Od danych surowych do dobrze zorganizowanej struktury – krok drugi
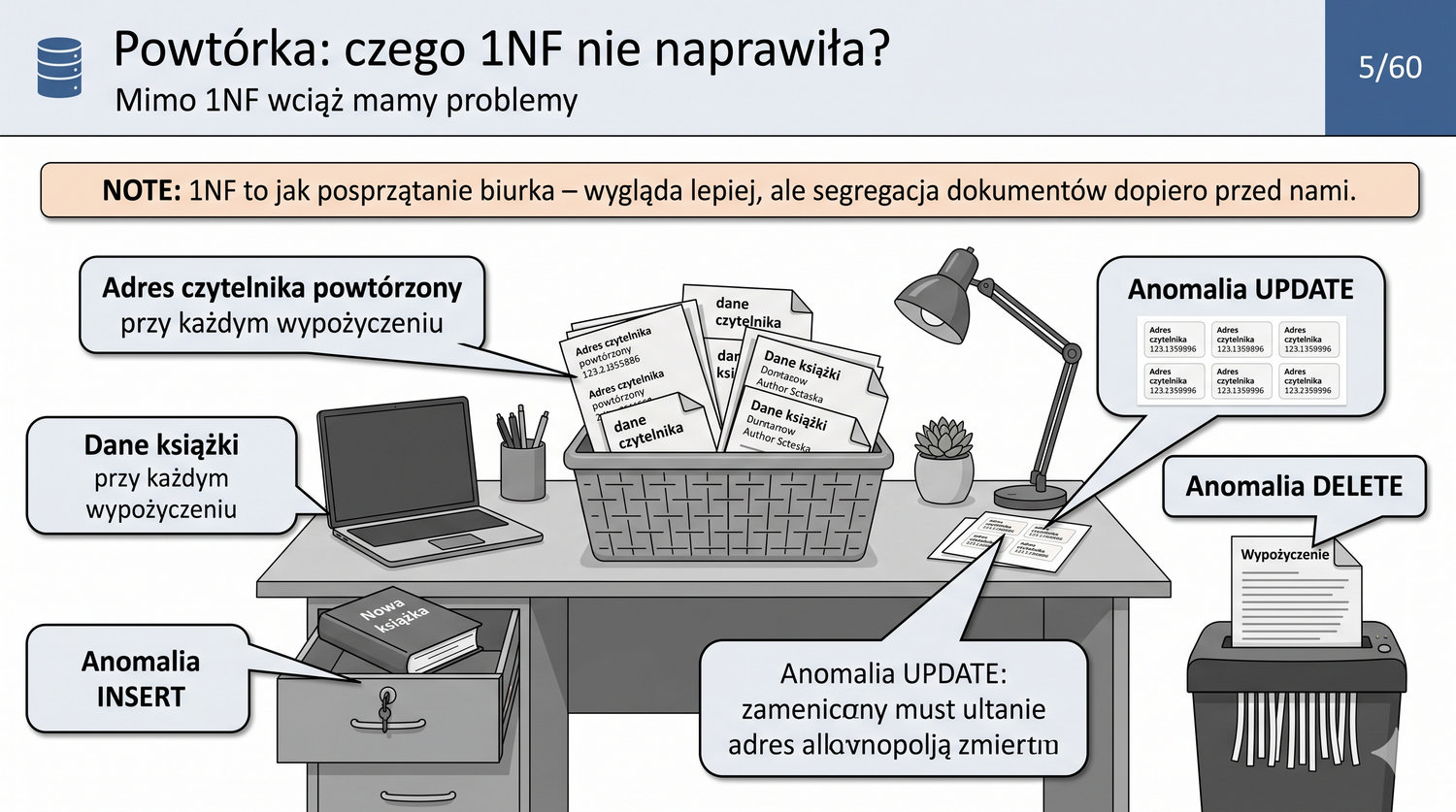
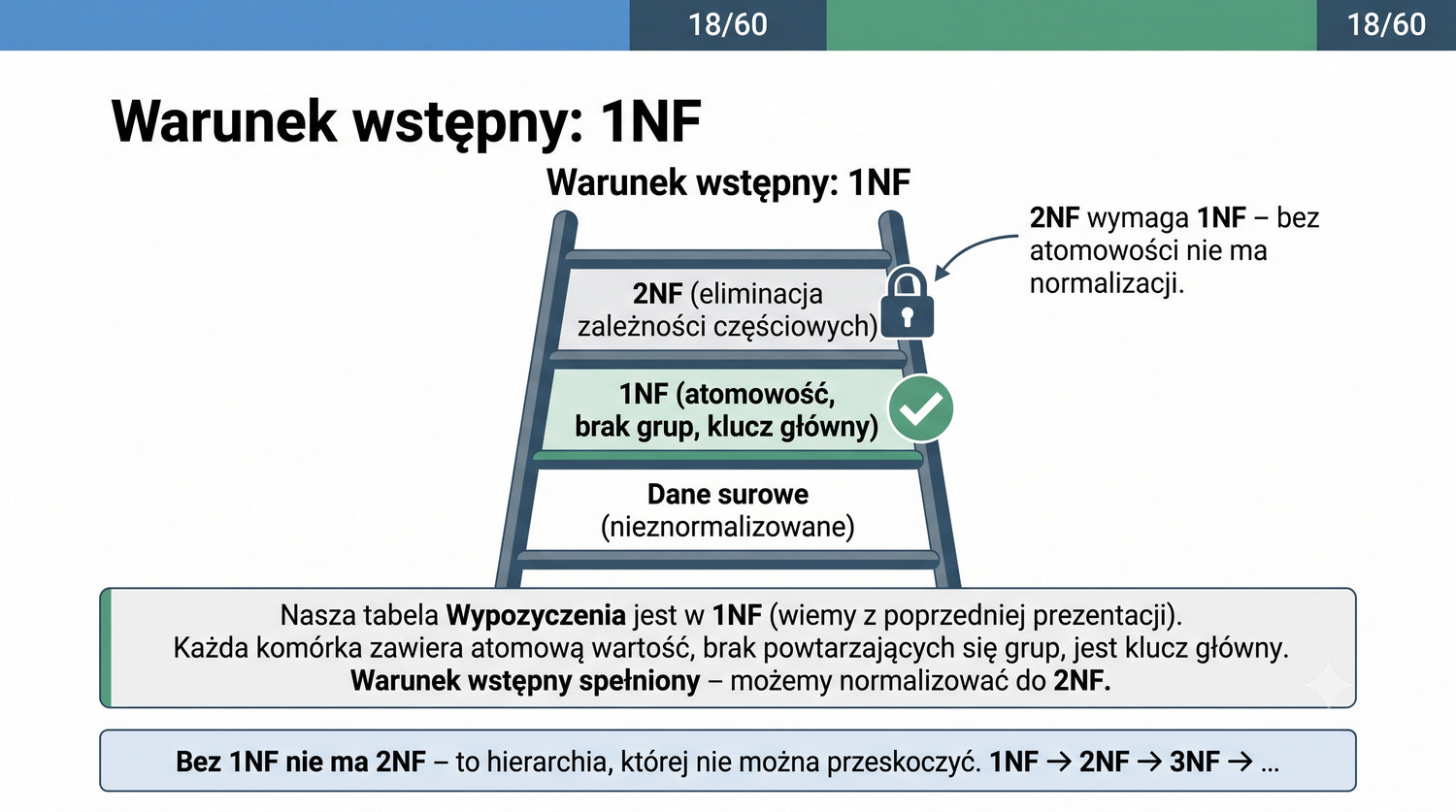
Zakładamy znajomość 1NF (atomowość, brak powtarzających się grup, klucz główny).
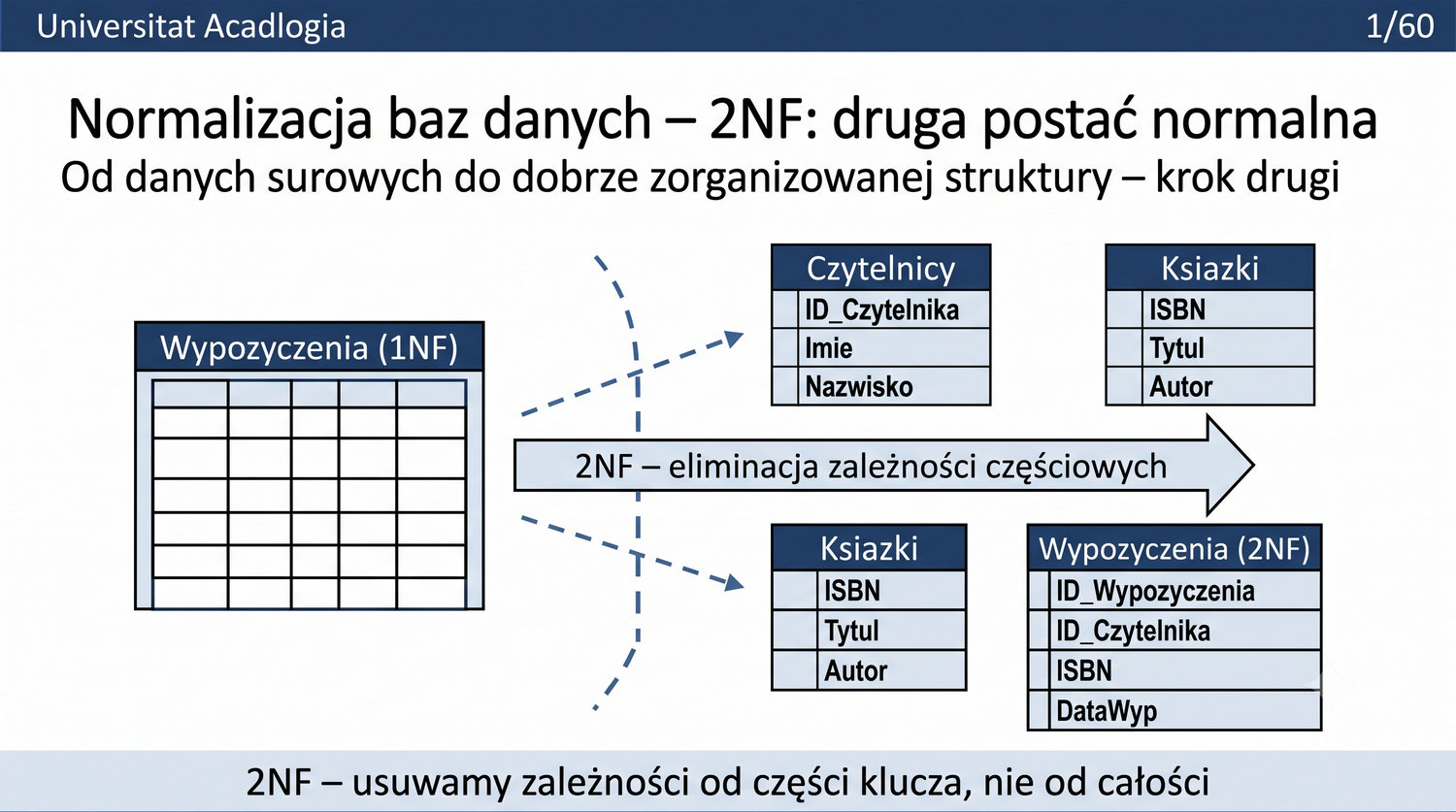
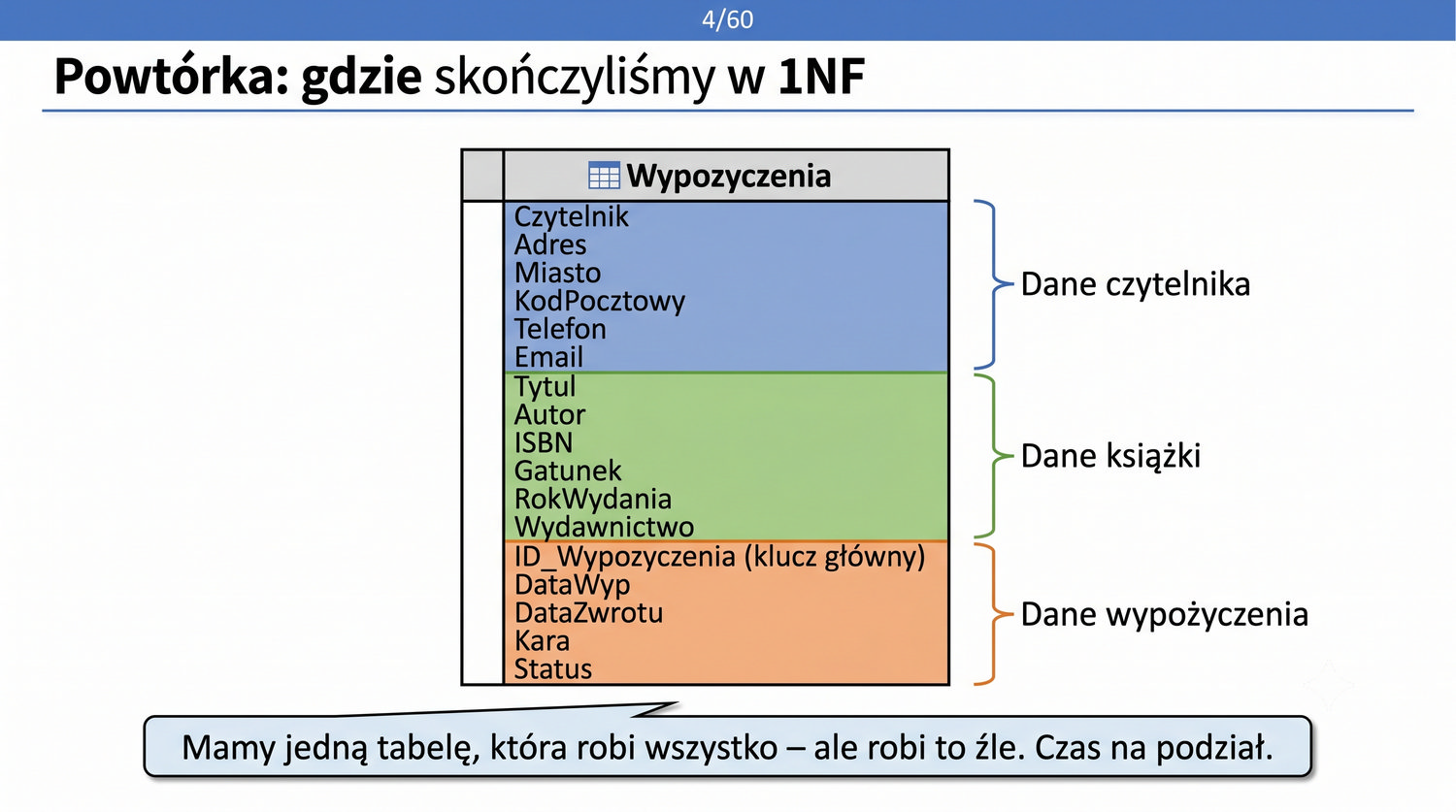
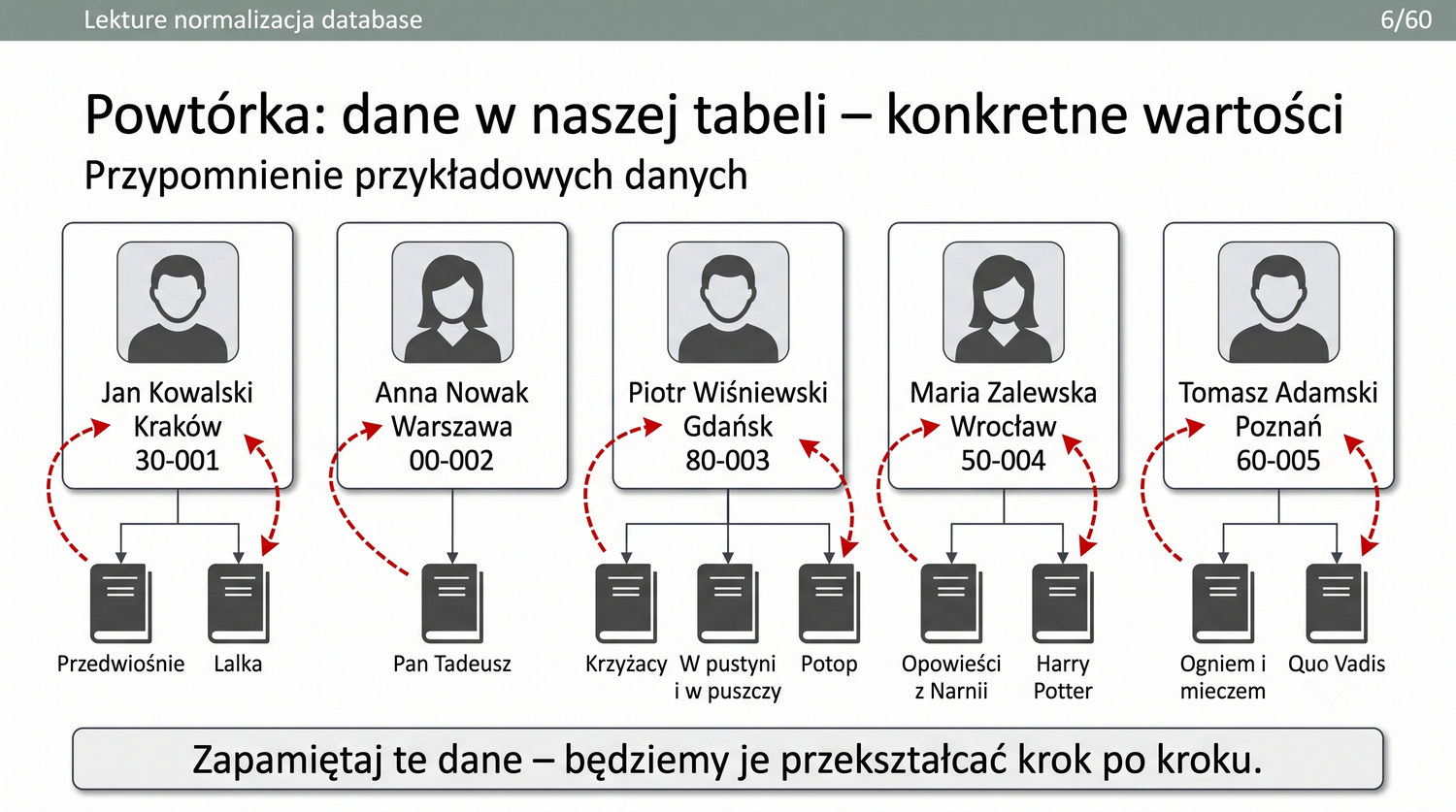
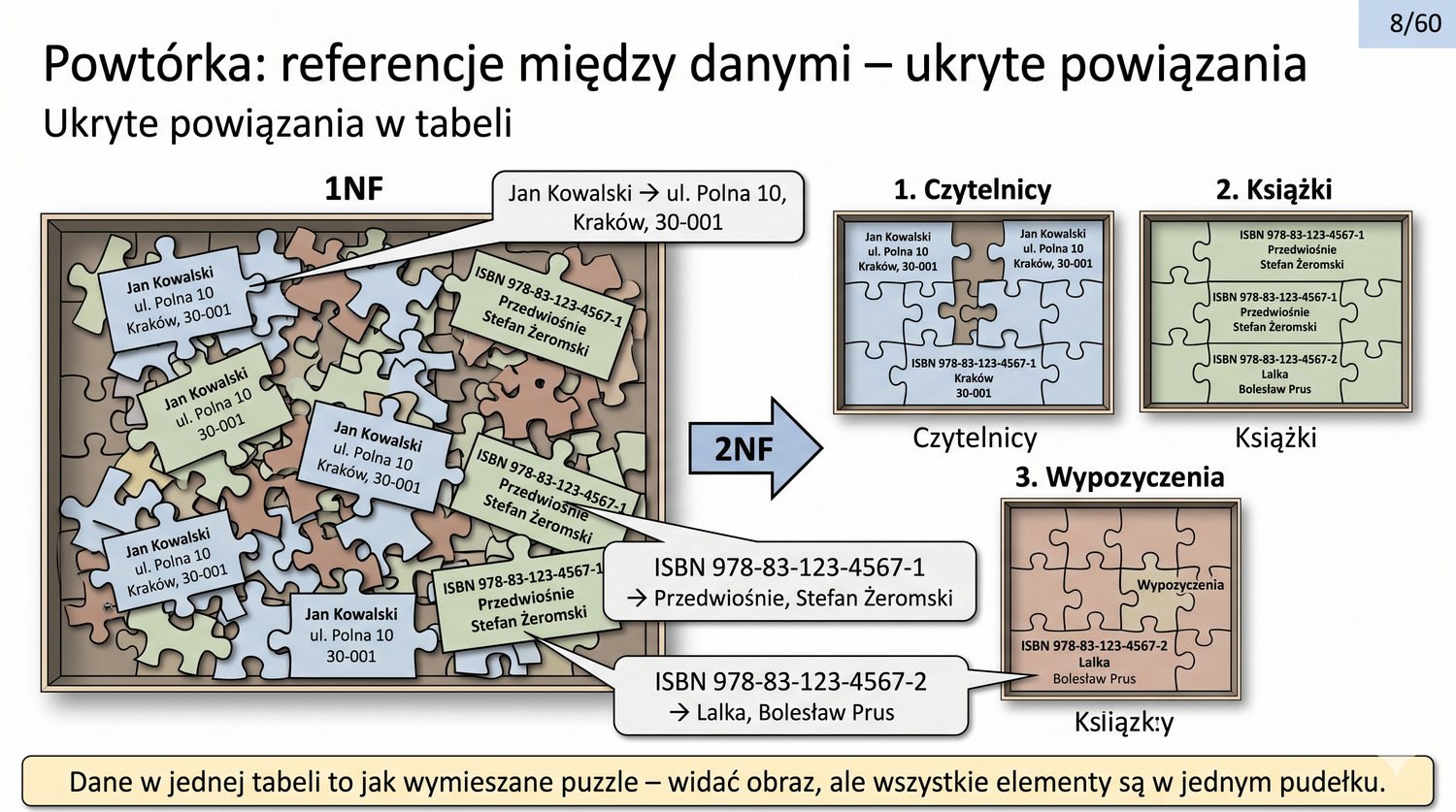
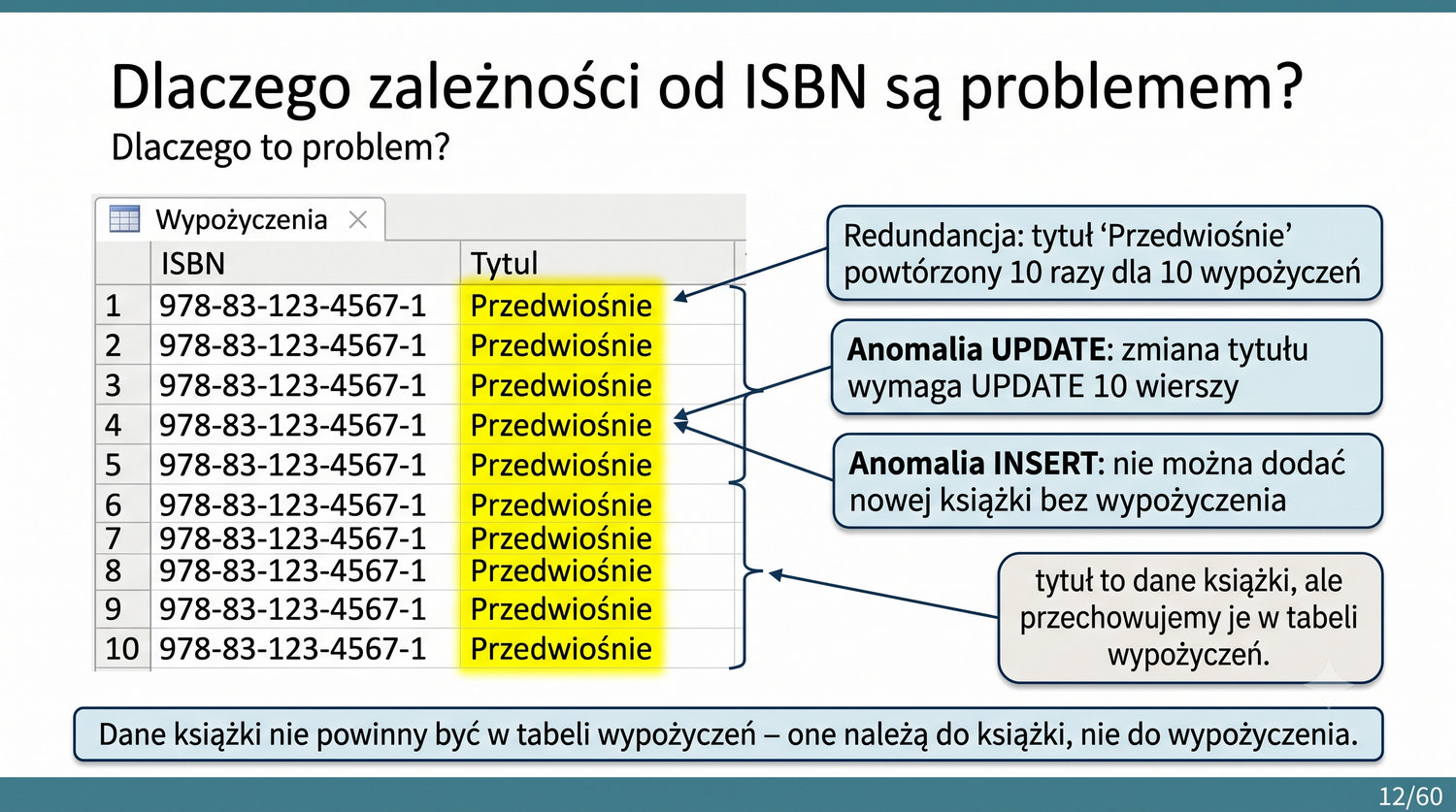
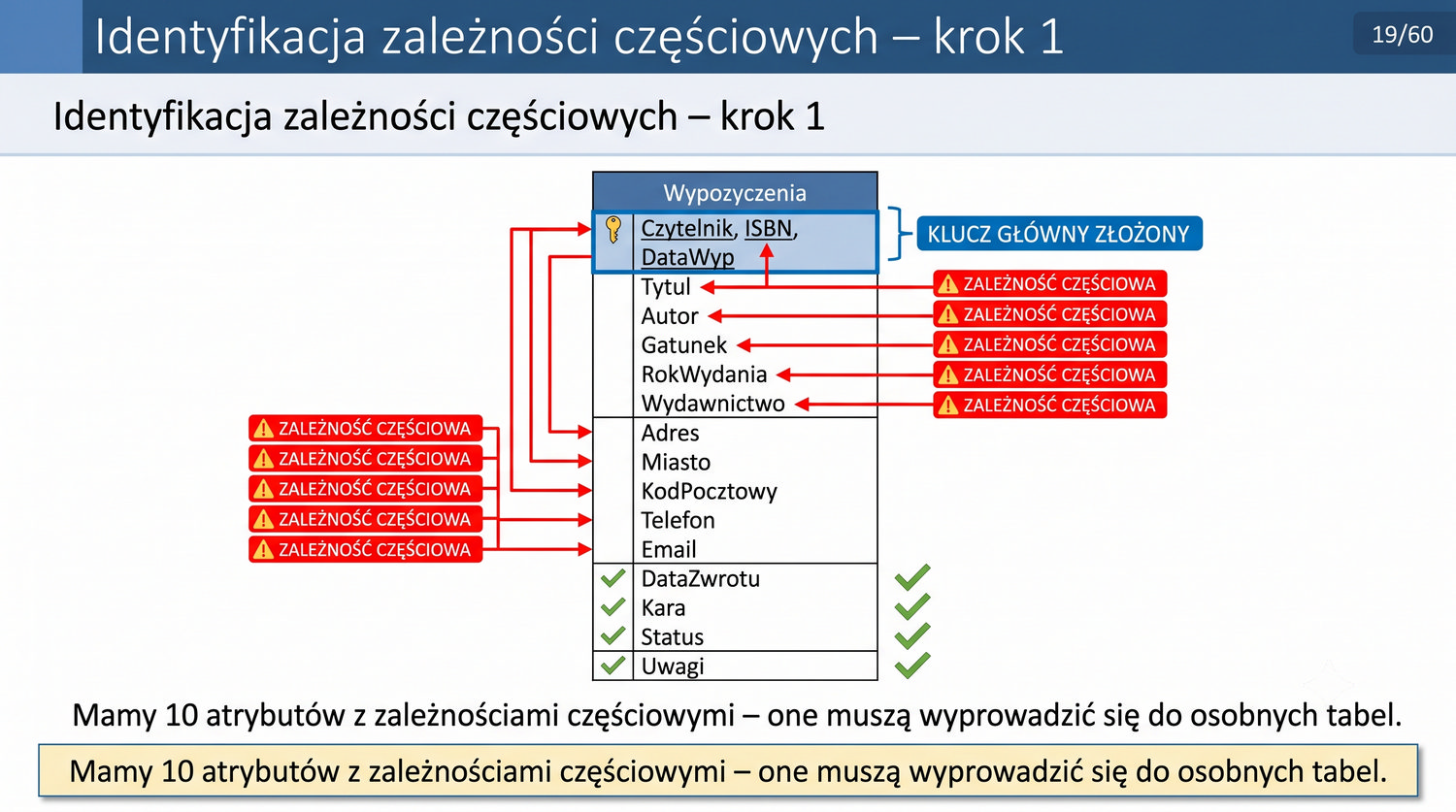
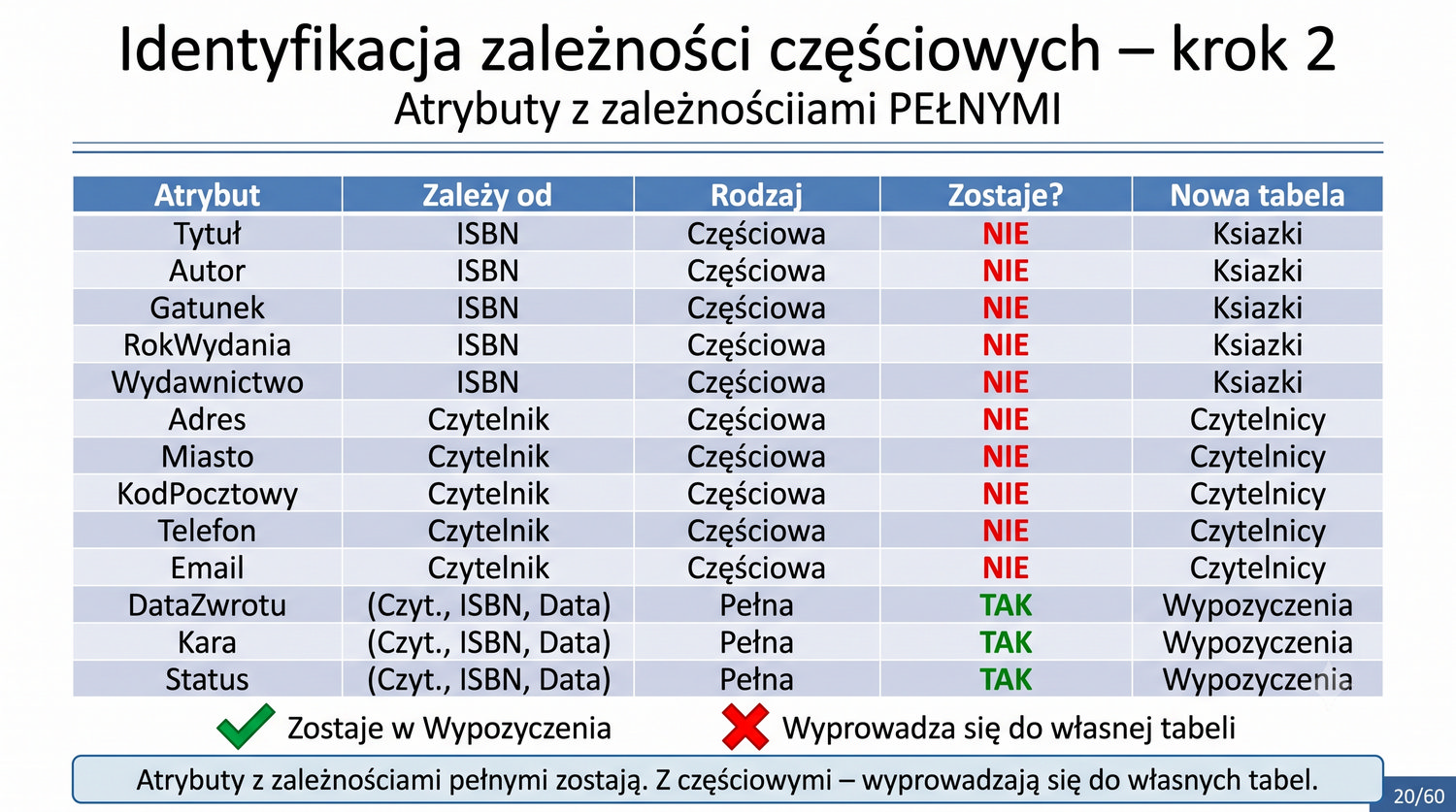
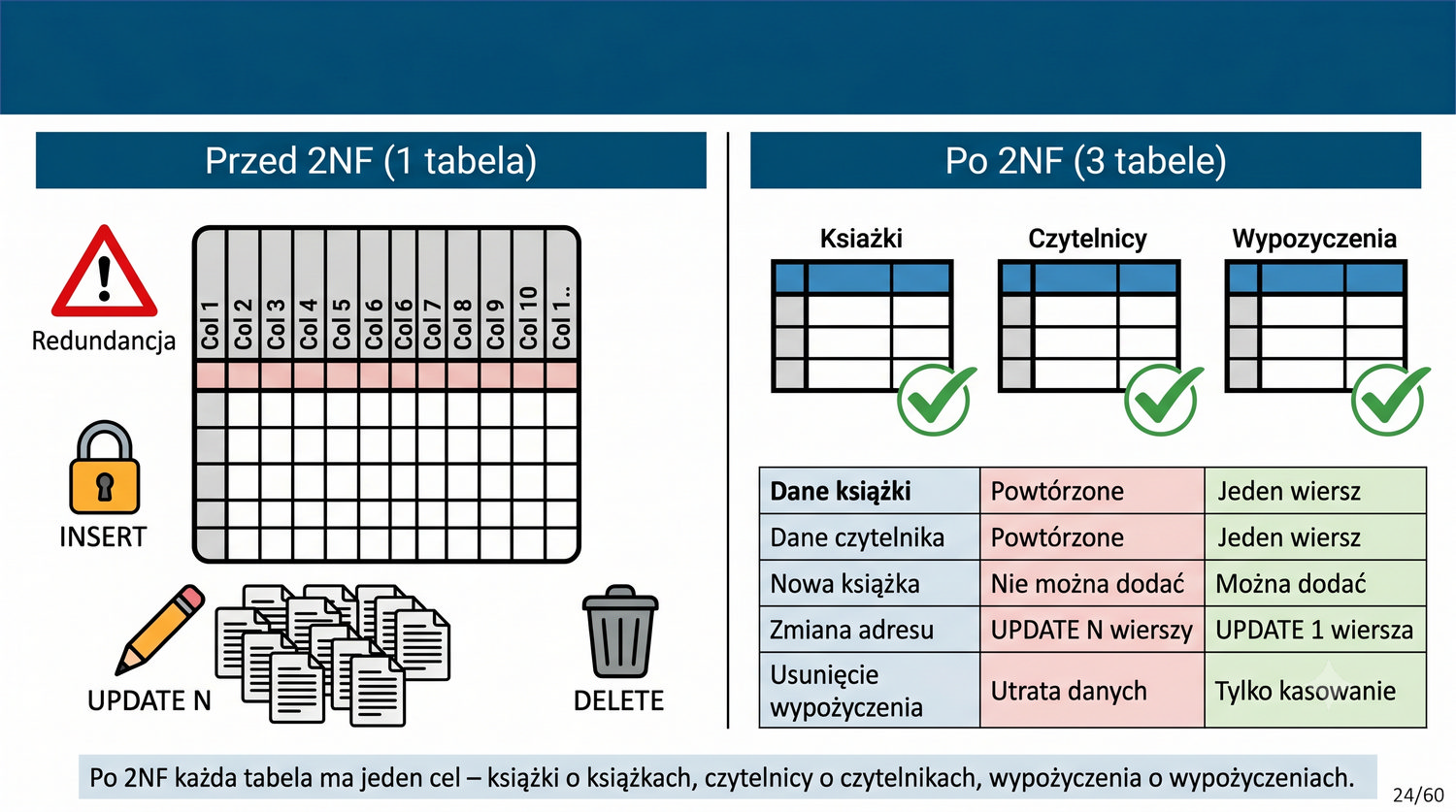
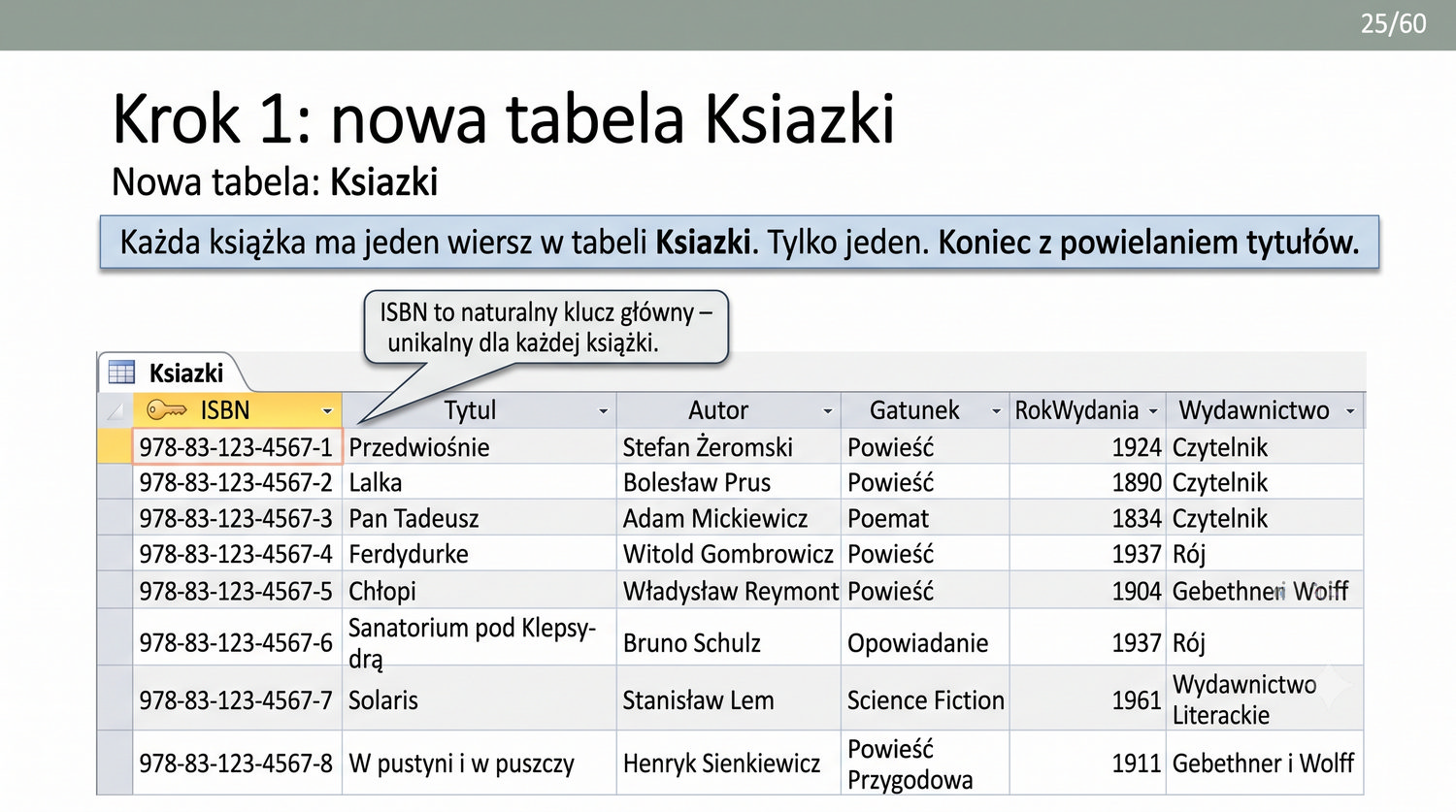
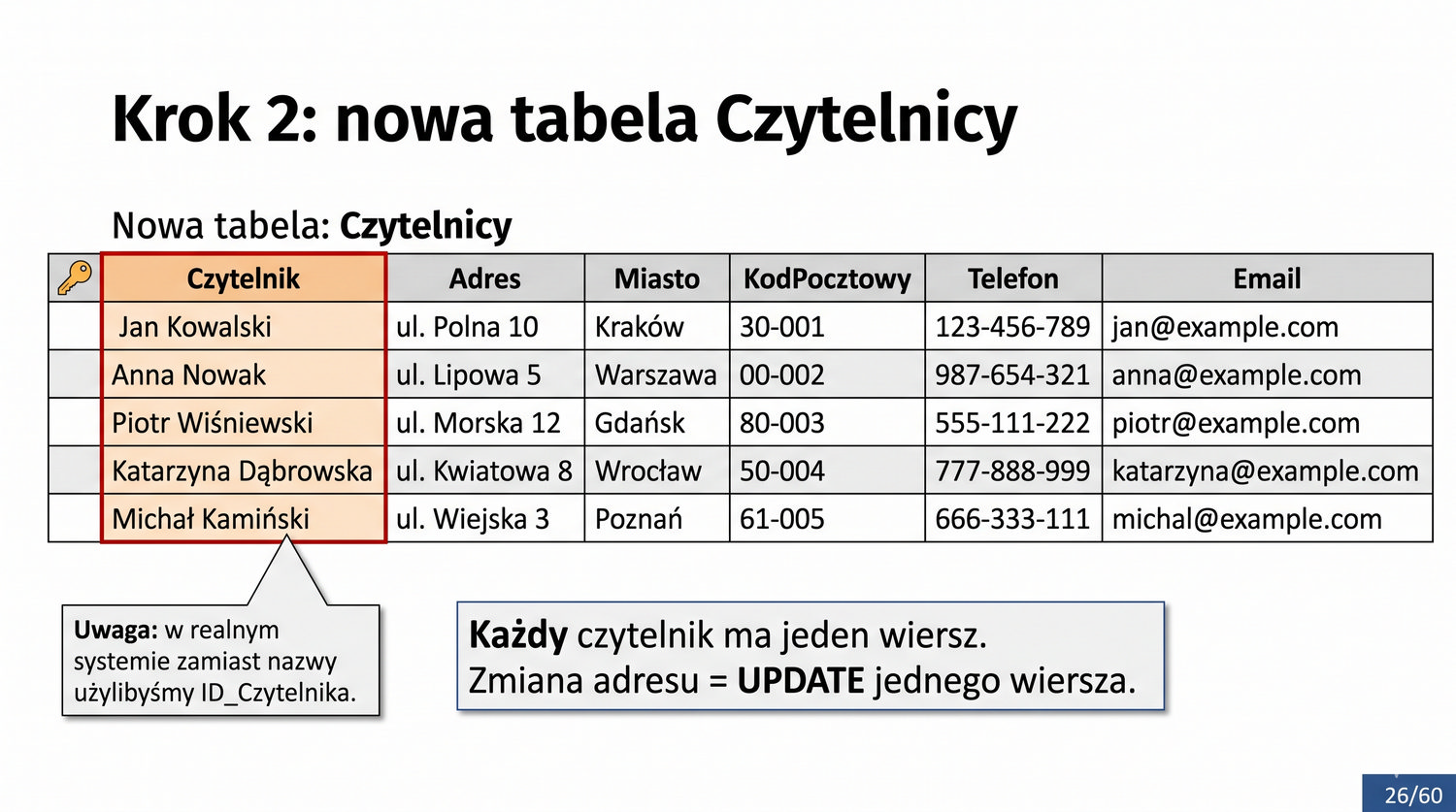
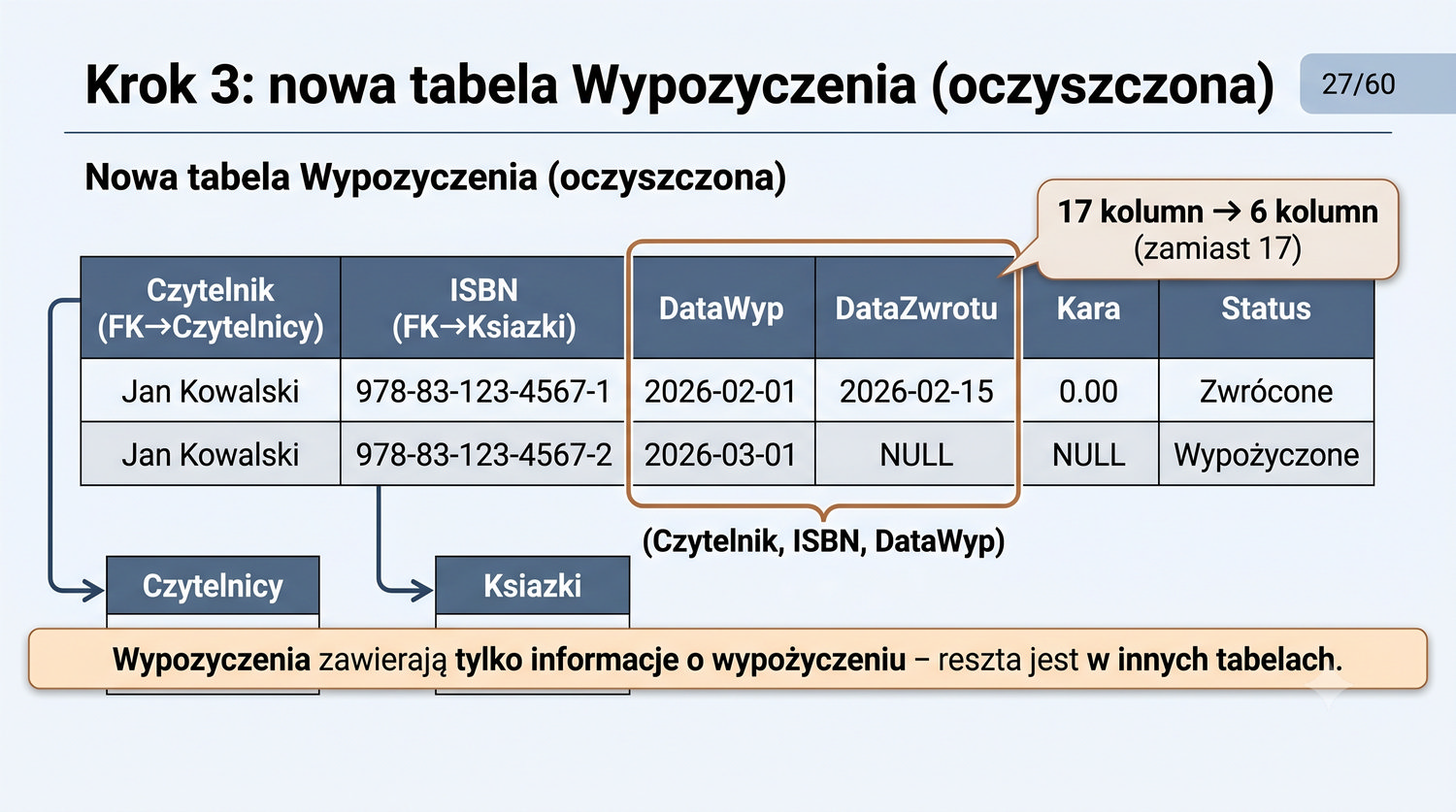
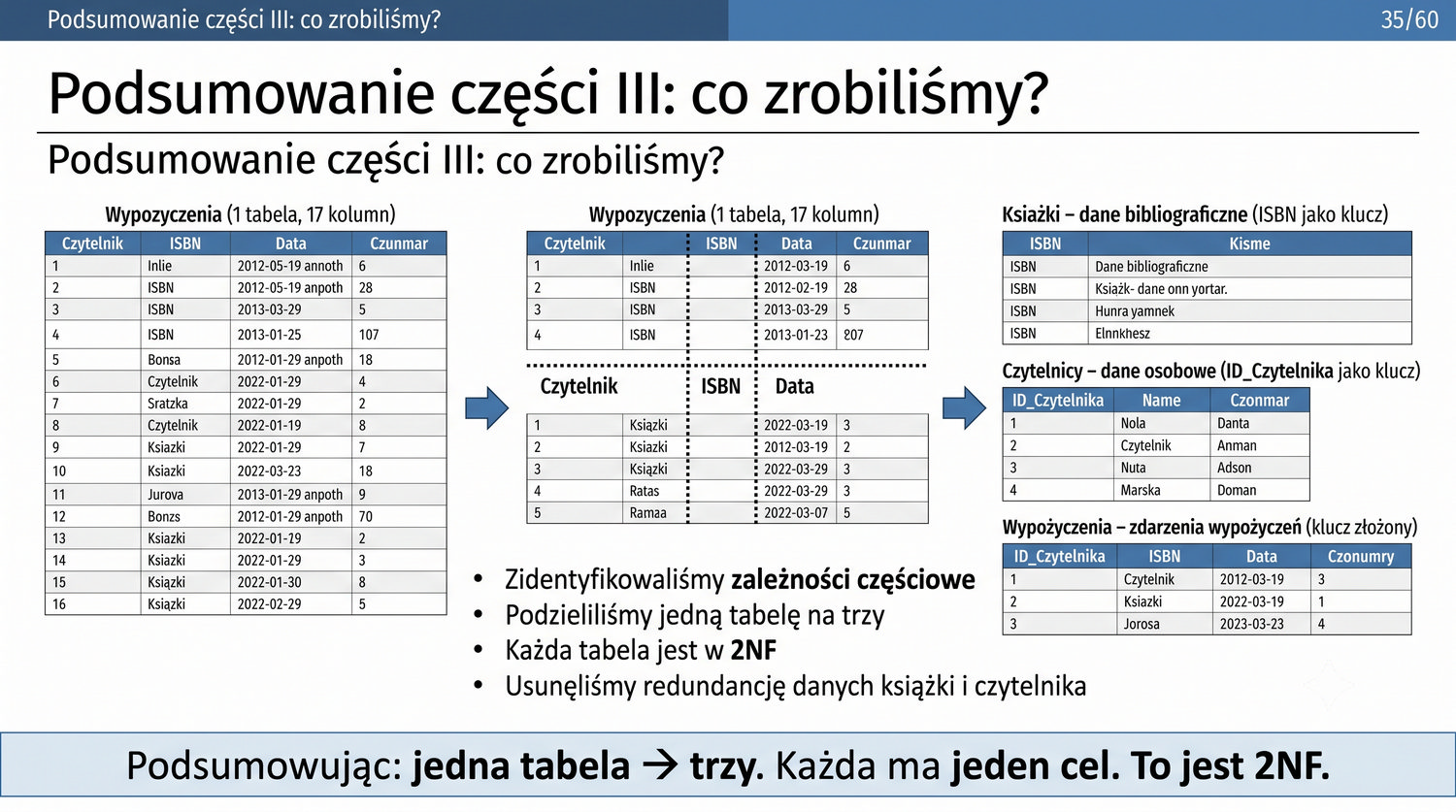
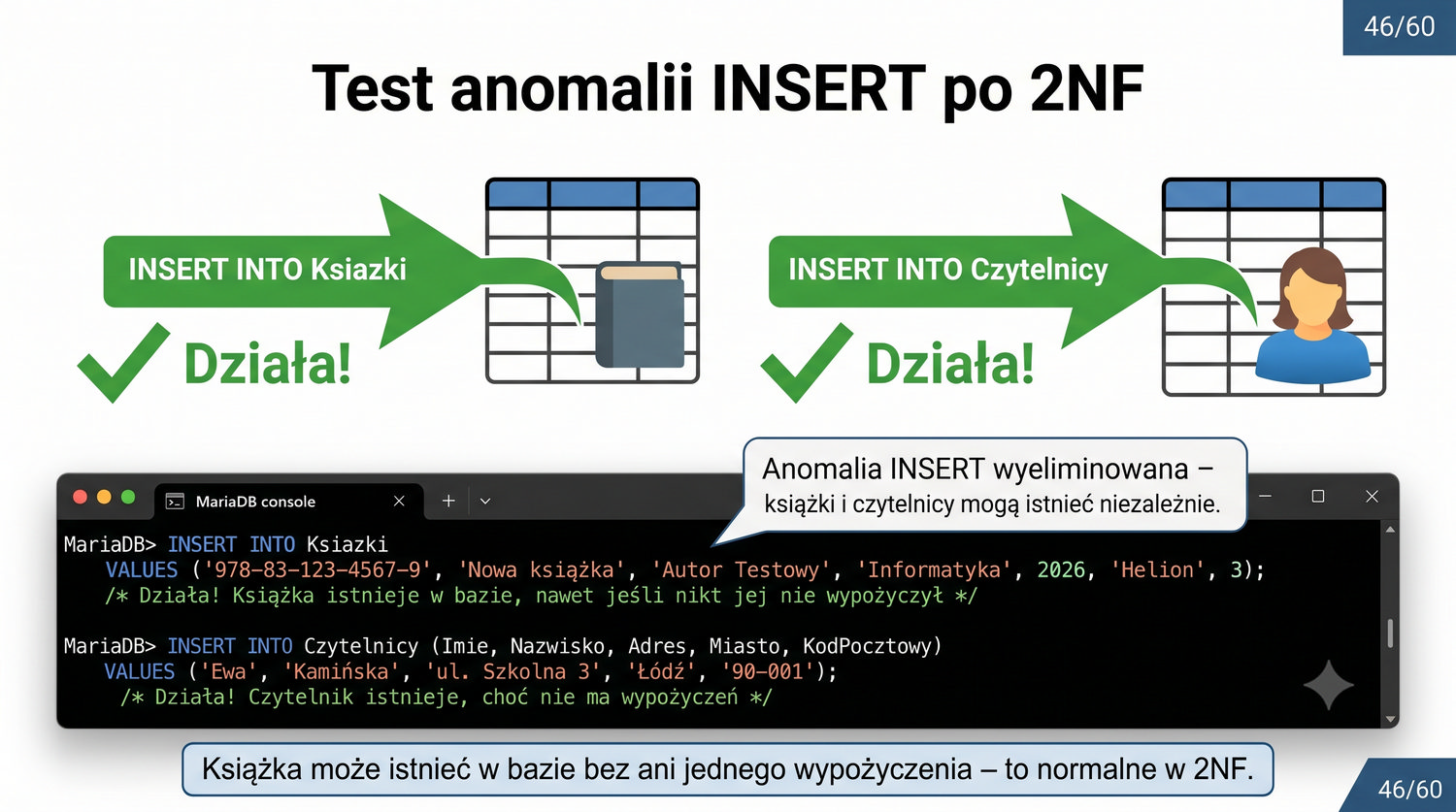
W poprzedniej prezentacji doprowadziliśmy dane biblioteczne do 1NF. Teraz czas na drugi krok: eliminację częściowych zależności funkcyjnych.
1NF dała nam trzy rzeczy: atomowość, brak powtarzających się grup i klucz główny.
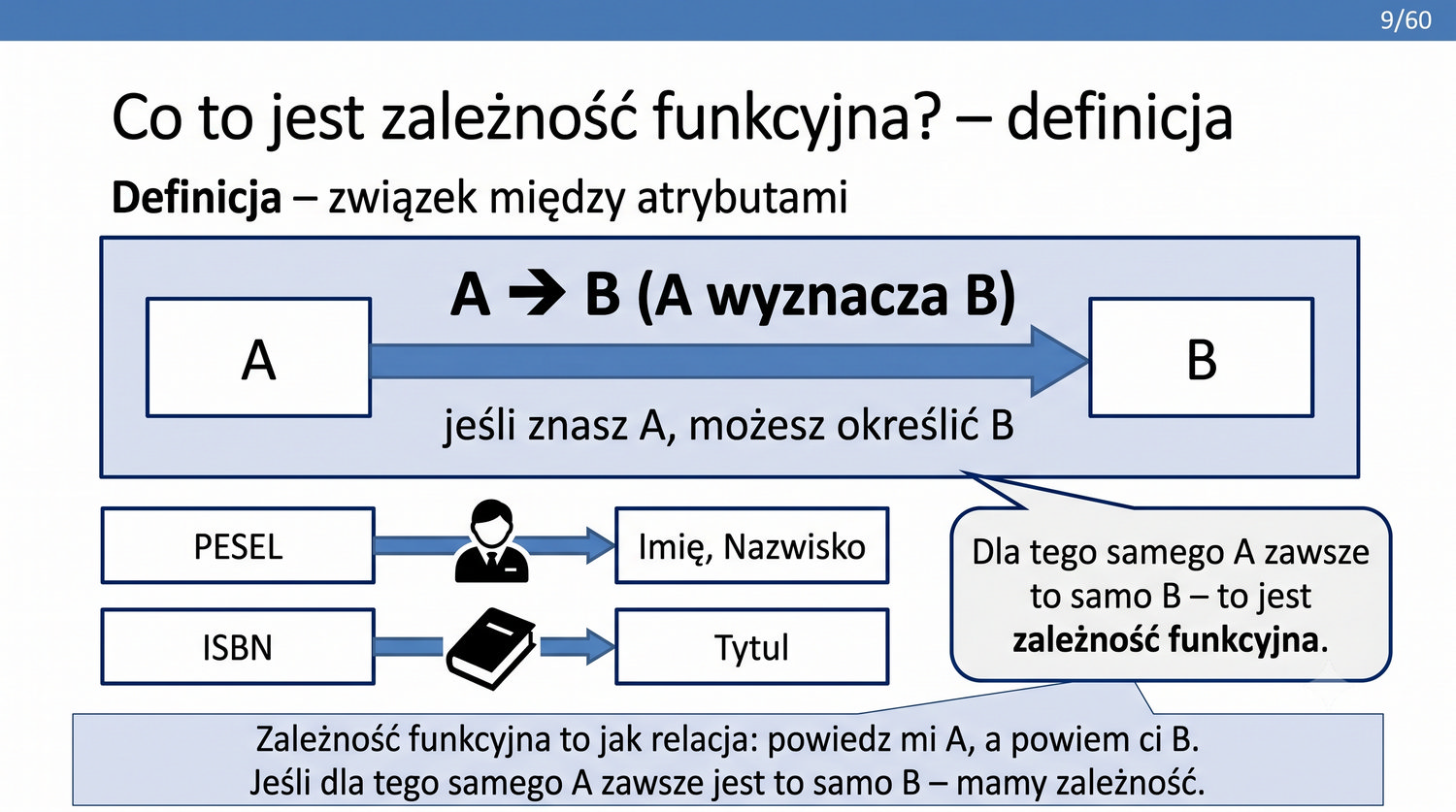
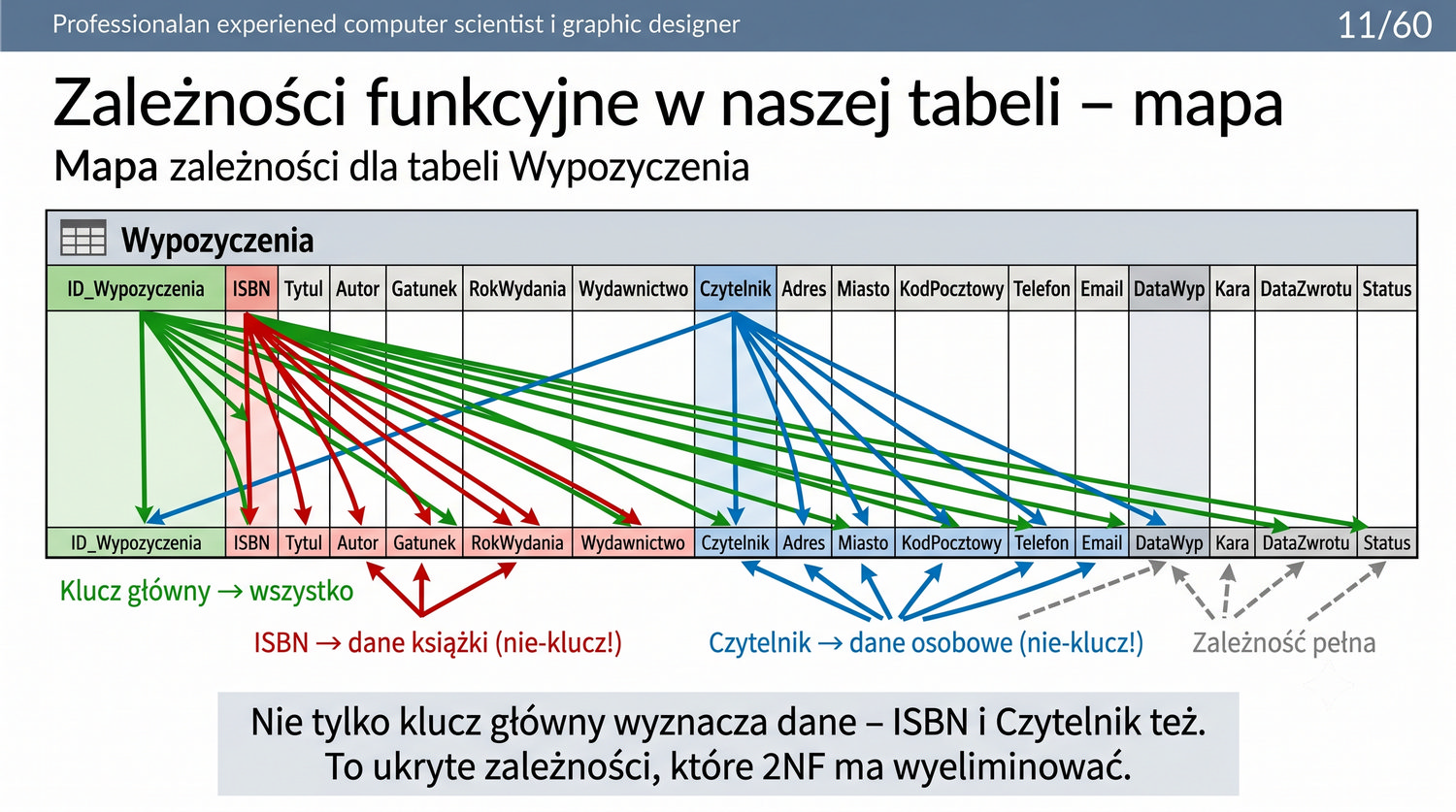
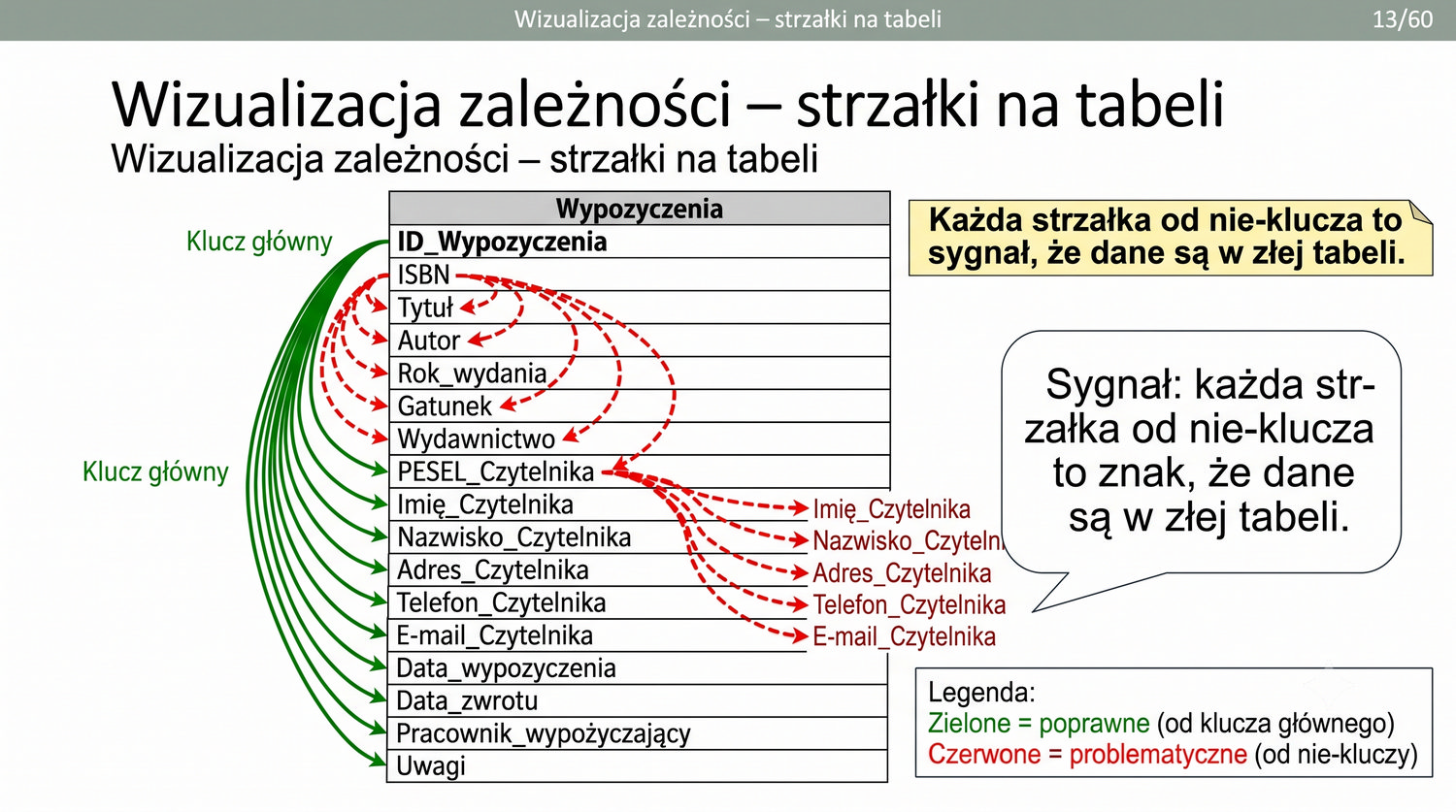
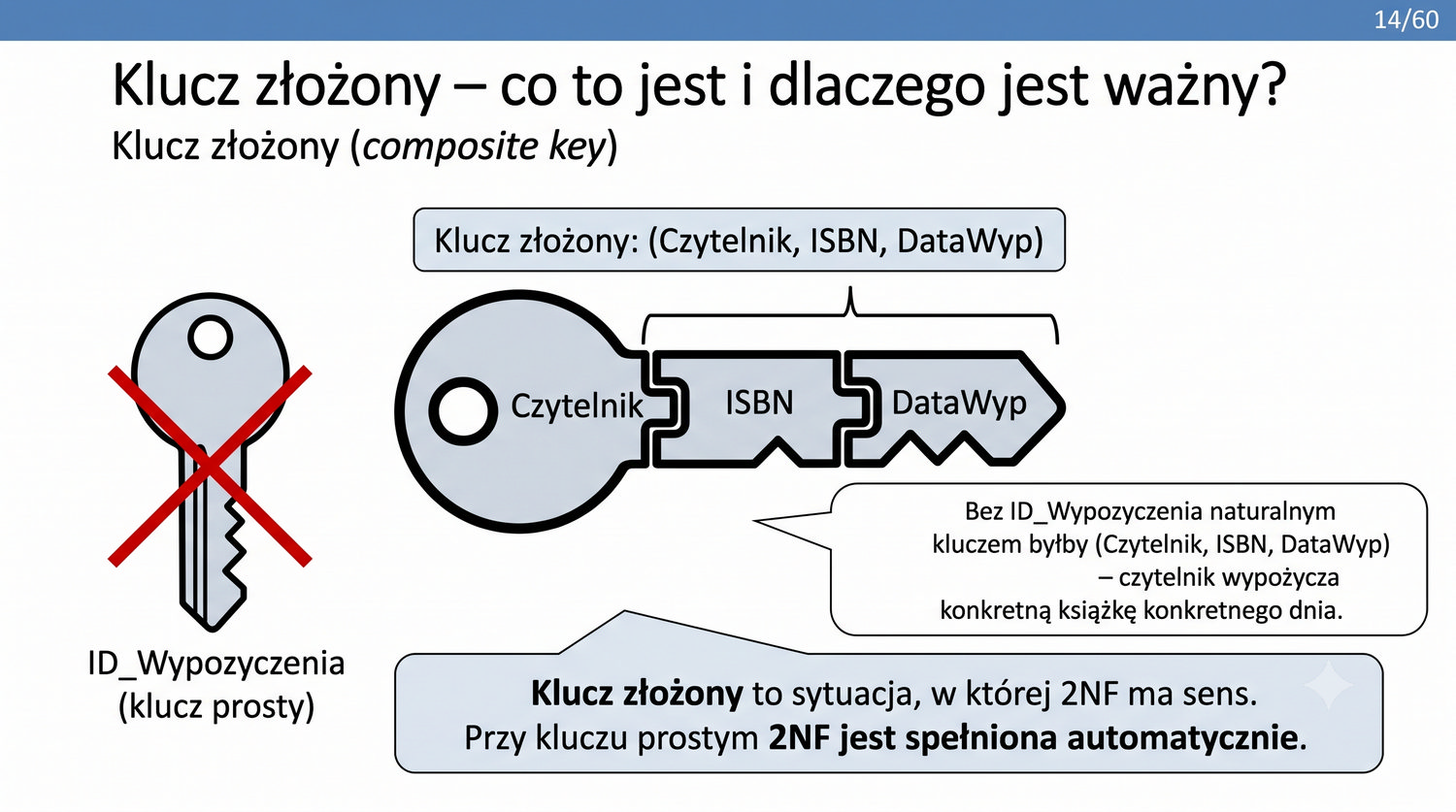
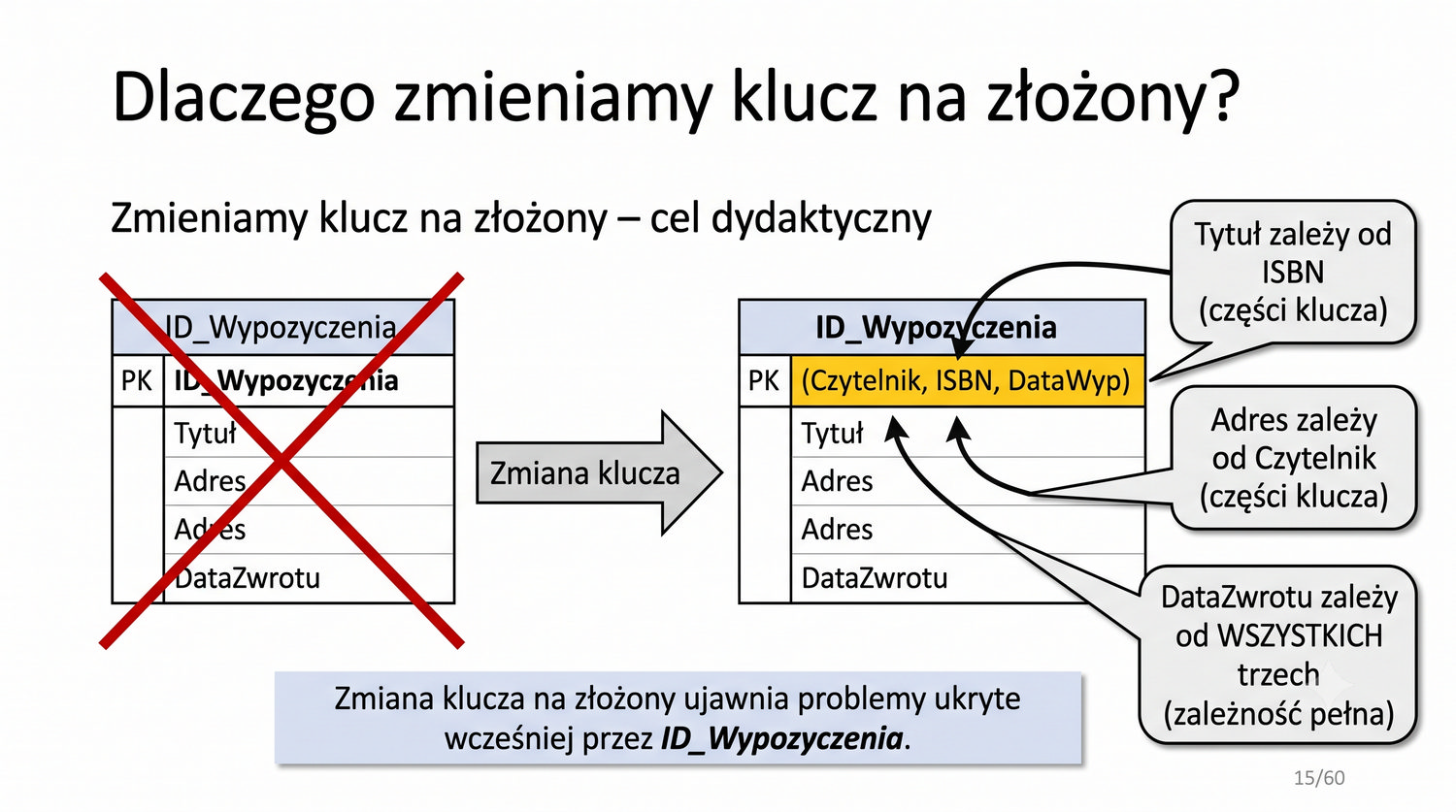
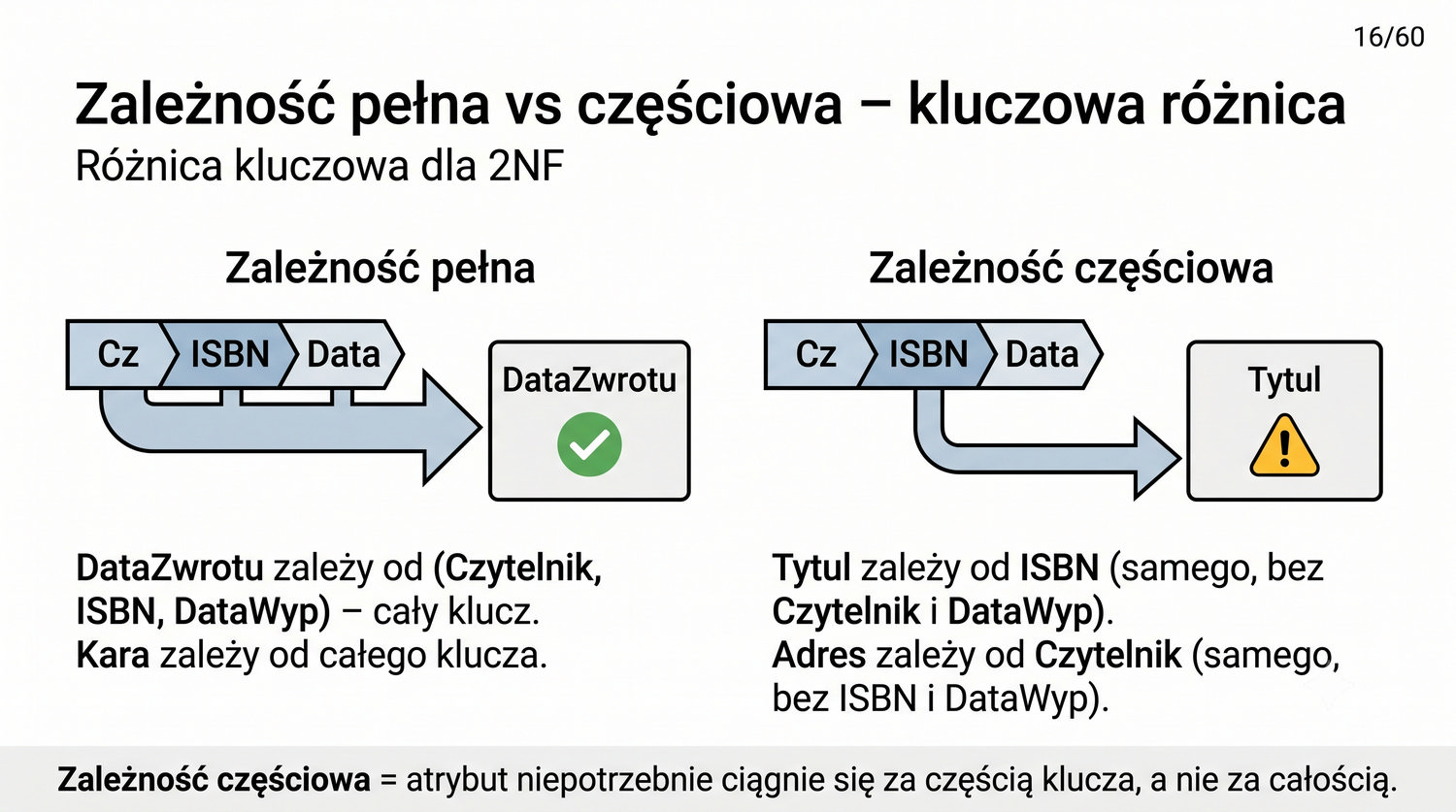
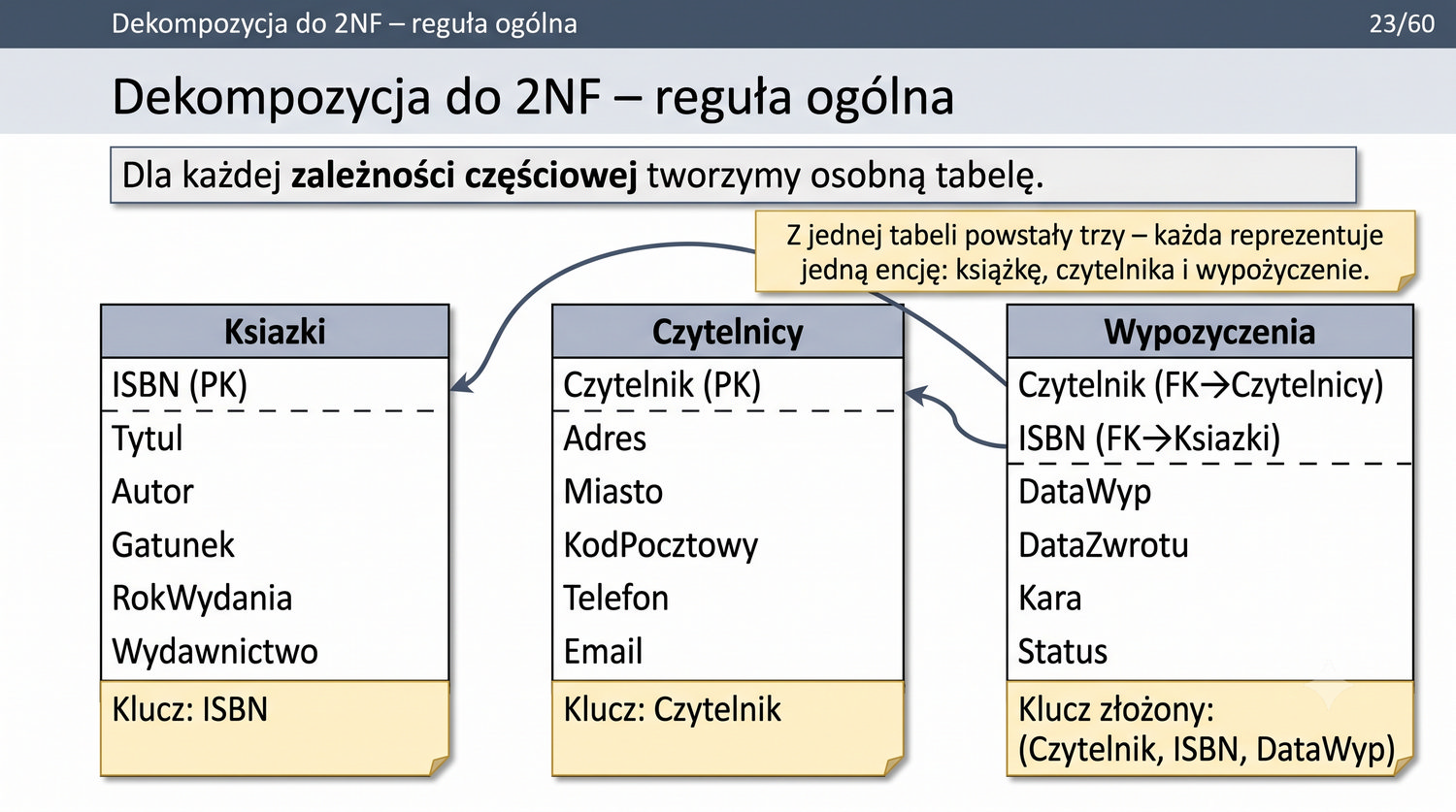
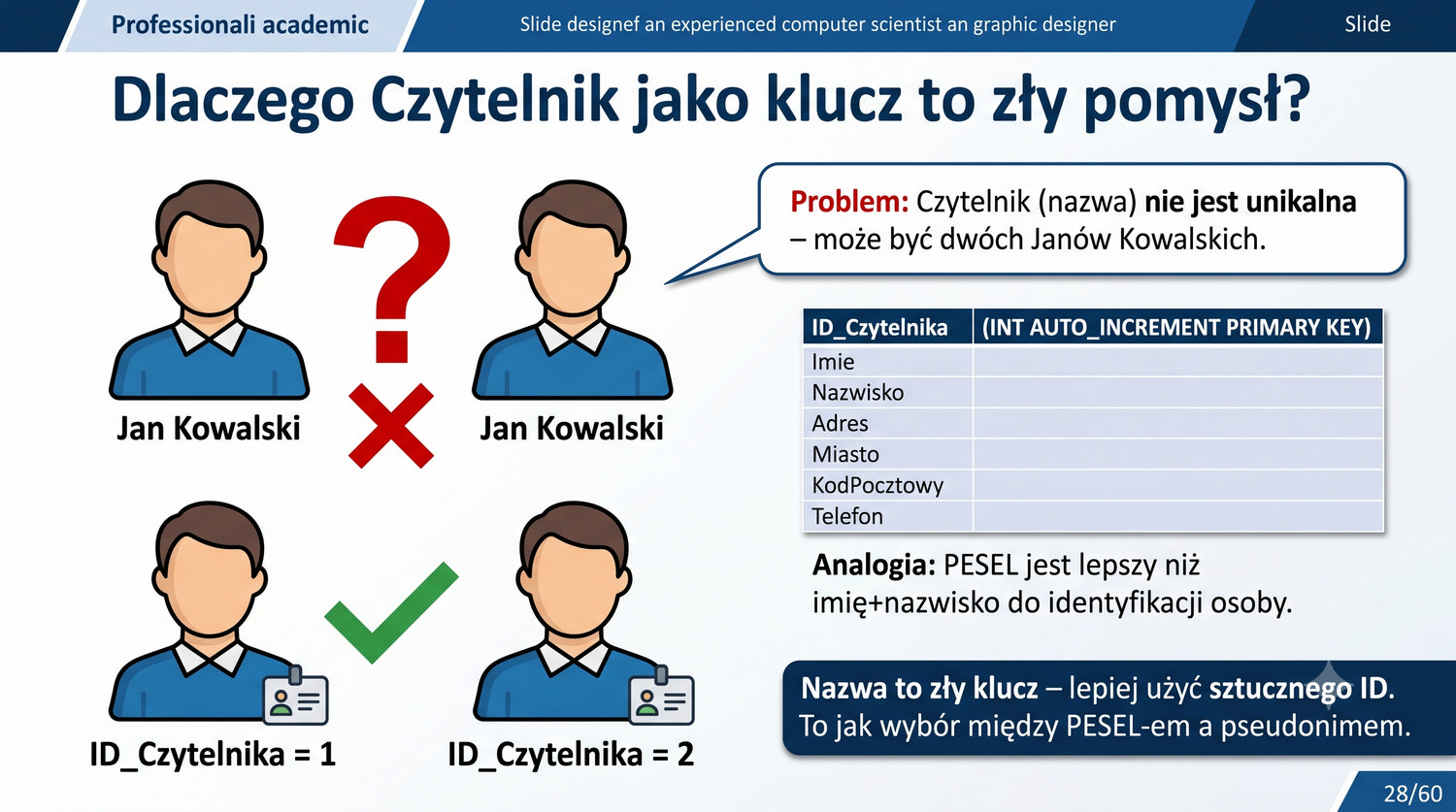
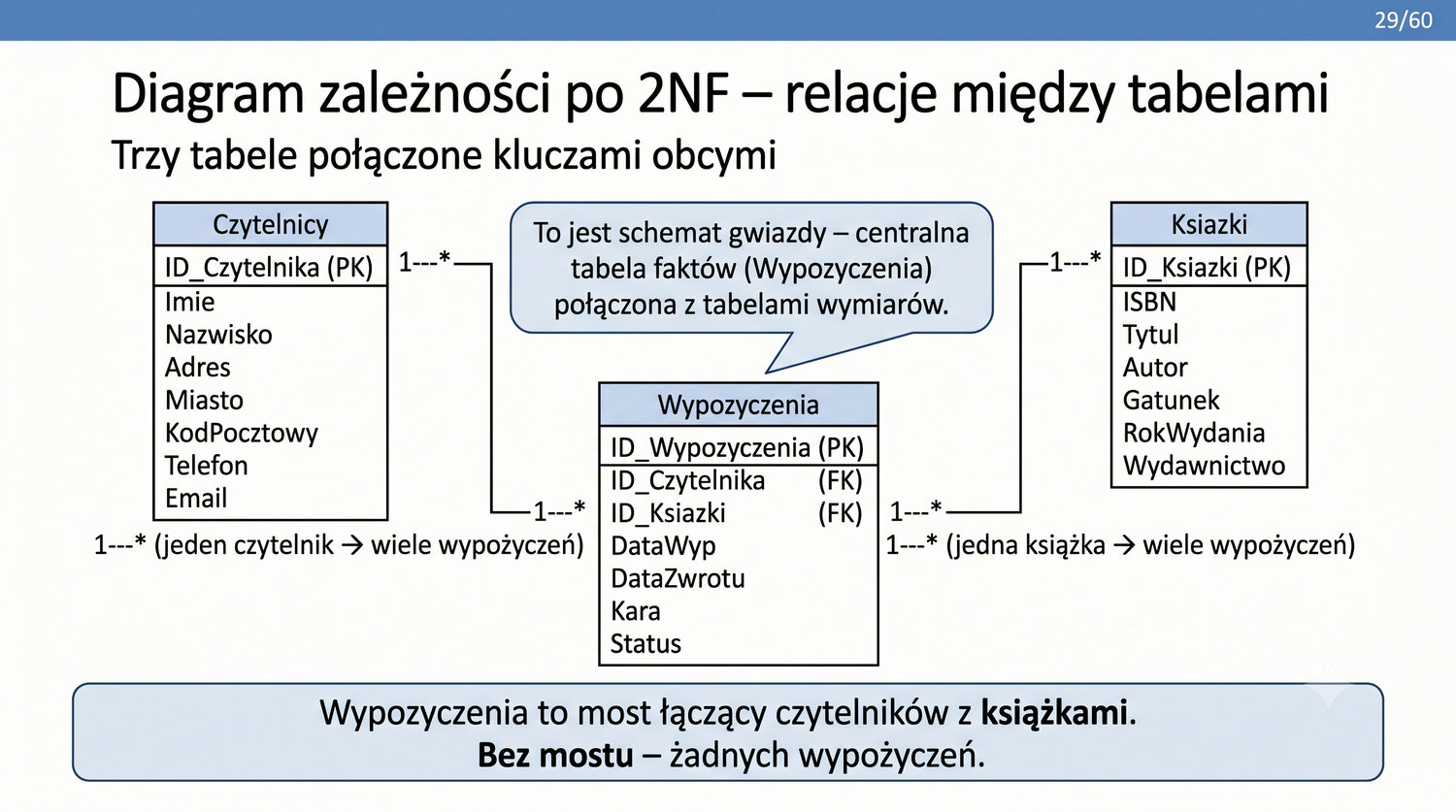
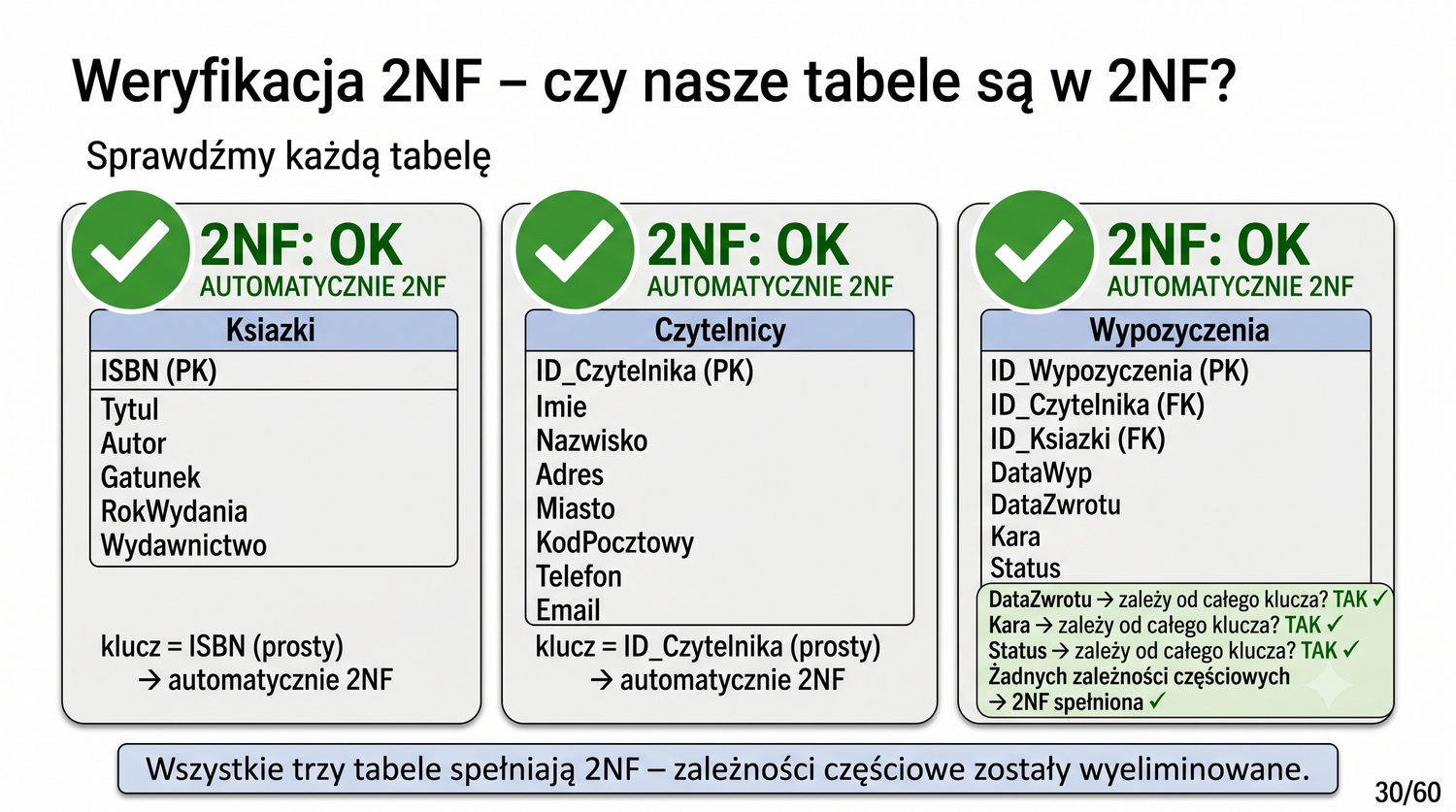
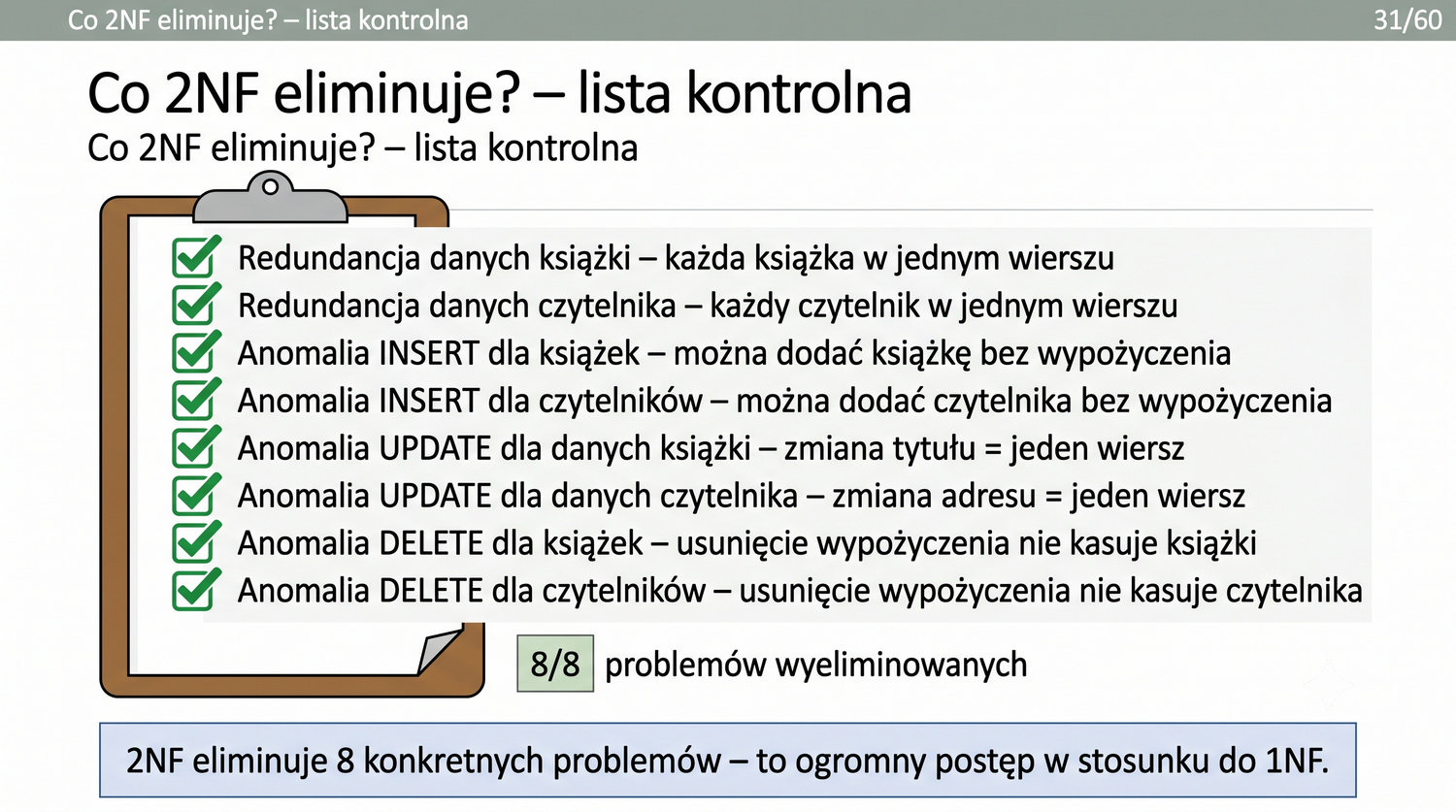
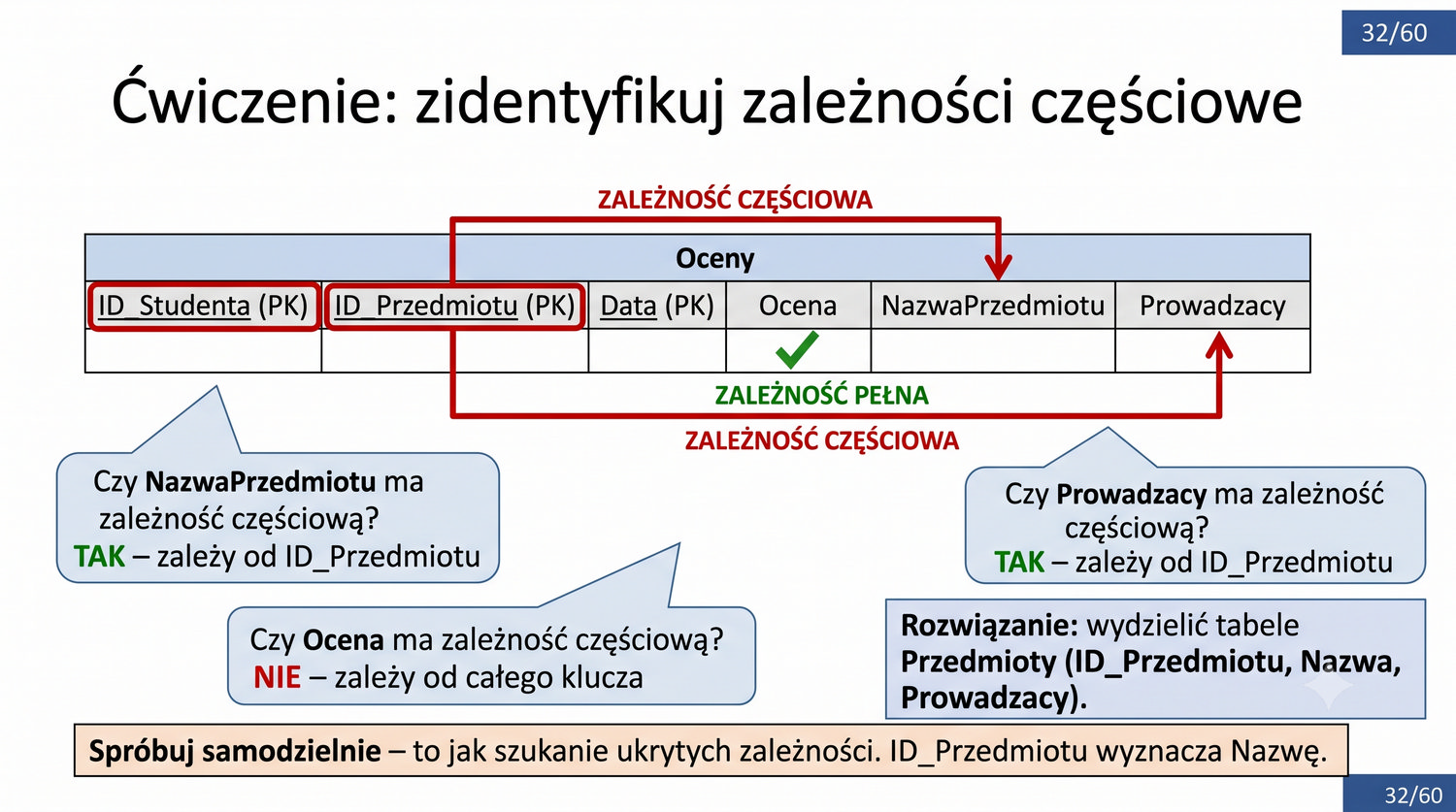
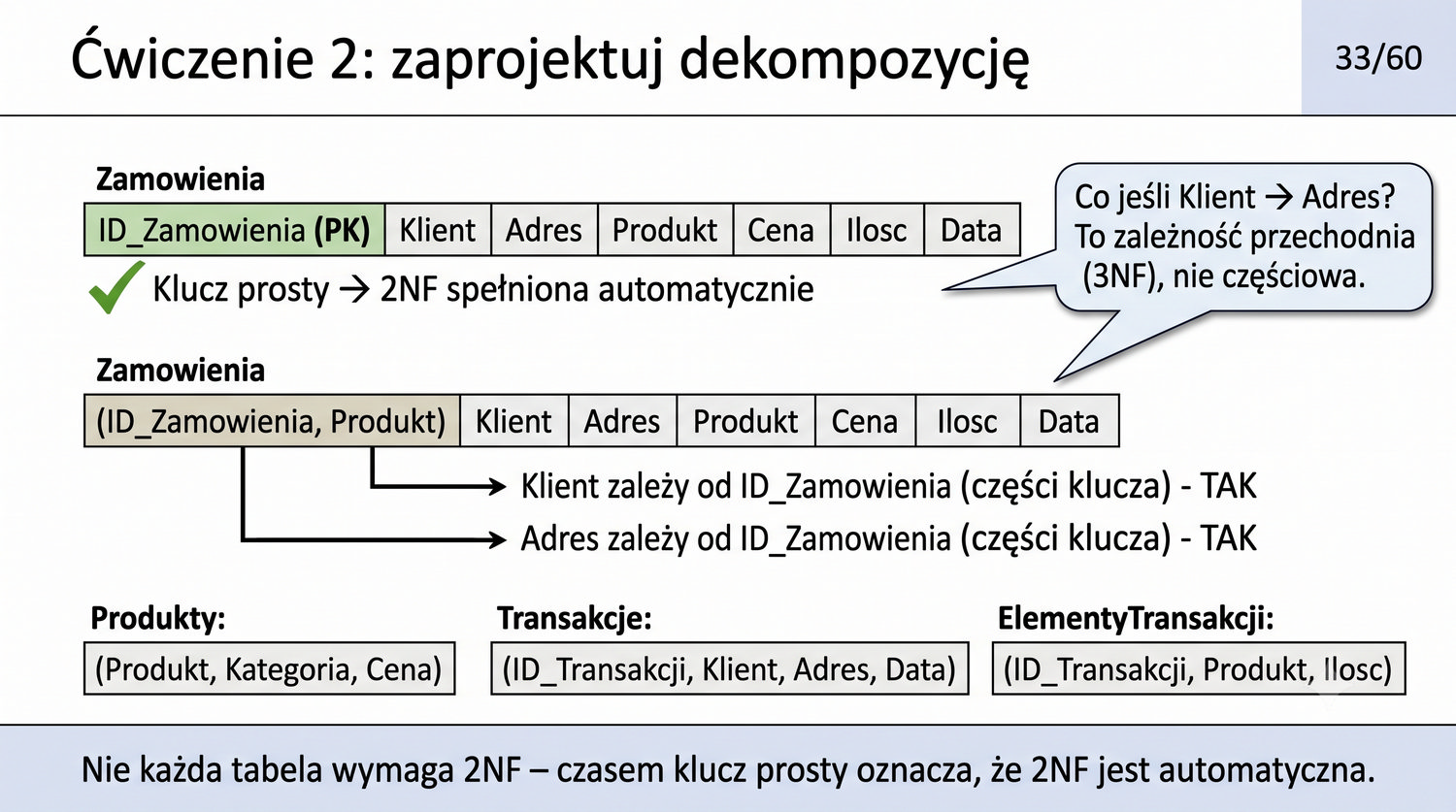
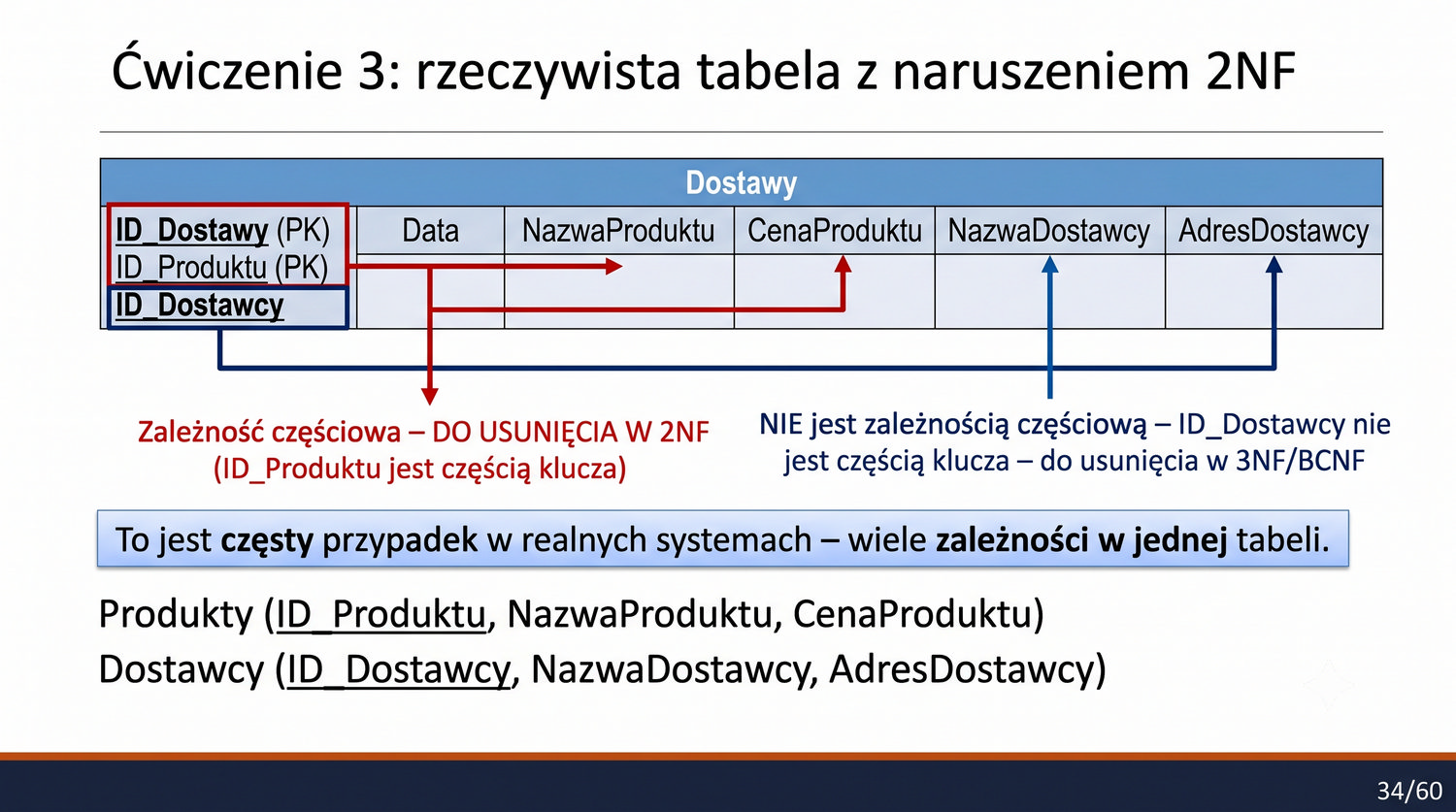
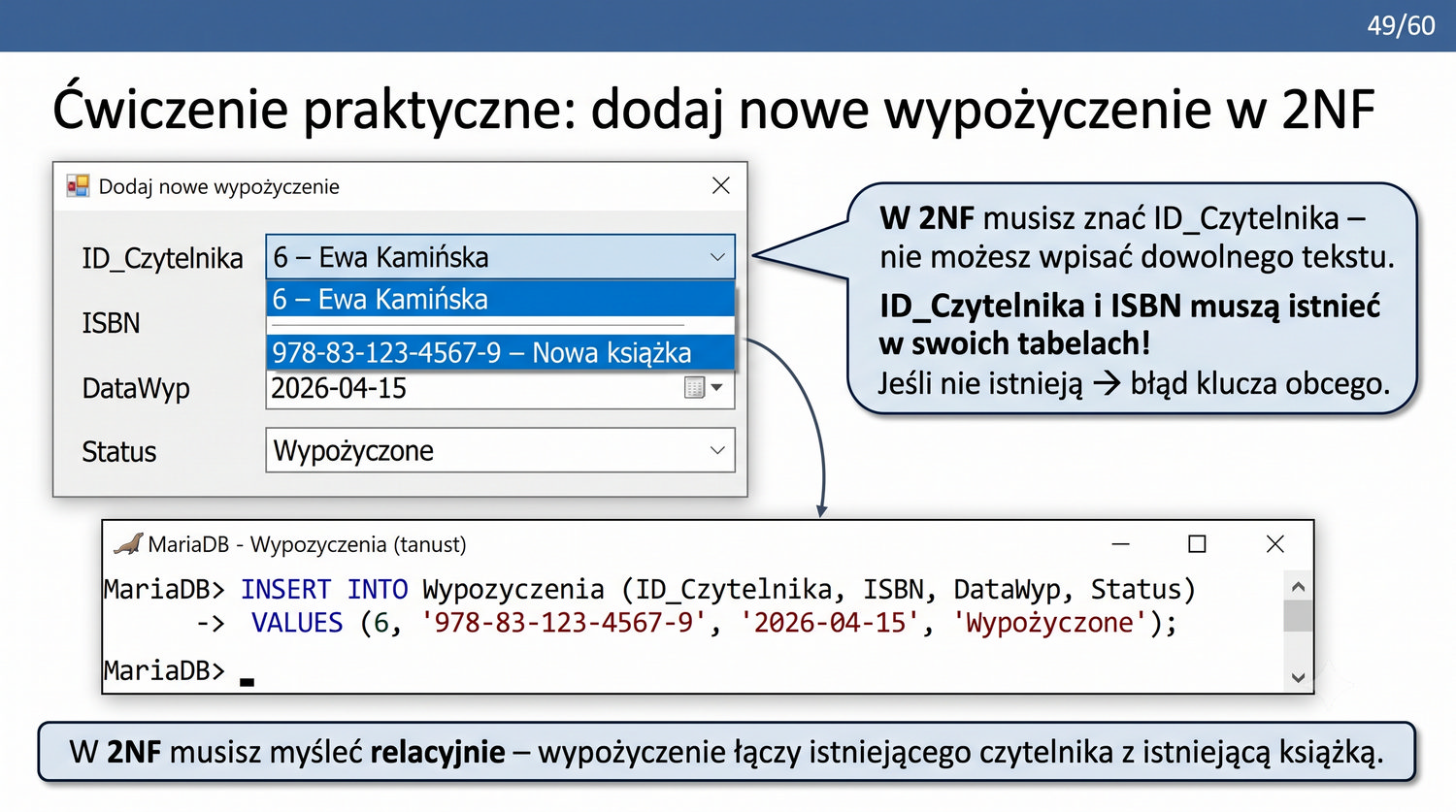
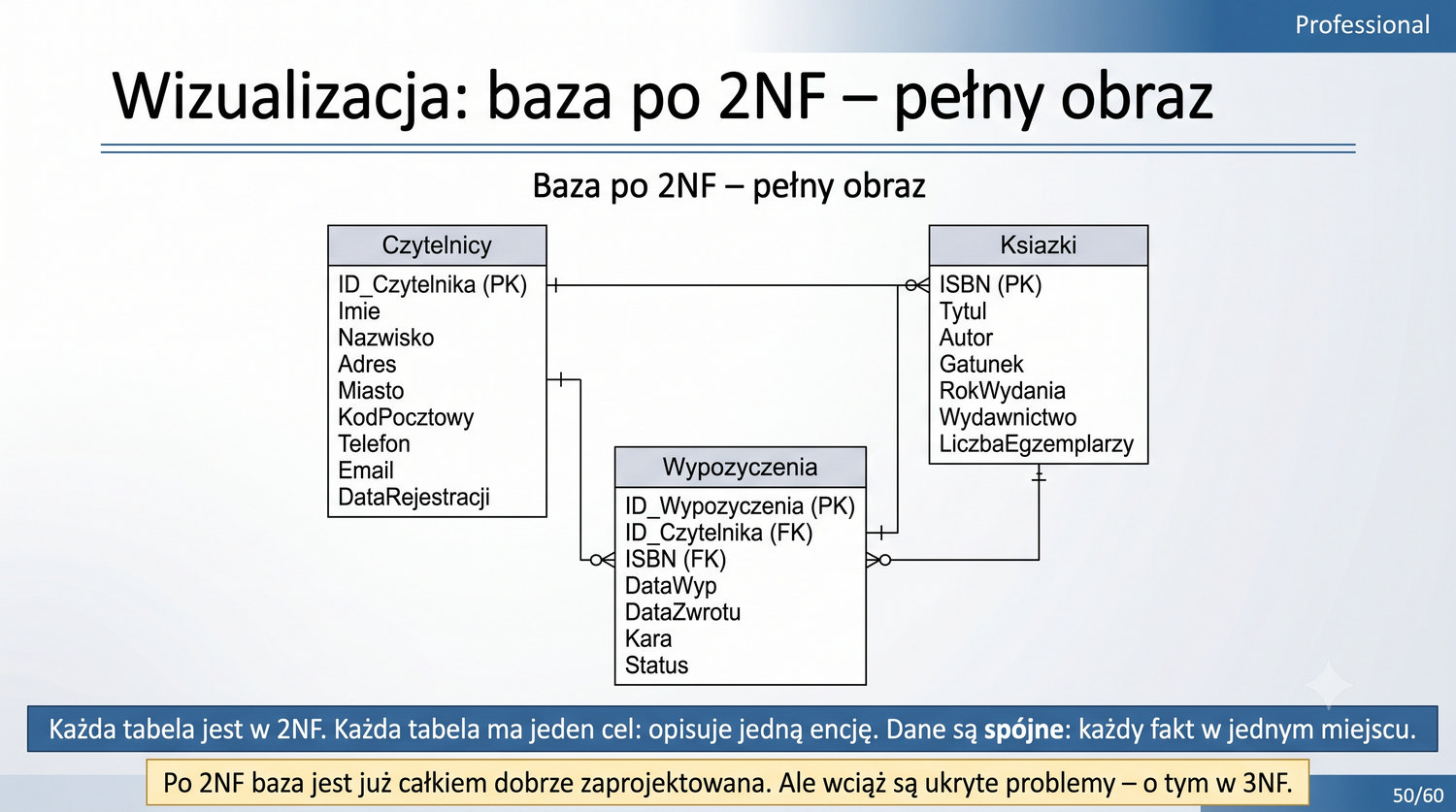
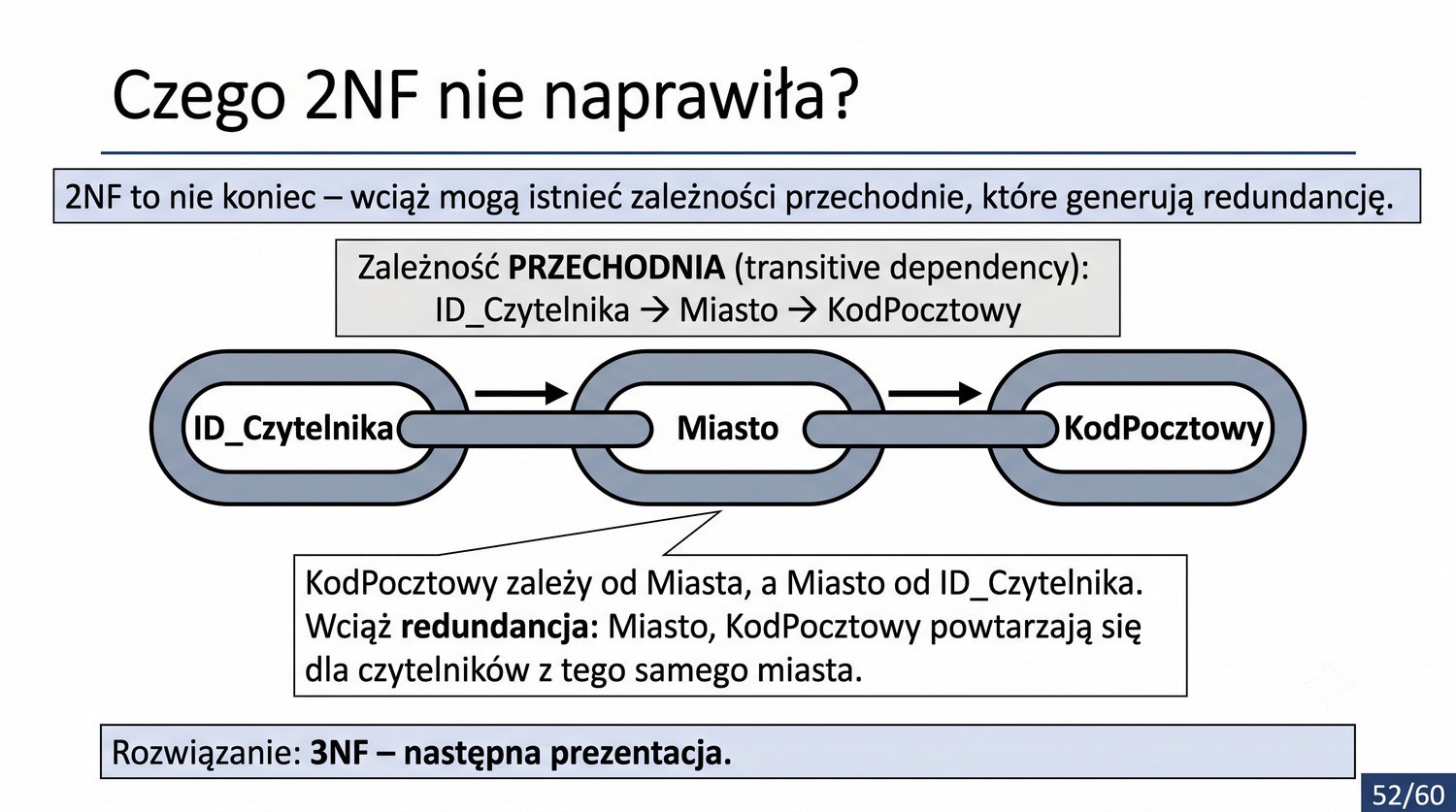
2NF – usuwamy zależności od części klucza, nie od całości