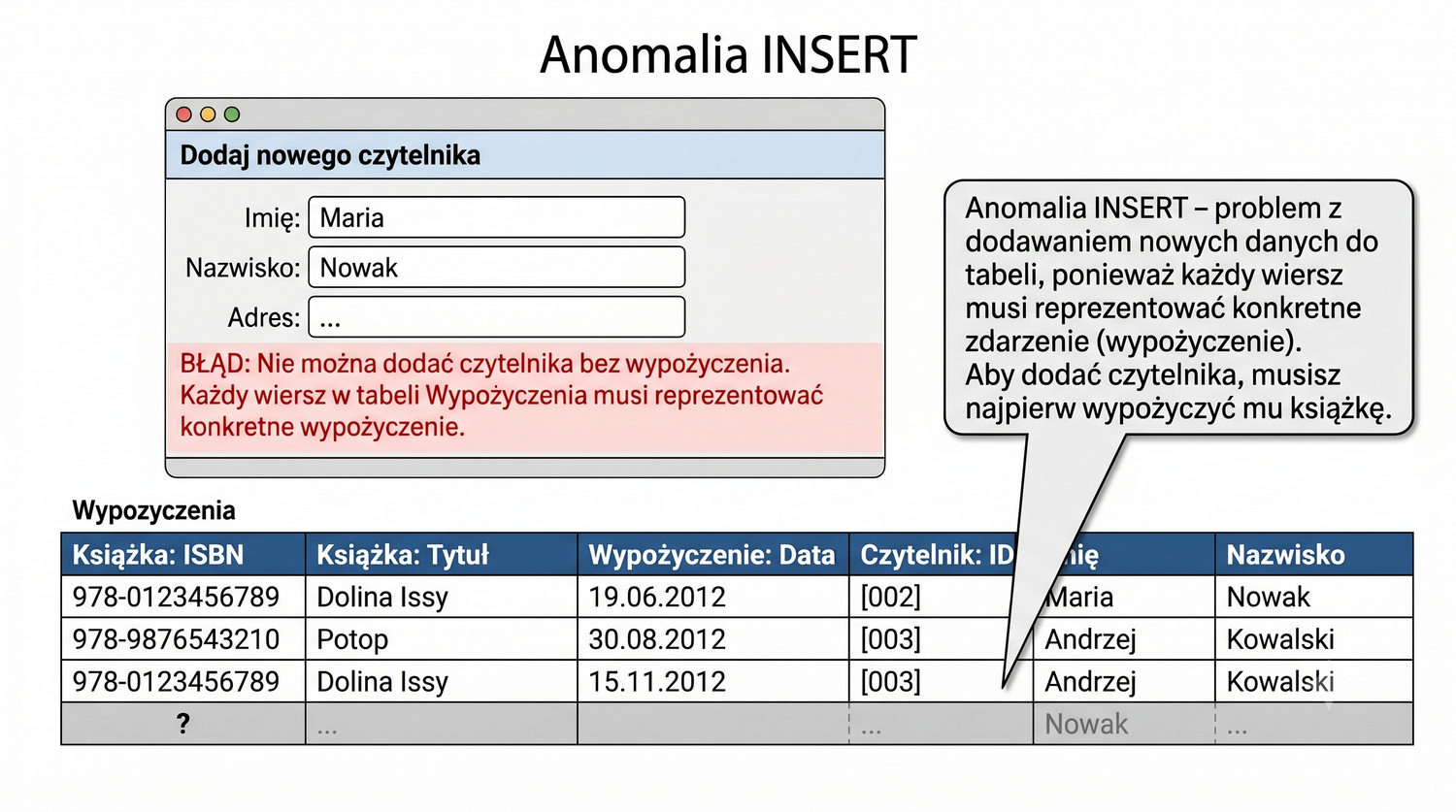
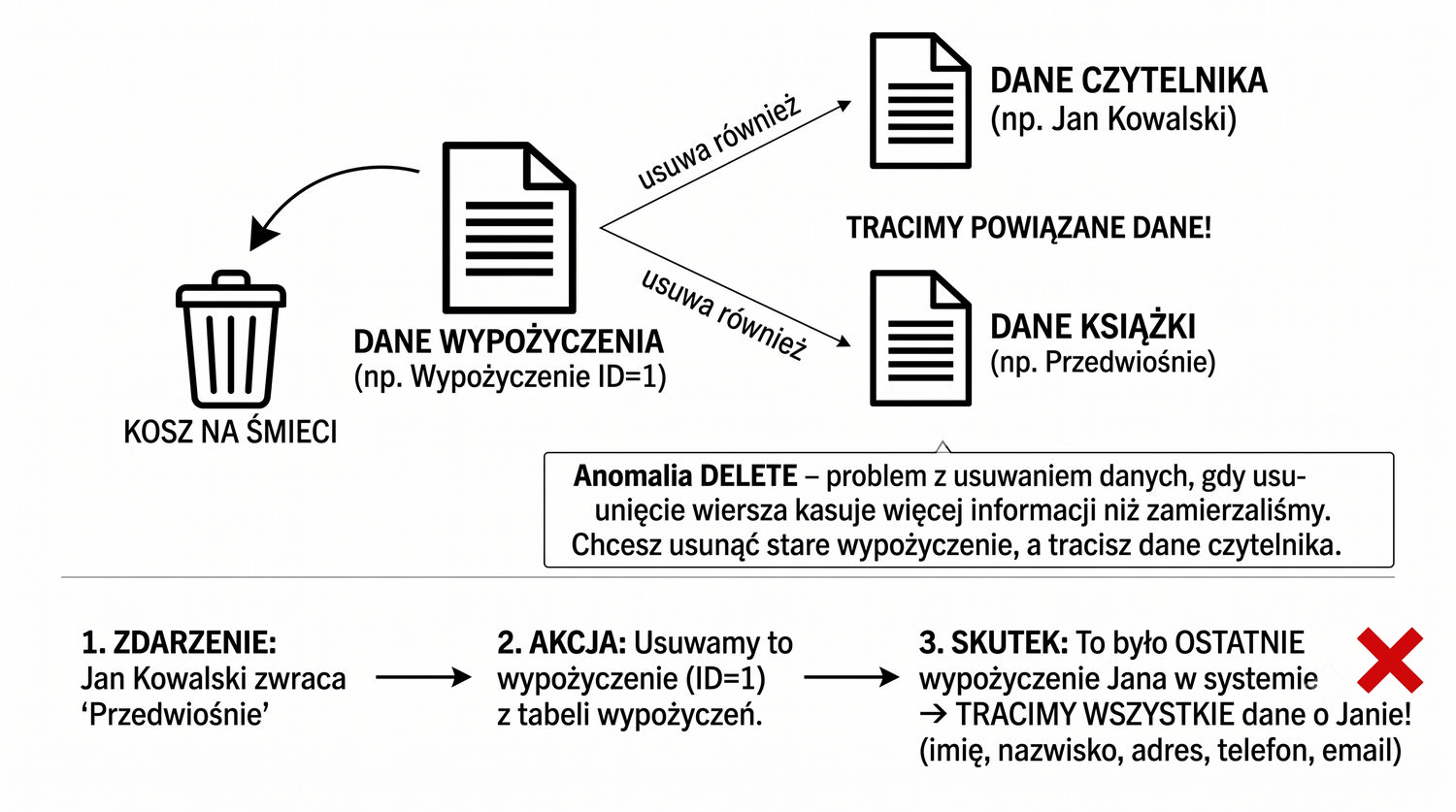
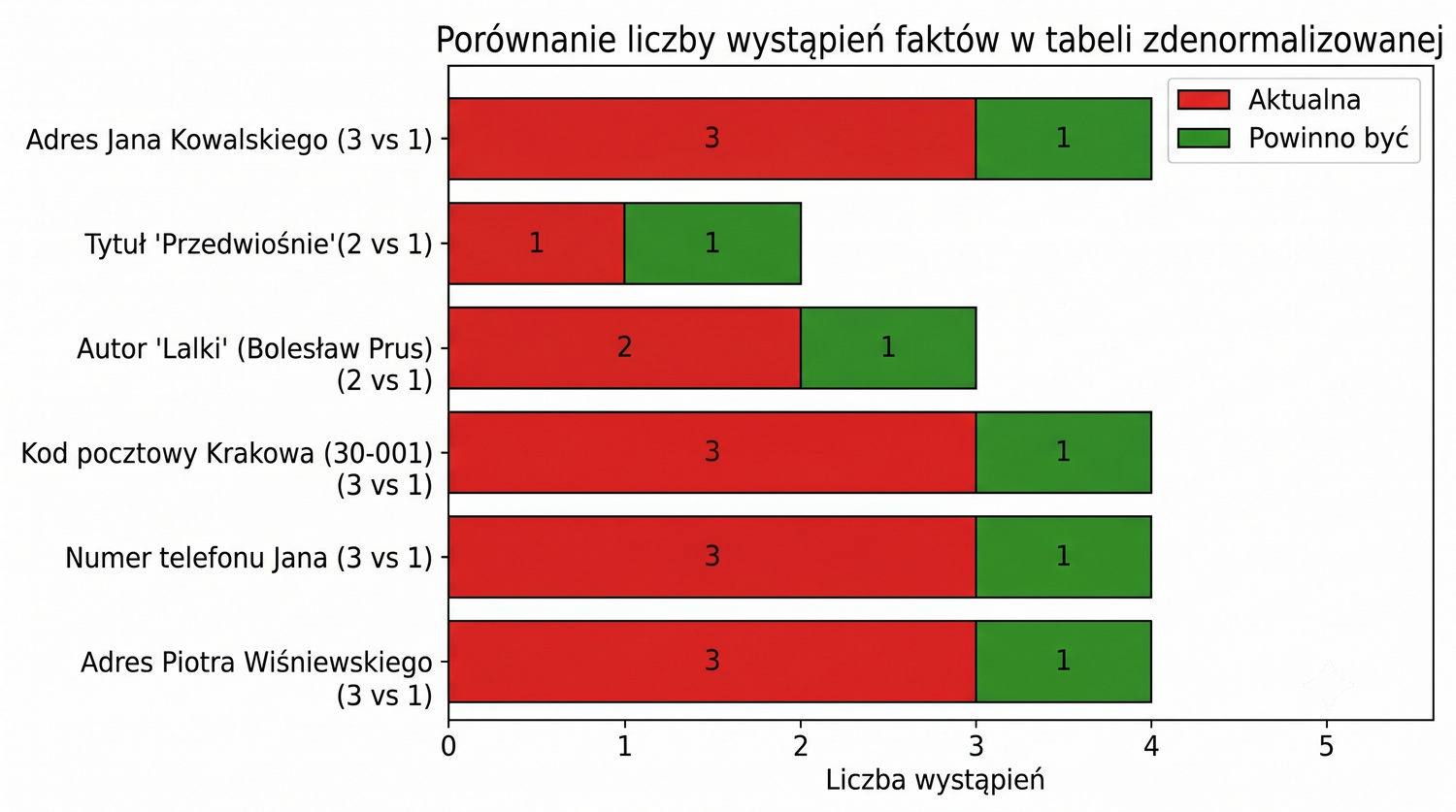
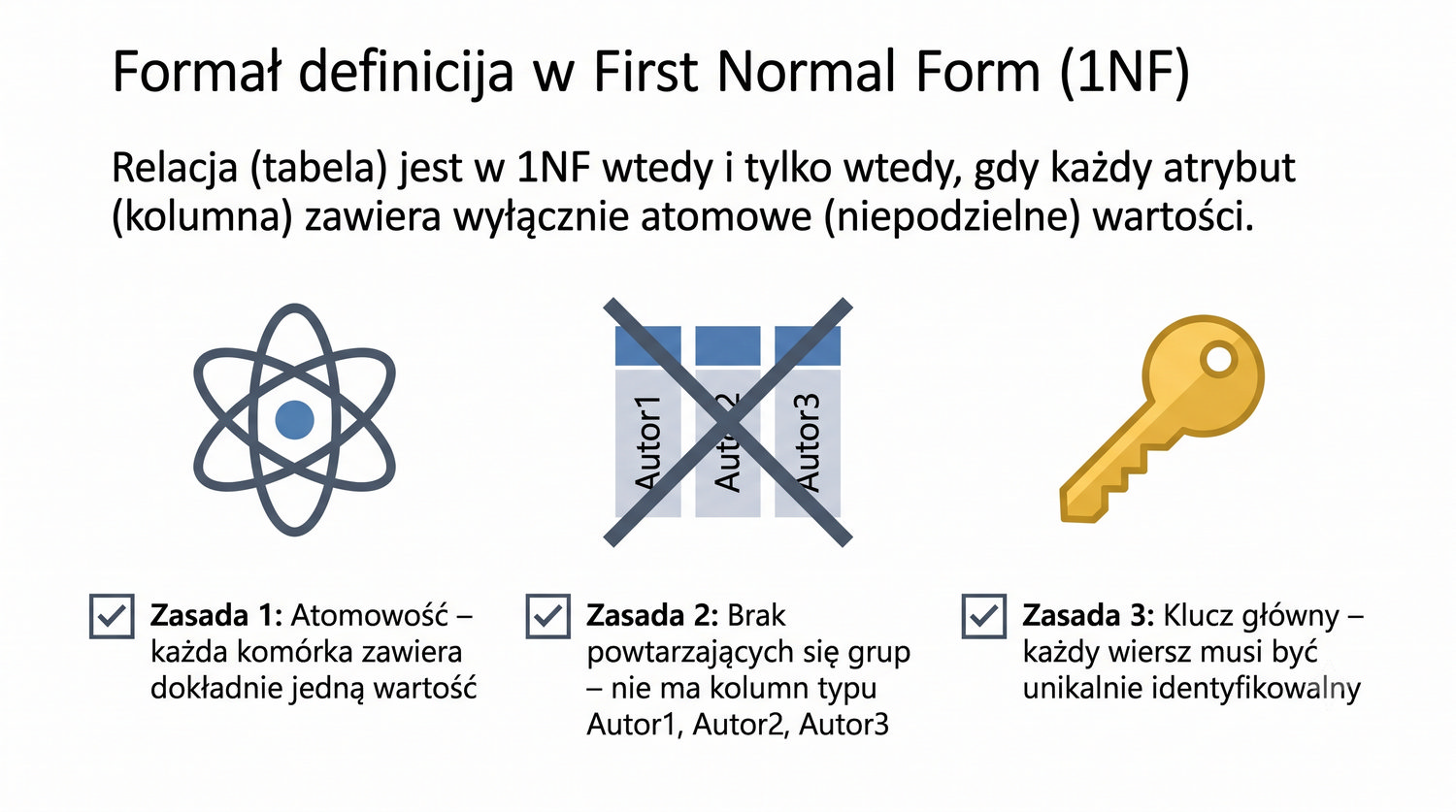
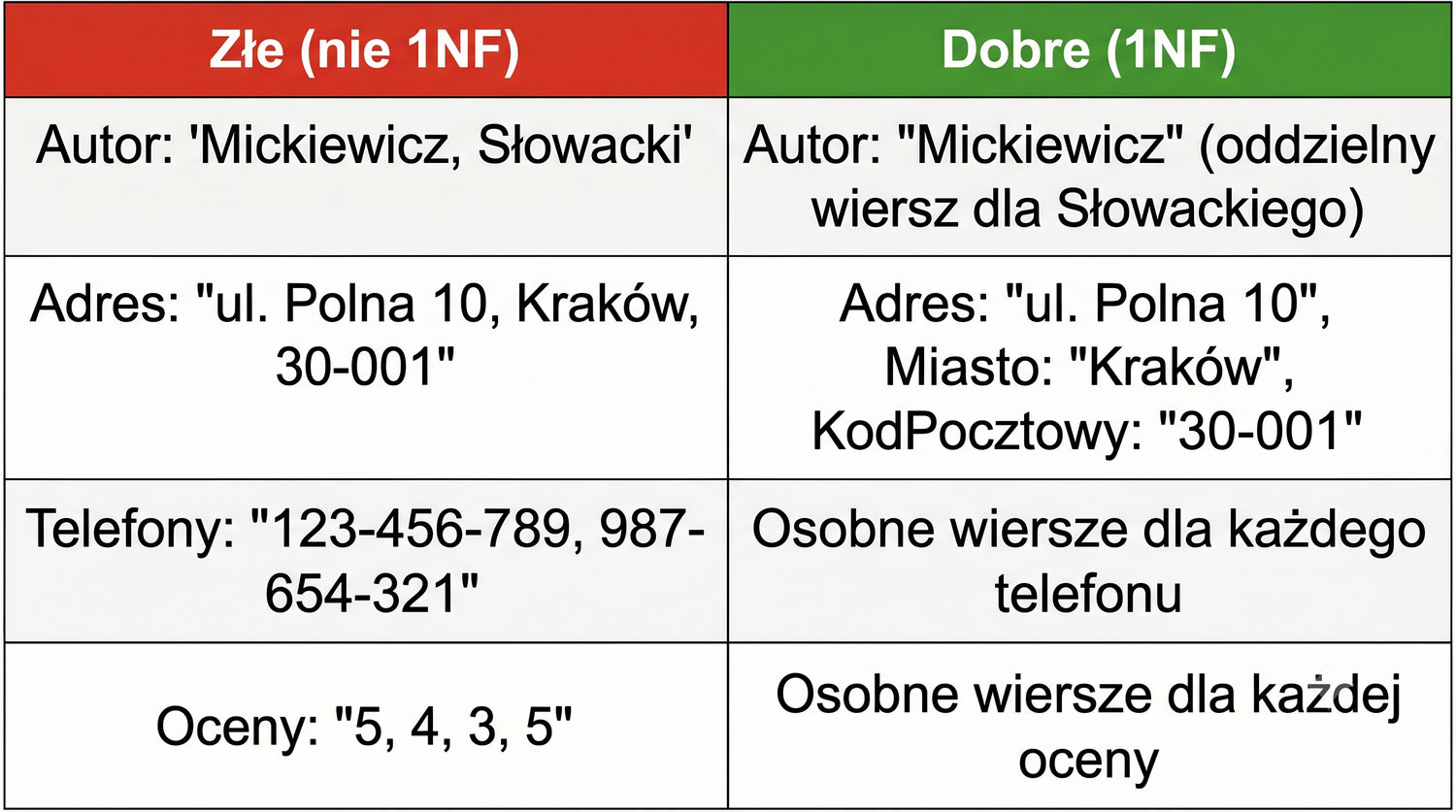
Normalizacja to proces organizacji danych w bazie w celu minimalizacji redundancji i zależności