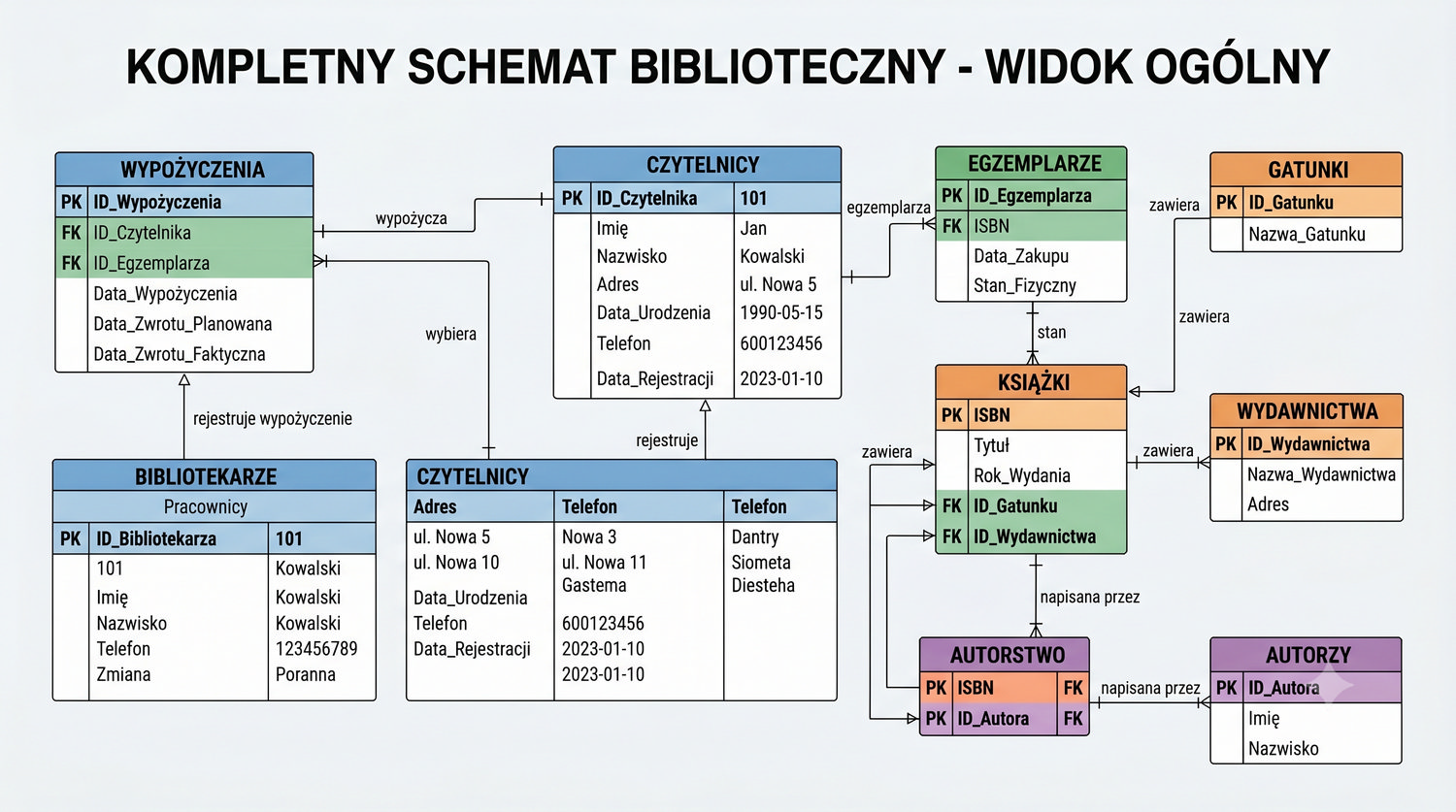
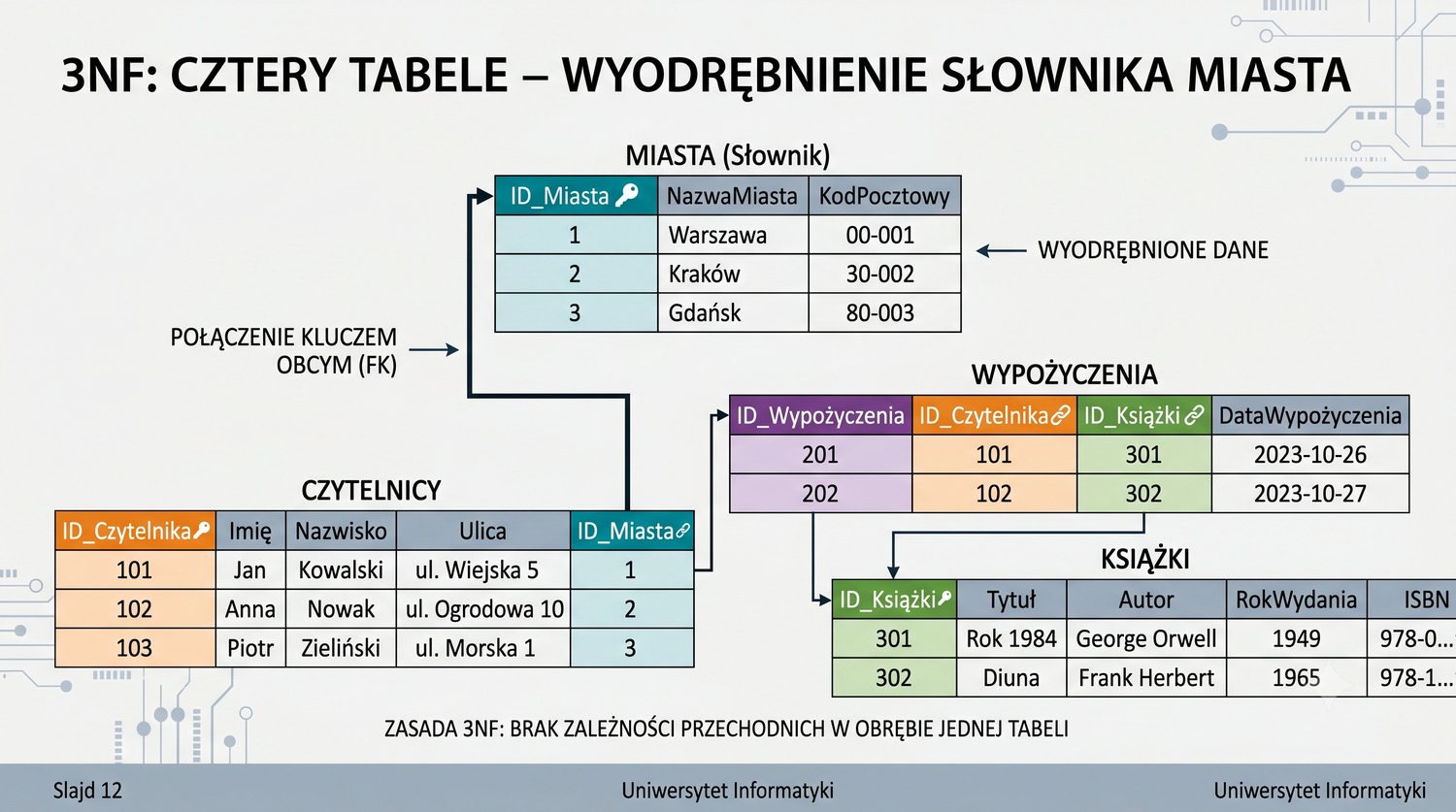
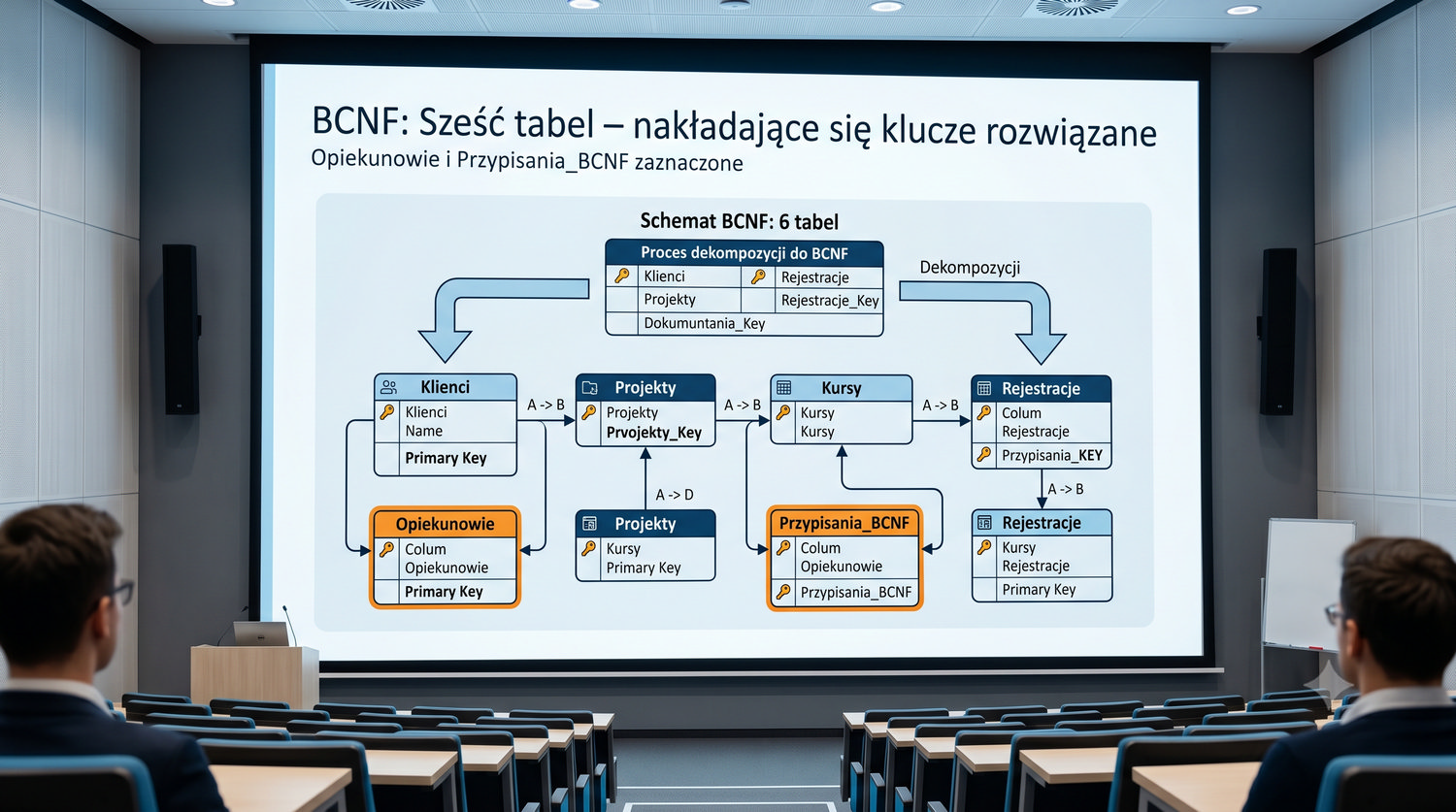
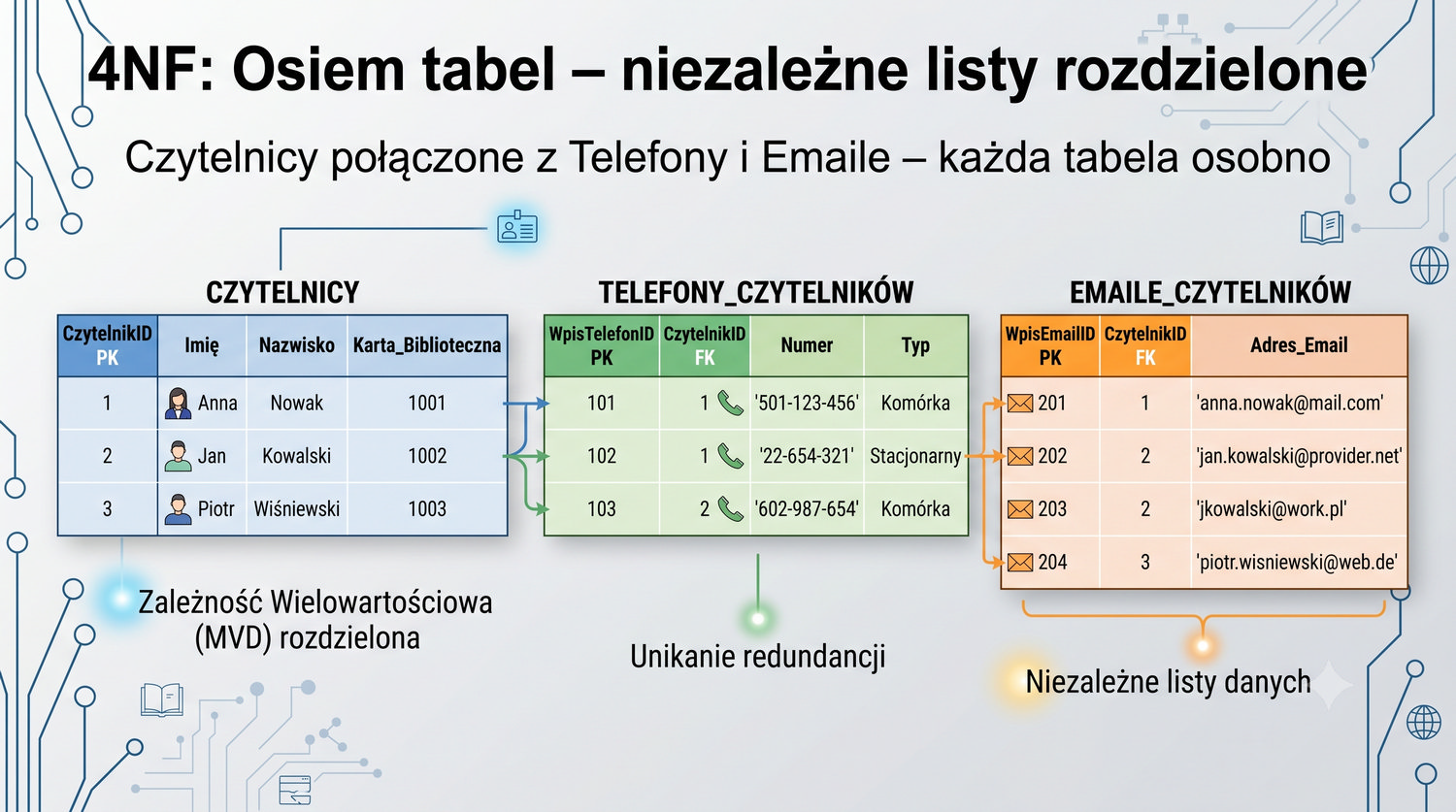
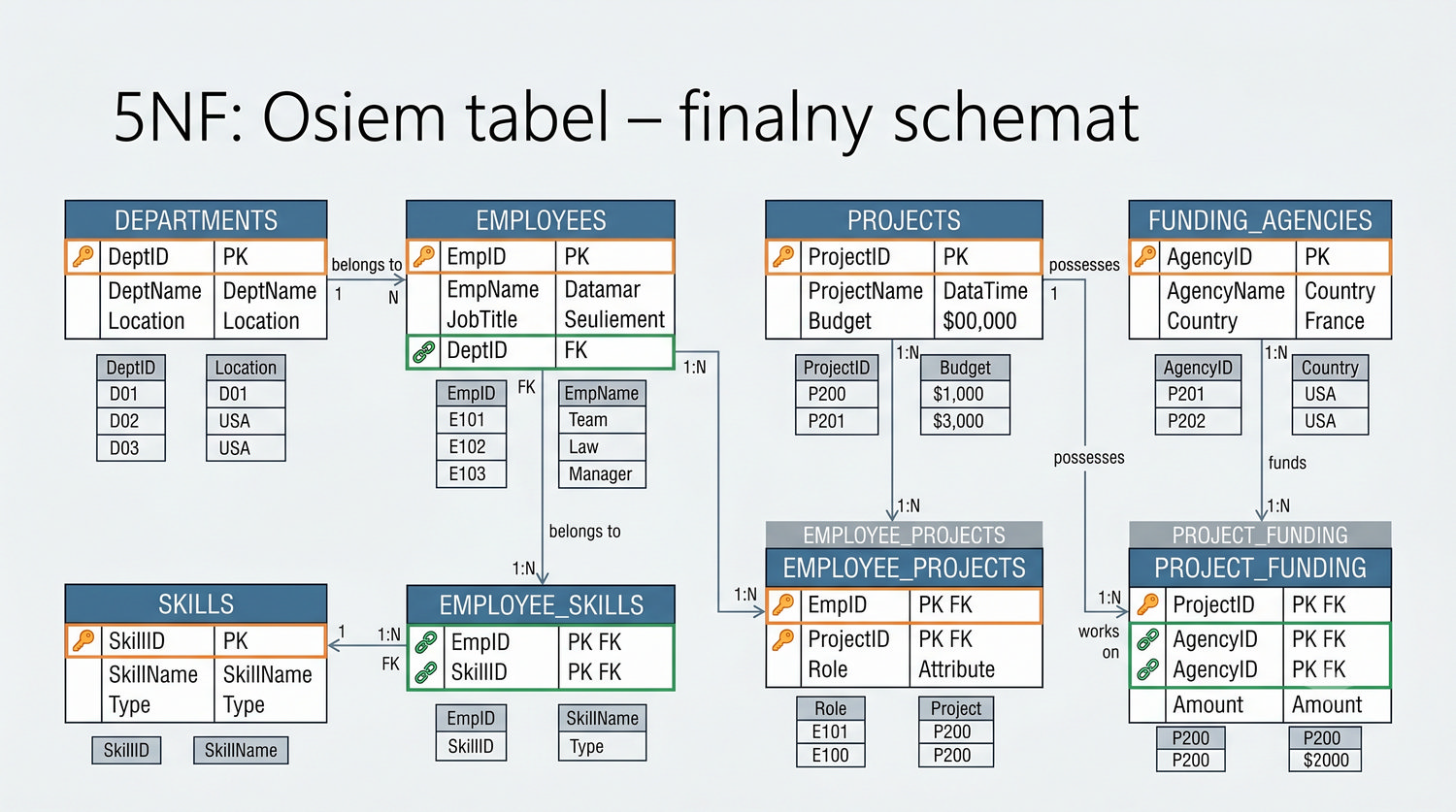
Od 1NF do 5NF – wszystkie tabele w jednym miejscu
Podsumowuje cały proces normalizacji systemu bibliotecznego.
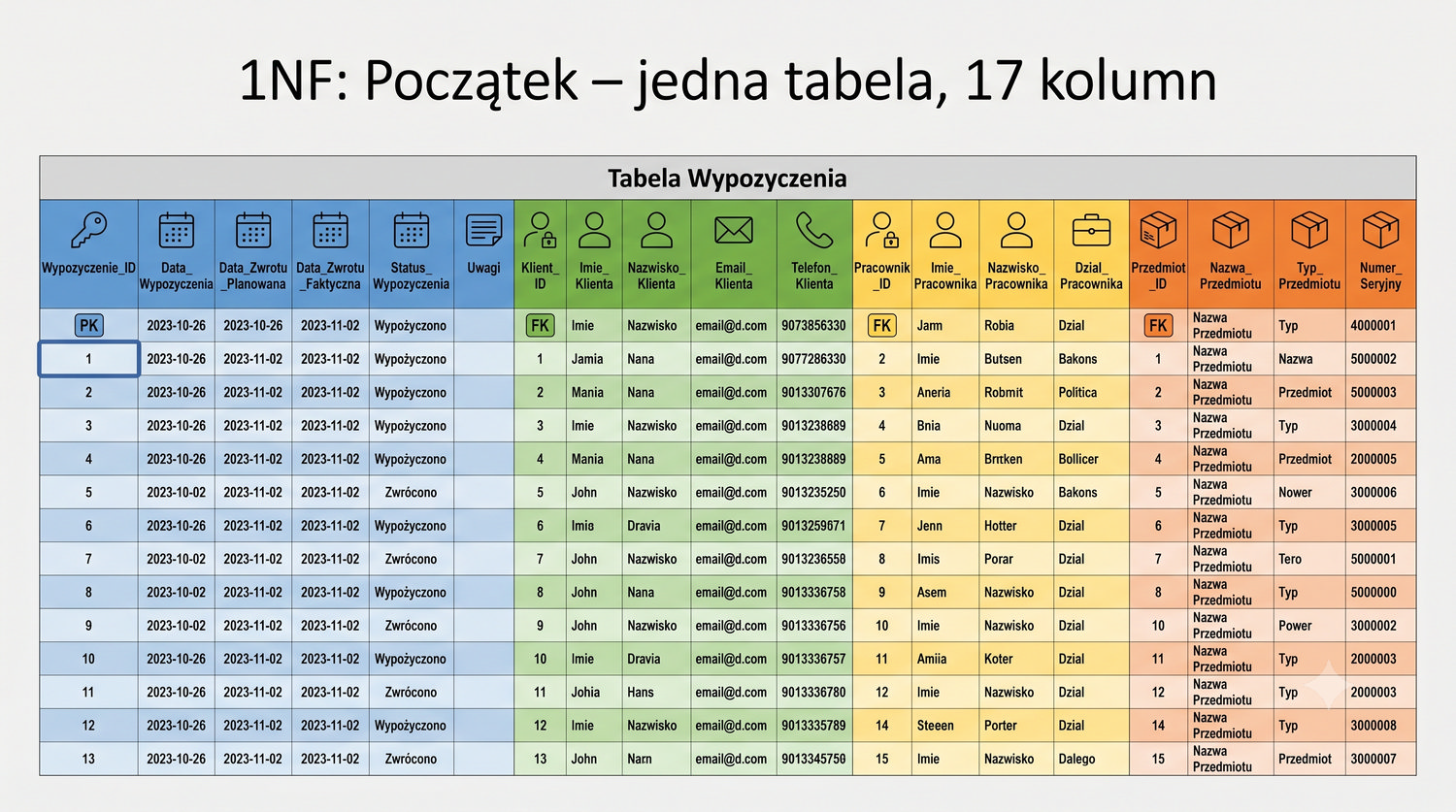
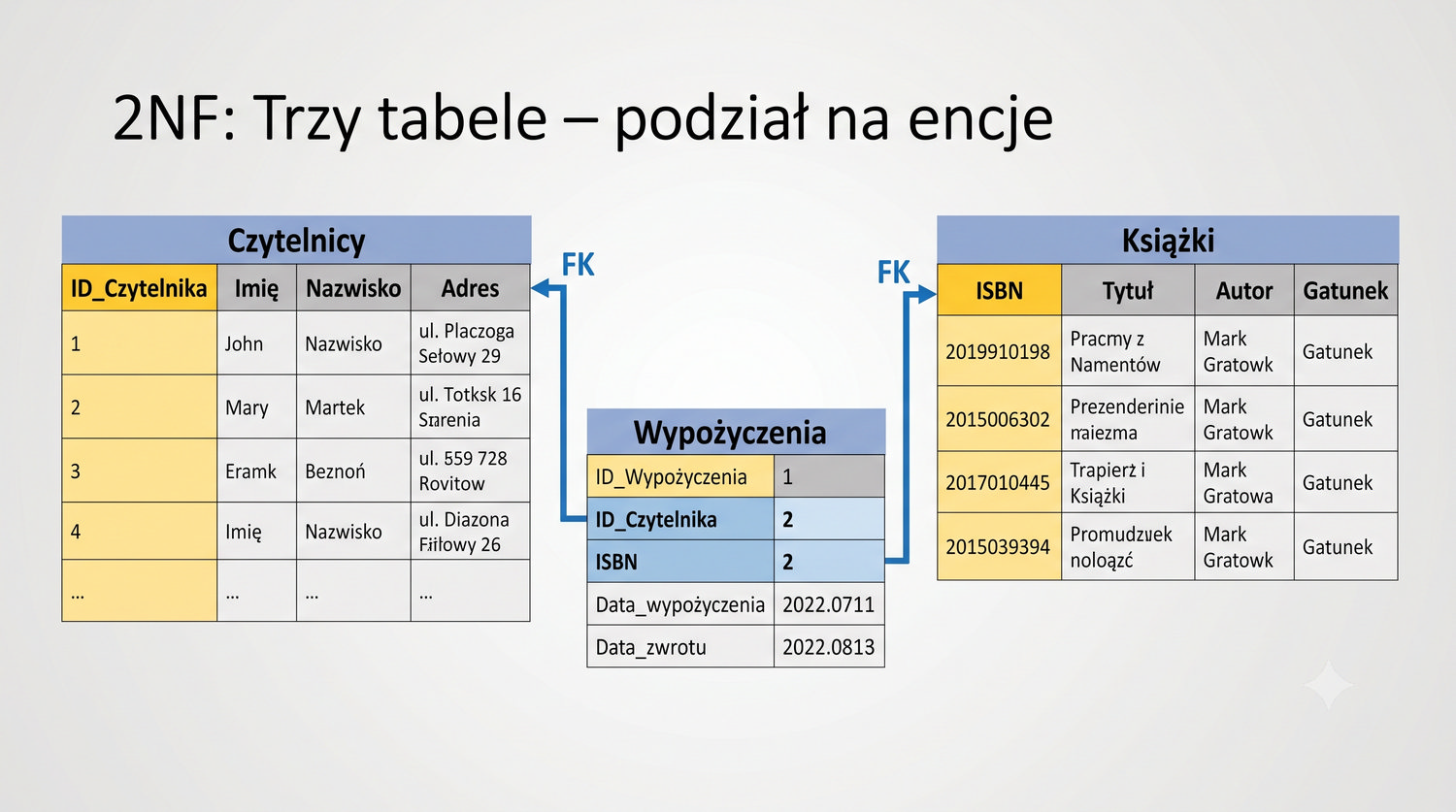
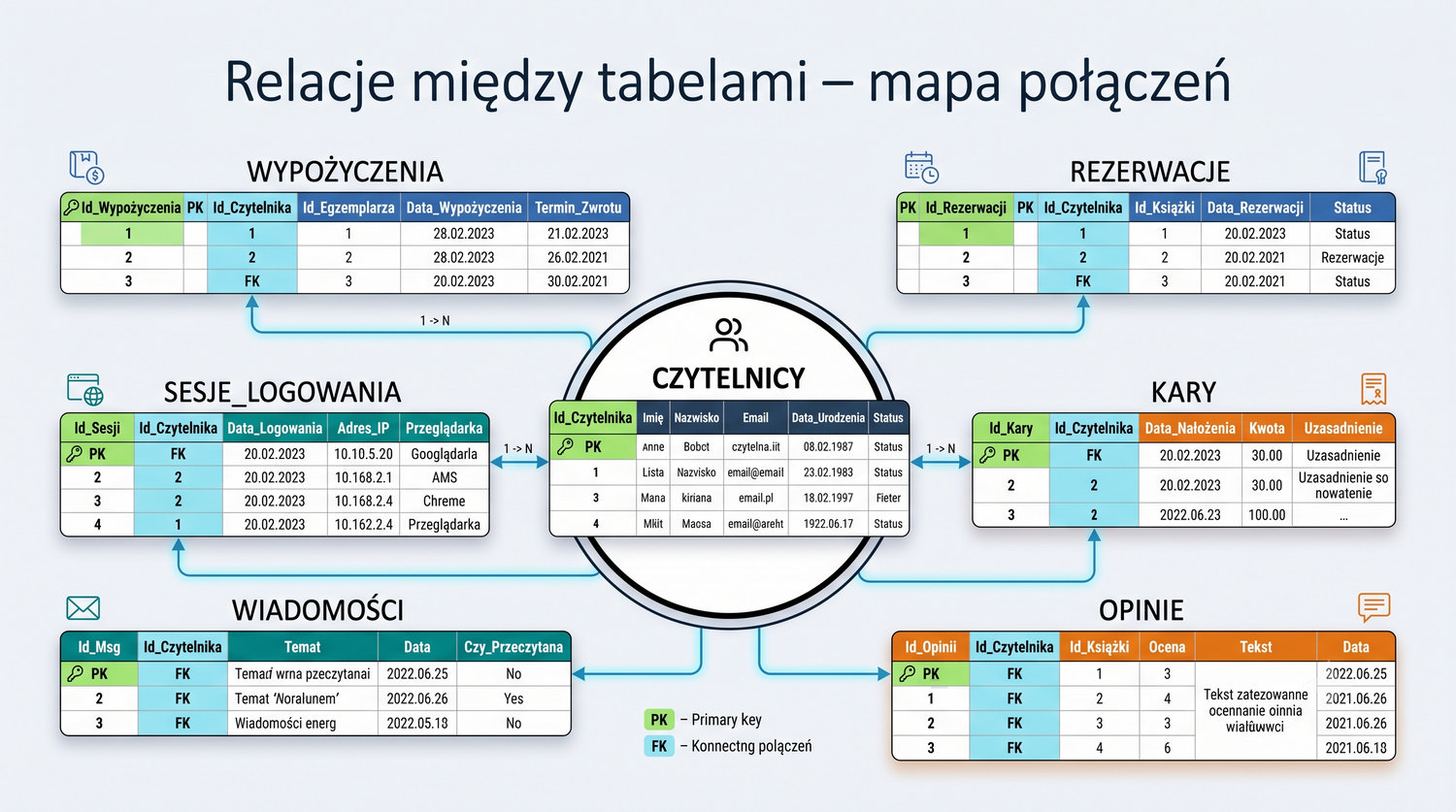
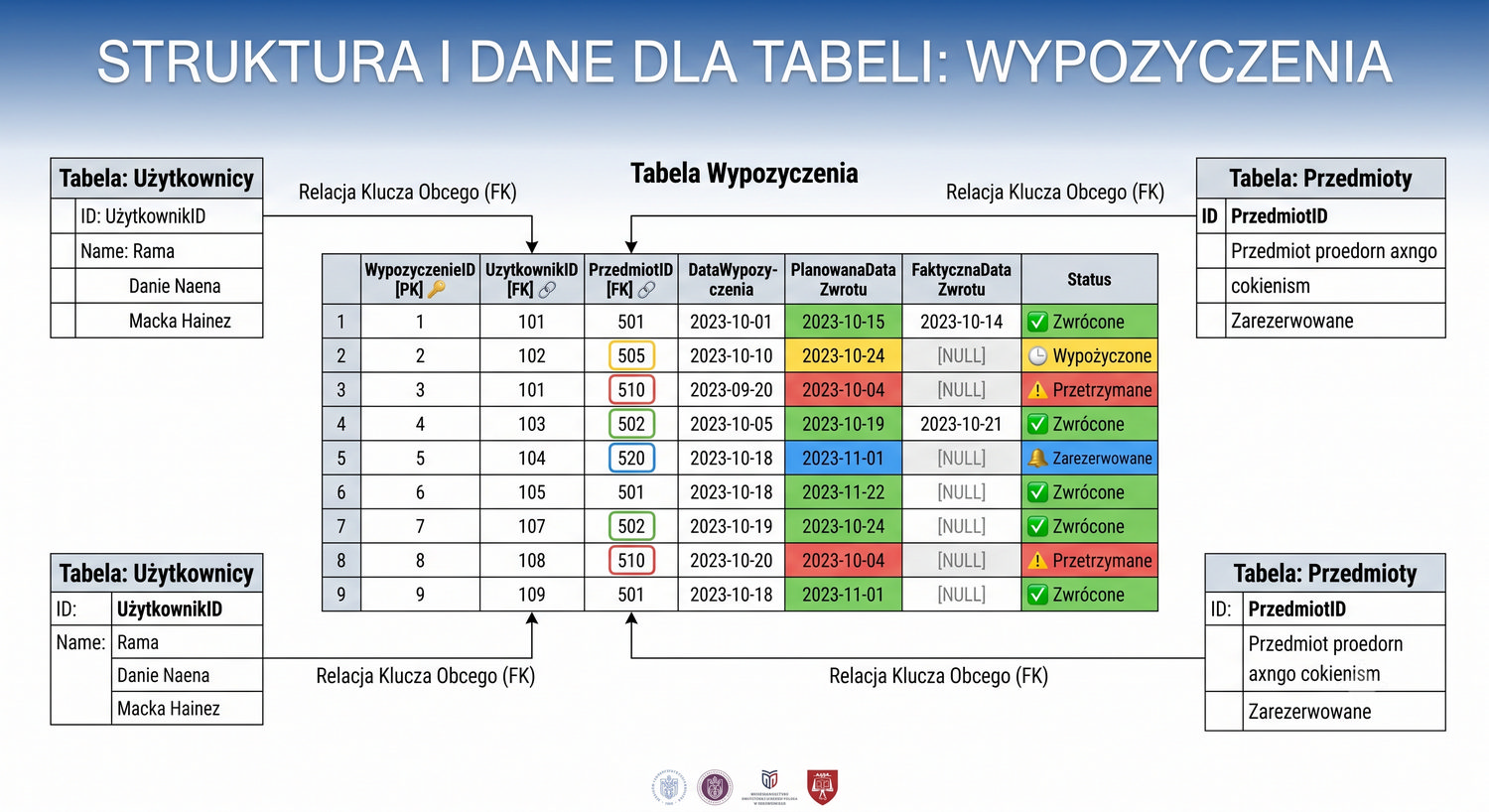
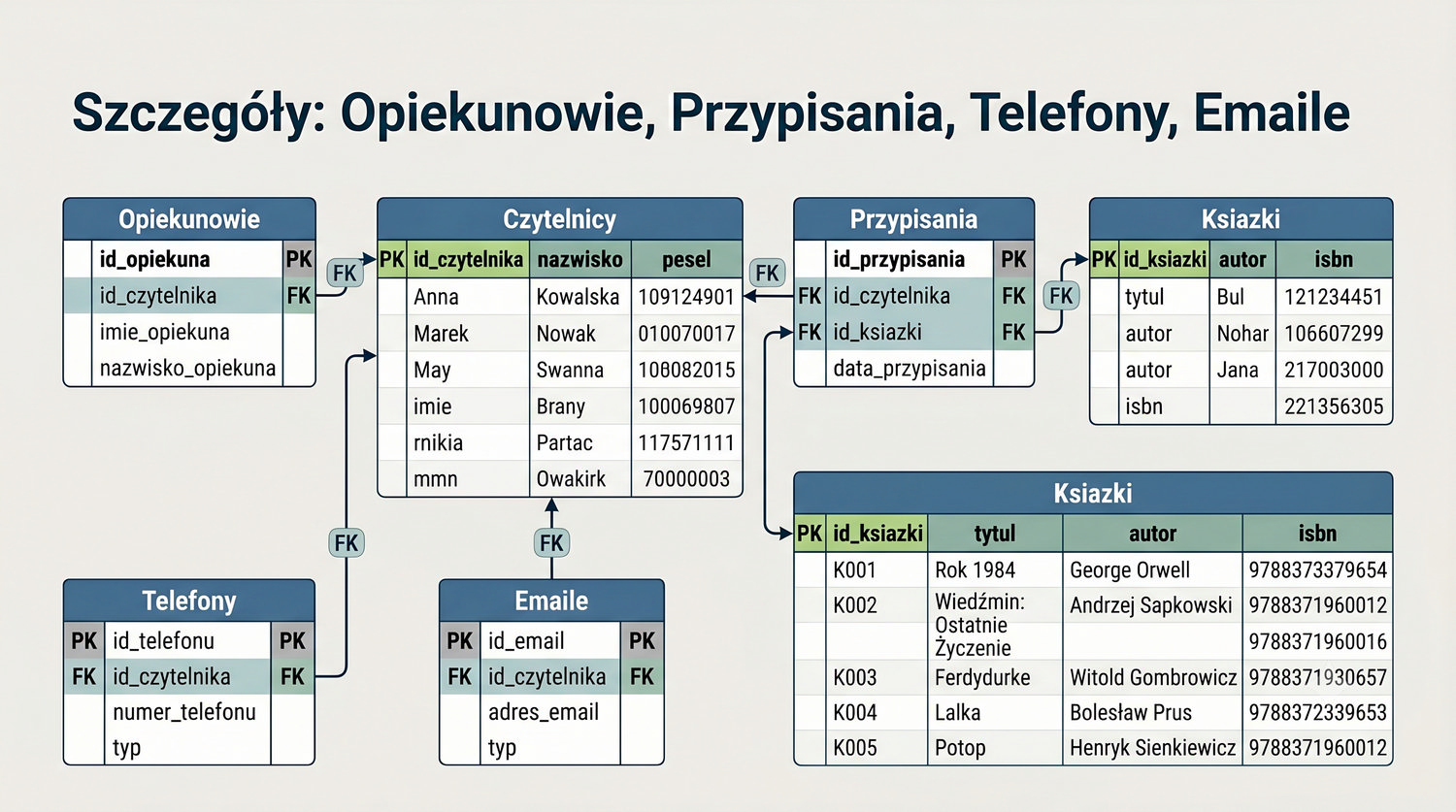
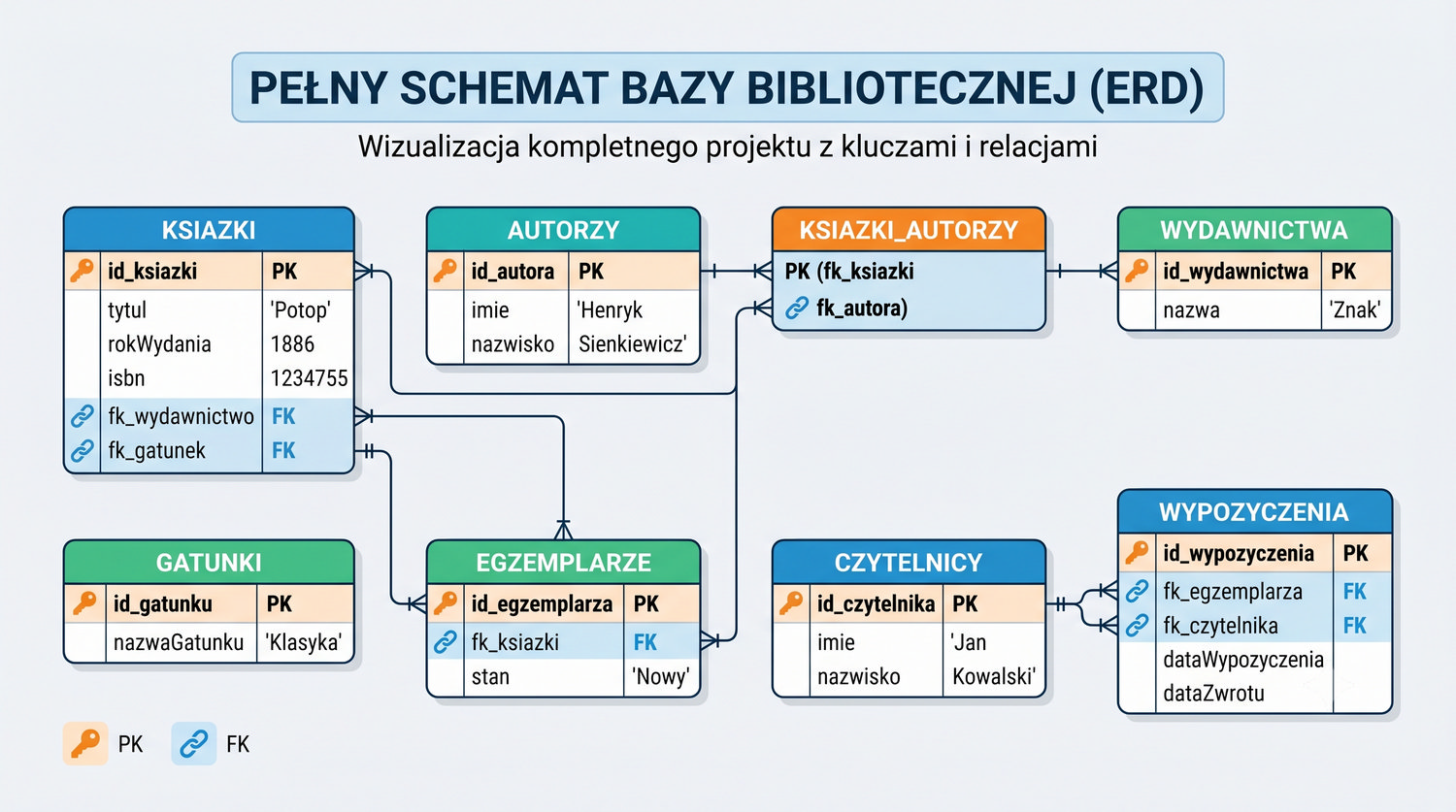
W cyklu normalizacji przeszliśmy od jednej tabeli z 17 kolumnami do ośmiu czystych, wyspecjalizowanych tabel.
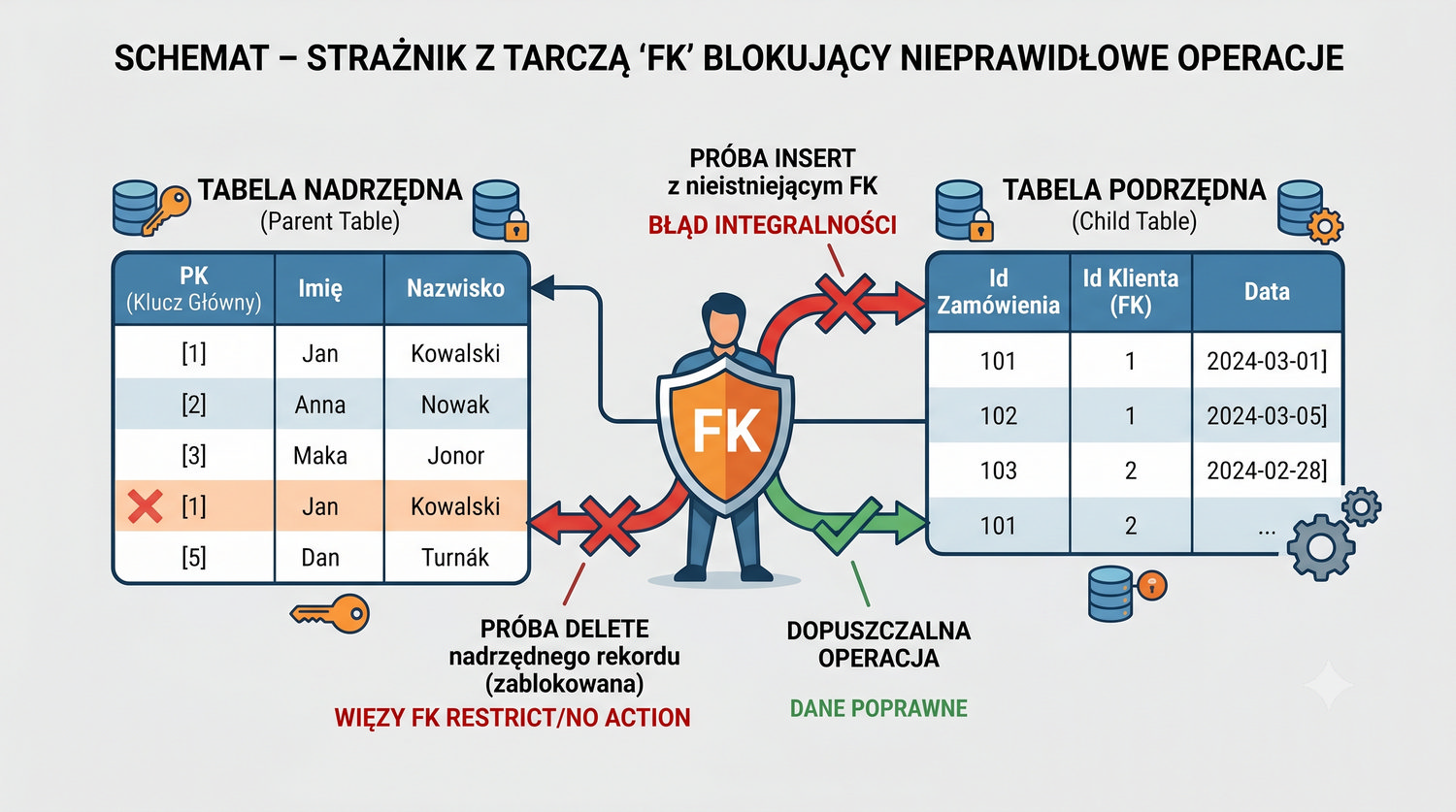
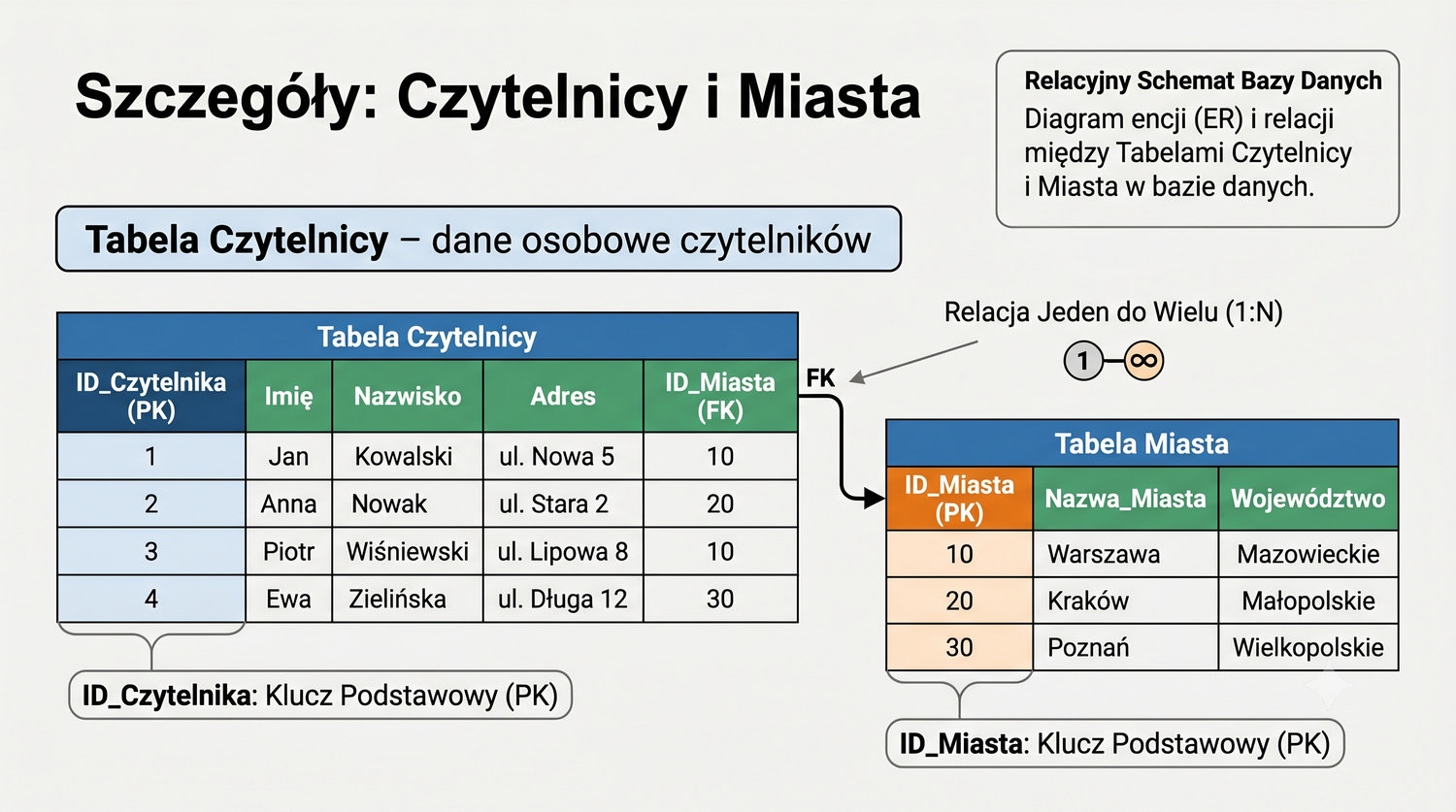
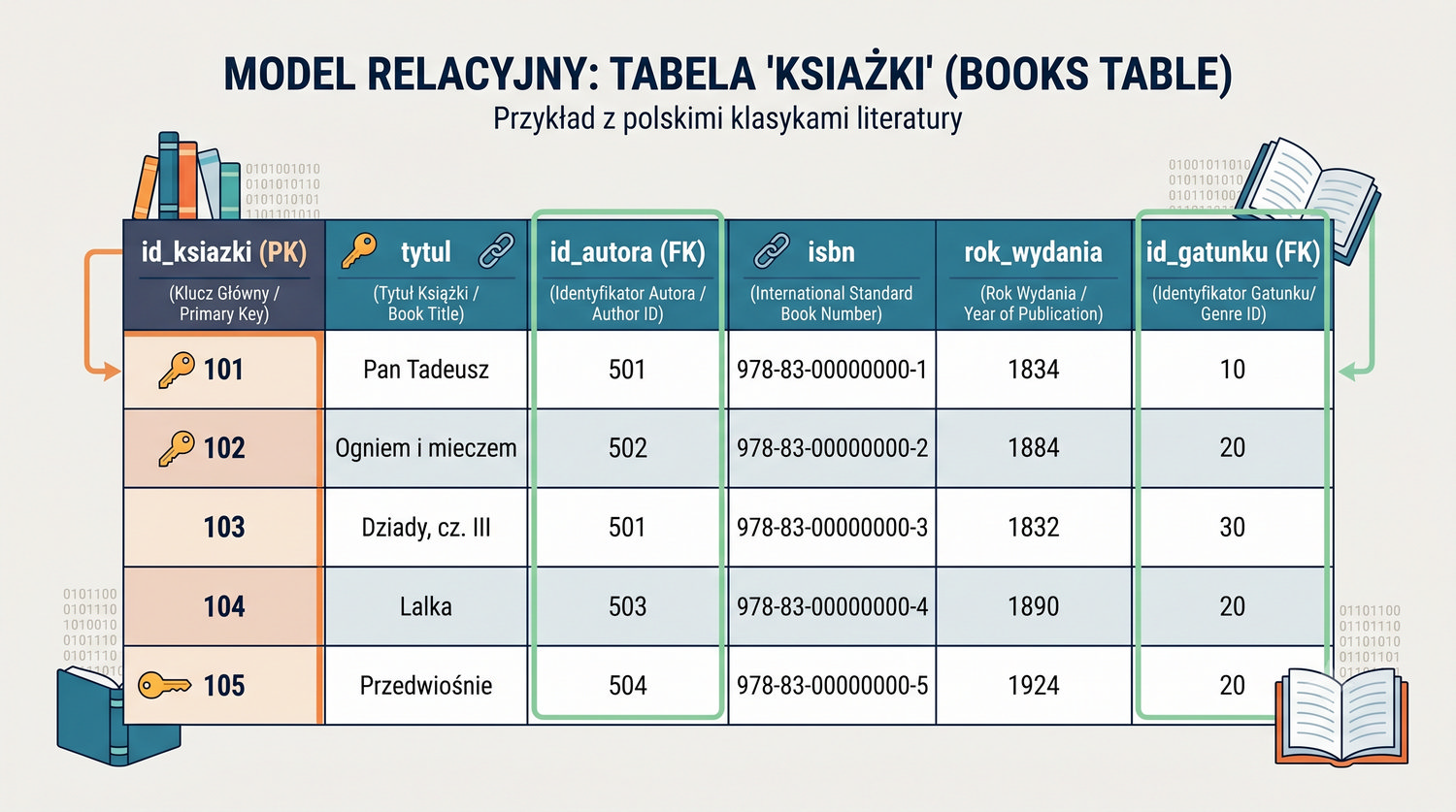
Ta prezentacja zbiera wszystkie tabele w jednym miejscu – pokazuje strukturę, klucze, relacje i zależności.
Widok = widok ogólny. Tu zobaczysz cały schemat bazy – od 1NF po 5NF – w jednym miejscu.