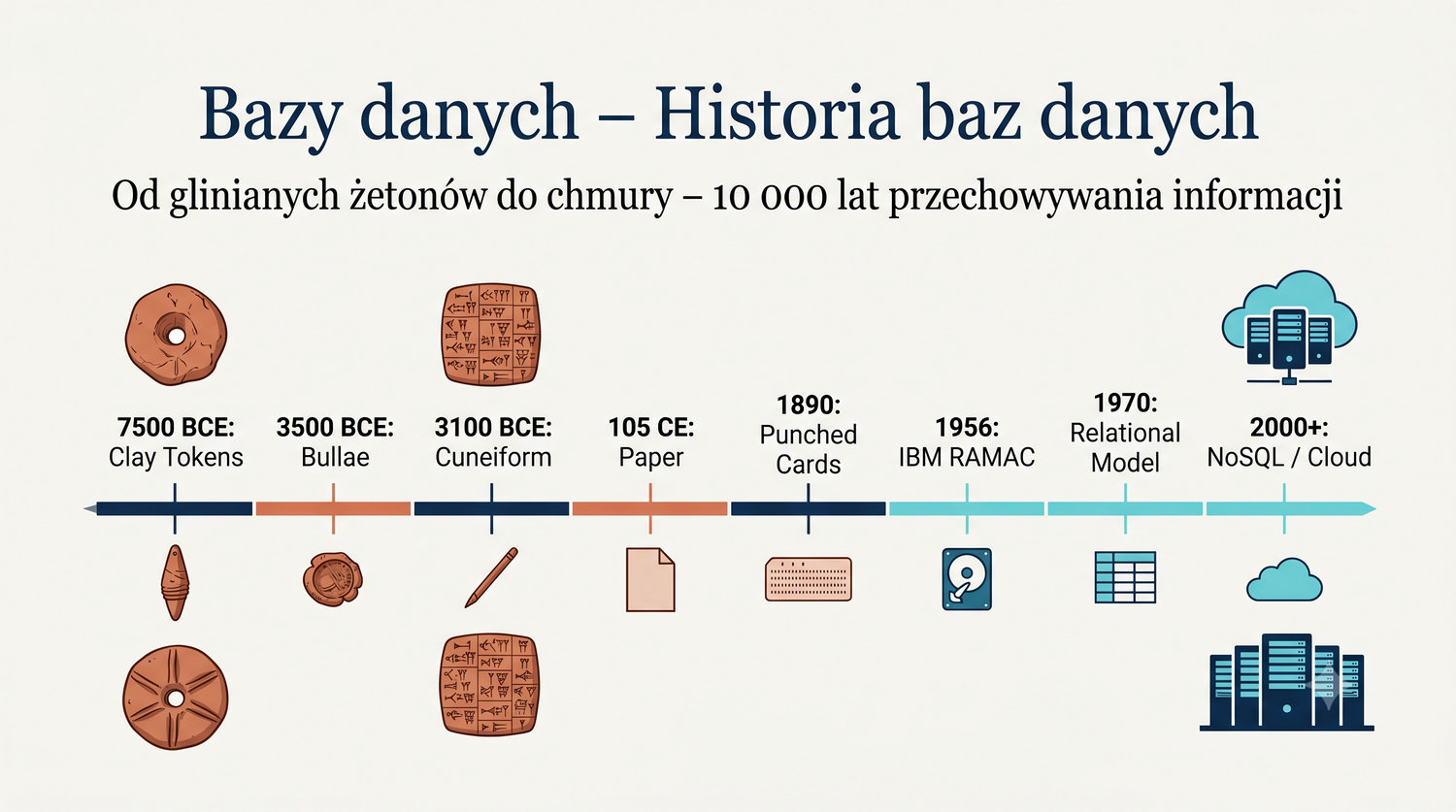
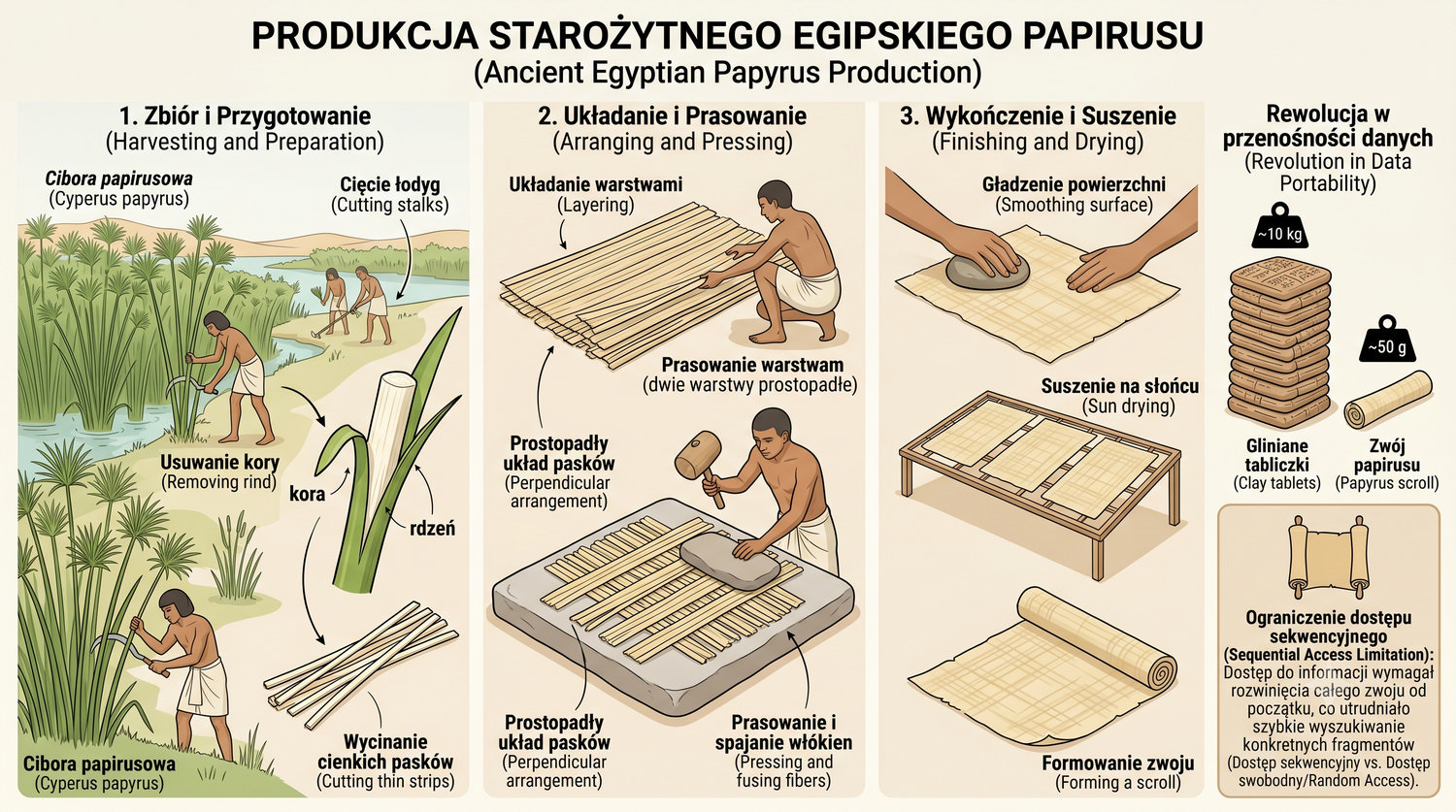
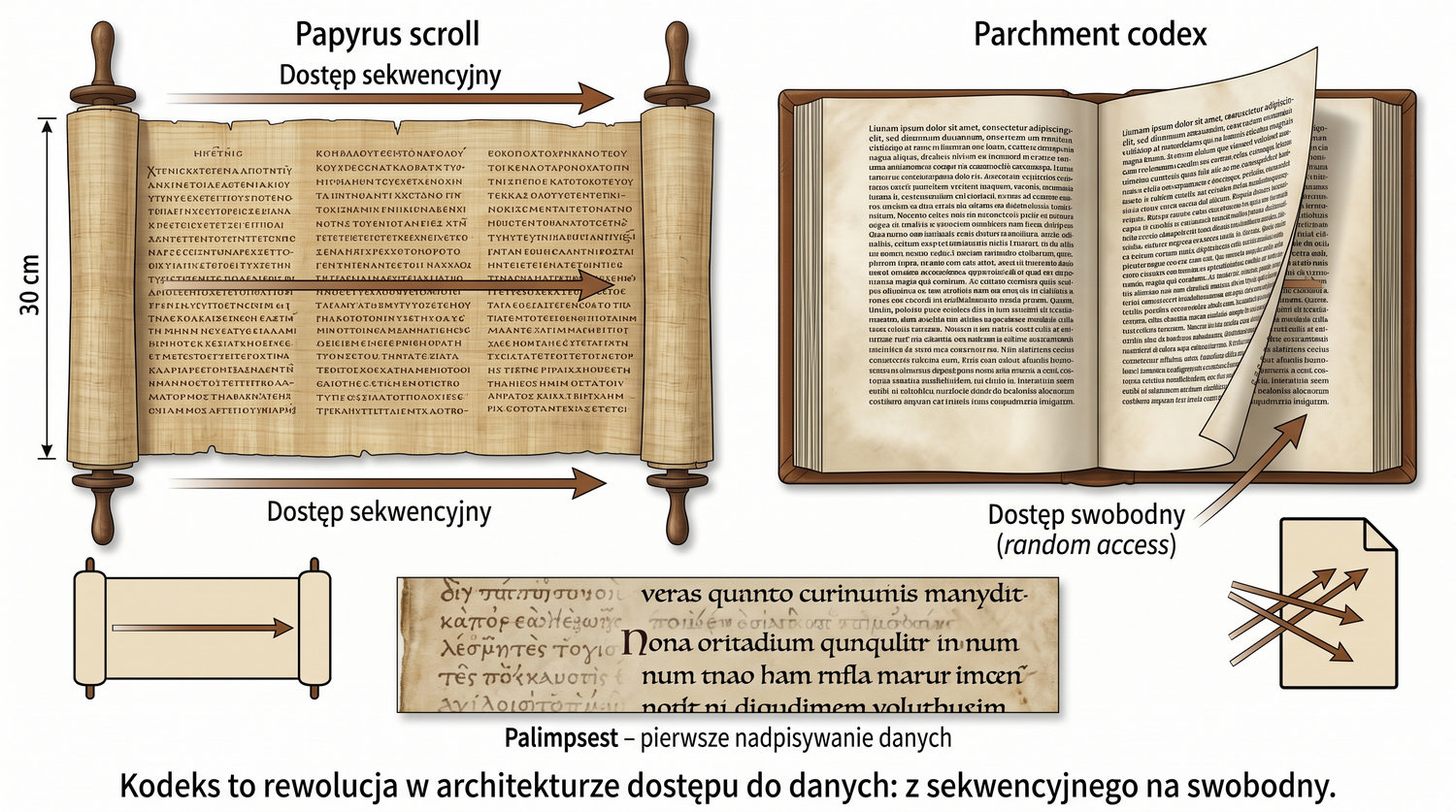
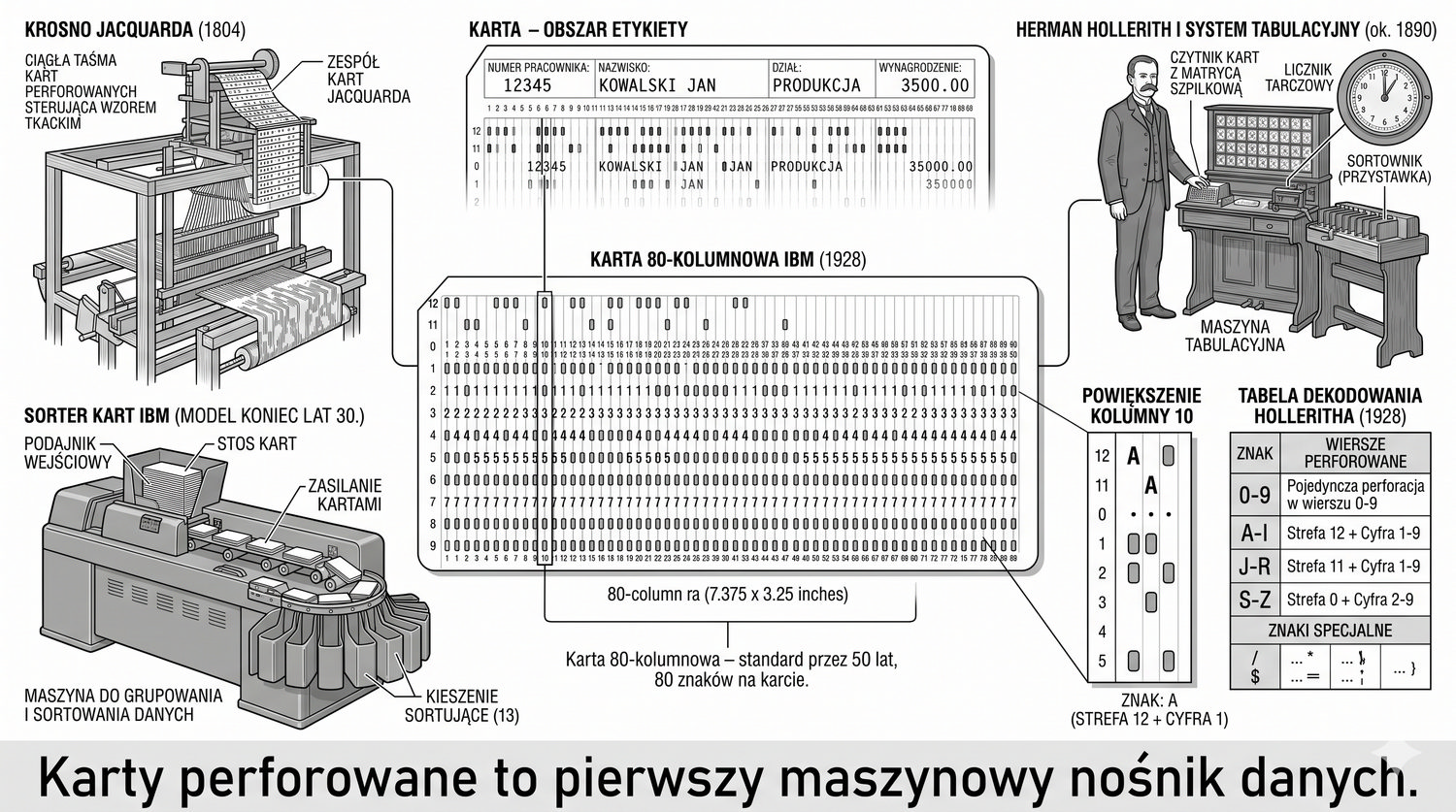
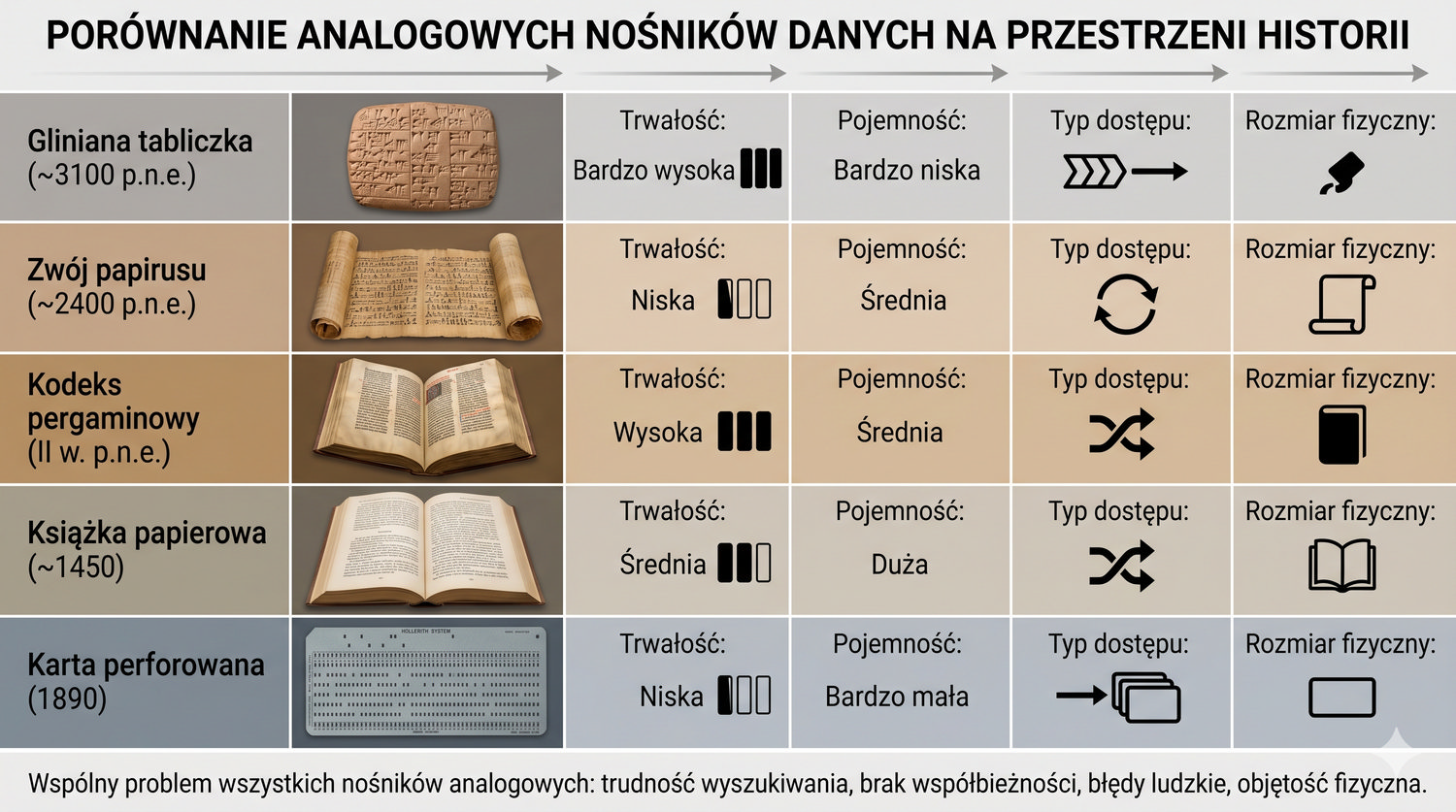
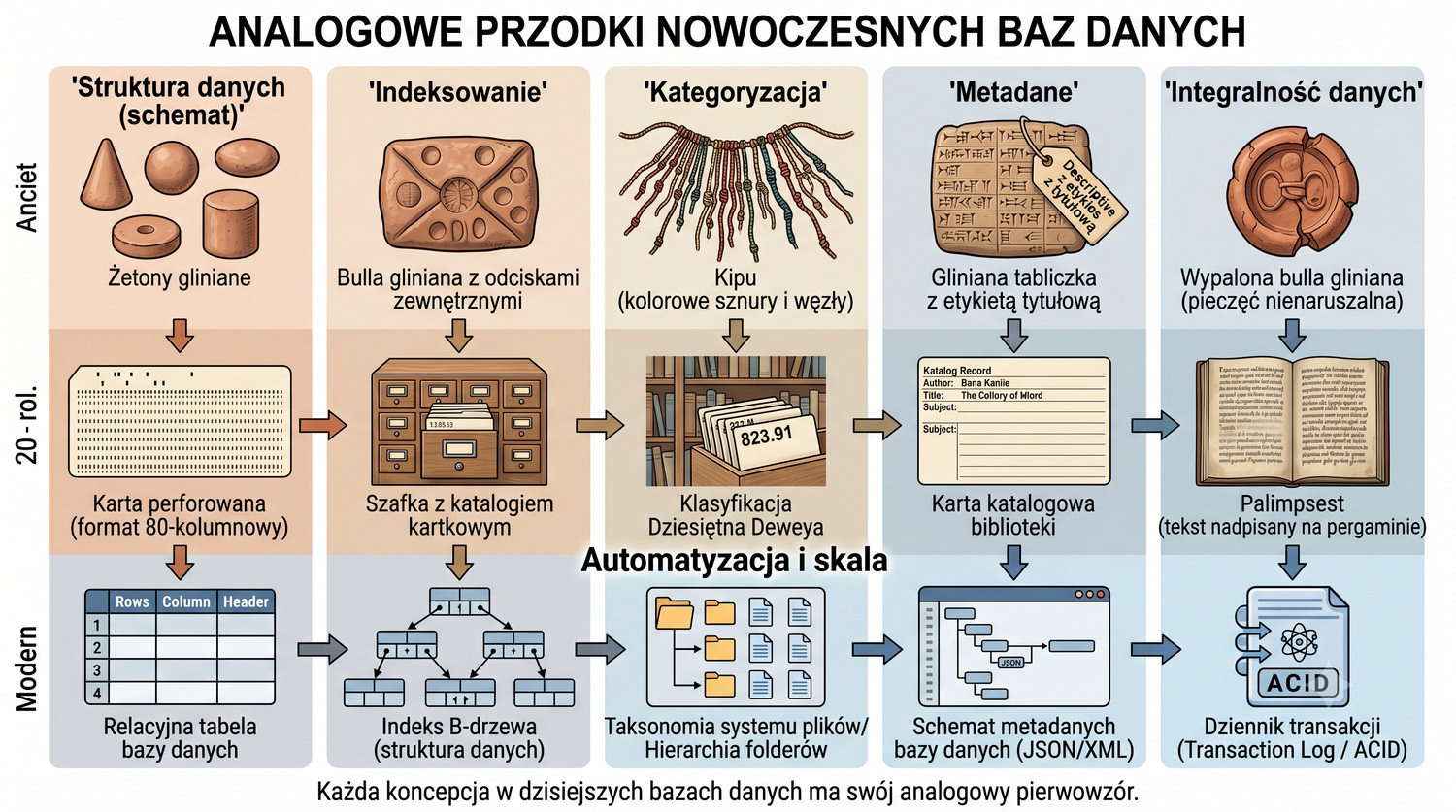
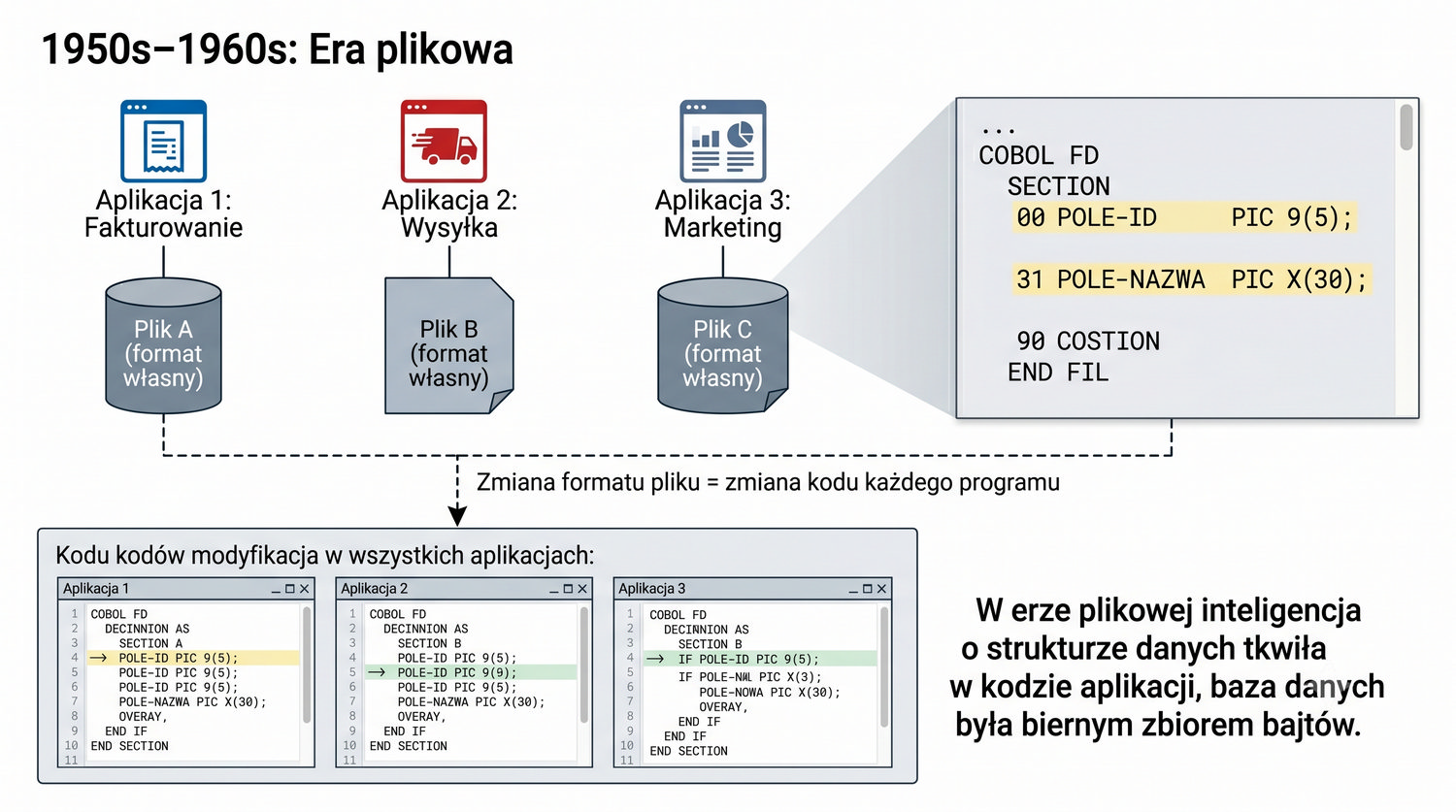
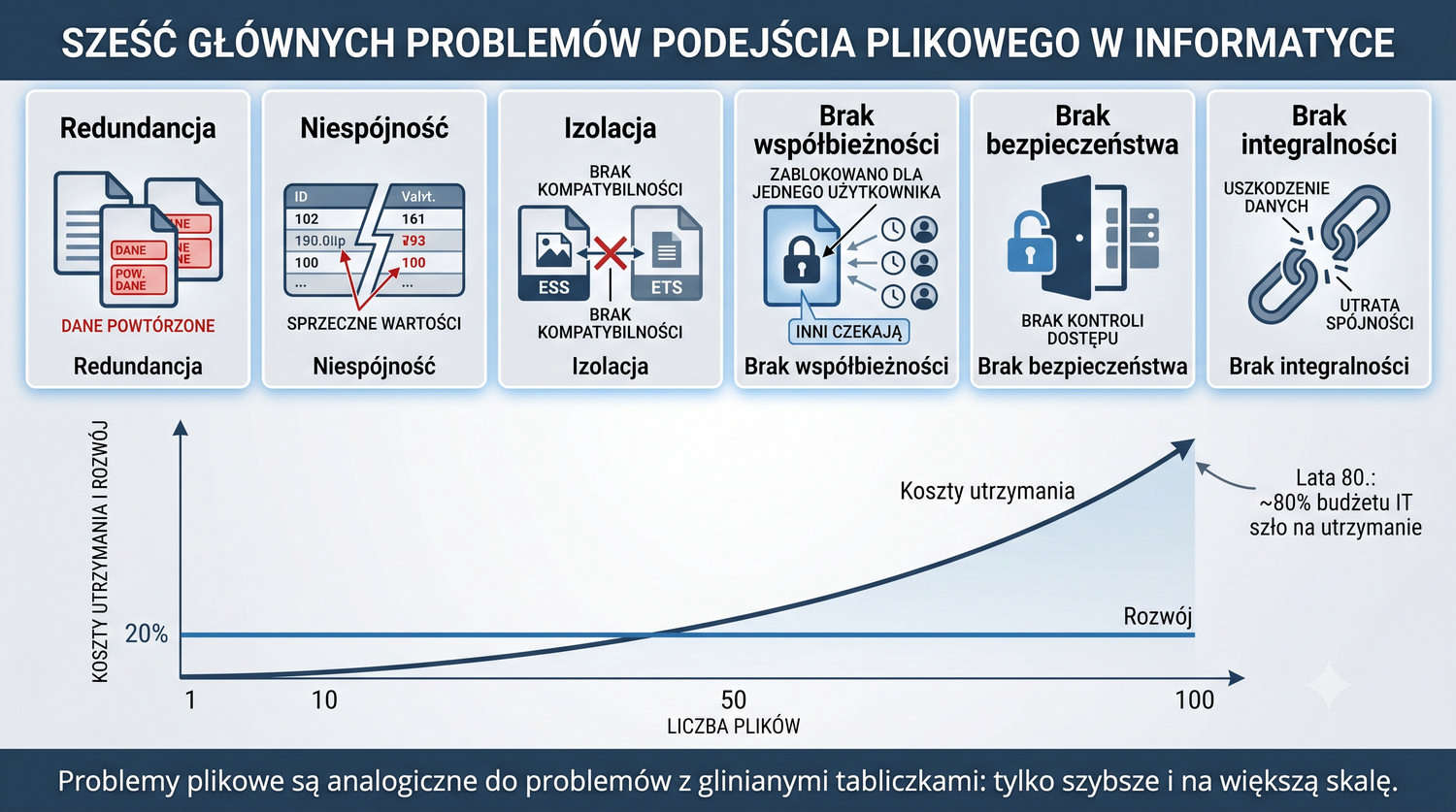
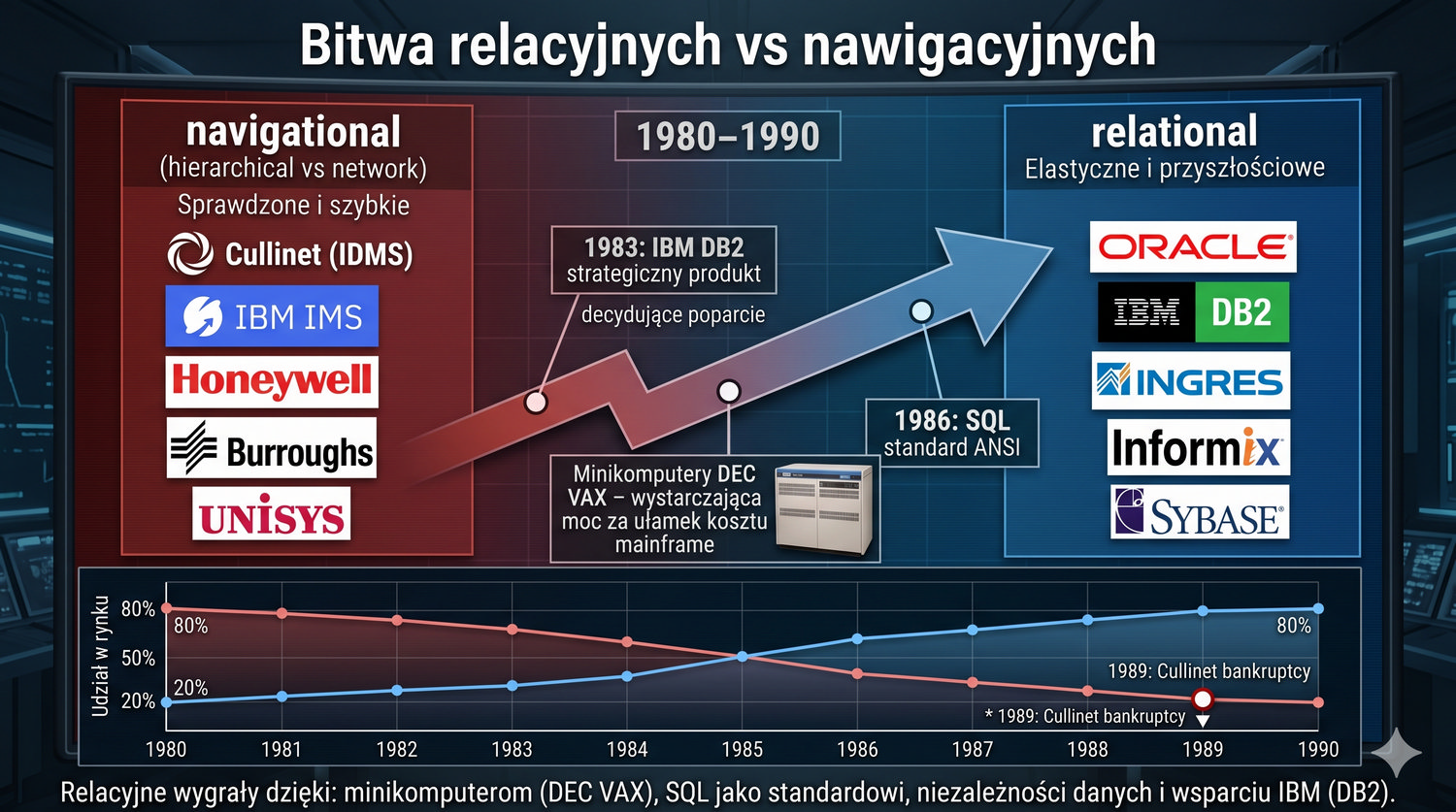
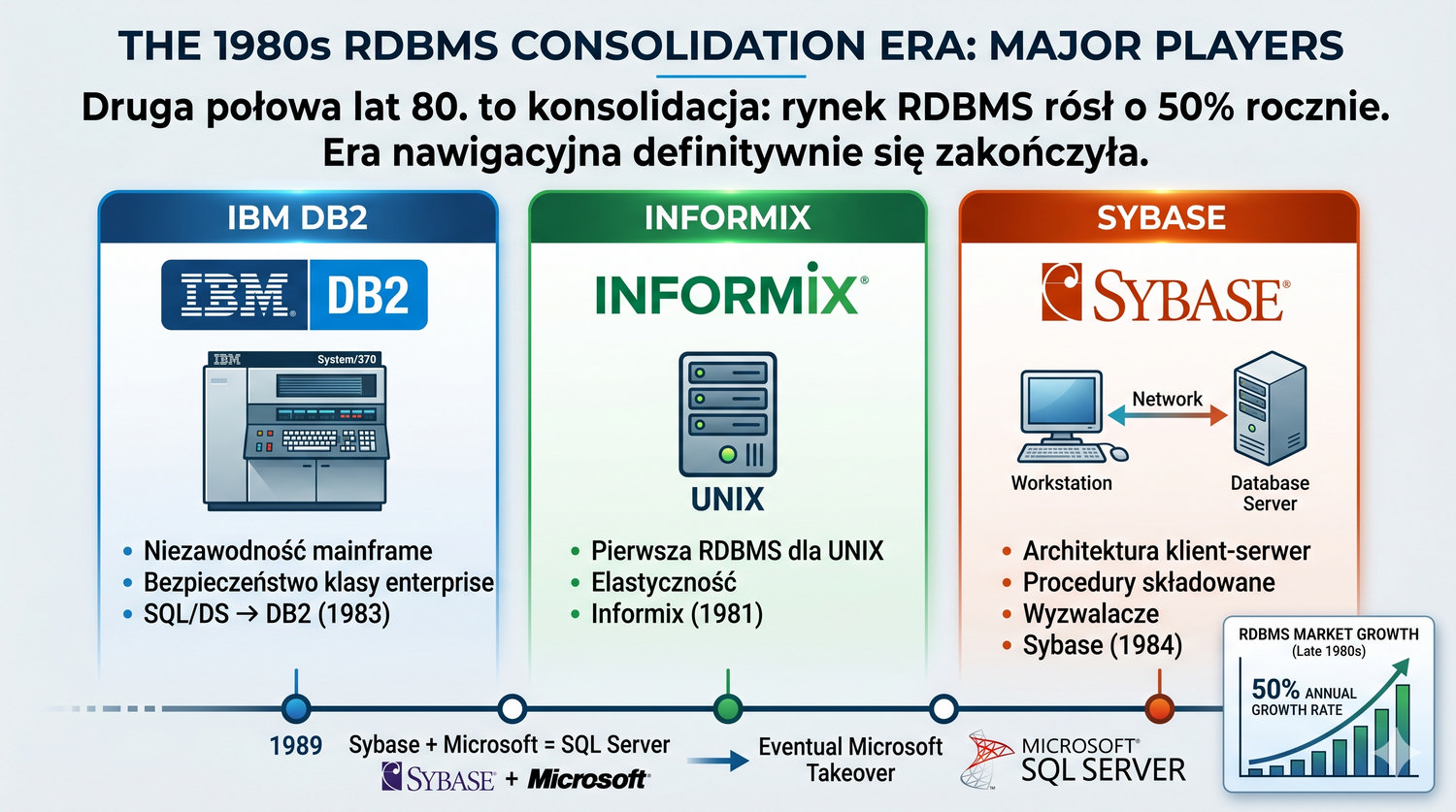
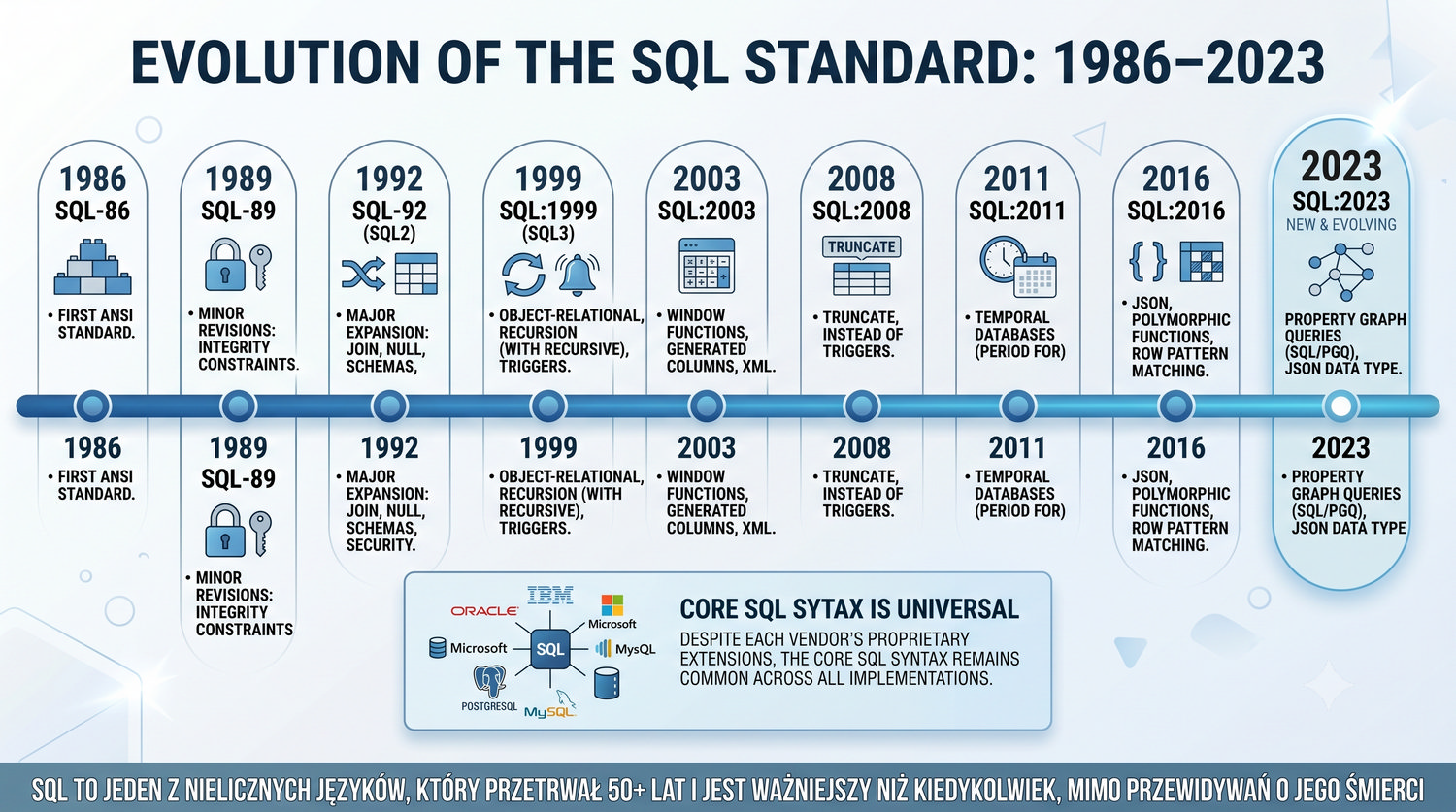
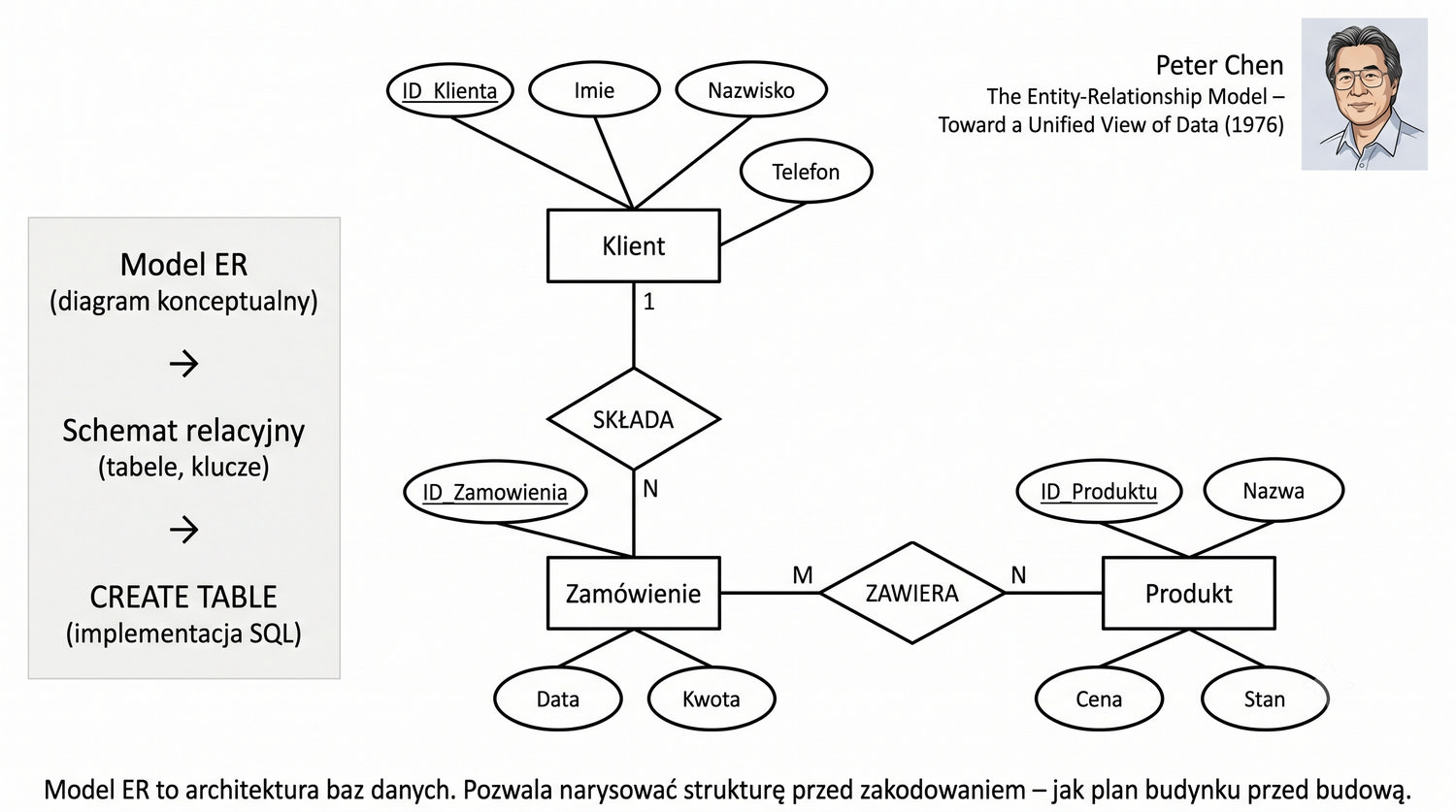
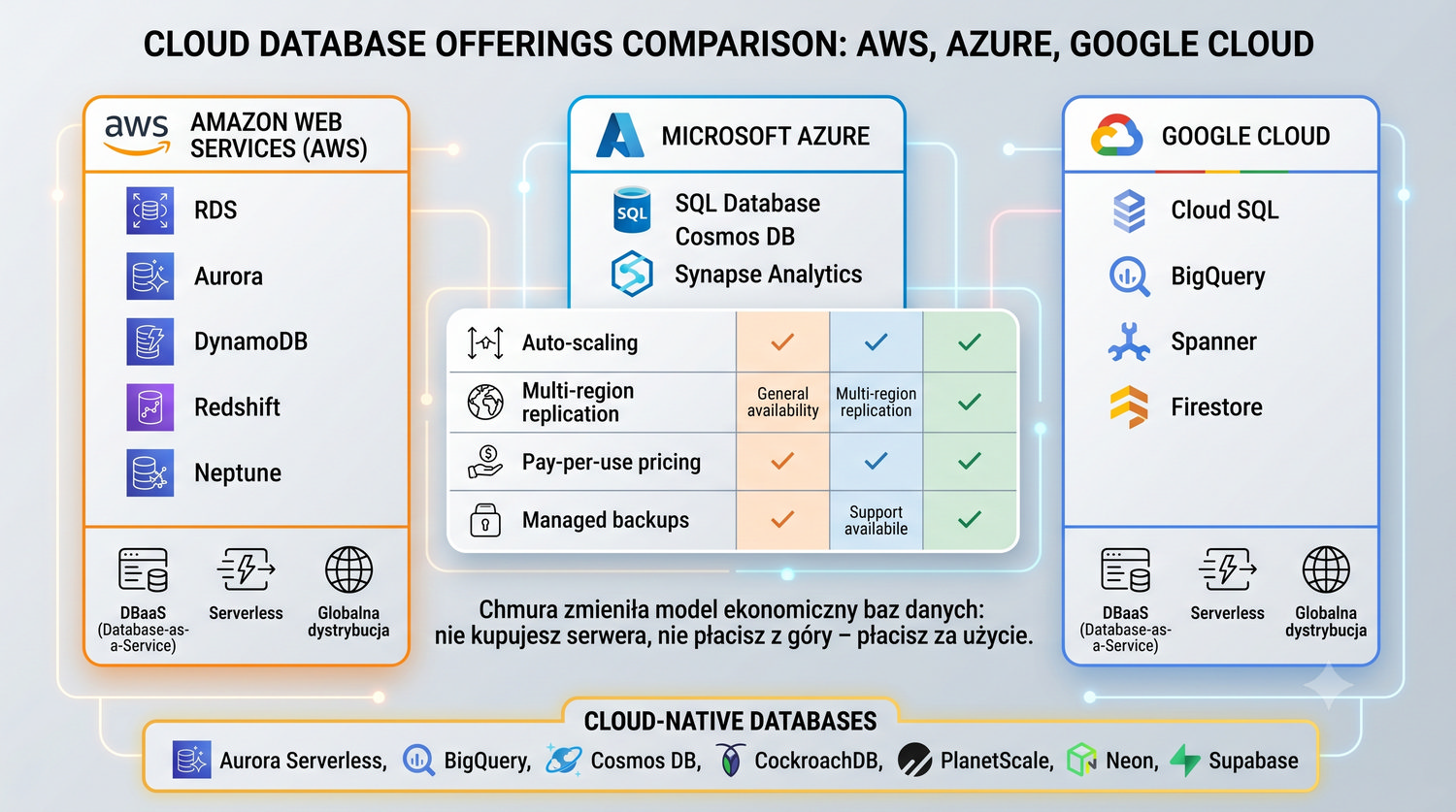
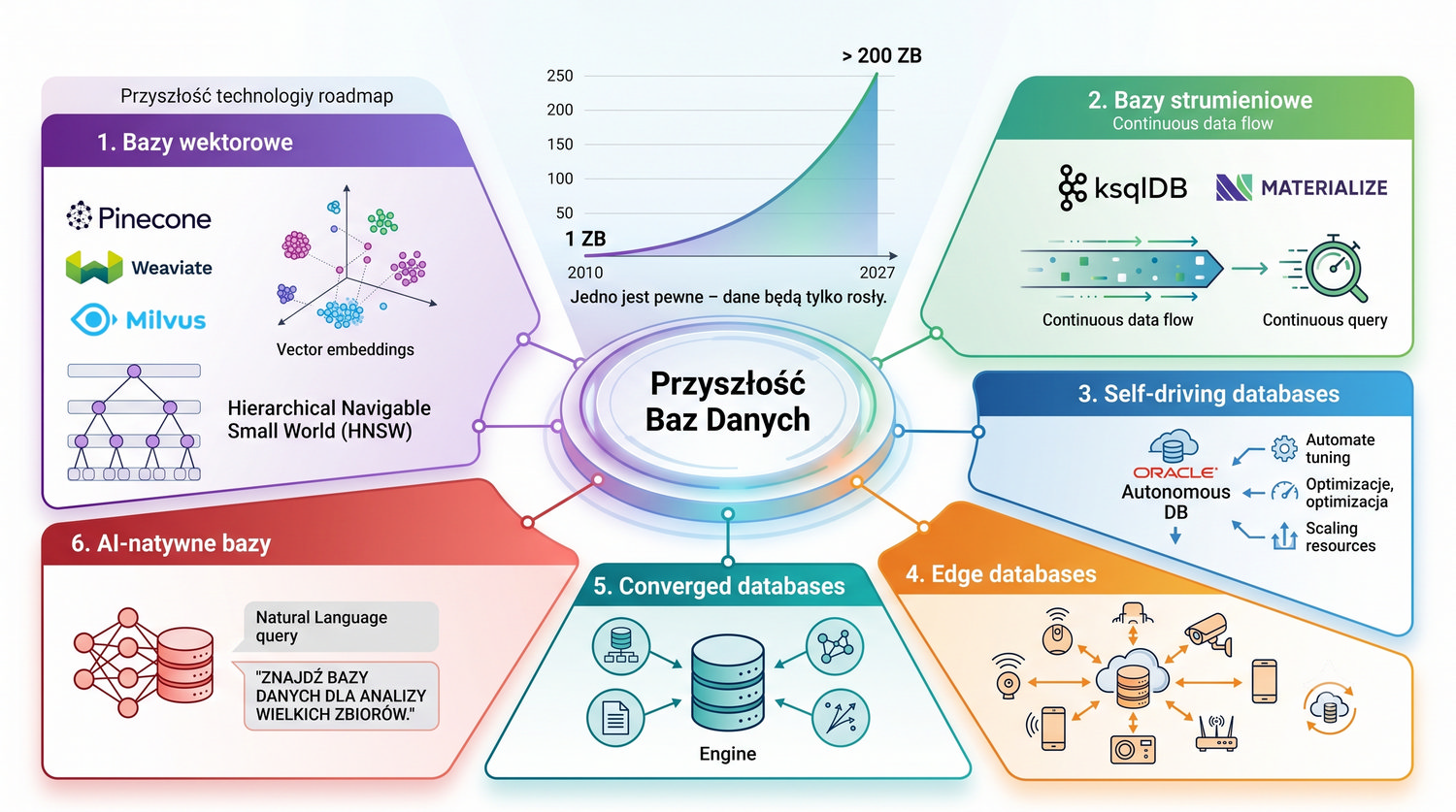
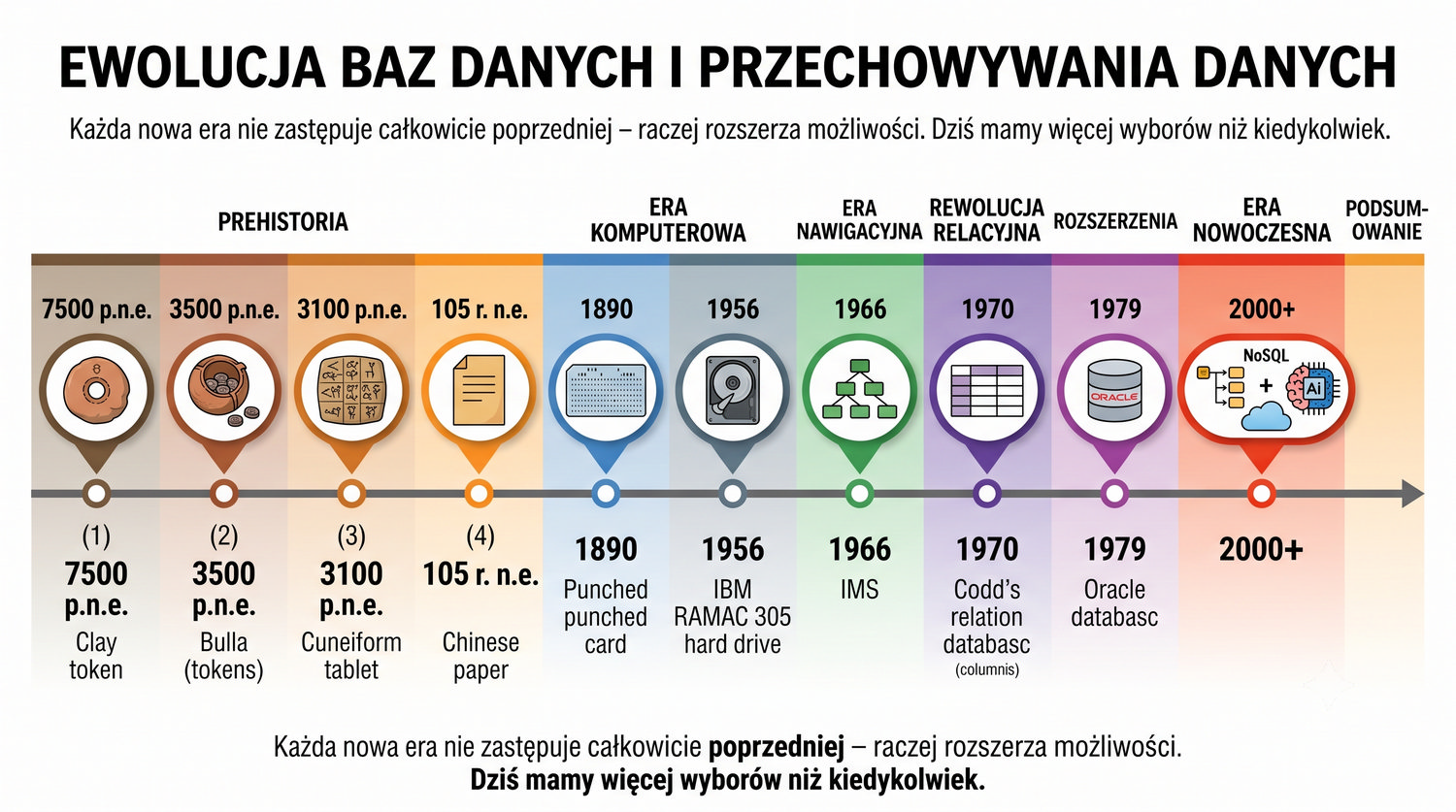
Od glinianych żetonów do chmury – 10 000 lat przechowywania informacji
Prezentacja poświęcona historii systemów przechowywania i zarządzania danymi – od pierwszych glinianych żetonów w neolicie, przez papier, karty perforowane, aż po współczesne bazy danych w chmurze.
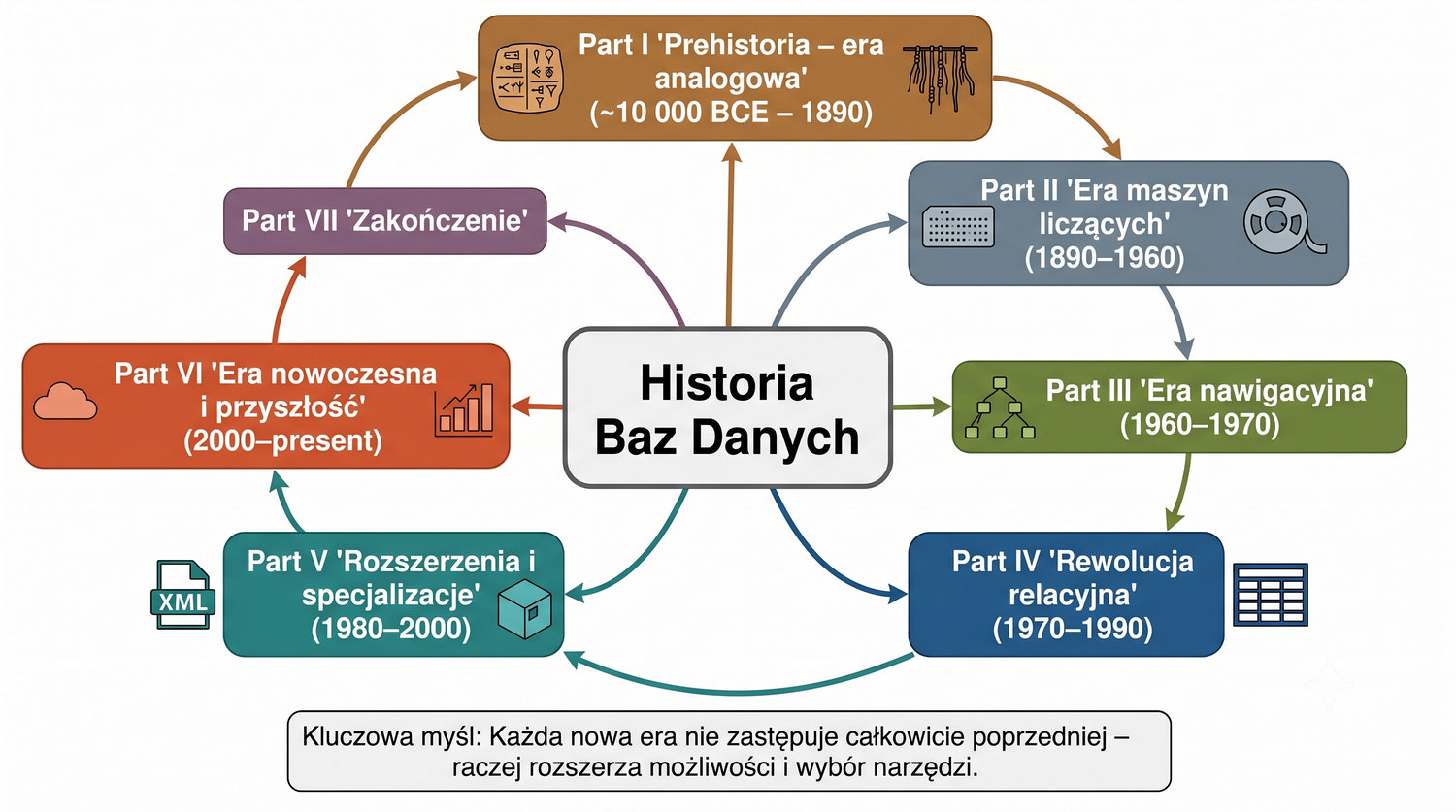
Omówione zostaną najważniejsze etapy ewolucji baz danych, kluczowe postacie, przełomowe technologie oraz lekcje płynące z historii.
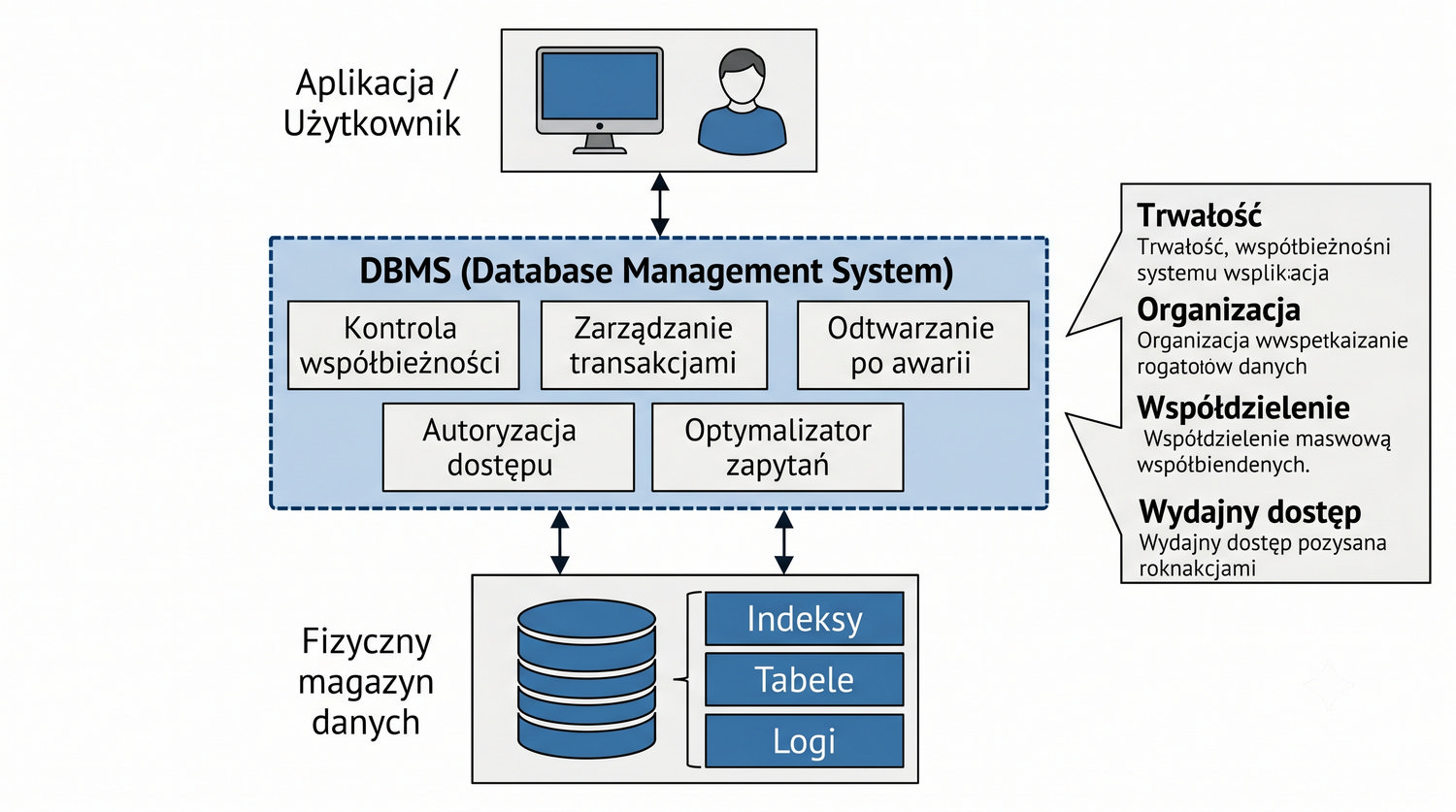
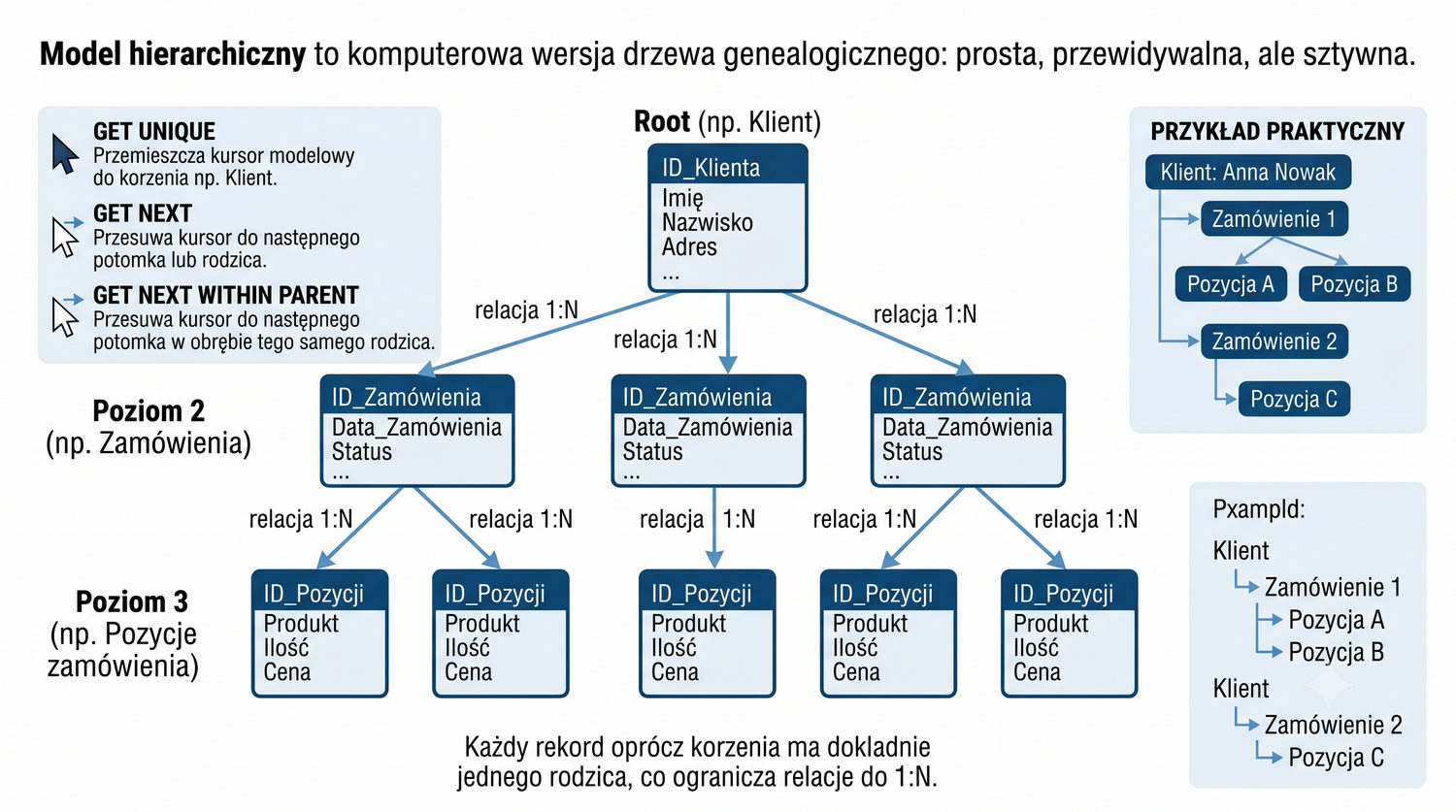
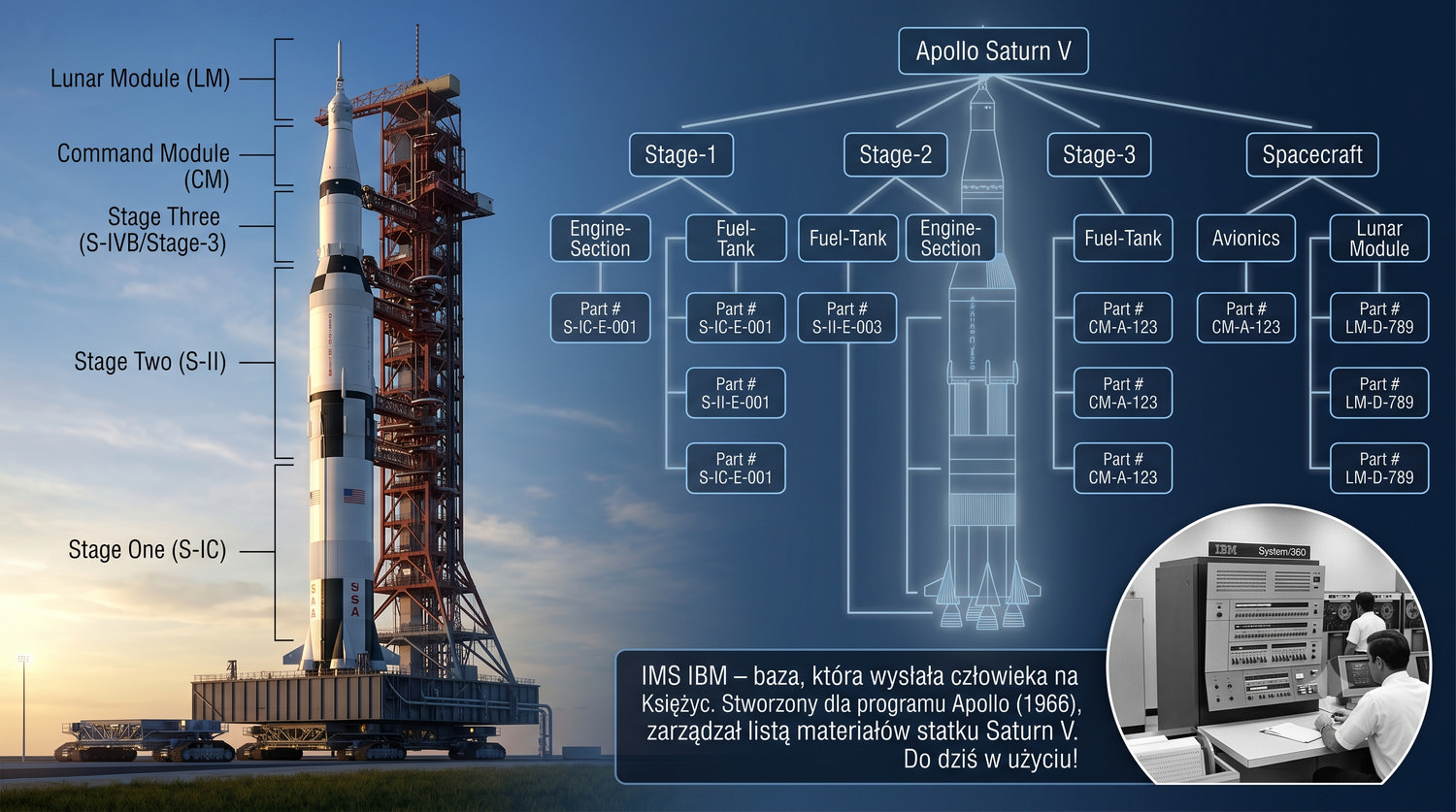
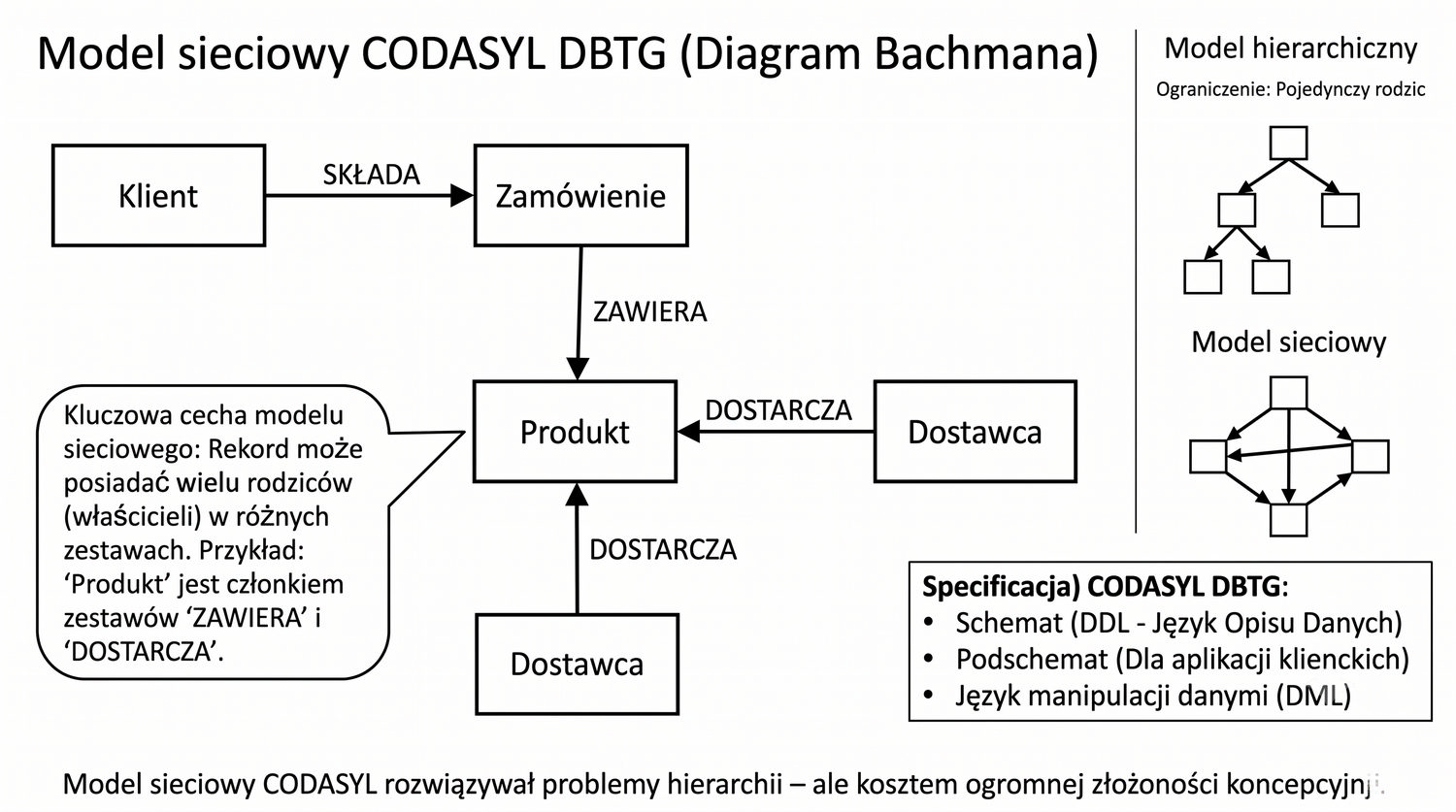
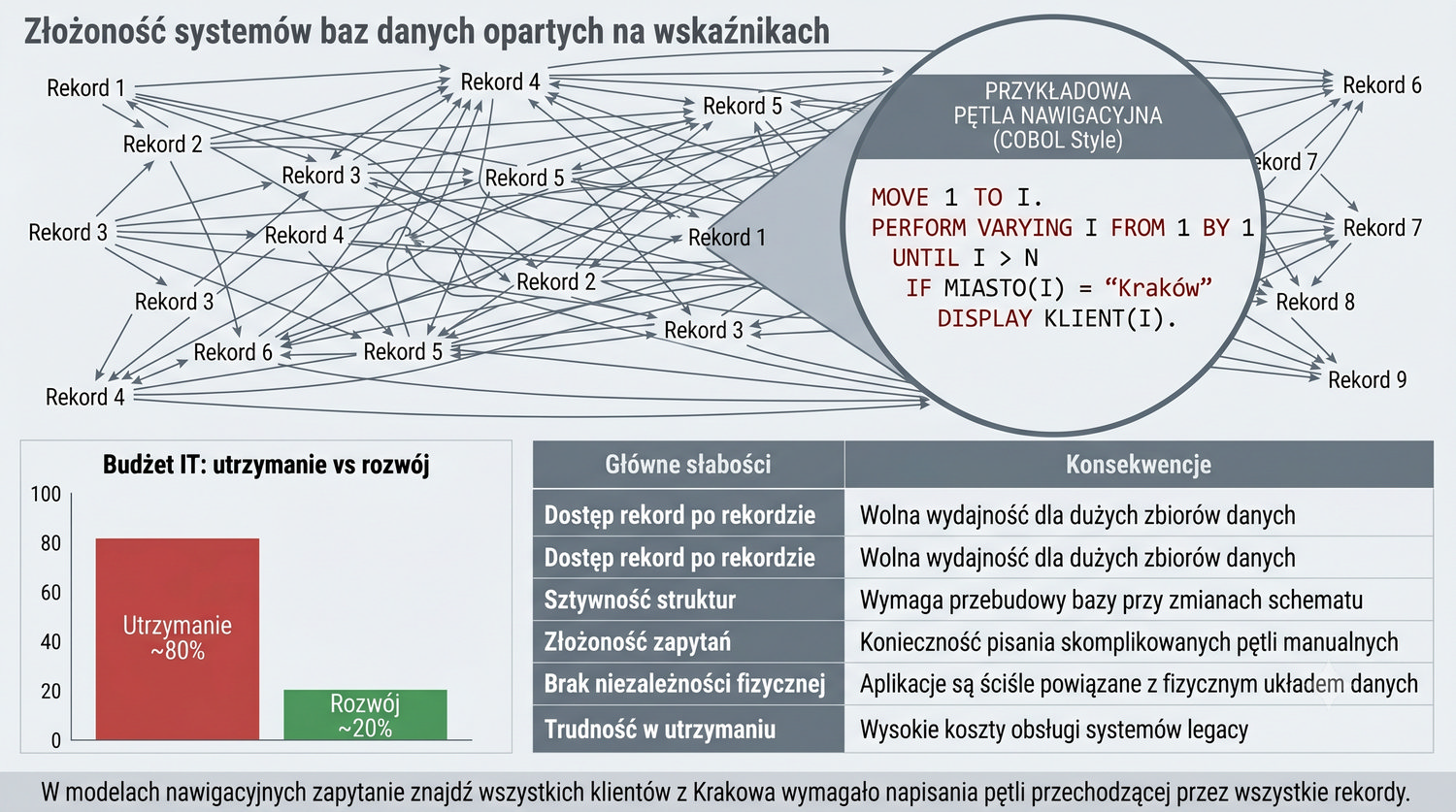
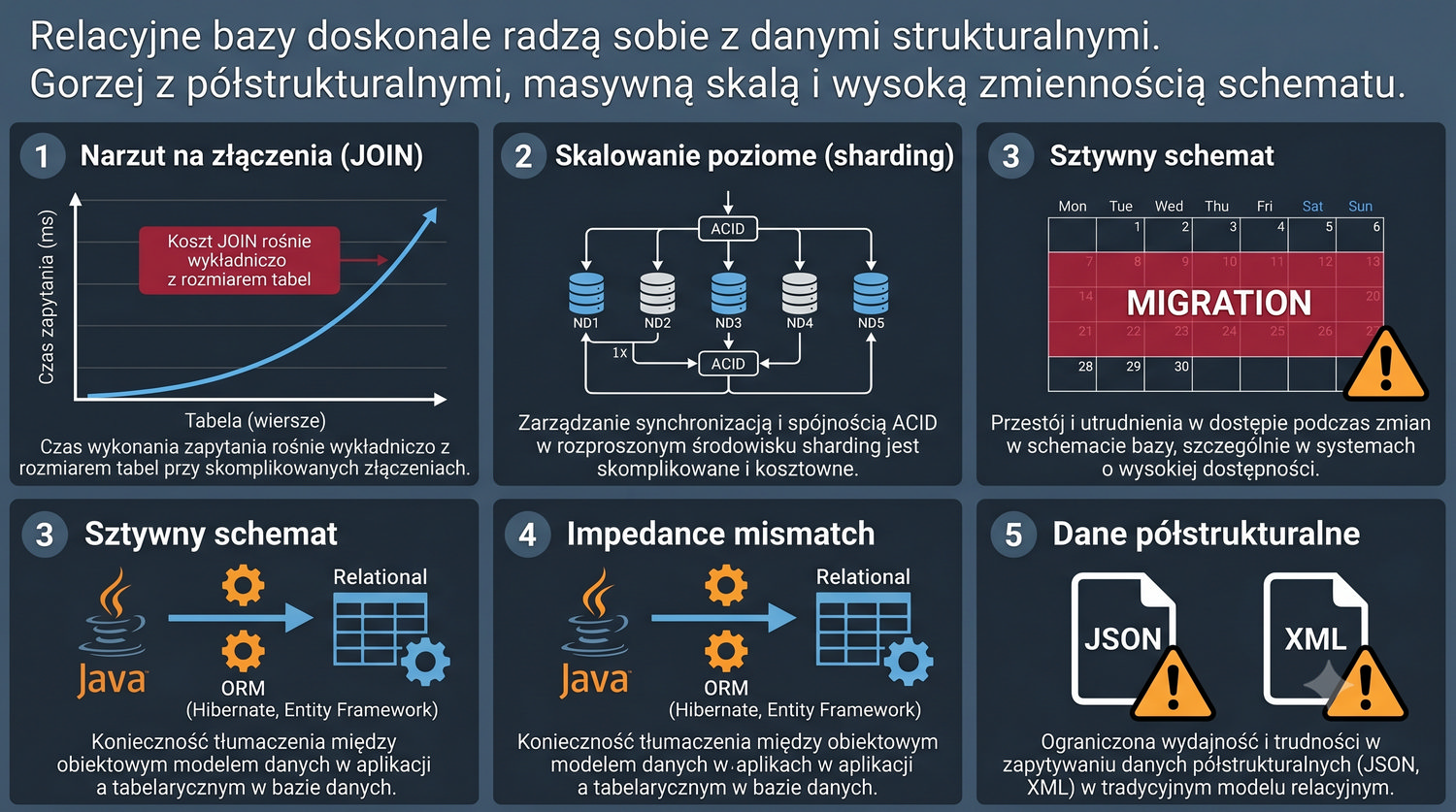
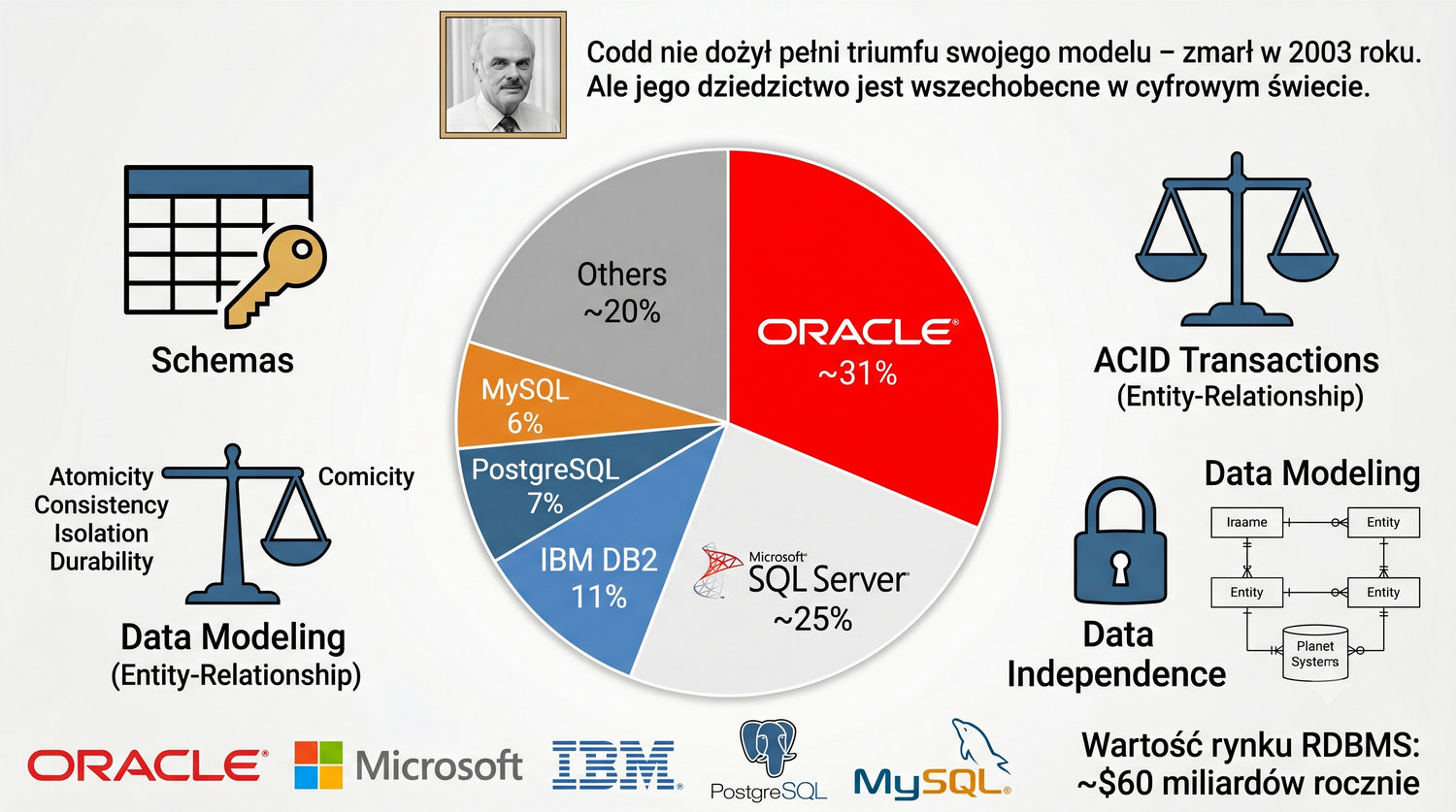
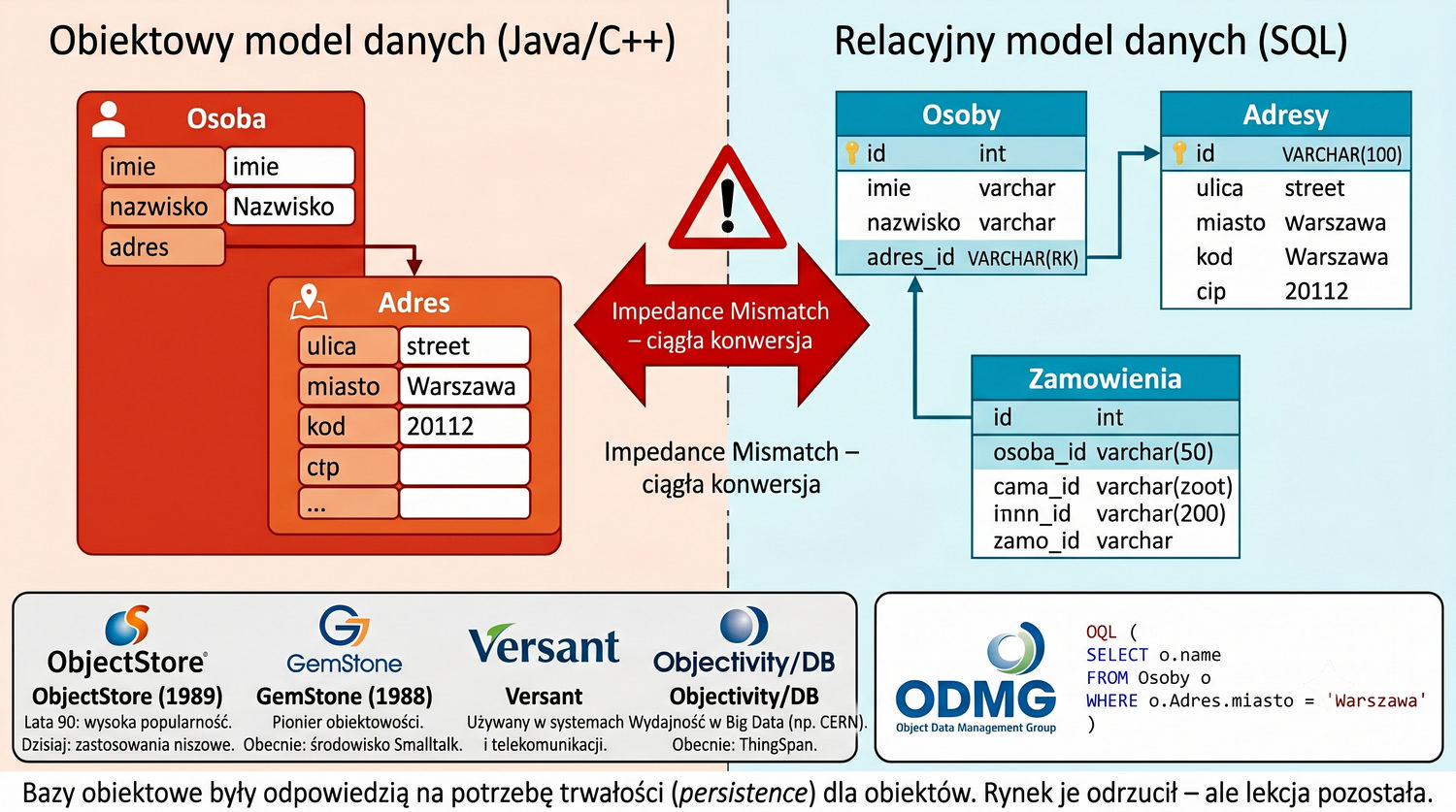
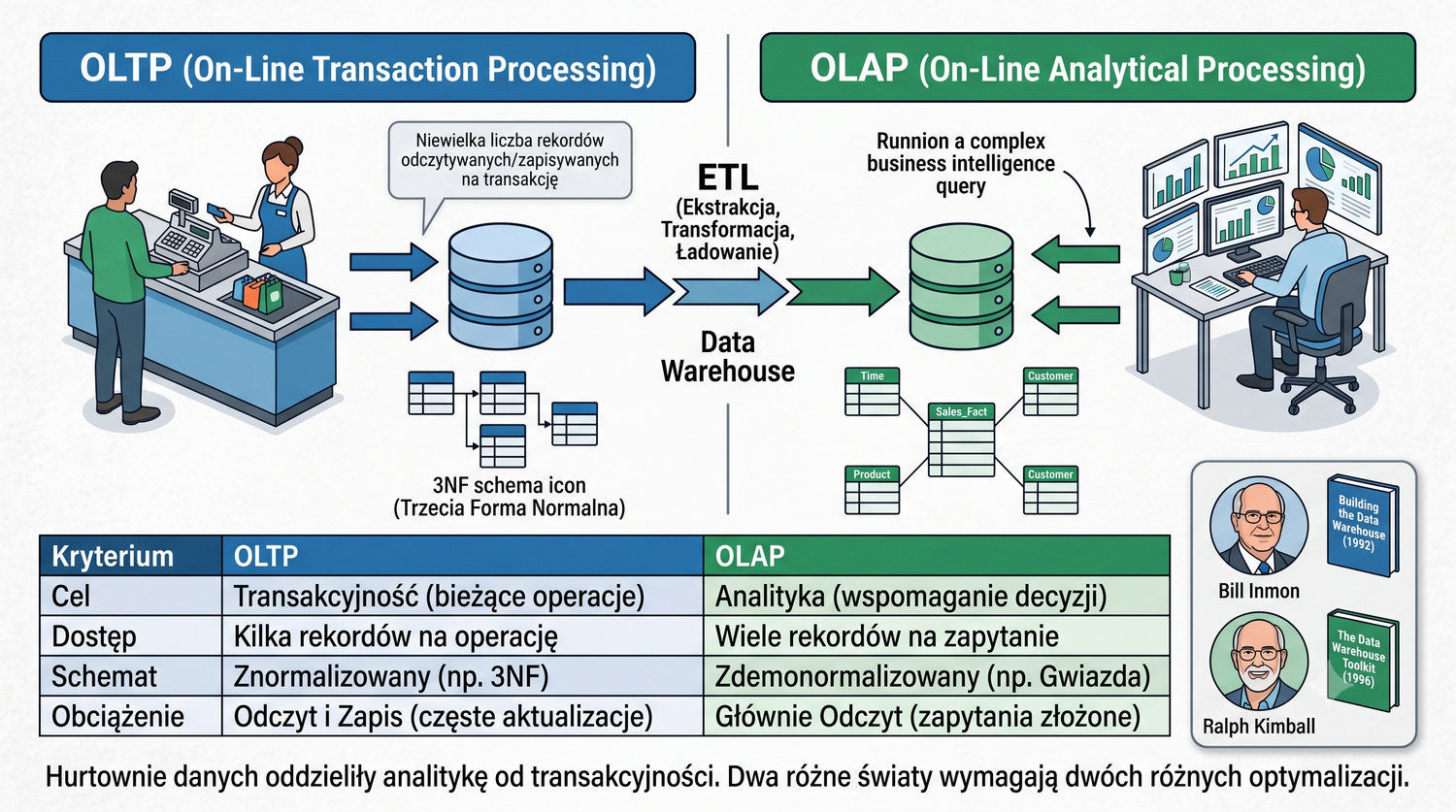
Baza danych – zorganizowany zbiór danych wraz z systemem zarządzania umożliwiającym wydajny dostęp, modyfikację i utrzymanie spójności.