Eliminacja zależności przechodnich
Po 1NF i 2NF – czas na 3NF.
3NF – usuwamy zależności łańcuchowe między atrybutami niekluczowymi
Po 1NF i 2NF – czas na 3NF.

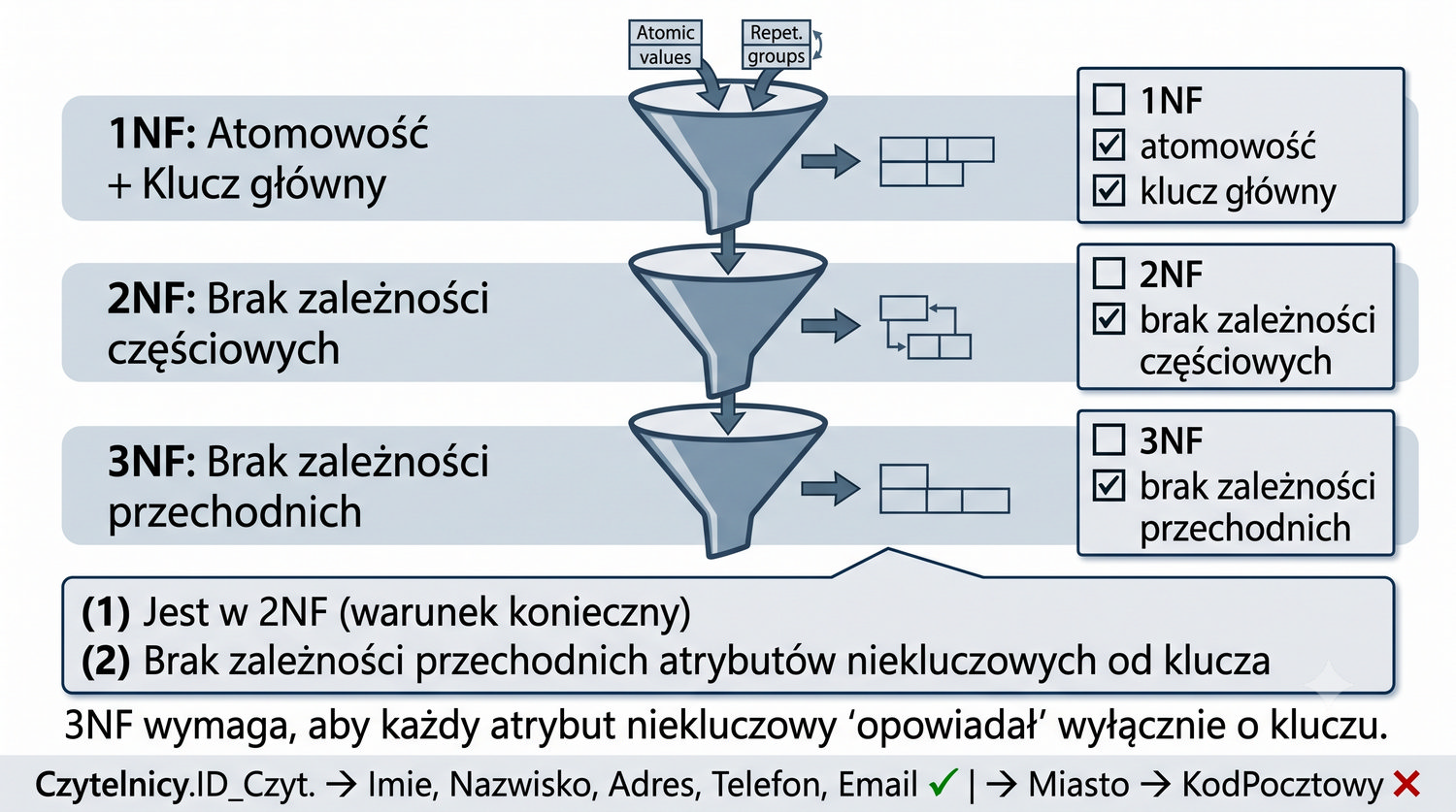
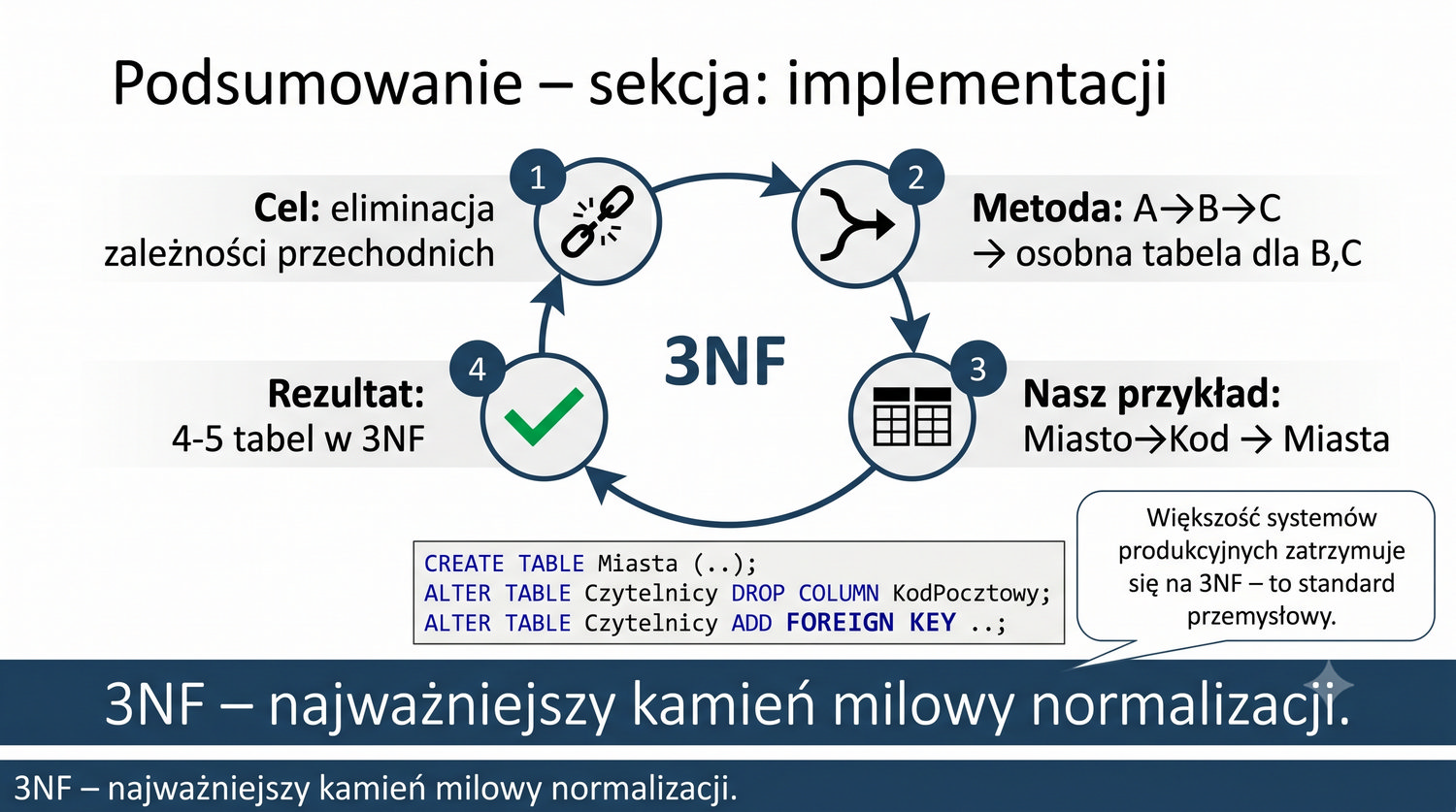
Trzecia postać normalna stanowi jeden z najważniejszych etapów normalizacji, ponieważ to właśnie do 3NF doprowadza się większość produkcyjnych baz danych w systemach biznesowych. Podczas gdy 1NF zapewniła atomowość wartości w komórkach, a 2NF wyeliminowała częściowe zależności funkcyjne poprzez podział tabel, 3NF zajmuje się eliminacją zależności przechodnich. To właśnie 3NF uznawana jest za "złoty standard" normalizacji w praktyce inżynierskiej.
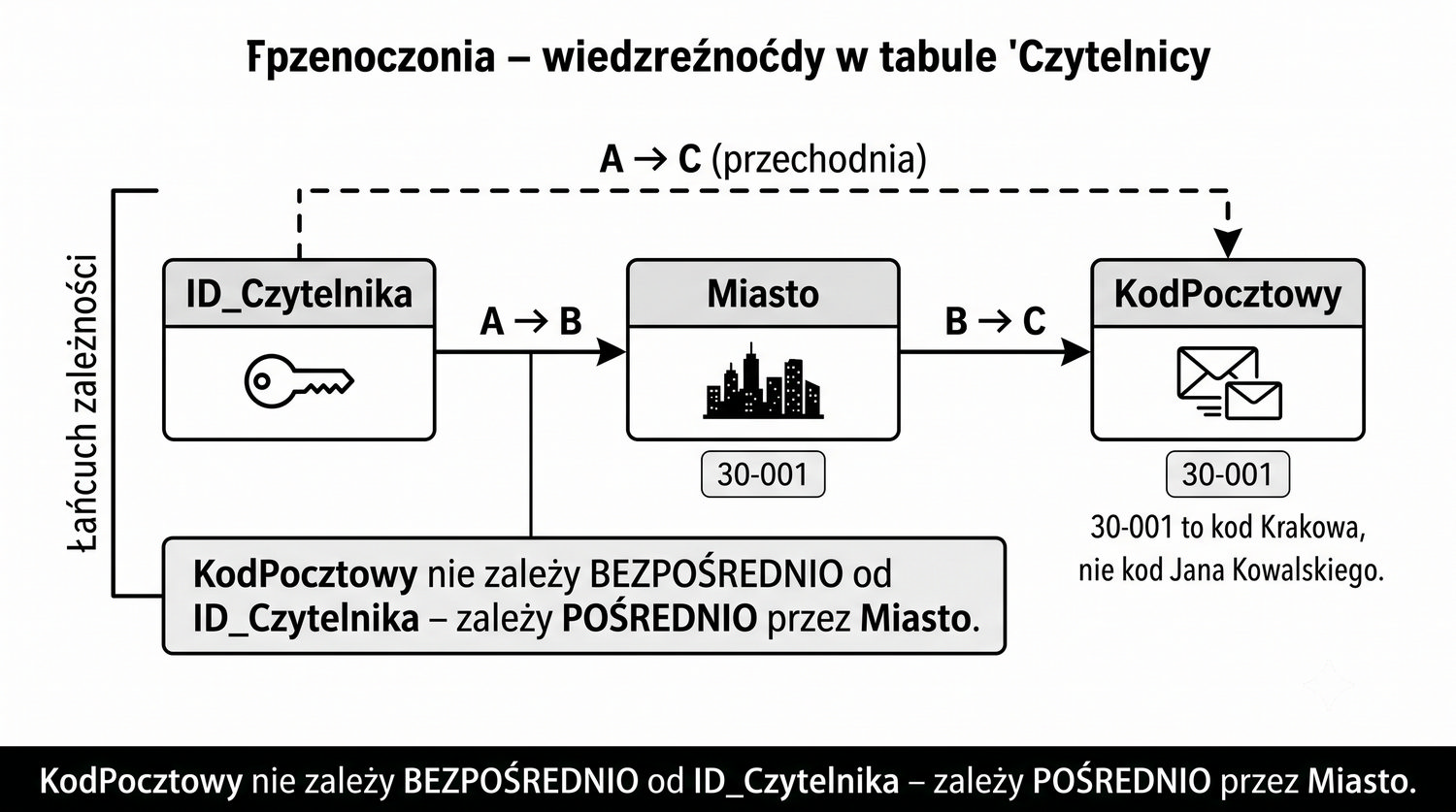
Zależność przechodnia występuje wtedy, gdy atrybut niebędący kluczem zależy od innego atrybutu niebędącego kluczem, który z kolei zależy od klucza głównego. W naszej tabeli Czytelnicy mamy taką zależność: ID_Czytelnika → Miasto → KodPocztowy. Oznacza to, że kod pocztowy zależy od miasta, a nie bezpośrednio od identyfikatora czytelnika. Konsekwencją jest możliwość wystąpienia niespójności – dwóch czytelników z tego samego miasta może mieć różne kody pocztowe.
W praktyce 3NF eliminuje ten problem poprzez utworzenie osobnej tabeli dla każdej grupy atrybutów połączonych zależnością przechodnią. W naszym przypadku utworzymy tabelę Miasta, która będzie przechowywać unikalne pary (Miasto, KodPocztowy). Dzięki temu kod pocztowy będzie przechowywany tylko raz dla każdego miasta, co całkowicie eliminuje ryzyko niespójności i redukuje redundancję danych.
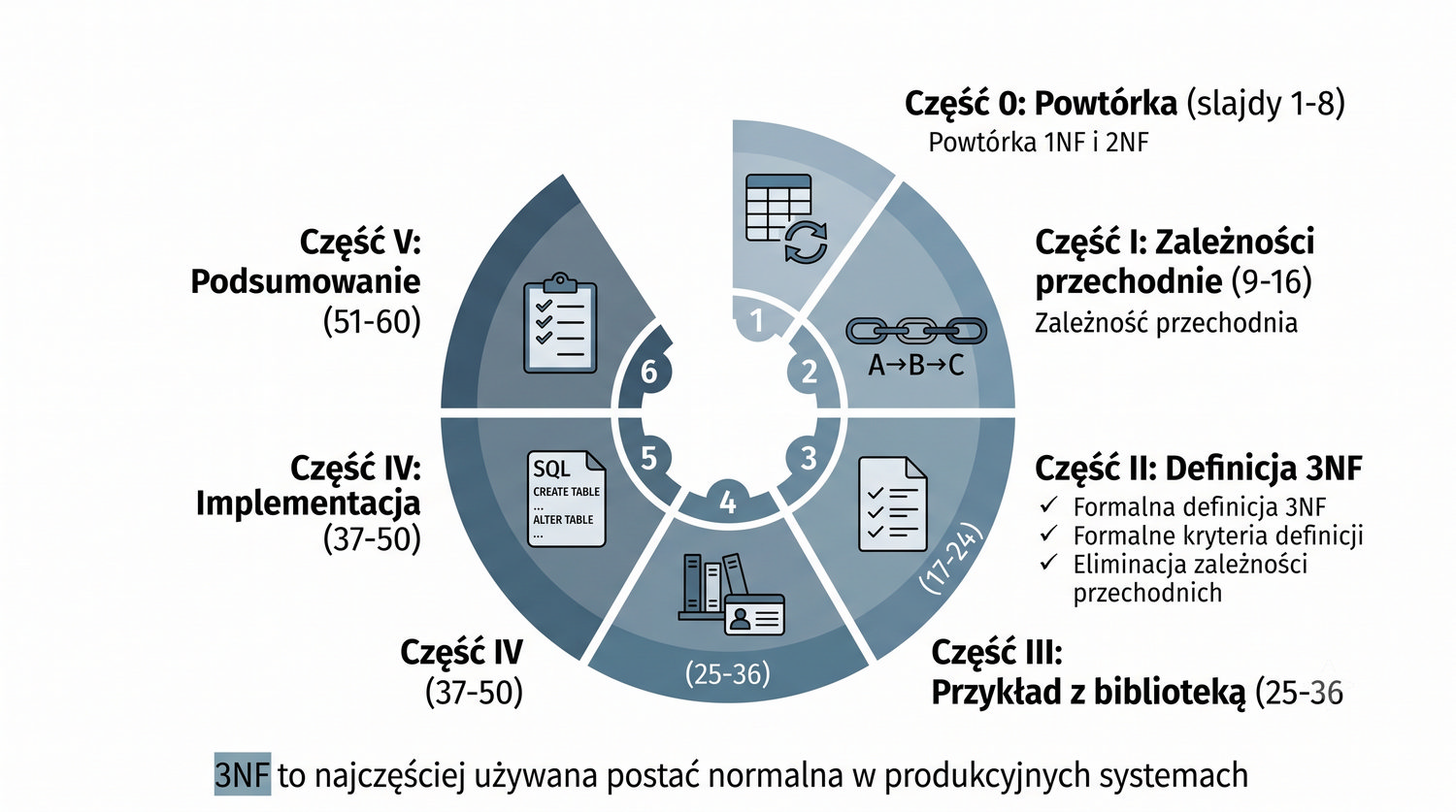
Prezentacja o 3NF została zaprojektowana według sprawdzonego schematu dydaktycznego: rozpoczyna się od przypomnienia wiedzy o 1NF i 2NF, następnie wprowadza koncepcję zależności przechodnich, definiuje 3NF, demonstruje dekompozycję na praktycznym przykładzie bibliotecznym, a kończy implementacją w MariaDB i podsumowaniem. Taka struktura zapewnia płynne przejście od znanych już koncepcji do nowego materiału.
Szczególnie istotna jest część poświęcona implementacji, w której zobaczysz, jak utworzyć tabelę Miasta, przenieść do niej dane i powiązać z tabelą Czytelnicy za pomocą klucza obcego. To praktyczne umiejętności, które będą Ci potrzebne w codziennej pracy z bazami danych, niezależnie od tego, czy projektujesz nowy system, czy refaktoryzujesz istniejący.
W ostatniej części prezentacji znajdziesz ćwiczenia do samodzielnego wykonania, które pomogą Ci utrwalić zdobytą wiedzę. Zachęcam do aktywnego uczestnictwa w każdej części i notowania pytań, które pojawią się w trakcie prezentacji. Pamiętaj, że 3NF jest standardem w projektowaniu baz danych – jej opanowanie jest niezbędne dla każdego inżyniera oprogramowania.
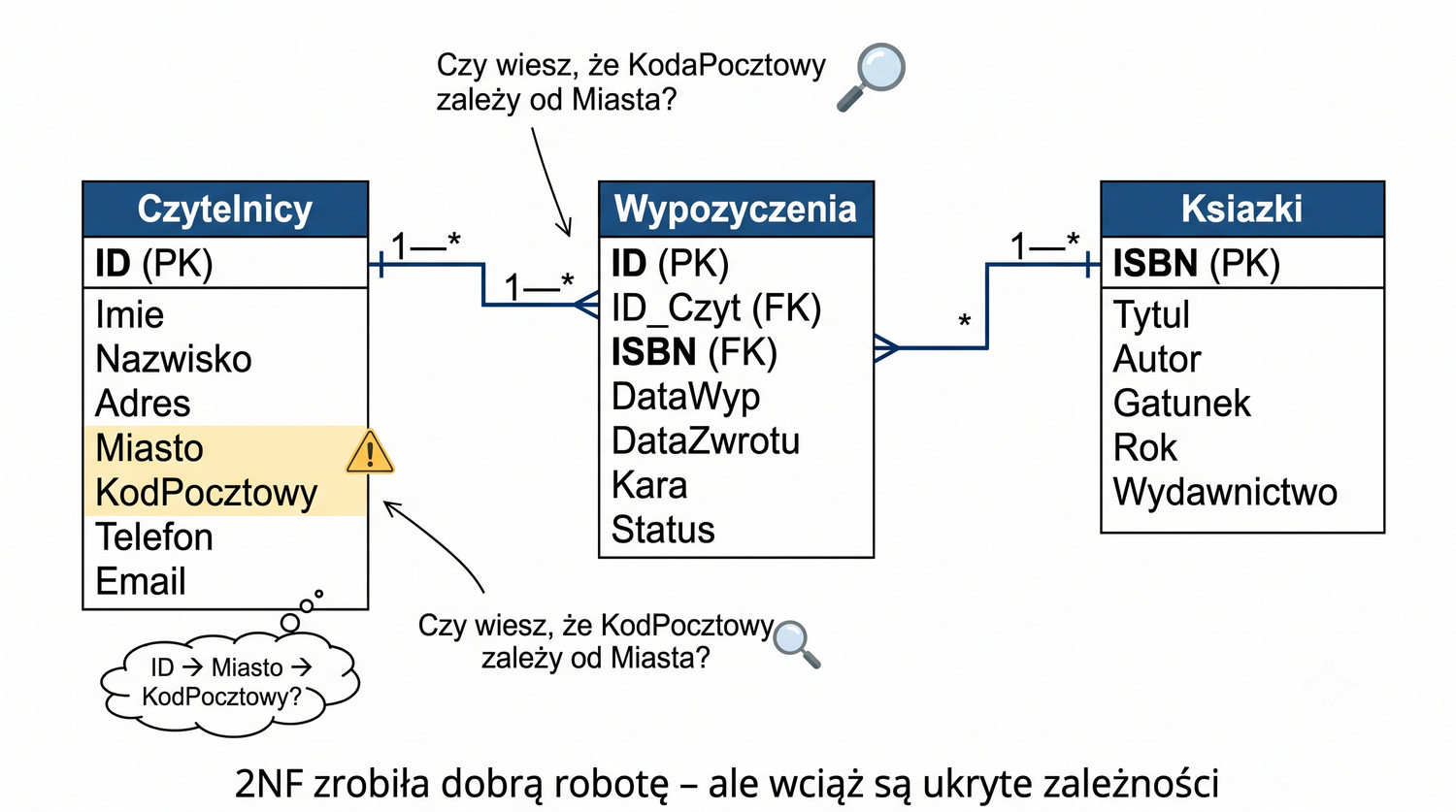
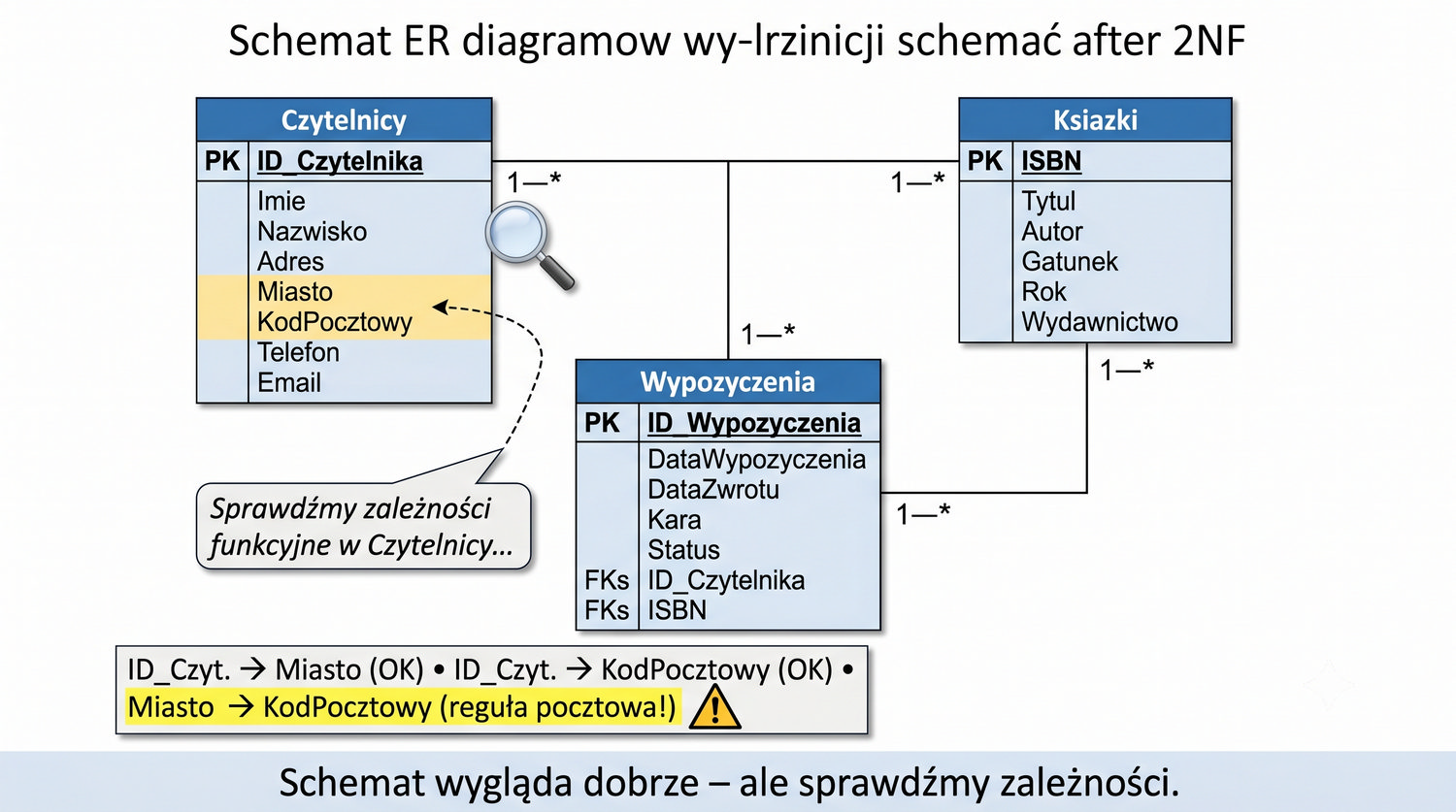
Przypomnienie stanu po 2NF jest dobrym punktem wyjścia do zrozumienia, dlaczego 3NF jest potrzebna. Po zakończeniu drugiego etapu normalizacji nasza baza danych składa się z trzech tabel: Czytelnicy (z danymi osobowymi czytelników), Ksiazki (z metadanymi książek) oraz Wypozyczenia (z informacjami o zdarzeniach wypożyczenia). Każda tabela ma swój klucz główny, a tabela Wypozyczenia zawiera klucze obce łączące ją z pozostałymi tabelami.
Dzięki 2NF wyeliminowaliśmy redundancję danych czytelnika i książki oraz wszystkie trzy rodzaje anomalii (INSERT, UPDATE, DELETE) związane z przechowywaniem różnych encji w jednej tabeli. Operacje na danych stały się prostsze i bezpieczniejsze – zmiana adresu czytelnika wymaga aktualizacji tylko jednego wiersza, a dodanie nowej książki jest możliwe bez jednoczesnego wypożyczenia.
Mimo tych udoskonaleń, w tabeli Czytelnicy wciąż istnieje subtelny problem: zależność przechodnia między miastem a kodem pocztowym. Kod pocztowy jest atrybutem miasta, a nie czytelnika, ale w obecnej strukturze jest przechowywany jako atrybut czytelnika. To może prowadzić do niespójności – na przykład dwóch czytelników z Krakowa może mieć różne kody pocztowe, co jest błędem logicznym, którego baza danych nie wychwyci.
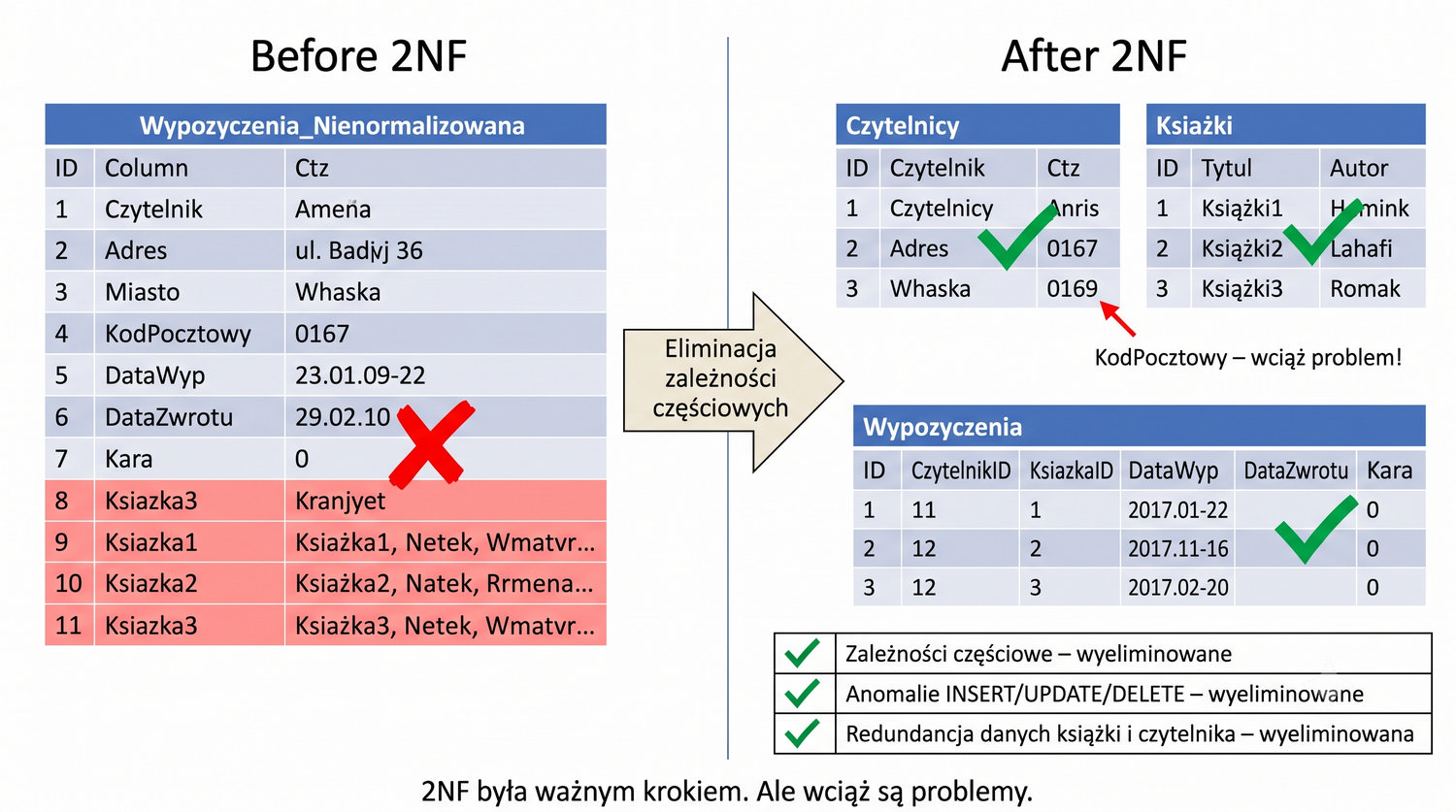
Tabela Czytelnicy po 2NF zawiera sześć kolumn: ID_Czytelnika jako klucz główny oraz Adres, Miasto, KodPocztowy, Telefon, Email jako atrybuty opisujące czytelnika. Na pierwszy rzut oka struktura wydaje się poprawna – każda encja (czytelnik) ma swoją tabelę, a wszystkie atrybuty są atomowe. Jednak przy bliższej analizie dostrzegamy problem: kod pocztowy nie jest bezpośrednią cechą czytelnika.
W rzeczywistości kod pocztowy jest cechą miasta, a nie konkretnej osoby. W systemie pocztowym to miasto (a konkretnie ulica w mieście) ma przypisany kod pocztowy. Czytelnik mieszka w danym mieście, które ma określony kod pocztowy, ale kod ten nie zależy od czytelnika – zależy od miasta. Jeśli dwóch czytelników mieszka w tym samym mieście, powinni mieć ten sam kod pocztowy, co nie jest wymuszane przez obecną strukturę.
Ta pozornie drobna niedoskonałość może prowadzić do realnych problemów w systemie. Jeśli pracownik biblioteki ręcznie wpisze kod pocztowy "00-001" dla czytelnika z Krakowa (poprawny kod dla Krakowa to "30-001"), system nie zgłosi błędu. Dopiero przy generowaniu raportów pocztowych okaże się, że przesyłki do tego czytelnika będą kierowane do Warszawy. Eliminacja takiego ryzyka jest właśnie celem 3NF.
| ID | Imię | Miasto | Kod |
|---|---|---|---|
| 1 | Jan Kowalski | Kraków | 30-001 |
| 2 | Anna Nowak | Warszawa | 00-002 |
| 3 | Piotr Wiśniewski | Gdańsk | 80-003 |
Czy widzisz problem? Kraków i 30-001 się powtarzają...
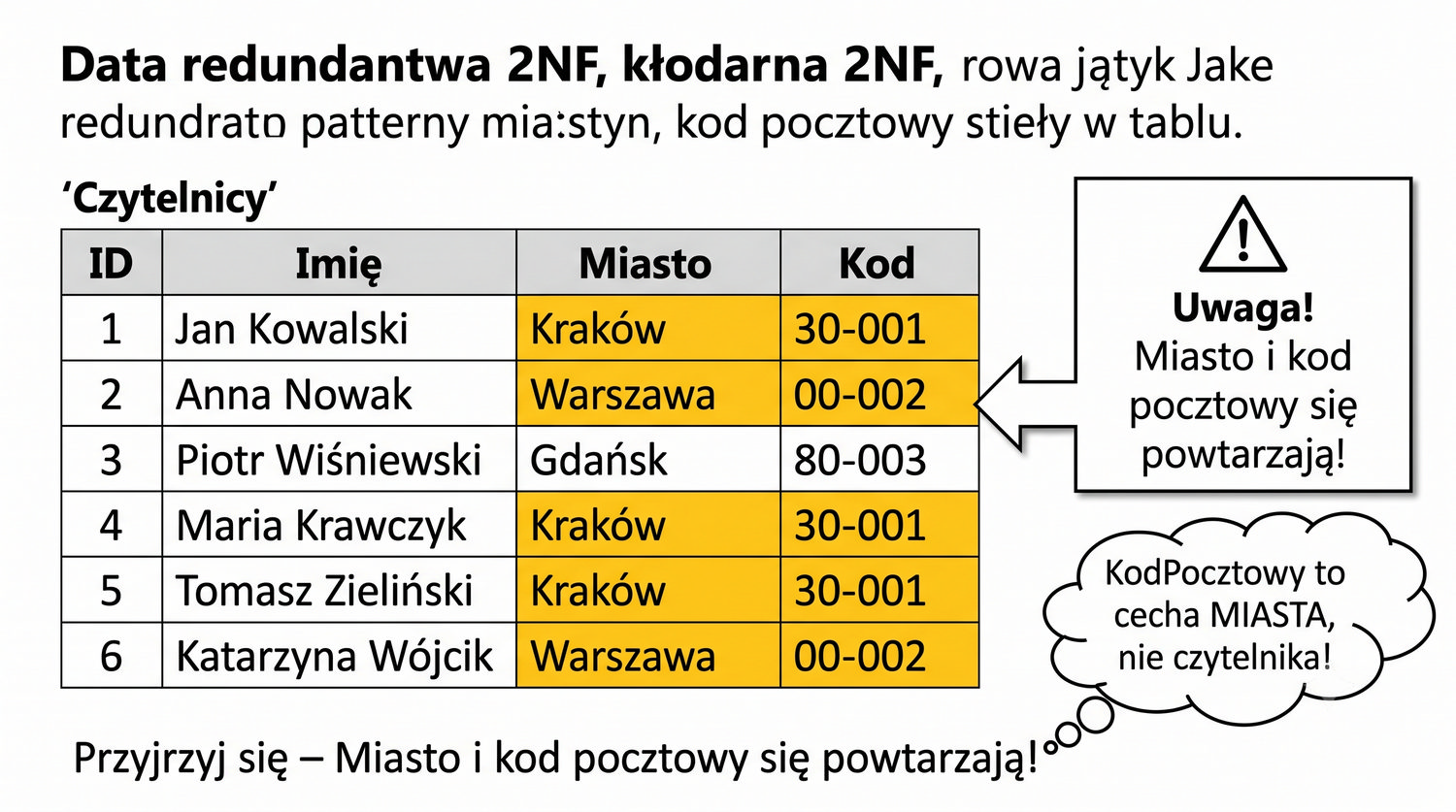
Analiza przykładowych danych w tabeli Czytelnicy unaocznia problem, który na pierwszy rzut oka może być trudny do zauważenia. Kod pocztowy 30-001 pojawia się dla wszystkich czytelników z Krakowa, a 00-002 dla wszystkich z Warszawy. To nie jest przypadek – kod pocztowy jest cechą miasta, a nie indywidualnego czytelnika. Przechowując go w tabeli Czytelnicy, tworzymy sztuczną redundancję, która będzie narastać wraz z liczbą czytelników.
W systemie bibliotecznym z tysiącem czytelników w Krakowie, kod "30-001" pojawi się tysiąc razy w tabeli Czytelnicy. Jeśli kod pocztowy dla Krakowa ulegnie zmianie (co zdarza się przy reformach administracyjnych), konieczna będzie aktualizacja wszystkich tysiąca wierszy. Jest to nie tylko czasochłonne, ale przede wszystkim ryzykowne – łatwo pominąć któryś z wierszy, wprowadzając niespójność w danych.
Rozwiązaniem jest przeniesienie kodu pocztowego do osobnej tabeli Miasta, gdzie każda para (Miasto, KodPocztowy) występuje dokładnie jeden raz. W tabeli Czytelnicy pozostaje tylko ID_Miasta jako klucz obcy, co eliminuje redundancję i ryzyko niespójności. To jest właśnie istota trzeciej postaci normalnej – usunięcie zależności przechodnich poprzez wydzielenie atrybutów, które nie są bezpośrednio zależne od klucza głównego.
| ISBN | Tytuł | Autor | Gatunek |
|---|---|---|---|
| 978-83-123-4567-1 | Przedwiośnie | Żeromski | Powieść |
| 978-83-123-4567-2 | Lalka | Prus | Powieść |
Gatunek to VARCHAR – brak zależności przechodnich.
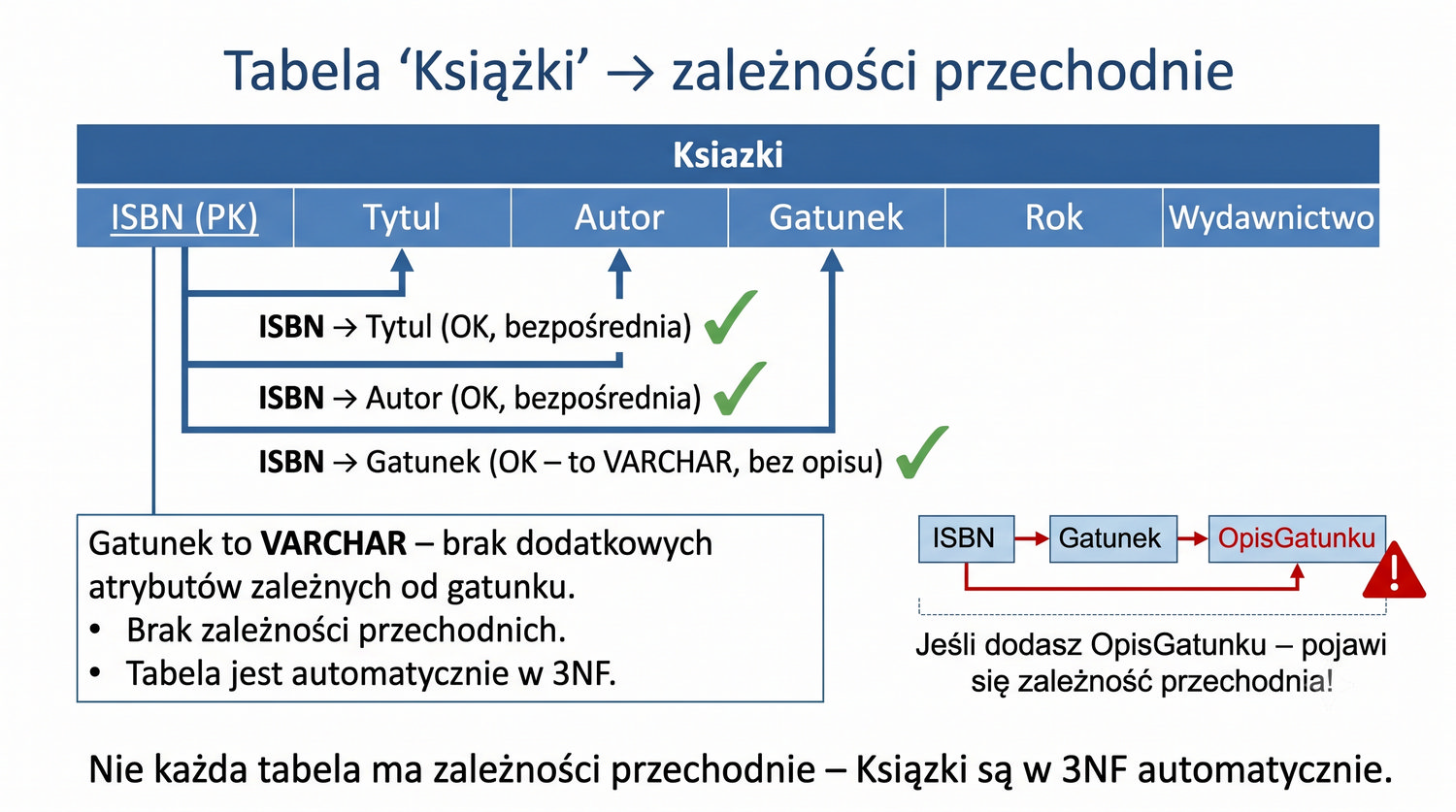
Inny przykład zależności przechodniej, który może wystąpić w naszej bazie, dotyczy gatunku książki. W tabeli Ksiazki mamy kolumnę Gatunek przechowującą nazwę gatunku literackiego. Jeśli dodalibyśmy kolumnę OpisGatunku z opisem danego gatunku, pojawiłaby się zależność przechodnia: ID_Ksiazki → Gatunek → OpisGatunku. Opis gatunku zależałby od gatunku, a nie bezpośrednio od ID_Ksiazki.
Konsekwencje byłyby takie same jak dla kodu pocztowego: redundancja opisu gatunku dla wszystkich książek tego samego gatunku oraz ryzyko niespójności. Jeśli dla dwóch książek z gatunkiem "Powieść" opis zostałby wprowadzony w różnych wersjach, nie wiadomo byłoby, która wersja jest poprawna. Rozwiązaniem jest utworzenie osobnej tabeli Gatunki z atrybutami (NazwaGatunku, Opis) i odwołanie się do niej z tabeli Ksiazki za pomocą klucza obcego.
W naszym przykładzie bibliotecznym na szczęście nie mamy kolumny z opisem gatunku, więc ten problem nas nie dotyczy. Jednak w rzeczywistych systemach takie sytuacje są bardzo częste – projektanci często dodają do tabel atrybuty opisowe, które są zależne od innych atrybutów niebędących kluczami, nieświadomie wprowadzając zależności przechodnie, które w dłuższej perspektywie prowadzą do problemów z integralnością danych.
Analiza przykładowych danych w tabeli Czytelnicy ujawnia problem, który na pierwszy rzut oka może być niewidoczny. Spójrzmy na dane: Jan Kowalski mieszka w Krakowie, kod pocztowy 30-001. Anna Nowak mieszka w Warszawie, kod 00-002. Piotr Wiśniewski w Gdańsku, kod 80-003. Wszystko wydaje się poprawne – każdy czytelnik ma miasto i kod pocztowy, które logicznie do siebie pasują.
Problem polega na tym, że baza danych nie ma wiedzy o tym, które kody pocztowe pasują do których miast. Gdyby pracownik biblioteki wprowadził nowego czytelnika z Krakowem i kodem "00-002" (warszawskim), baza danych nie zgłosiłaby błędu. Dopiero przy próbie wysłania korespondencji okazałoby się, że adres jest nieprawidłowy. To klasyczny przykład ukrytego problemu integralności danych, który 3NF ma na celu wyeliminować.
W systemach produkcyjnych, gdzie dane są wprowadzane przez wielu pracowników w różnym czasie, ryzyko takich błędów jest znaczne. Każdy pracownik może mieć inną wiedzę o kodach pocztowych lub po prostu popełnić literówkę. 3NF chroni przed tymi błędami poprzez scentralizowanie danych o miastach i kodach pocztowych w osobnej tabeli, gdzie są one przechowywane raz i walidowane przy wprowadzaniu.
ID_Czytelnika → Miasto → KodPocztowy – zależność przechodnia!
To stwierdzenie – "30-001 to kod Krakowa, nie kod Jana Kowalskiego" – doskonale oddaje sedno problemu, który rozwiązuje 3NF. Kod pocztowy 30-001 jest przypisany do miasta Kraków, a nie do konkretnej osoby. Jan Kowalski tylko mieszka w Krakowie, więc pośrednio korzysta z tego kodu pocztowego. Przechowywanie kodu pocztowego jako atrybutu czytelnika jest więc błędem semantycznym w modelowaniu danych.
W projektowaniu baz danych kluczową zasadą jest, że każdy atrybut powinien być przechowywany w tabeli encji, której bezpośrednio dotyczy. Kod pocztowy dotyczy miasta – to miasto ma kod pocztowy. Czytelnik ma adres zamieszkania, który zawiera nazwę miasta, ale sam kod pocztowy nie jest cechą czytelnika. To subtelne, ale ważne rozróżnienie, które ma istotne konsekwencje dla integralności danych.
W praktyce, gdy projektujemy bazę danych, powinniśmy zawsze zadawać sobie pytanie: "Czy ten atrybut rzeczywiście zależy bezpośrednio od klucza głównego tej tabeli?" Jeśli nie, powinien zostać przeniesiony do innej tabeli. To właśnie ta zasada – każdy atrybut niekluczowy musi zależeć wyłącznie od klucza głównego i to w sposób bezpośredni, a nie przez pośrednictwo innych atrybutów – stanowi istotę trzeciej postaci normalnej.
Warunek: B nie jest kluczem kandydującym. Przykład: ID_Czyt. → Miasto → KodPocztowy.
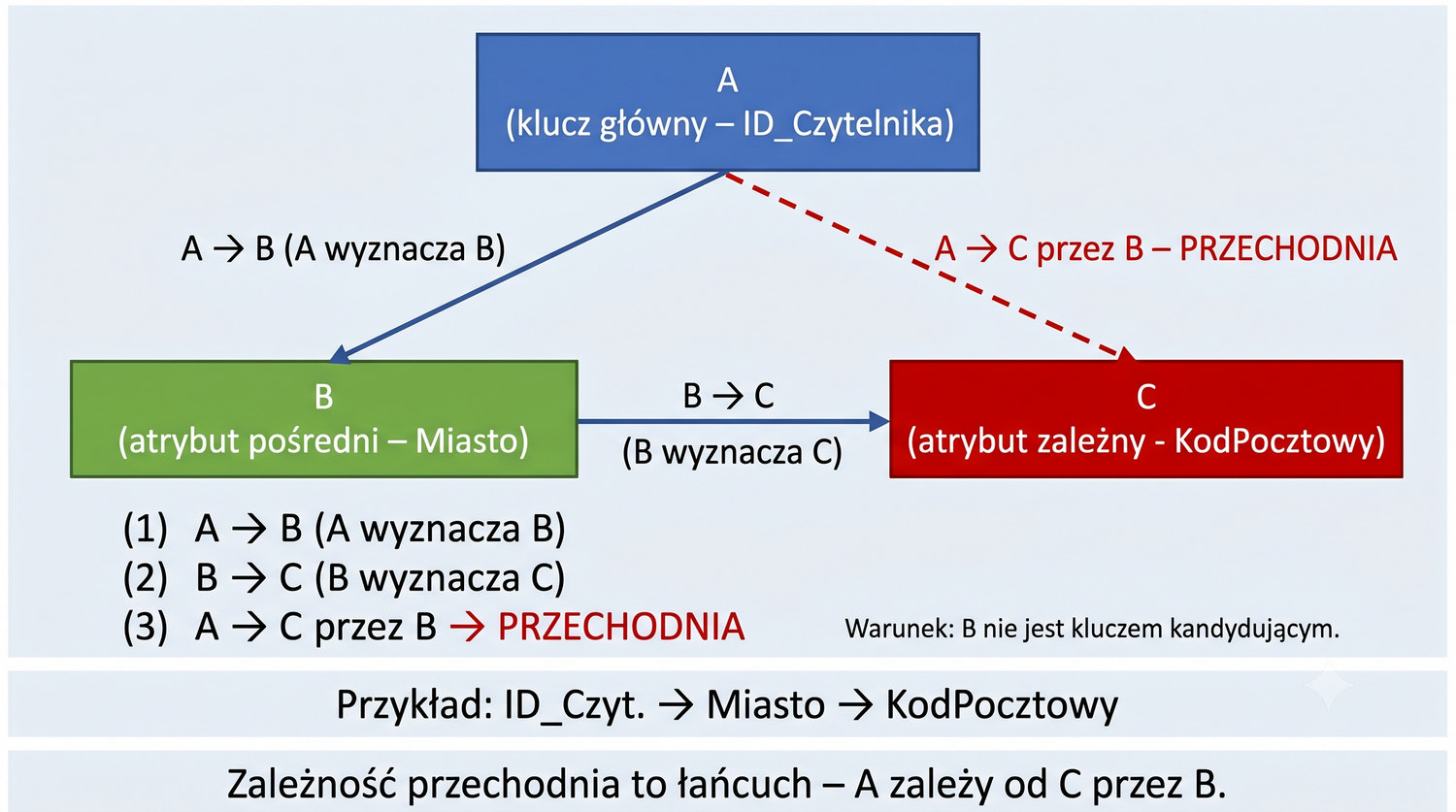
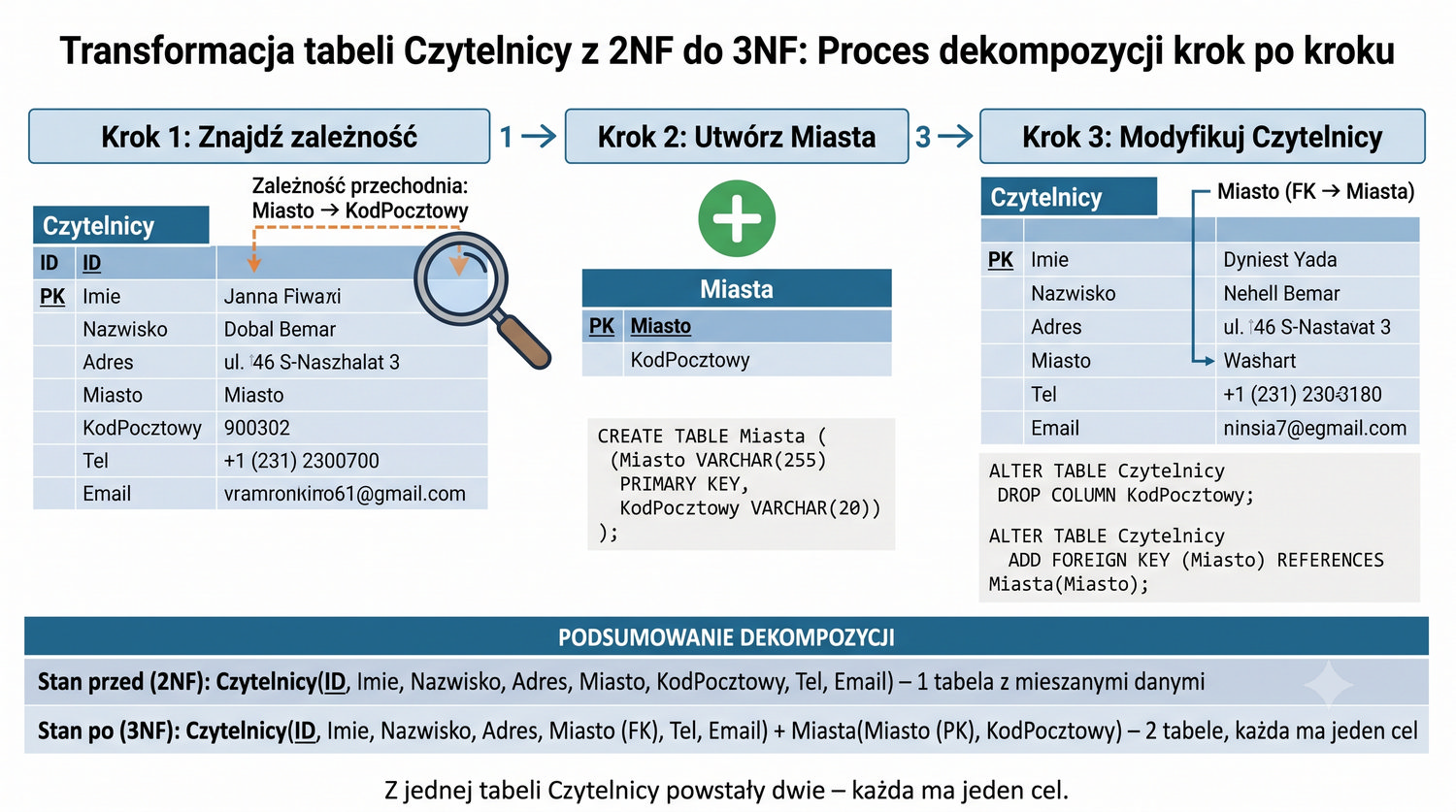
W kontekście normalizacji zależność przechodnia oznacza, że atrybut niebędący kluczem (A) zależy od innego atrybutu niebędącego kluczem (B), który z kolei zależy od klucza głównego (K). Formalnie: jeśli K → B i B → A, to K → A jest zależnością przechodnią. W naszej tabeli Czytelnicy: ID_Czytelnika → Miasto → KodPocztowy. Kod pocztowy zależy od miasta, a miasto od ID_Czytelnika.
Definicja 3NF mówi, że relacja jest w 3NF, jeśli jest w 2NF i żaden atrybut niekluczowy nie jest przechodnio zależny od klucza głównego. Innymi słowy, każdy atrybut niekluczowy musi zależeć wyłącznie od klucza głównego, i to w sposób bezpośredni. W praktyce oznacza to, że jeśli mamy łańcuch zależności K → B → A, to atrybut A powinien zostać przeniesiony do osobnej tabeli wraz z atrybutem B.
W naszym przykładzie tworzymy tabelę Miasta z atrybutami (ID_Miasta, Miasto, KodPocztowy), gdzie każda para (Miasto, KodPocztowy) występuje dokładnie raz. W tabeli Czytelnicy pozostaje ID_Miasta jako klucz obcy. Dzięki temu łańcuch zależności zostaje przerwany: ID_Miasta → KodPocztowy (bezpośrednio) i ID_Czytelnika → ID_Miasta (bezpośrednio), ale nie ma już zależności ID_Czytelnika → Miasto → KodPocztowy.
(ID_Prac, Imie, ID_Dzialu, NazwaDzialu, BudzetDzialu)
50 prac. w IT = 50×'IT'. Zmiana budżetu = UPDATE 50 wierszy.
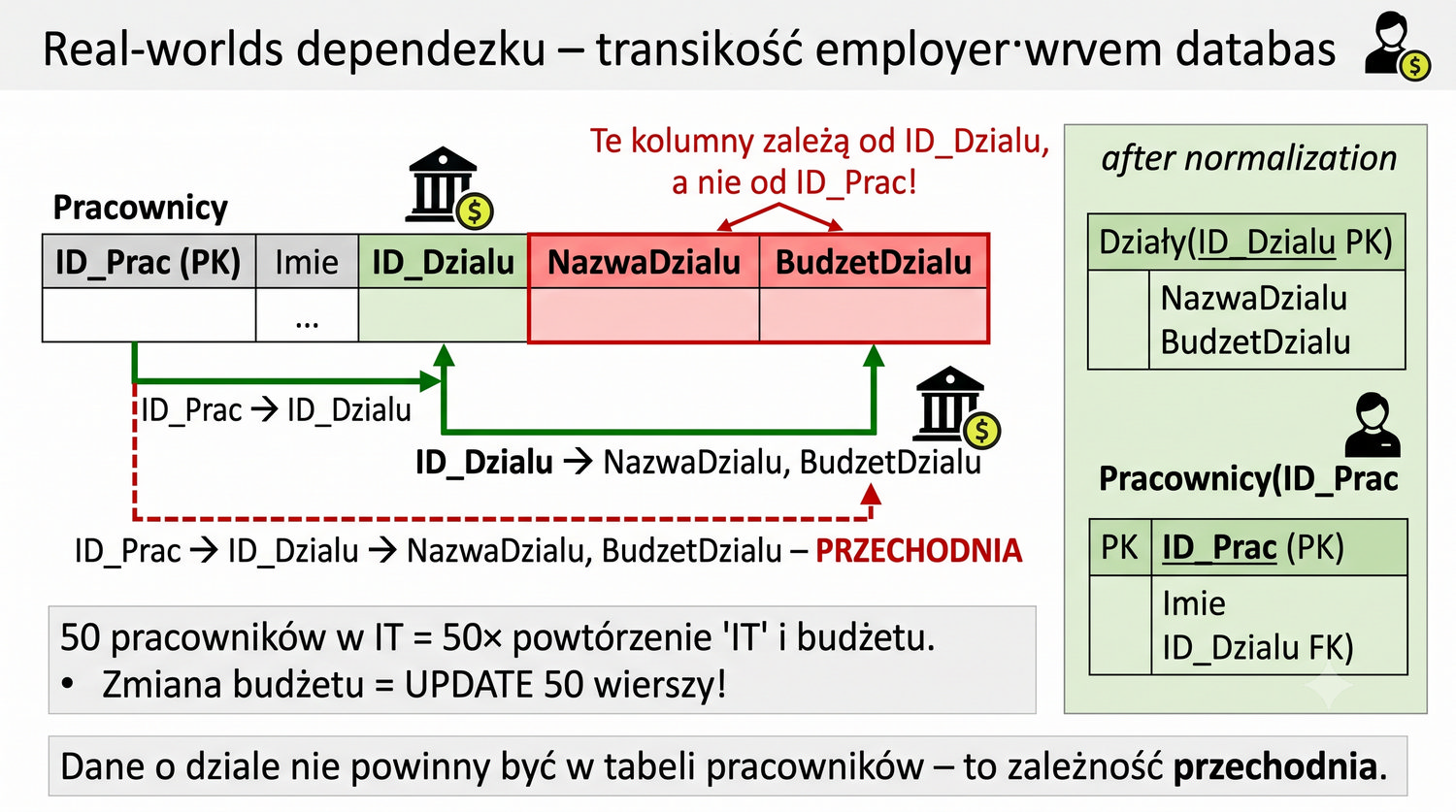
Przykład z działami pracowników ilustruje kolejny scenariusz, w którym 3NF rozwiązuje realny problem. Jeśli w tabeli Pracownicy przechowujemy kolumny ID_Dzialu i NazwaDzialu, to NazwaDzialu zależy od ID_Dzialu, a nie od ID_Pracownika. Jeśli dział zmieni nazwę, konieczna będzie aktualizacja wszystkich pracowników w tym dziale. Rozwiązaniem jest utworzenie osobnej tabeli Dzialy z atrybutami (ID_Dzialu, NazwaDzialu).
Po wydzieleniu tabeli Dzialy, zmiana nazwy działu wymaga aktualizacji dokładnie jednego wiersza. Wszyscy pracownicy automatycznie "widzą" nową nazwę poprzez relację klucza obcego. To ten sam wzorzec, który zastosowaliśmy dla kodu pocztowego – uniezależnienie atrybutu opisu od encji nadrzędnej i przeniesienie go do osobnej tabeli.
W praktyce biznesowej taki problem występuje bardzo często. Systemy kadrowe, magazynowe, sprzedażowe – wszystkie mają encje, które mają atrybuty opisowe zależne od innych encji. 3NF dostarcza uniwersalnego wzorca postępowania: jeśli atrybut niekluczowy zależy od innego atrybutu niekluczowego, należy utworzyć osobną tabelę dla tych atrybutów i połączyć ją kluczem obcym z tabelą główną.
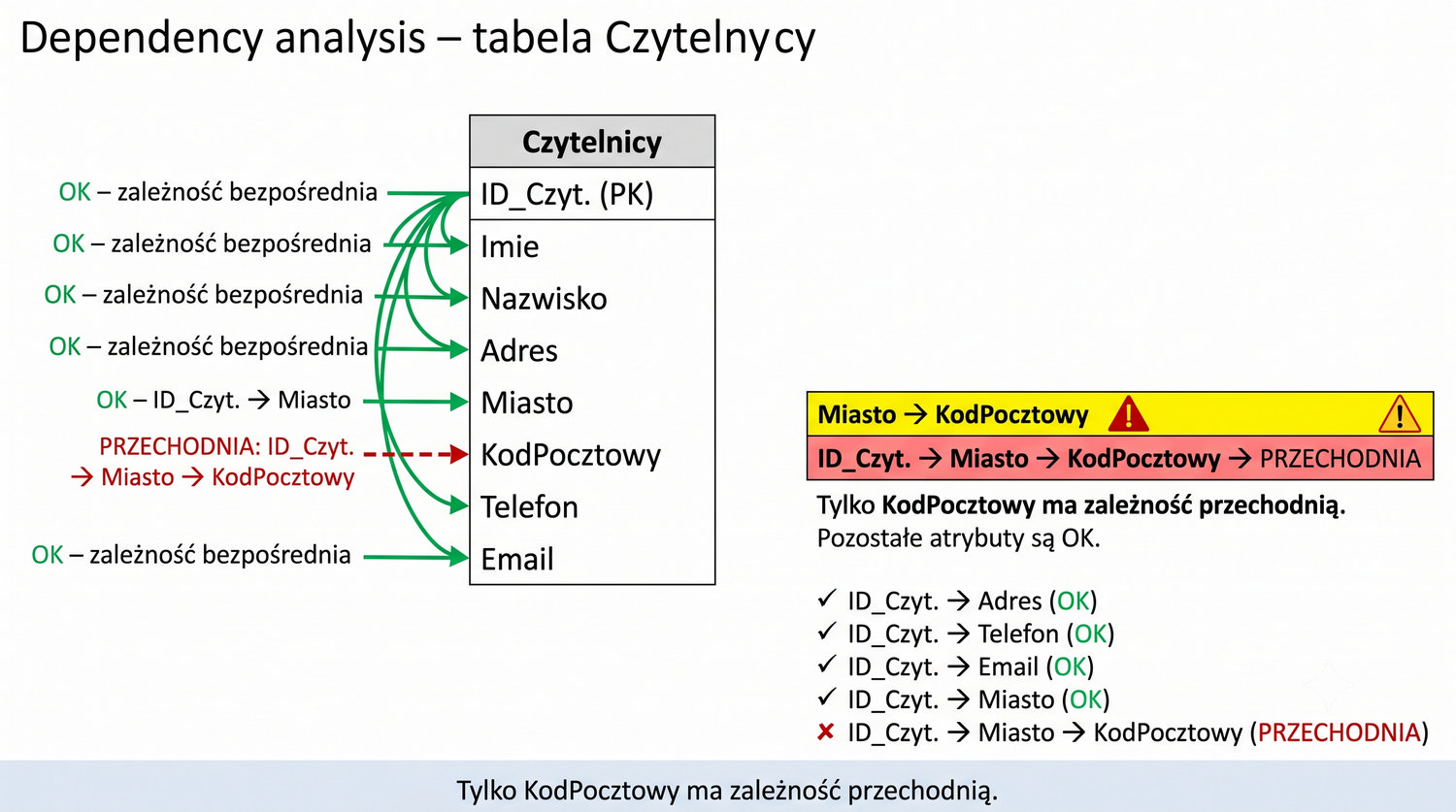
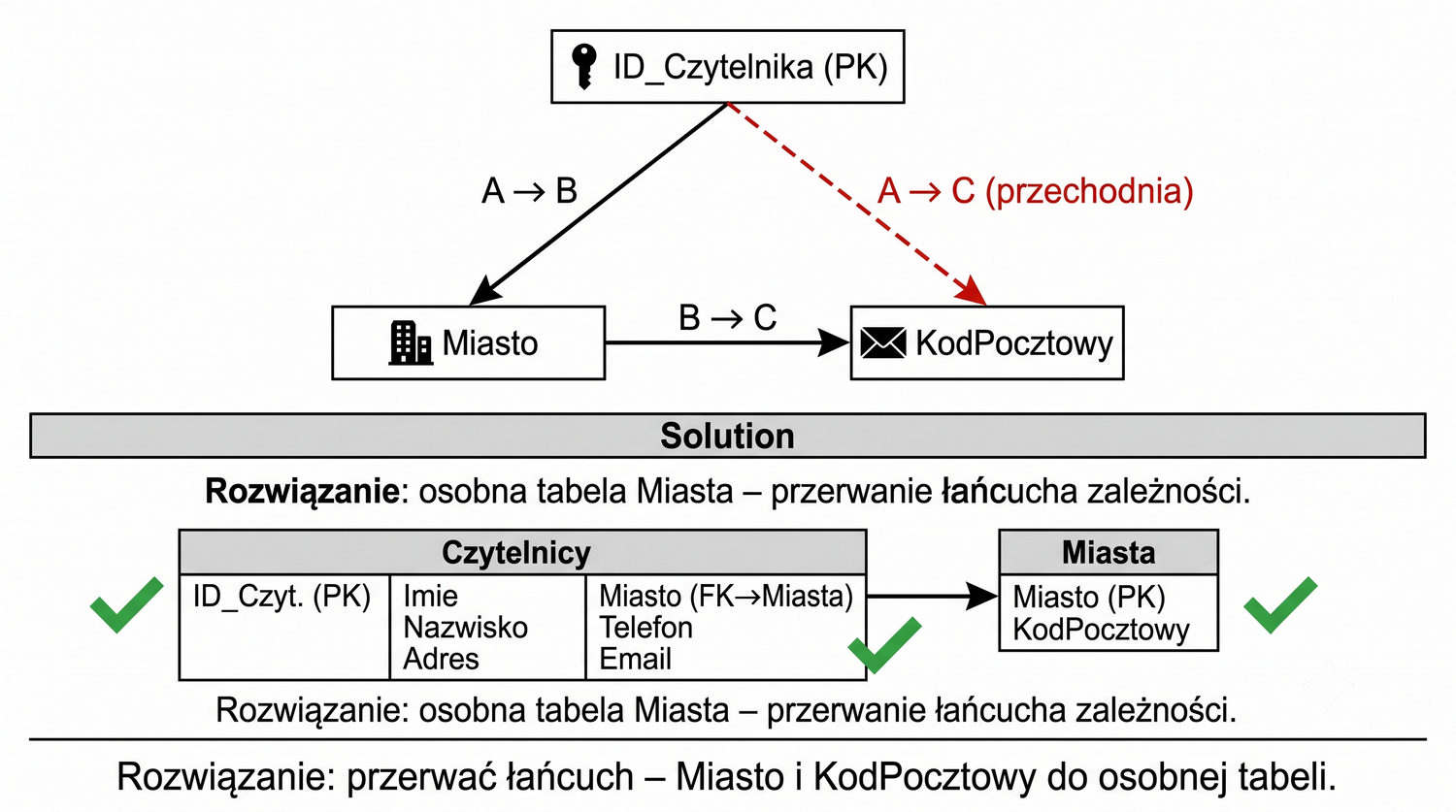
Wizualizacja graficzna zależności przechodniej w tabeli Czytelnicy pomaga zrozumieć, jak atrybuty są ze sobą powiązane. Strzałka od ID_Czytelnika do Miasto reprezentuje zależność funkcyjną: ID_Czytelnika → Miasto. Strzałka od Miasto do KodPocztowy reprezentuje zależność: Miasto → KodPocztowy. KodPocztowy "wisi" na Mieście, a nie na ID_Czytelnika – to klasyczny przykład zależności przechodniej.
W dobrze zaprojektowanej bazie danych wszystkie strzałki powinny wychodzić wyłącznie od klucza głównego. Każda strzałka, która łączy dwa atrybuty niebędące kluczami, jest potencjalnym źródłem problemów. W naszym przypadku strzałka od Miasto do KodPocztowy łączy dwa atrybuty niekluczowe, co narusza zasadę 3NF i może prowadzić do niespójności danych.
Rozwiązaniem jest przerwanie łańcucha zależności poprzez utworzenie tabeli Miasta. W nowej strukturze strzałki wyglądają następująco: ID_Miasta → Miasto, ID_Miasta → KodPocztowy (obie od klucza głównego) oraz ID_Czytelnika → ID_Miasta (klucz obcy do tabeli Miasta). Nie ma już strzałek łączących atrybuty niekluczowe, co oznacza, że tabela Czytelnicy (po modyfikacji) jest w 3NF.
Ksiazki nie mają zależności przechodnich – są w 3NF.
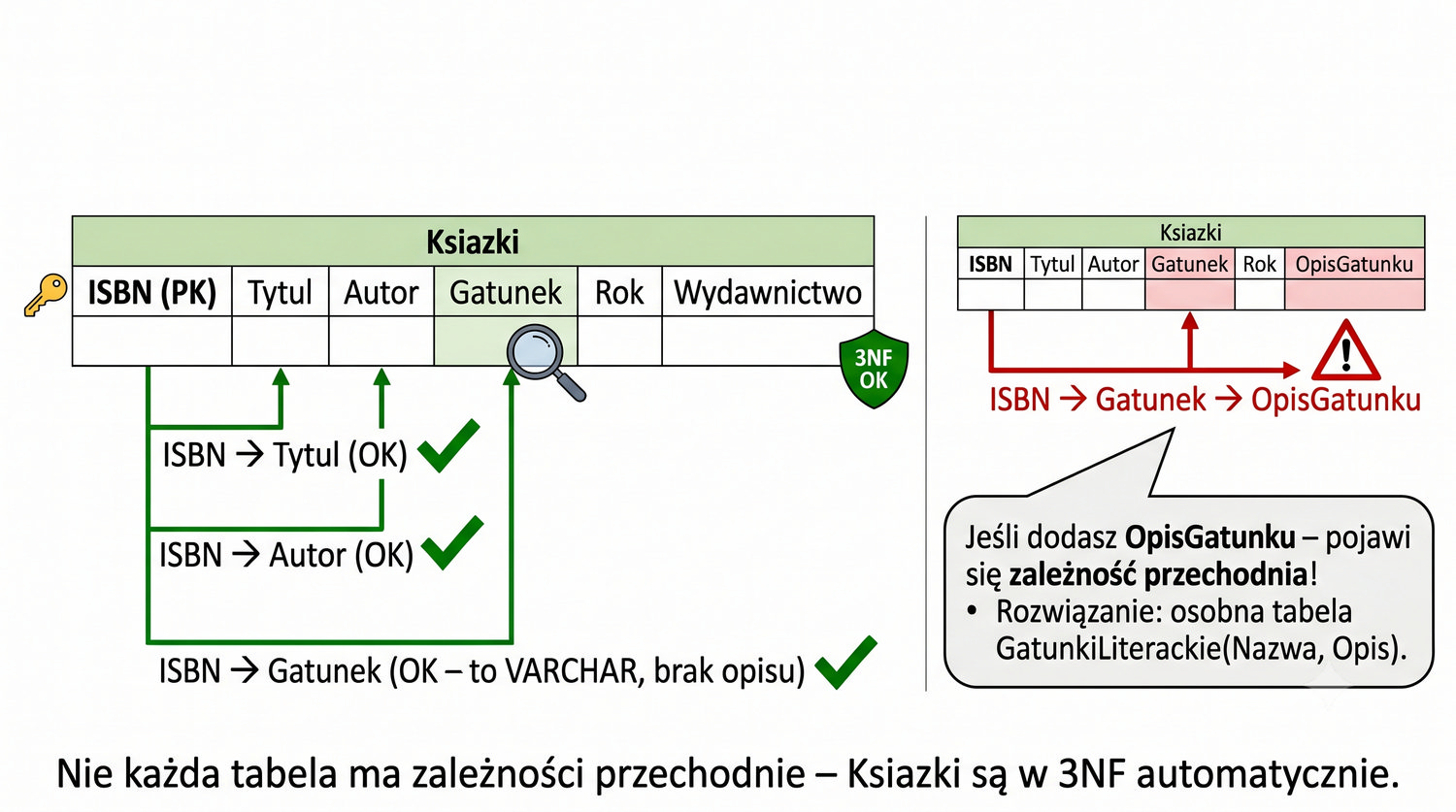
Analiza potencjalnych zależności przechodnich w tabeli Ksiazki pokazuje, że podobny problem mógłby wystąpić również dla gatunku książki. W obecnej strukturze tabela Ksiazki zawiera kolumnę Gatunek, która przechowuje nazwę gatunku literackiego. Jeśli w przyszłości dodalibyśmy kolumnę OpisGatunku, pojawiłaby się zależność przechodnia: ID_Ksiazki → Gatunek → OpisGatunku.
Taka sytuacja jest bardzo prawdopodobna w rzeczywistym systemie bibliotecznym. Pracownicy biblioteki mogą chcieć dodać opisy gatunków, aby ułatwić czytelnikom wybór książek. Gdyby opis gatunku był przechowywany w tabeli Ksiazki, każda książka z gatunkiem "Powieść" miałaby kopię tego samego opisu. Zmiana opisu wymagałaby aktualizacji wszystkich książek danego gatunku.
Rozwiązaniem jest profilaktyczne utworzenie tabeli GatunkiLiterackie z atrybutami (NazwaGatunku, Opis), jeszcze zanim problem się pojawi. W tabeli Ksiazki przechowujemy NazwaGatunku jako klucz obcy, co eliminuje redundancję i ryzyko niespójności. To dobra praktyka projektowa – przewidywanie przyszłych potrzeb i modelowanie danych w sposób, który zapobiega problemom, zanim one wystąpią.
Wypozyczenia – brak zależności przechodnich.
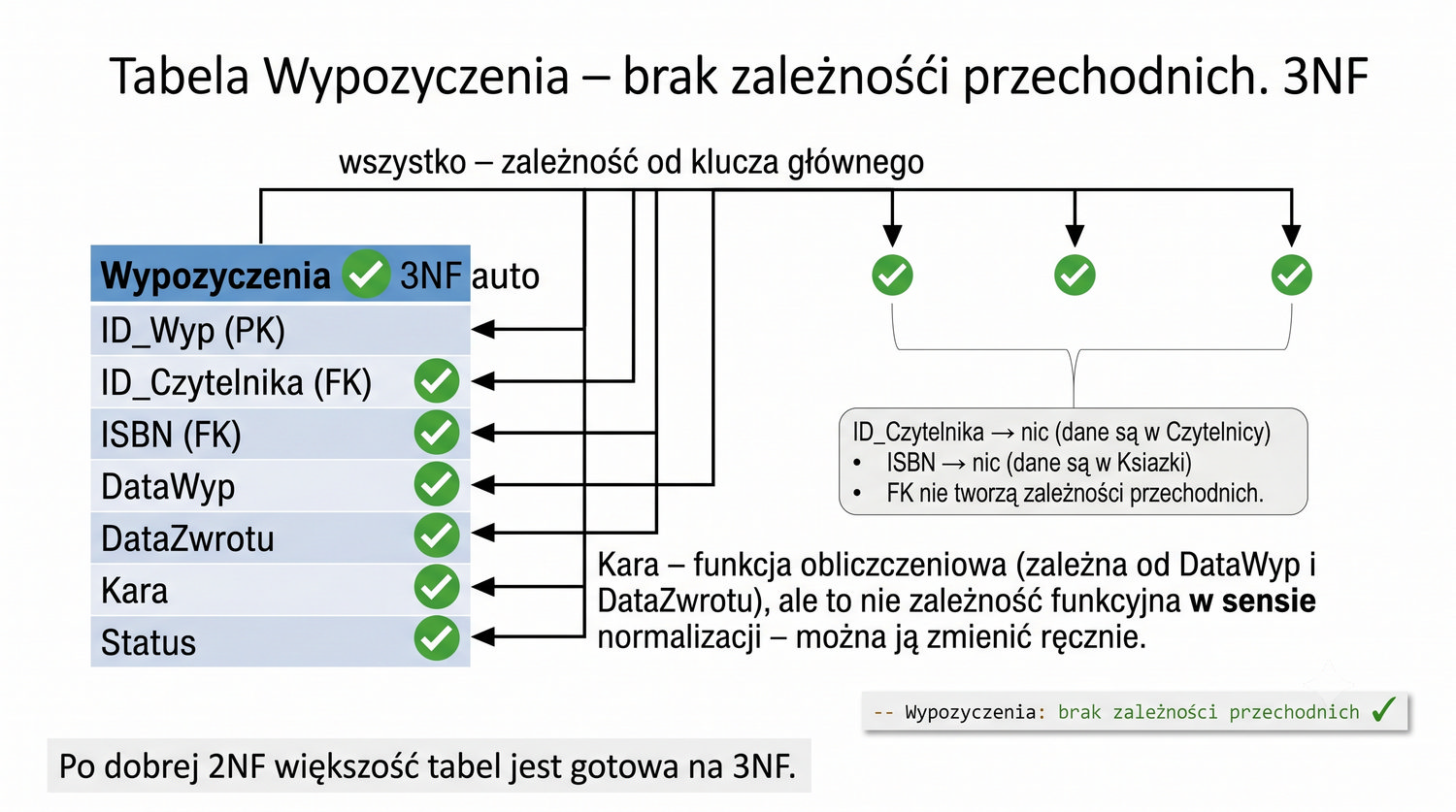
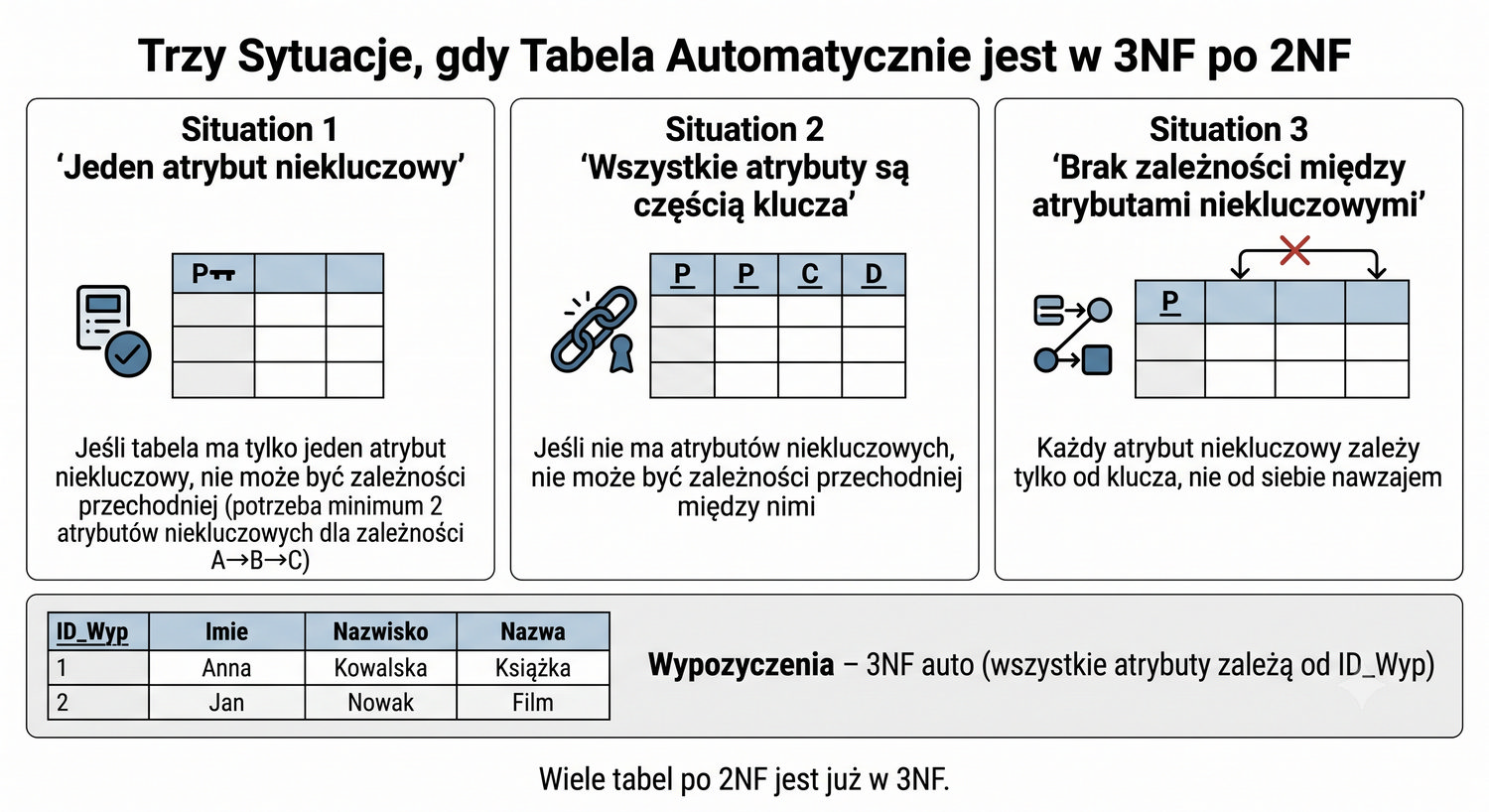
W tabeli Wypozyczenia po 2NF mamy kolumnę Kara, która na pierwszy rzut oka może wydawać się zależna od atrybutów DataWyp i DataZwrotu. W rzeczywistości kara jest funkcją obliczaną na podstawie różnicy między datą zwrotu a datą wypożyczenia, a nie zależnością funkcyjną w sensie normalizacji. To ważne rozróżnienie: funkcja obliczeniowa to nie to samo co zależność funkcyjna.
Zależność funkcyjna oznacza, że dana wartość atrybutu jest jednoznacznie określona przez wartość innego atrybutu w całej tabeli. Funkcja obliczeniowa oznacza, że wartość jest wyliczana na podstawie innych wartości, ale może być również zmieniona ręcznie (np. jeśli bibliotekarz zdecyduje się darować karę). W naszym przypadku kara może być zarówno wyliczona, jak i nadpisana ręcznie, więc nie jest to czysta zależność funkcyjna.
W praktyce kolumny obliczeniowe często przechowuje się w tabeli jako osobne atrybuty, ponieważ ich przechowywanie przyspiesza zapytania (nie trzeba za każdym razem wyliczać wartości). Jednak z punktu widzenia normalizacji, kara nie wprowadza zależności przechodniej ani częściowej, więc nie stanowi problemu dla 3NF. Decyzja o pozostawieniu kary w tabeli Wypozyczenia jest poprawna z punktu widzenia reguł normalizacji.
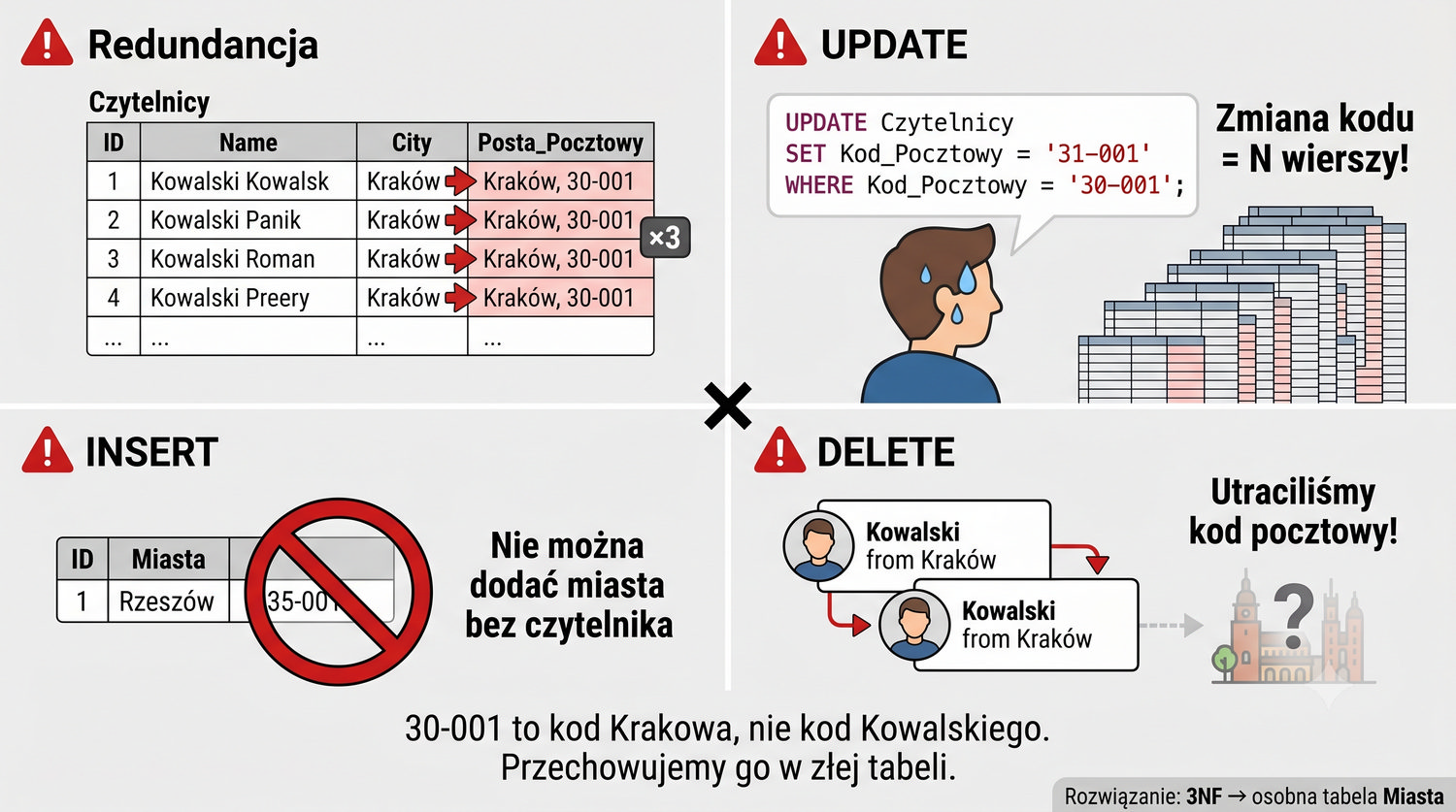
Przechowywanie kodu pocztowego w tabeli Czytelnicy generuje cztery konkretne problemy, analogiczne do tych, które występowały w 1NF. Po pierwsze, redundancja – kod pocztowy Krakowa powtarza się dla każdego czytelnika z Krakowa. Po drugie, anomalia UPDATE – zmiana kodu pocztowego dla miasta wymaga aktualizacji wszystkich czytelników w tym mieście. Po trzecie, anomalia INSERT – nie można dodać nowego miasta z kodem pocztowym, dopóki nie ma w nim czytelnika.
Po czwarte, anomalia DELETE – jeśli ostatni czytelnik z danego miasta zostanie usunięty, tracimy informację o kodzie pocztowym dla tego miasta. Te problemy są identyczne w swojej strukturze z tymi, które eliminowaliśmy w 2NF, ale dotyczą teraz relacji między miastem a kodem pocztowym, a nie między czytelnikiem a wypożyczeniem. To pokazuje, że normalizacja jest procesem iteracyjnym – te same wzorce problemów pojawiają się na różnych poziomach abstrakcji.
Wszystkie te problemy znikają po wydzieleniu tabeli Miasta, w której każda para (Miasto, KodPocztowy) występuje dokładnie raz. W tabeli Czytelnicy przechowujemy ID_Miasta jako klucz obcy, co eliminuje redundancję i wszystkie trzy anomalie. Zmiana kodu pocztowego dla Krakowa wymaga teraz aktualizacji jednego wiersza w tabeli Miasta, a dodanie nowego miasta z kodem pocztowym jest możliwe bez istnienia czytelnika w tym mieście.
Rozwiązanie: osobna tabela Miasta.
Metafora hydrauliczna pomaga zrozumieć naturę zależności przechodniej. Wyobraźmy sobie system wodociągowy, w którym woda (dane) płynie ze źródła (klucz główny) do odbiorców (atrybuty). W normalnej sytuacji woda płynie jedną rurą bezpośrednio ze źródła do każdego odbiorcy – to jest zależność bezpośrednia od klucza głównego. W przypadku zależności przechodniej woda płynie dwoma rurami: najpierw ze źródła do pośrednika, a potem z pośrednika do odbiorcy.
W naszej tabeli Czytelnicy mamy: ID_Czytelnika (źródło) → Miasto (pośrednik) → KodPocztowy (odbiorca). Kod pocztowy otrzymuje dane nie bezpośrednio od źródła (ID_Czytelnika), ale przez pośrednika (Miasto). To sprawia, że zmiana w źródle (ID_Czytelnika) może nie dotrzeć do odbiorcy (KodPocztowy), jeśli zmiana dotyczy tylko pośrednika. Na przykład, gdy czytelnik się przeprowadza, zmieniamy Miasto, ale KodPocztowy może nie zostać zaktualizowany.
Metafora ta unaocznia, dlaczego zależności przechodnie są niebezpieczne – tworzą one niejawne powiązania między atrybutami, które mogą prowadzić do niespójności, gdy dane są aktualizowane. Prawidłowo zaprojektowana baza danych (w 3NF) ma strukturę gwiazdy: każde źródło (klucz główny) łączy się bezpośrednio ze swoimi odbiorcami (atrybutami) bez pośredników, co eliminuje ryzyko utraty synchronizacji danych.
Książka: Jan Kowalski, Kraków, 30-001
Słownik: Kraków → 30-001
W książce masz tylko miasto. Kod sprawdzasz w słowniku. To 3NF!

Stwierdzenie "Kod pocztowy nie jest przepisywany przy każdej osobie" odnosi się do praktyki ręcznego przepisywania danych w systemach papierowych, ale ma głębokie znaczenie w kontekście normalizacji. W tradycyjnej, papierowej ewidencji, kod pocztowy był przepisywany dla każdego czytelnika z osobna. Przy tysiącu czytelników w Krakowie, kod "30-001" pojawiał się tysiąc razy w kartotekach.
W systemie komputerowym ta redundancja jest nie tylko niepotrzebna, ale przede wszystkim niebezpieczna. Jeśli kod pocztowy dla Krakowa zmieni się z "30-001" na "30-100" (np. po reformie administracyjnej), konieczna będzie aktualizacja wszystkich tysiąca rekordów. Ryzyko pominięcia choćby jednego rekordu jest realne, a konsekwencje – dwóch czytelników z Krakowa z różnymi kodami pocztowymi – naruszają integralność danych.
Dlatego właśnie 3NF eliminuje tę redundancję poprzez wydzielenie tabeli Miasta, w której kod pocztowy jest przechowywany dokładnie raz dla każdego miasta. W systemie komputerowym kod pocztowy jest "przepisywany" automatycznie poprzez relację klucza obcego – każdy czytelnik z Krakowa automatycznie widzi aktualny kod pocztowy Krakowa, bez potrzeby ręcznego przepisywania go dla każdej osoby.
Każdy atrybut niekluczowy musi zależeć BEZPOŚREDNIO od klucza.
Zasada "atrybuty niekluczowe nie mogą zależeć od siebie nawzajem" jest nieformalnym, ale bardzo praktycznym sformułowaniem trzeciej postaci normalnej. Oznacza to, że w tabeli będącej w 3NF wszystkie atrybuty niebędące kluczami powinny być od siebie niezależne – każdy z nich powinien zależeć wyłącznie od klucza głównego. Jeśli atrybut A determinuje atrybut B, to A i B nie powinny znajdować się w tej samej tabeli.
W naszej tabeli Czytelnicy, atrybuty Miasto i KodPocztowy są od siebie zależne – konkretne miasto determinuje konkretny kod pocztowy. Ta zależność między dwoma atrybutami niekluczowymi narusza 3NF. Rozwiązaniem jest przeniesienie pary (Miasto, KodPocztowy) do osobnej tabeli Miasta, gdzie Miasto staje się kluczem głównym (lub częścią klucza), a KodPocztowy jest atrybutem zależnym bezpośrednio od tego klucza.
W praktyce reguła ta jest bardzo pomocna podczas projektowania baz danych. Wystarczy przeanalizować wszystkie atrybuty w tabeli i sprawdzić, czy istnieją między nimi jakiekolwiek zależności funkcyjne inne niż od klucza głównego. Jeśli tak, oznacza to, że tabela powinna zostać podzielona na dwie lub więcej tabel, aby wyeliminować te zależności. To proste narzędzie analityczne pozwala szybko zidentyfikować potencjalne problemy w projekcie bazy danych.
Dla każdej zależności X → A:
Jeśli X nie jest kluczem i A nie jest częścią klucza – naruszenie 3NF.
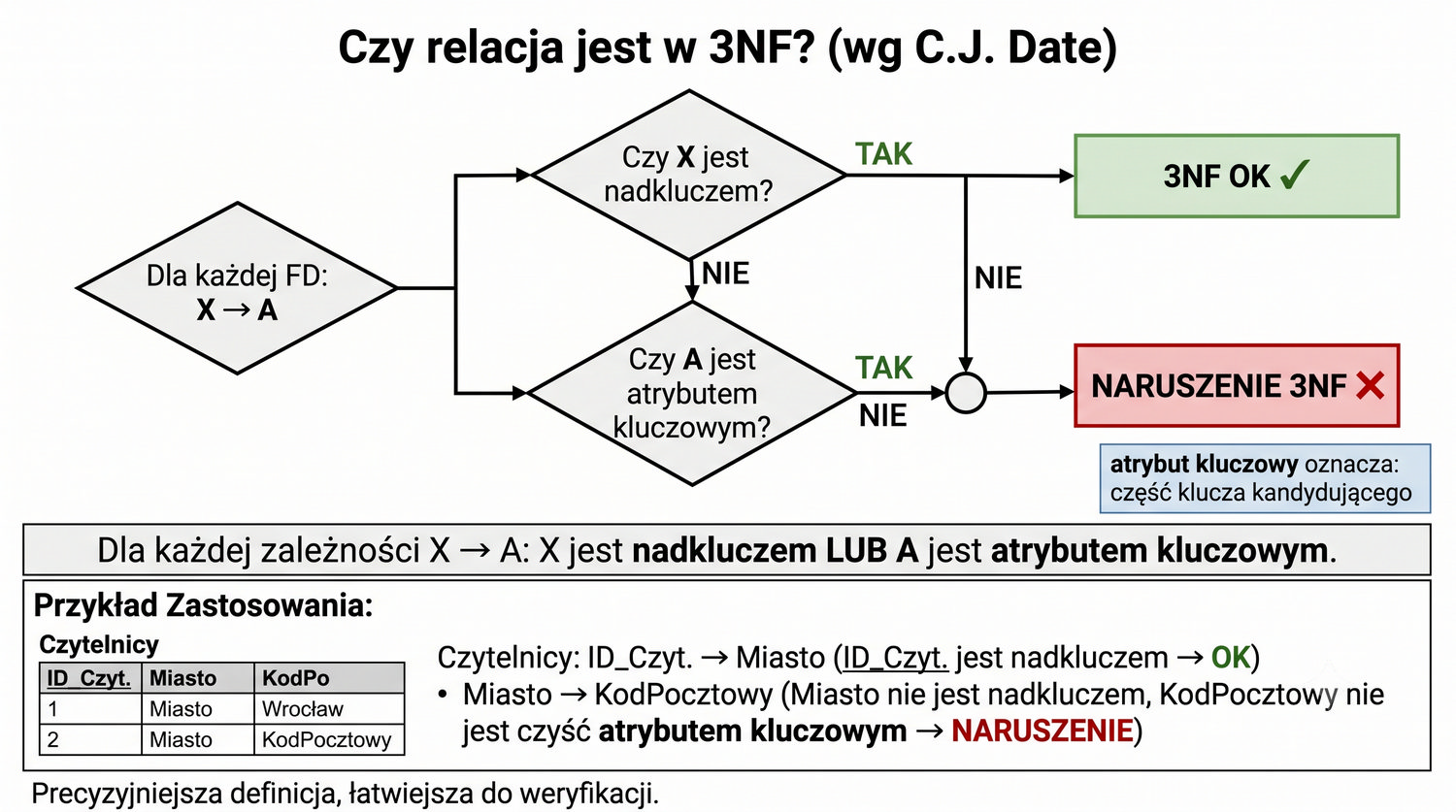
Praktyczna definicja 3NF – "każdy atrybut niekluczowy zależy wyłącznie od klucza" – jest uproszczeniem, które jednak doskonale oddaje intencję tej postaci normalnej. Pełna, formalna definicja brzmi: relacja R jest w 3NF, jeśli dla każdej zależności funkcyjnej X → A (gdzie A jest pojedynczym atrybutem) zachodzi co najmniej jeden z warunków: (1) A ∈ X (trywialna), (2) X jest nadkluczem, (3) A jest atrybutem kluczowym (należy do klucza kandydującego).
W praktyce inżynierskiej definicja "każdy atrybut niekluczowy zależy wyłącznie od klucza" jest wystarczająca w znakomitej większości przypadków. Podczas projektowania baz danych dla systemów biznesowych, rzadko spotyka się sytuacje, w których atrybut niekluczowy zależy od części klucza (to problem 2NF) lub od innego atrybutu niekluczowego (to problem 3NF). Te dwa przypadki pokrywają praktycznie wszystkie rzeczywiste problemy normalizacyjne.
Warto jednak pamiętać, że formalna definicja 3NF dopuszcza sytuację, w której atrybut niekluczowy zależy od innego atrybutu niekluczowego, pod warunkiem że ten drugi atrybut należy do klucza kandydującego. W praktyce oznacza to, że jeśli tabela ma dwa klucze kandydujące, zależność między nimi jest dozwolona. Jest to jednak przypadek rzadki i zwykle pomijany w praktycznych zastosowaniach normalizacji.
| Postać | Eliminuje | Nasza |
|---|---|---|
| 1NF | Nieatomowe + brak klucza | ✔ |
| 2NF | Zależności częściowe | ✔ |
| 3NF | Zależności przechodnie | ✘ Kod |
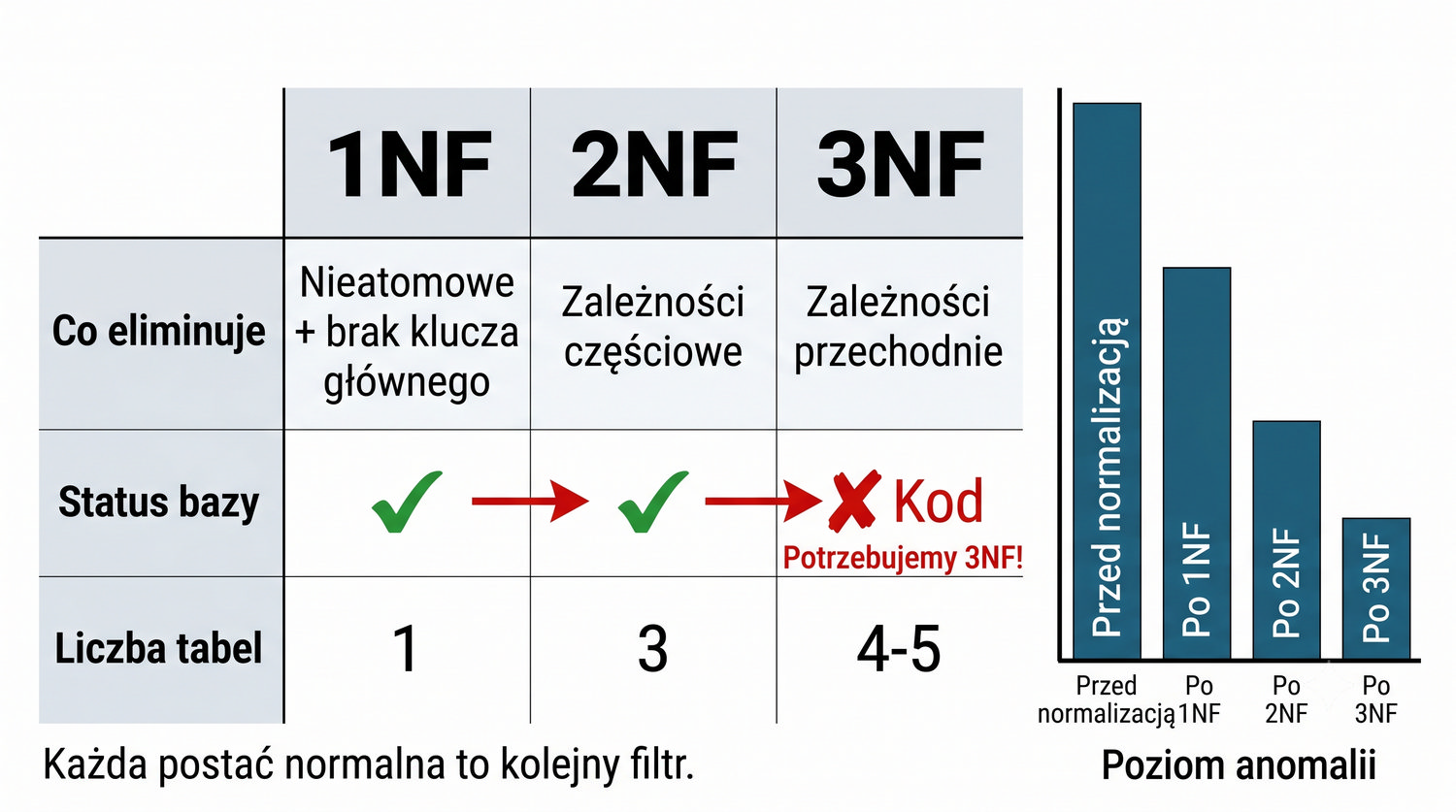
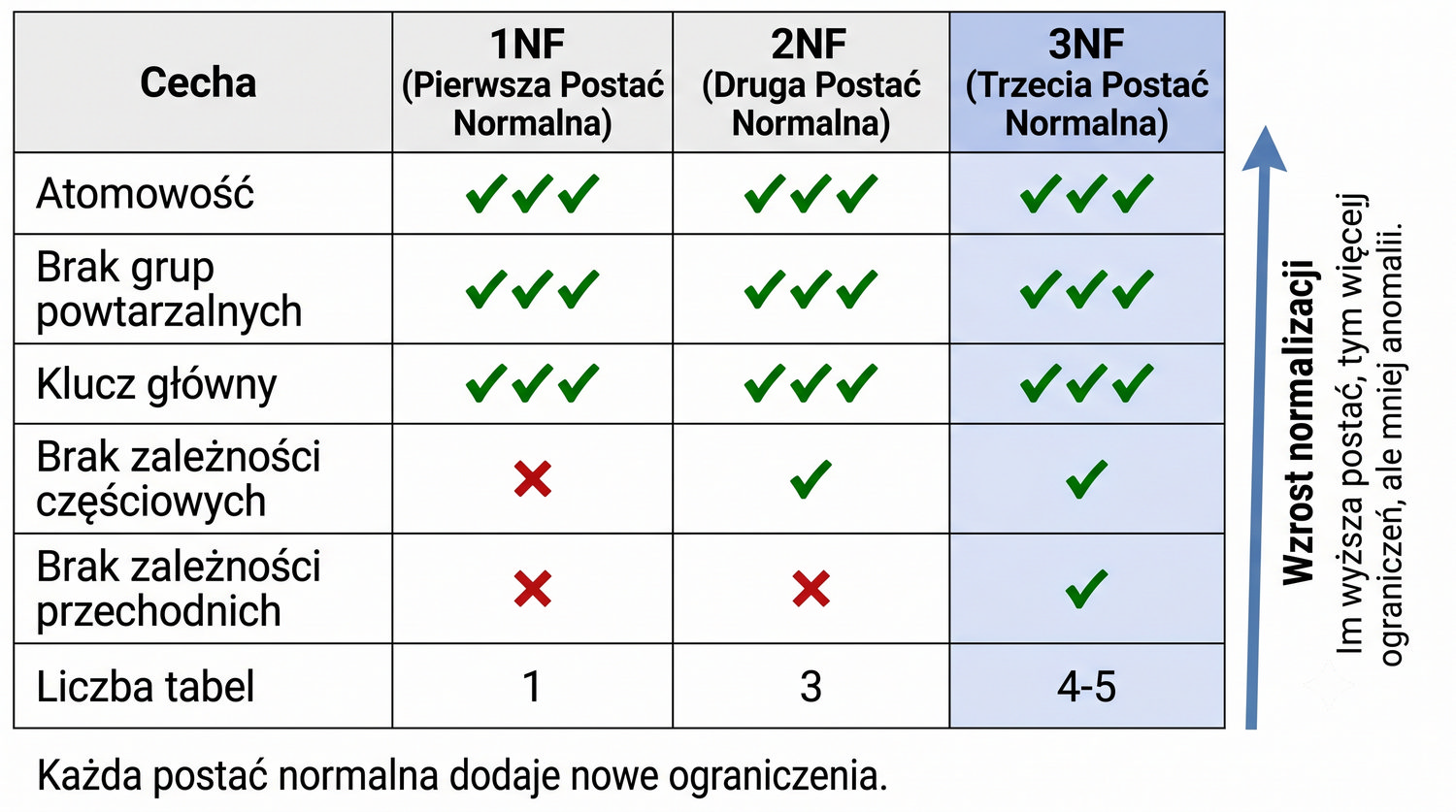
Porównanie 1NF i 3NF zasługuje na szczegółowe omówienie, ponieważ te dwie postaci normalne stanowią najważniejsze etapy normalizacji. 1NF usuwa strukturę nienormalizowaną – eliminuje grupy powtarzalne i zapewnia atomowość wartości. Problem w 1NF był "gruby" i łatwo widoczny: jedna komórka mogła zawierać wiele książek, a kolumny powtarzały się (Ksiazka1, Ksiazka2, ...). Dekompozycja z 1NF do 2NF była radykalna – z jednej tabeli powstawały trzy.
3NF natomiast zajmuje się problemami "drobniejszymi" – zależnościami przechodnimi, które są subtelniejsze i trudniejsze do wykrycia. Podczas gdy 1NF eliminuje oczywiste naruszenia struktury, 3NF poprawia jakość danych na głębszym poziomie semantycznym. Problem w 3NF jest trudniejszy do zauważenia, ponieważ wymaga zrozumienia, które atrybuty są ze sobą logicznie powiązane, a które tylko wydają się być powiązane.
Dekompozycja z 2NF do 3NF również jest mniej radykalna niż z 1NF do 2NF – zamiast tworzenia trzech tabel z jednej, w 3NF wydzielamy jedną tabelę (Miasta) z dwóch tabel (Czytelnicy). Mimo że zmiana jest mniejsza, jej wpływ na integralność danych jest równie istotny. 3NF eliminuje anomalie, które mogłyby pozostać niewykryte przez długi czas, a ich konsekwencje – błędne dane w raportach – mogłyby być kosztowne.
Rozdzielenie tabel Czytelnicy i Miasta według kryterium logicznego – dane osobowe vs dane geograficzne – jest przykładem dobrego projektowania baz danych. Każda tabela powinna reprezentować jedną encję lub jeden koncept. Mieszanie danych geograficznych (Miasto, KodPocztowy) z danymi osobowymi (Imię, Nazwisko, Telefon) w jednej tabeli narusza zasadę separacji odpowiedzialności i prowadzi do redundancji.
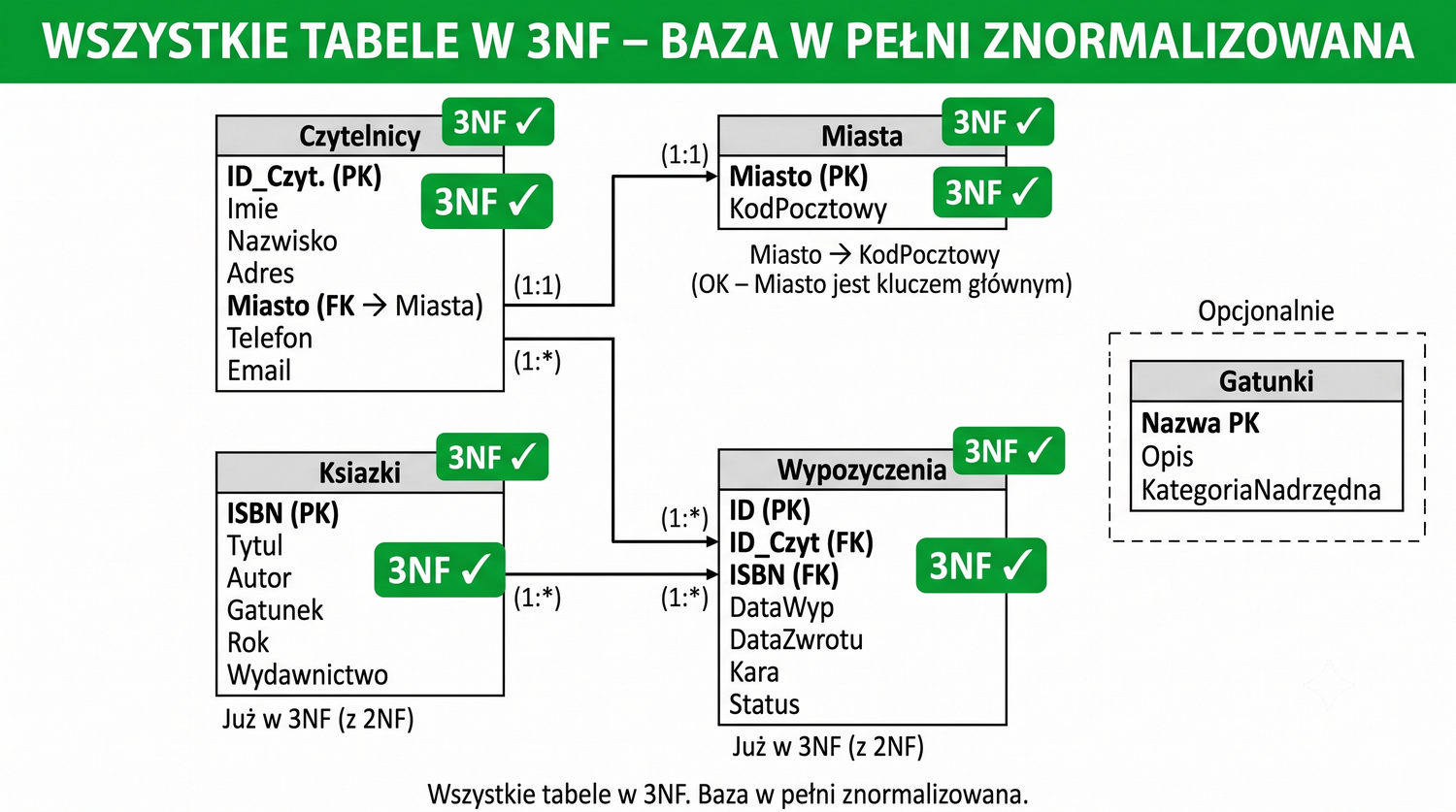
Po dekompozycji do 3NF tabela Czytelnicy zawiera wyłącznie dane osobowe czytelników: ID_Czytelnika, Imię, Nazwisko, Adres, Telefon, Email oraz ID_Miasta jako klucz obcy. Tabela Miasta zawiera dane geograficzne: ID_Miasta, NazwaMiasta, KodPocztowy. Każda tabela ma jeden, jasno określony cel. Taka struktura ułatwia zarządzanie danymi – zmiany w danych geograficznych nie wymagają modyfikacji danych osobowych i odwrotnie.
W rzeczywistych systemach bibliotecznych tabele Miasta mogą być dodatkowo rozszerzone o województwo, powiat, czy strefę pocztową, co jeszcze bardziej uzasadnia ich wydzielenie do osobnej tabeli. Często tworzy się również tabele Ulice, a nawet tabele Adresy (łączące Miasta i Ulice), aby jeszcze precyzyjniej modelować rzeczywistość. Każdy z tych podziałów zwiększa elastyczność i integralność systemu.
3NF spełniona!
Osiągnięcie 3NF – brak zależności przechodnich – jest rzeczywiście najważniejszym kamieniem milowym w procesie normalizacji dla większości systemów bazodanowych. W praktyce inżynierskiej 3NF uznaje się za wystarczający poziom normalizacji dla systemów produkcyjnych. Dalsze postaci normalne (BCNF, 4NF, 5NF) dotyczą specyficznych, rzadziej spotykanych problemów, takich jak zależności wielowartościowe czy zależności złączeniowe.
Moment, w którym baza danych osiąga 3NF, oznacza, że wszystkie podstawowe anomalie (INSERT, UPDATE, DELETE) zostały wyeliminowane. Redundancja jest zredukowana do minimum praktycznego, a struktura tabel odzwierciedla rzeczywiste powiązania między encjami w systemie. To właśnie 3NF jest celem, do którego dąży się podczas projektowania schematu bazy danych, przed ewentualną denormalizacją dla optymalizacji wydajności.
Dla studenta informatyki zrozumienie różnicy między 2NF a 3NF jest kluczowe, ponieważ pozwala na samodzielną analizę i poprawę struktury baz danych. W odróżnieniu od 1NF (która jest oczywista) i 2NF (która wymaga zrozumienia kluczy złożonych), 3NF wymaga głębszego zrozumienia semantyki danych – wiedzy, które atrybuty są ze sobą powiązane i dlaczego. Ta umiejętność jest niezbędna dla każdego projektanta baz danych.
Przykład: Wypozyczenia – 3NF auto.
Zależności przechodnie są rzeczywiście specyficznym problemem, który występuje rzadziej niż problemy eliminowane przez 1NF czy 2NF. O ile grupy powtarzalne (problem 1NF) są łatwe do wykrycia, a zależności częściowe (problem 2NF) pojawiają się w każdej tabeli z kluczem złożonym, o tyle zależności przechodnie wymagają głębszej analizy semantycznej i nie występują w każdej bazie danych.
Mimo że są rzadsze, zależności przechodnie mogą być szczególnie niebezpieczne, ponieważ są trudniejsze do wykrycia. Programista, który nie jest świadomy koncepcji normalizacji, może przez długi czas nie zauważyć problemu. Działająca aplikacja nie zgłasza błędów – jedynym symptomem są rosnące problemy z integralnością danych, które ujawniają się dopiero przy próbach aktualizacji lub przy generowaniu raportów.
W praktyce zależności przechodnie często pojawiają się w tabelach z atrybutami opisowymi, które są dodawane "na wszelki wypadek" lub "bo mogą się przydać". Typowym przykładem jest dodanie opisu do kategorii produktu, opisu do działu, czy opisu do miasta. Każdy z tych przypadków to potencjalna zależność przechodnia, która powinna zostać wyeliminowana przez wydzielenie osobnej tabeli.
(ID\_Faktury, Klient, Adres, Miasto, KodPocztowy, NIP, Data, KwotaNetto, StawkaVAT)

Przykład z klientami i miastami w systemie handlowym ilustruje uniwersalność wzorca dekompozycji 3NF. W systemie Klienci-Ceny-Zamowienia (wcześniej normalizowanym do 2NF) tabela Klienci może zawierać kolumny: NIP (klucz główny), Nazwa, Adres, Miasto, KodPocztowy. Zależność przechodnia NIP → Miasto → KodPocztowy jest identyczna jak w przypadku czytelników.
Rozwiązanie jest analogiczne: tworzymy tabelę Miasta(Miasto, KodPocztowy), gdzie Miasto jest kluczem głównym, a KodPocztowy atrybutem. W tabeli Klienci zostaje kolumna Miasto jako klucz obcy. Dzięki temu każda para (Miasto, KodPocztowy) występuje dokładnie jeden raz, a zmiana kodu pocztowego dla danego miasta wymaga aktualizacji dokładnie jednego wiersza.
Ten przykład pokazuje, że normalizacja nie jest procesem specyficznym dla konkretnej dziedziny – te same wzorce problemów pojawiają się w systemach bibliotecznych, handlowych, kadrowych, magazynowych i każdych innych. Umiejętność rozpoznawania tych wzorców i stosowania odpowiednich reguł normalizacji jest kluczową kompetencją projektanta baz danych, niezależnie od branży.
Produkty: (ID, Nazwa, Kategoria, OpisKategorii)
Zamowienia: (ID, Klient, Produkt, Ilosc, Cena, Data)
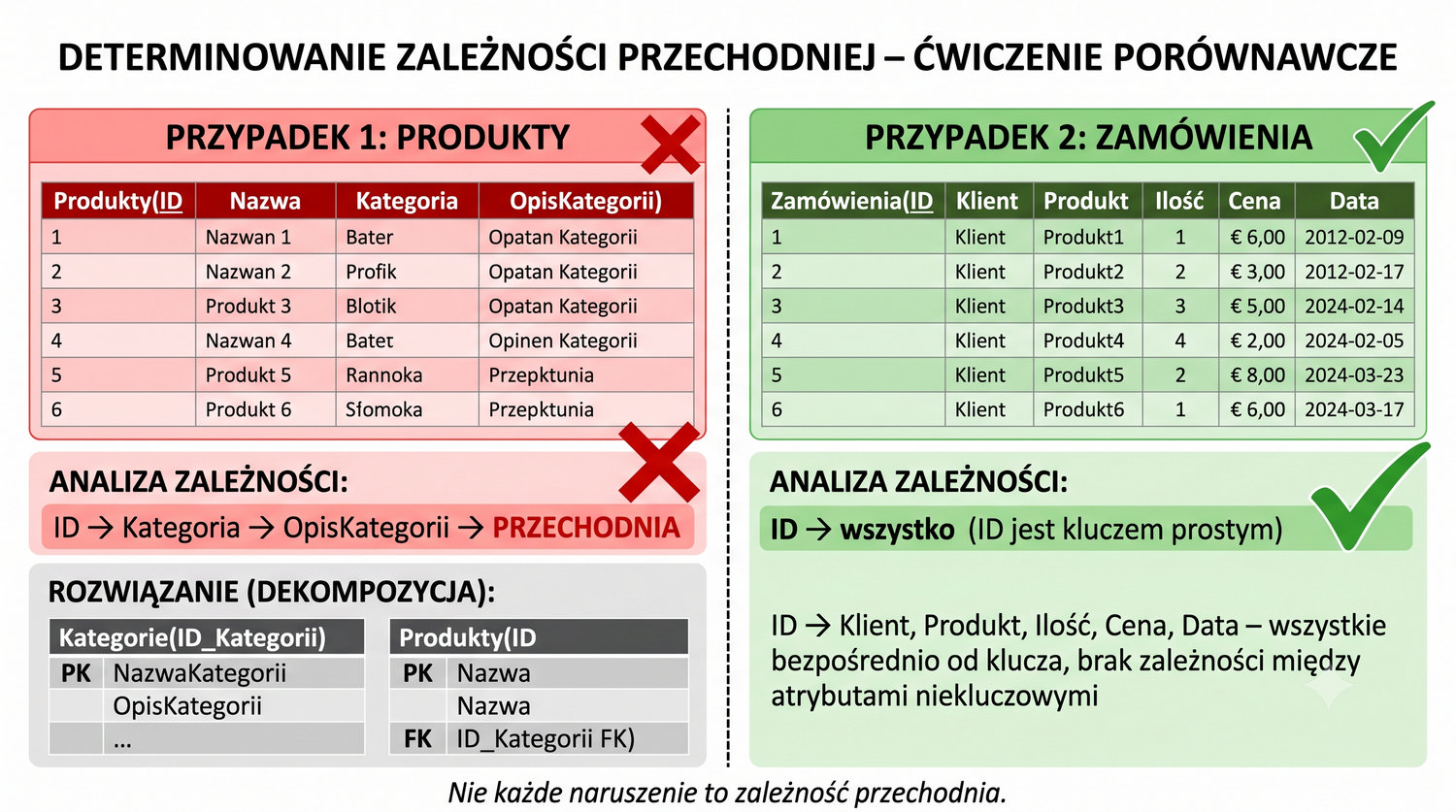
Tworzenie osobnej tabeli Kategorie jest kolejnym przykładem eliminacji zależności przechodniej. W systemie handlowym tabela Produkty może zawierać kolumny ID_Produktu, Nazwa, Cena, Kategoria, OpisKategorii. Zależność ID_Produktu → Kategoria → OpisKategorii jest klasyczną zależnością przechodnią. Opis kategorii nie zależy od produktu, ale od kategorii, do której produkt należy.
Rozwiązanie polega na utworzeniu tabeli Kategorie(ID_Kategorii, NazwaKategorii, OpisKategorii), gdzie ID_Kategorii jest kluczem głównym. W tabeli Produkty przechowujemy ID_Kategorii jako klucz obcy. Dzięki temu zmiana opisu kategorii wymaga aktualizacji dokładnie jednego wiersza w tabeli Kategorie, a wszystkie produkty automatycznie "widzą" nowy opis.
W rzeczywistych systemach tabela Kategorie może być znacznie bardziej rozbudowana – może zawierać hierarchię kategorii (kategoria nadrzędna), atrybuty specyficzne dla kategorii, czy metadane dotyczące wyświetlania w sklepie internetowym. Wydzielenie kategorii do osobnej tabeli na etapie 3NF umożliwia późniejsze rozszerzanie jej struktury bez konieczności modyfikacji tabeli Produkty.
| Miasto | Kod |
|---|---|
| Kraków | 30-001 |
| Warszawa | 00-002 |
| Gdańsk | 80-003 |
| Wrocław | 50-004 |
| Poznań | 60-005 |
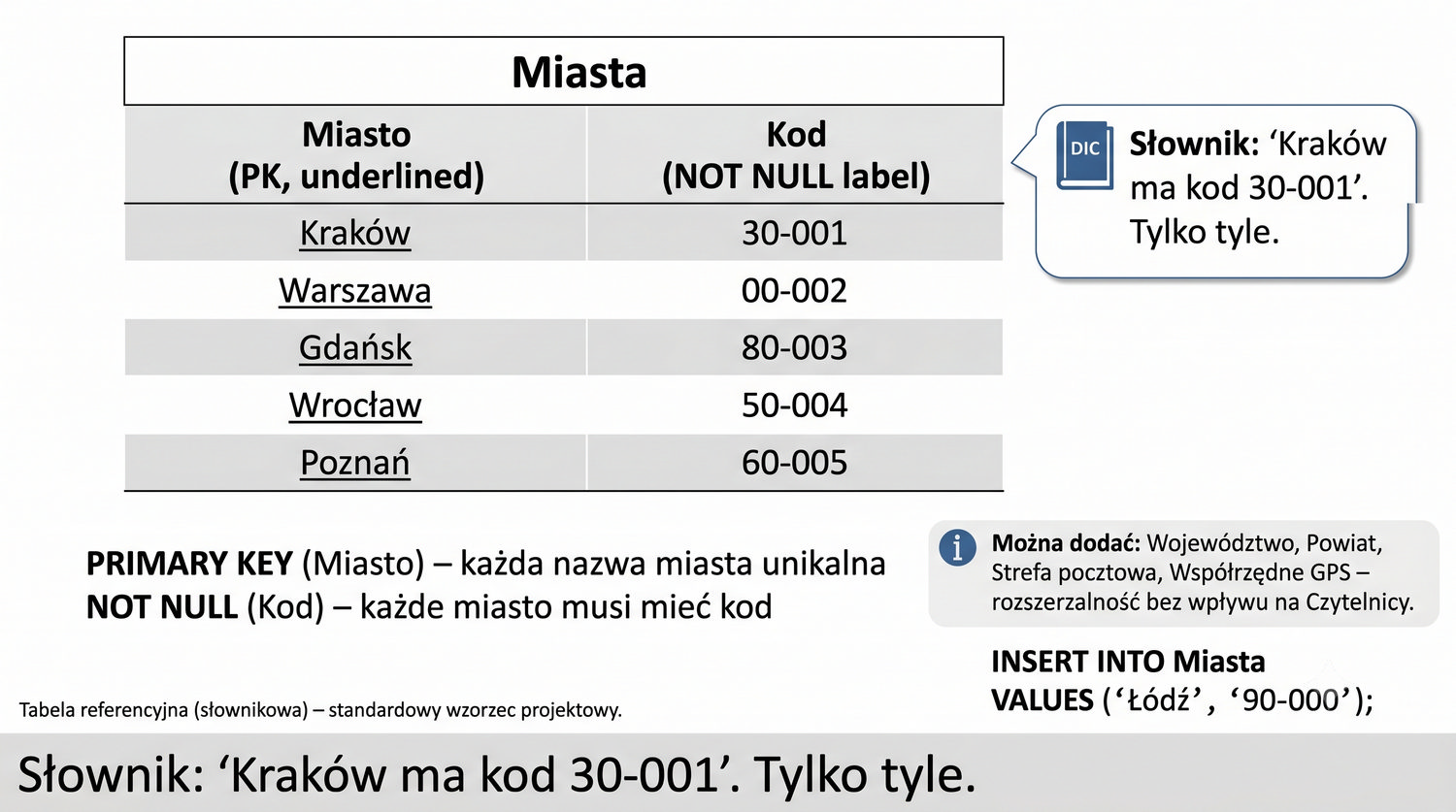
Tabela Miasta jako tabela referencyjna (słownikowa) to standardowy wzorzec projektowy w systemach bazodanowych. Tabele referencyjne zawierają dane, które są używane przez inne tabele jako wartości referencyjne – w tym przypadku lista miast z kodami pocztowymi. W realnym systemie tabela Miasta może zawierać znacznie więcej informacji: województwo, powiat, strefę pocztową, współrzędne geograficzne, czy nawet numer kierunkowy.
Stosowanie tabel referencyjnych ma wiele zalet. Po pierwsze, zapewnia spójność danych – nie ma ryzyka, że to samo miasto pojawi się z różnymi pisowniami (np. "Wrocław", "Wroclaw", "WROCŁAW"). Po drugie, ułatwia zarządzanie danymi – zmiana województwa dla miasta wymaga modyfikacji jednego wiersza. Po trzecie, umożliwia dodawanie atrybutów opisowych bez zmiany struktury tabel głównych.
W praktyce często stosuje się osobne tabele referencyjne dla kodów pocztowych (KodyPocztowe), ponieważ w polskim systemie pocztowy kod może obejmować wiele miejscowości (np. strefa pocztowa). Hierarchia: Województwo → Powiat → Miasto → KodPocztowy może być modelowana jako seria tabel referencyjnych, gdzie każda tabela zawiera klucz obcy do tabeli nadrzędnej. Taka struktura zapewnia pełną elastyczność i integralność danych.
Czytelnicy: (ID, Imie, Nazwisko, Adres, Miasto FK, Telefon, Email)

Stwierdzenie "Zmiana kodu Krakowa = UPDATE 1 wiersza w Miasta" doskonale ilustruje praktyczną korzyść z 3NF. Przed normalizacją, gdy kod pocztowy był przechowywany w tabeli Czytelnicy, zmiana kodu dla Krakowa wymagałaby aktualizacji N wierszy (gdzie N to liczba czytelników w Krakowie). Po dekompozycji do 3NF, zmiana ta wymaga aktualizacji dokładnie jednego wiersza w tabeli Miasta.
Różnica jest fundamentalna nie tylko ze względu na wydajność. Aktualizacja jednego wiersza jest operacją atomową – albo się udaje w całości, albo w ogóle. Aktualizacja tysiąca wierszy może się nie udać w połowie (np. awaria serwera), pozostawiając bazę w stanie niespójnym. Dodatkowo, aktualizacja jednego wiersza wymaga jednej blokady (lock), podczas gdy aktualizacja tysiąca wierszy wymaga tysiąca blokad, co może prowadzić do zakleszczeń (deadlocków).
W systemach o wysokiej dostępności, gdzie czas przestoju jest niedopuszczalny, możliwość wykonania pojedynczej operacji UPDATE zamiast tysiąca ma ogromne znaczenie operacyjne. Aktualizacja kodu pocztowego dla całego miasta może być wykonana w ramach jednej transakcji SQL, która trwa ułamki sekundy, nawet przy rekordach zablokowanych przez inne transakcje. To jeden z powodów, dla których 3NF jest standardem w systemach produkcyjnych.
| Aspekt | Przed | Po |
|---|---|---|
| Kolumny w Czytelnicy | 8 | 7 |
| Liczba tabel | 3 | 4 |
| Kod pocztowy | W każdym wierszu | Raz w Miasta |
| Zmiana kodu | N wierszy | 1 wiersz |
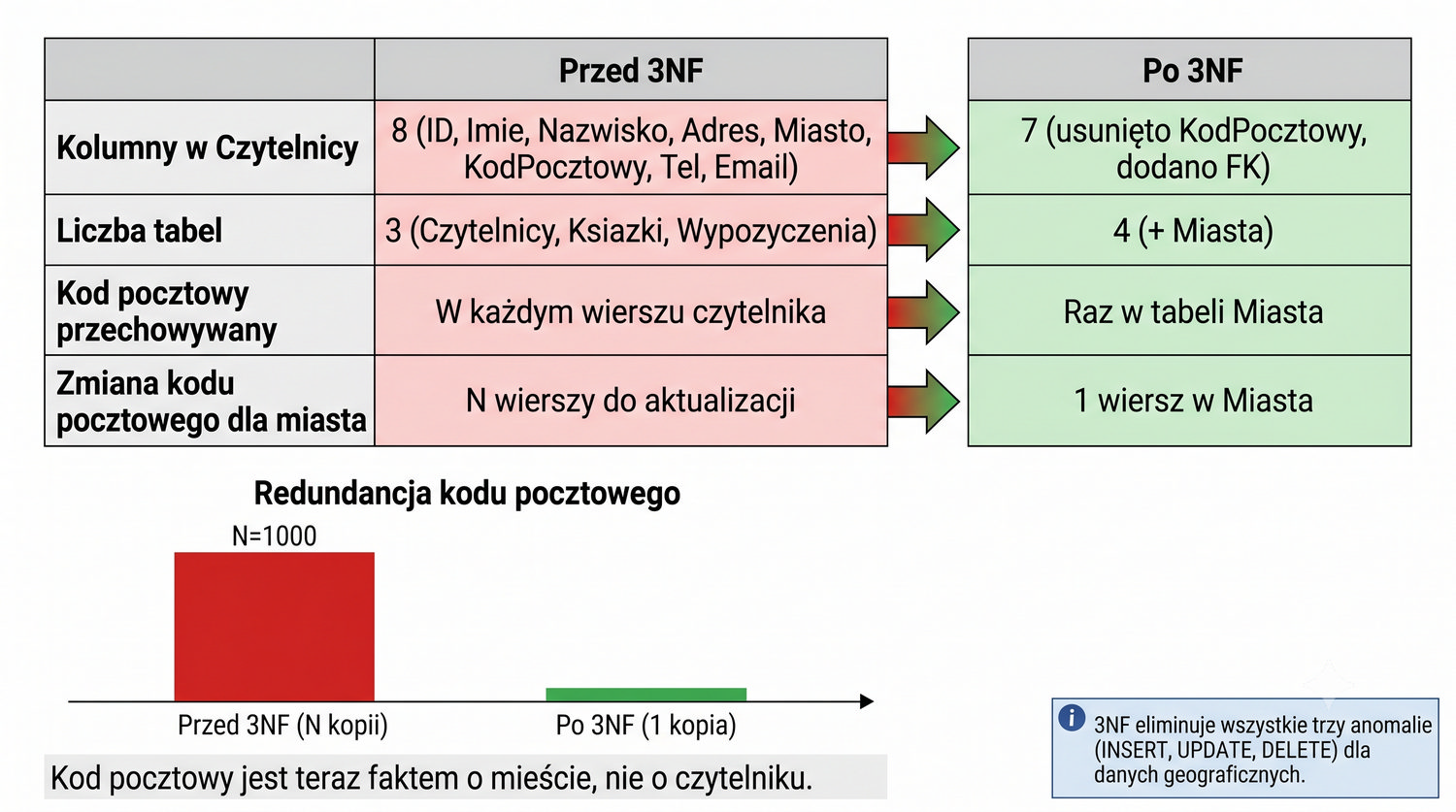
3NF eliminuje wszystkie trzy rodzaje anomalii (INSERT, UPDATE, DELETE) w kontekście danych geograficznych. Anomalia INSERT: przed normalizacją nie można było dodać nowego miasta z kodem pocztowym, dopóki nie pojawił się czytelnik w tym mieście. Po normalizacji dodanie miasta jest niezależne od istnienia czytelników – można dodać dowolne miasto do tabeli Miasta w każdej chwili.
Anomalia UPDATE: przed normalizacją zmiana kodu pocztowego dla miasta wymagała aktualizacji wszystkich czytelników w tym mieście. Po normalizacji zmiana kodu wymaga aktualizacji dokładnie jednego wiersza w tabeli Miasta. Anomalia DELETE: przed normalizacją usunięcie ostatniego czytelnika z danego miasta powodowało utratę informacji o kodzie pocztowym tego miasta. Po normalizacji usunięcie czytelnika nie wpływa na dane w tabeli Miasta.
Warto zauważyć, że te same anomalie dotyczą również innych atrybutów, które mogą być przechowywane w tabeli Miasta – województwa, strefy pocztowej, czy współrzędnych geograficznych. Każdy z tych atrybutów, gdyby był przechowywany w tabeli Czytelnicy, generowałby te same trzy anomalie. 3NF zapewnia, że każdy atrybut jest przechowywany w tabeli encji, której bezpośrednio dotyczy, co eliminuje wszystkie anomalie.
Jeśli przechowujemy opis gatunku:
ISBN → GatunekNazwa → OpisGatunku → PRZECHODNIA
Rozwiązanie: Gatunki (Nazwa PK, Opis, KategoriaNadrzędna)

Stwierdzenie "Jeśli nie potrzebujesz opisu gatunku, nie ma to sensu" odnosi się do pragmatycznego podejścia do normalizacji. Jeśli w tabeli Ksiazki nie ma atrybutu OpisGatunku, to nie ma zależności przechodniej, a więc nie ma potrzeby wydzielania osobnej tabeli Gatunki. Normalizacja nie powinna być celem samym w sobie – powinna być stosowana tam, gdzie przynosi rzeczywiste korzyści w postaci eliminacji anomalii.
W praktyce oznacza to, że nie każdą tabelę trzeba normalizować do 3NF. Jeśli tabela zawiera atrybut Gatunek, ale nie ma żadnych dodatkowych atrybutów opisowych zależnych od Gatunku, to pozostawienie Gatunku jako kolumny w tabeli Ksiazki jest w pełni dopuszczalne. Normalizacja jest narzędziem, a nie dogmatem – celem jest poprawa jakości danych, a nie osiągnięcie formalnej doskonałości za wszelką cenę.
Jednakże, jeśli w przyszłości pojawi się potrzeba dodania opisu gatunku (np. wzbogacenie systemu o informacje dla czytelników), wtedy konieczne będzie przeprowadzenie dekompozycji do 3NF. Dlatego dobrą praktyką jest projektowanie bazy danych z myślą o przyszłych rozszerzeniach – nawet jeśli obecnie nie ma potrzeby przechowywania opisu gatunku, warto rozważyć, czy taka potrzeba może pojawić się w przyszłości.
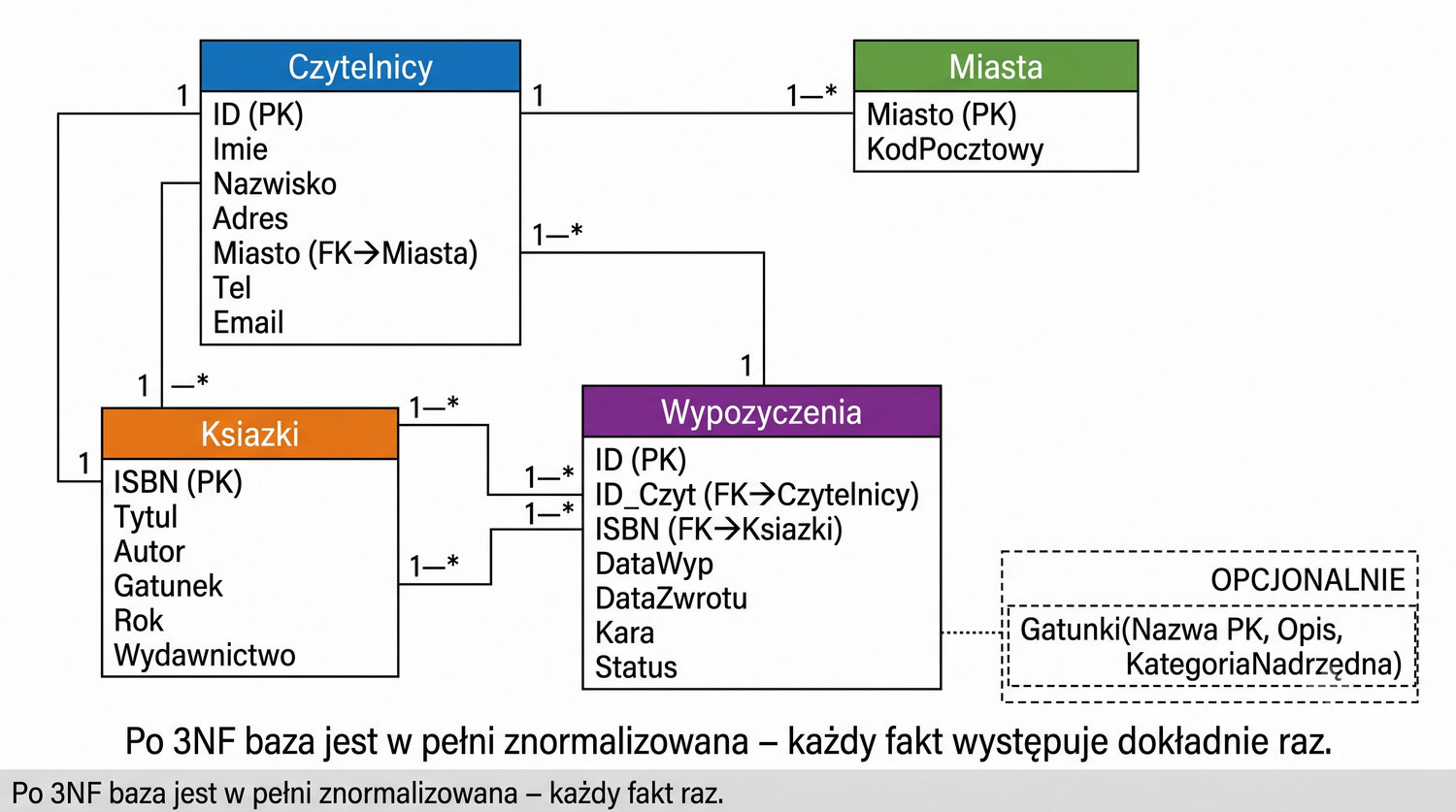
Zasada "każda tabela ma jeden cel" jest fundamentalną regułą projektowania relacyjnych baz danych, która znajduje swoje formalne uzasadnienie w normalizacji. Każda tabela powinna reprezentować jedną encję – typ obiektu w modelowanej rzeczywistości. Mieszanie różnych encji w jednej tabeli prowadzi do redundancji, anomalii i trudności w utrzymaniu systemu.
W naszym przypadku tabela Czytelnicy reprezentuje encję "czytelnik" – osobę korzystającą z biblioteki. Tabela Miasta reprezentuje encję "miasto" – lokalizację geograficzną. Każda z tych encji ma swoje własne atrybuty i własny cykl życia. Czytelnicy są dodawani, usuwani i modyfikowani niezależnie od miast. Miasta mogą być dodawane i modyfikowane niezależnie od czytelników. Łączenie tych encji w jednej tabeli tworzy sztuczne powiązania.
W dobrze zaprojektowanej bazie danych każda tabela ma swój własny klucz główny i zestaw atrybutów, które są bezpośrednio zależne od tego klucza. Relacje między tabelami są realizowane za pomocą kluczy obcych, które łączą encje, ale nie ingerują w ich wewnętrzną strukturę. Taka architektura zapewnia modularność, elastyczność i łatwość zarządzania danymi.

Po osiągnięciu 3NF baza danych jest "czysta" w sensie normalizacyjnym – wszystkie wykrywalne anomalie zostały wyeliminowane, a struktura tabel jest optymalna z punktu widzenia integralności danych. W języku inżynierii oprogramowania mówi się, że baza jest "gotowa do produkcji" – można na niej oprzeć działający system, nie obawiając się ukrytych problemów z danymi.
W praktyce produkcyjnej baza w 3NF jest punktem wyjścia dla każdego systemu, który będzie używany przez dłuższy czas. Nawet jeśli docelowo planuje się denormalizację dla optymalizacji wydajności (np. dodanie zduplikowanych kolumn dla szybszych odczytów), punktem startowym zawsze powinna być baza w 3NF. Pozwala to na świadome podjęcie decyzji o denormalizacji z pełnym zrozumieniem konsekwencji.
Warto podkreślić, że "gotowa do produkcji" nie oznacza "absolutnie doskonała". W zależności od specyficznych wymagań systemu, może być konieczne zastosowanie dalszych postaci normalnych (BCNF, 4NF, 5NF) lub odwrotnie – celowa denormalizacja dla poprawy wydajności zapytań. Elastyczność w podejściu do normalizacji jest równie ważna jak sama znajomość reguł normalizacyjnych.
Dla 90% systemów 3NF jest wystarczająca.
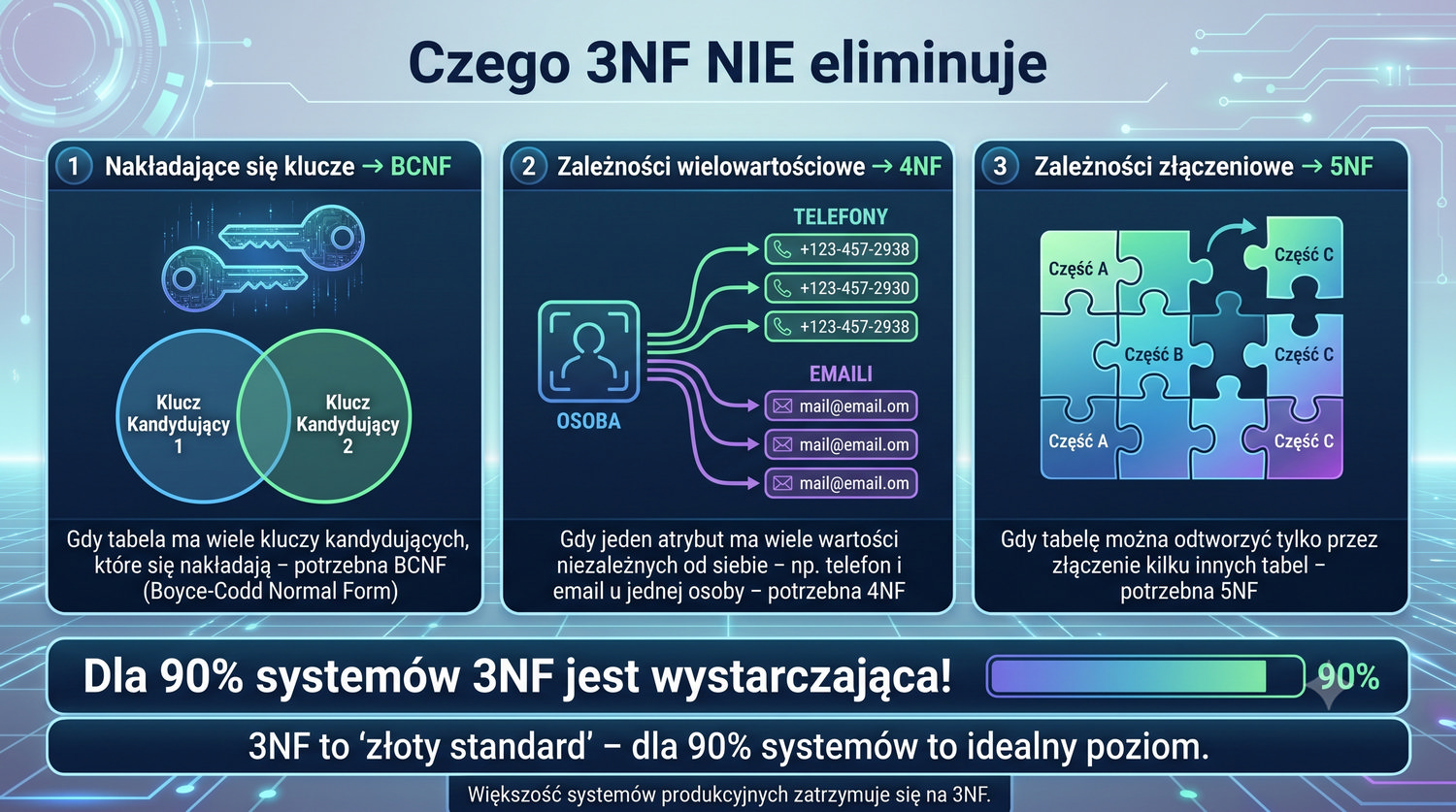
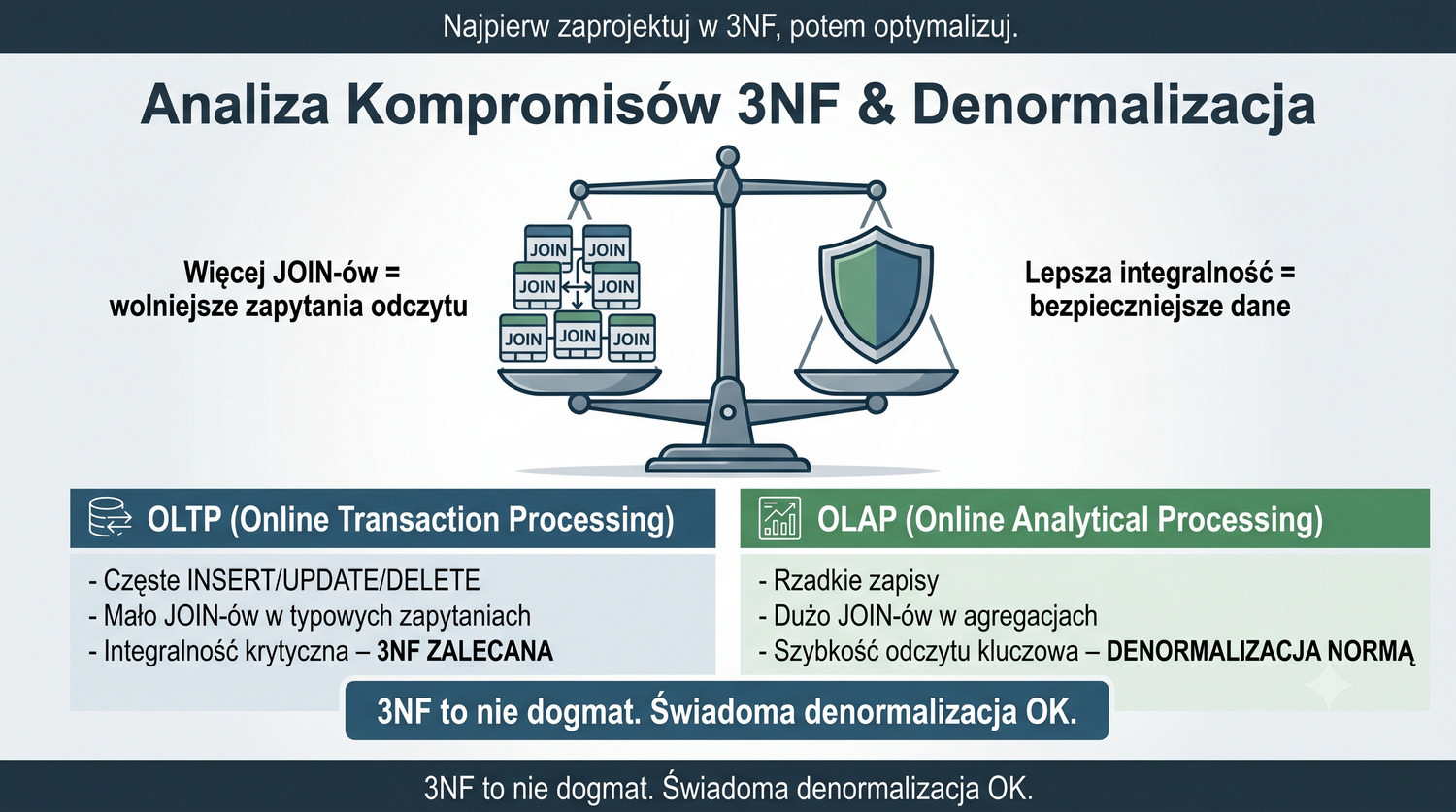
Stwierdzenie "Większość systemów produkcyjnych zatrzymuje się na 3NF" pojawia się w tej prezentacji wielokrotnie, ponieważ jest to jedna z najważniejszych praktycznych zasad w projektowaniu baz danych. 3NF jest uznawana za optymalny poziom normalizacji dla systemów OLTP, gdzie kluczowe znaczenie ma integralność danych przy jednoczesnej akceptowalnej wydajności zapytań. Rzadko spotyka się systemy produkcyjne znormalizowane do 4NF czy 5NF.
Dlaczego tak się dzieje? Dalsze postaci normalne (BCNF, 4NF, 5NF) eliminują problemy, które w praktyce występują niezwykle rzadko. Zależności wielowartościowe (4NF) i zależności złączeniowe (5NF) są w systemach biznesowych bardzo nietypowe. Koszt ich eliminacji – dodatkowe JOIN-y i bardziej skomplikowane zapytania – często przewyższa korzyści z ich eliminacji. Większość projektantów baz danych świadomie rezygnuje z dalszej normalizacji.
Należy jednak pamiętać, że "większość systemów" nie oznacza "wszystkich". W systemach, gdzie wymagana jest wyjątkowo wysoka integralność danych (systemy bankowe, medyczne), warto rozważyć dalsze postaci normalne. Również w hurtowniach danych często stosuje się normalizację do wyższych postaci, aby zapewnić elastyczność analiz. Decyzja zawsze powinna być podyktowana specyficznymi wymaganiami konkretnego systemu.
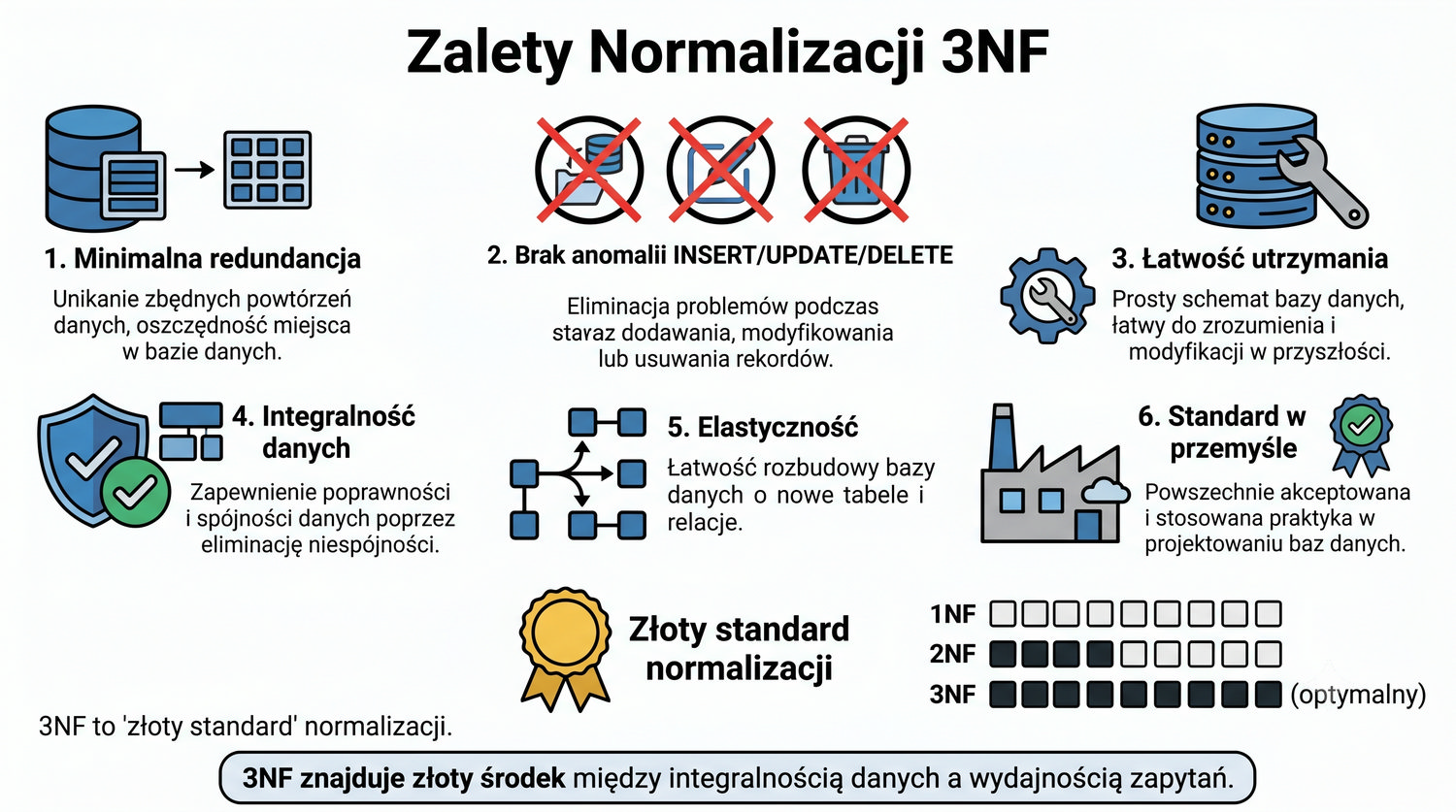
3NF jest uważana za optymalny poziom normalizacji, ponieważ znajduje złoty środek między dwoma przeciwstawnymi celami: integralnością danych a wydajnością zapytań. Z jednej strony, 3NF eliminuje wszystkie istotne anomalie (INSERT, UPDATE, DELETE), zapewniając wysoką integralność danych. Z drugiej strony, liczba tabel po 3NF jest zwykle wystarczająco mała, aby zapytania z JOIN-ami były akceptowalnie szybkie.
Porównajmy: 1NF to poziom minimalny, na którym system może działać, ale jest daleki od optymalnego pod względem integralności. 2NF to poprawa, ale wciąż pozostawia zależności przechodnie, które mogą powodować anomalie. 4NF i 5NF to poziomy, które dla wielu systemów są "przedobrzone" – eliminują problemy, które występują rzadko, a kosztem znacznie większej liczby tabel i bardziej skomplikowanych zapytań.
W praktyce często sytuacja wygląda następująco: projekt rozpoczyna się od 3NF, a następnie, w miarę identyfikowania wąskich gardeł wydajnościowych, selektywnie stosuje się denormalizację dla konkretnych zapytań, które są krytyczne dla wydajności. To podejście – "najpierw normalizuj, potem optymalizuj" – jest standardem w inżynierii baz danych i pozwala na osiągnięcie najlepszych rezultatów.
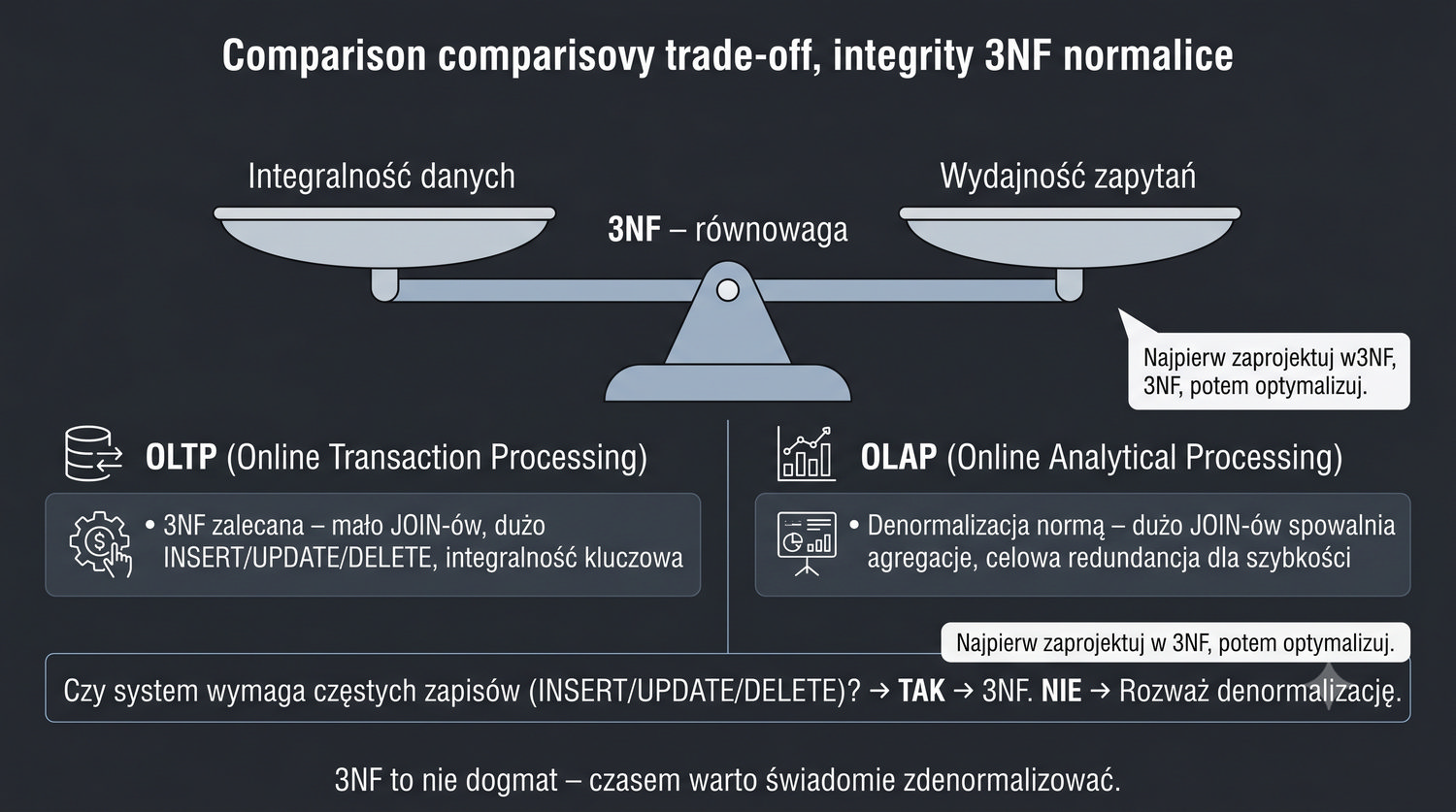
Zasada "Najpierw zaprojektuj w 3NF, potem optymalizuj" to jedna z najważniejszych maksym w inżynierii baz danych, pojawiająca się w tej prezentacji wielokrotnie ze względu na jej kluczowe znaczenie. Oznacza ona, że punktem wyjścia dla każdego projektu bazy danych powinna być struktura w pełni znormalizowana do 3NF. Dopiero później, na podstawie pomiarów wydajności i analizy wzorców zapytań, można świadomie odstąpić od normalizacji.
Denormalizacja bez punktu odniesienia w 3NF jest ryzykowna. Jeśli zaczniemy od struktury zdenormalizowanej, nigdy nie będziemy wiedzieć, jakie anomalie mogą wystąpić w danych. Co więcej, trudno będzie ocenić, czy dana denormalizacja rzeczywiście poprawia wydajność, skoro nie ma z czym porównać. Proces inżynieryjny wymaga punktu odniesienia, a 3NF dostarcza właśnie takiego punktu – czystej, wzorcowej struktury.
W praktyce często stosuje się podejście hybrydowe: większość tabel pozostaje w 3NF, a wybrane, krytyczne dla wydajności zapytania są optymalizowane poprzez selektywną denormalizację konkretnych kolumn. Na przykład, jeśli raport miesięczny wymaga złączenia pięciu tabel i jest zbyt wolny, można dodać zduplikowaną kolumnę w jednej z tabel, aby wyeliminować jeden JOIN. Każda taka decyzja powinna być udokumentowana.
-- Najpierw miasto INSERT INTO Miasta VALUES ('Łódź', '90-001'); -- Potem czytelnik INSERT INTO Czytelnicy ...;

Zdanie "Miasto istnieje niezależnie od czytelnika" podkreśla fundamentalną prawdę o modelowaniu danych: encje w systemie informatycznym powinny odzwierciedlać rzeczywiste byty, które mają własną tożsamość i cykl życia. Miasto istnieje w rzeczywistości niezależnie od tego, czy mieszka w nim czytelnik. Baza danych powinna to odzwierciedlać – tabela Miasta powinna zawierać wszystkie miasta, nawet te, w których nie ma jeszcze czytelników.
Klucz obcy (FK) z tabeli Czytelnicy do tabeli Miasta zapewnia integralność referencyjną: każdy czytelnik musi mieć przypisane istniejące miasto. Jednocześnie, miasto może istnieć w tabeli Miasta bez żadnego czytelnika, co eliminuje anomalię INSERT. To jest właśnie kluczowa różnica między przechowywaniem danych w jednej tabeli a w dwóch tabelach połączonych kluczem obcym.
W praktyce oznacza to, że podczas dodawania nowego czytelnika do systemu, bibliotekarz wybiera miasto z rozwijanej listy (pochodzącej z tabeli Miasta), a nie wpisuje go ręcznie. Jeśli miasto nie istnieje na liście, można je dodać do tabeli Miasta przed dodaniem czytelnika. Taki mechanizm zapewnia spójność danych i eliminuje ryzyko literówek czy niespójności w nazwach miast.
UPDATE Miasta SET KodPocztowy = '31-001' WHERE Miasto = 'Kraków'; SELECT c.Imie, m.KodPocztowy FROM Czytelnicy c JOIN Miasta m ON c.Miasto = m.Miasto;

Porównanie liczby wierszy przed i po normalizacji ilustruje redukcję redundancji. Przed 3NF, gdy tabela Czytelnicy zawierała atrybuty Miasto i KodPocztowy, kod pocztowy Krakowa ("30-001") był przechowywany tyle razy, ilu było czytelników w Krakowie. Przy trzech czytelnikach w Krakowie – trzy wiersze z kodem "30-001". Po 3NF kod "30-001" występuje dokładnie jeden raz w tabeli Miasta.
Różnica "3 wiersze → 1 wiersz" w tym małym przykładzie skaluje się liniowo. W systemie z tysiącem czytelników w Krakowie, przed normalizacją mamy 1000 kopii kodu "30-001", po normalizacji – jedną. Oszczędność miejsca to 999 wierszy. W systemie z milionem czytelników i setkami miast, oszczędność miejsca może być rzędu milionów wierszy, co przekłada się na realne oszczędności w pamięci masowej.
Warto jednak zauważyć, że oszczędność miejsca to tylko jedna z korzyści. Równie ważna jest eliminacja ryzyka niespójności – zamiast tysiąca wierszy do zaktualizowania przy zmianie kodu pocztowego, mamy jeden. Dodatkowo, zapytania agregujące (np. "policz czytelników według miasta") są szybsze, gdy dane geograficzne są w osobnej tabeli, ponieważ można użyć indeksów i grupowania na mniejszym zbiorze danych.
DELETE FROM Czytelnicy WHERE Miasto = 'Gdańsk'; SELECT * FROM Miasta; -- Gdańsk, 80-003 – dane bezpieczne
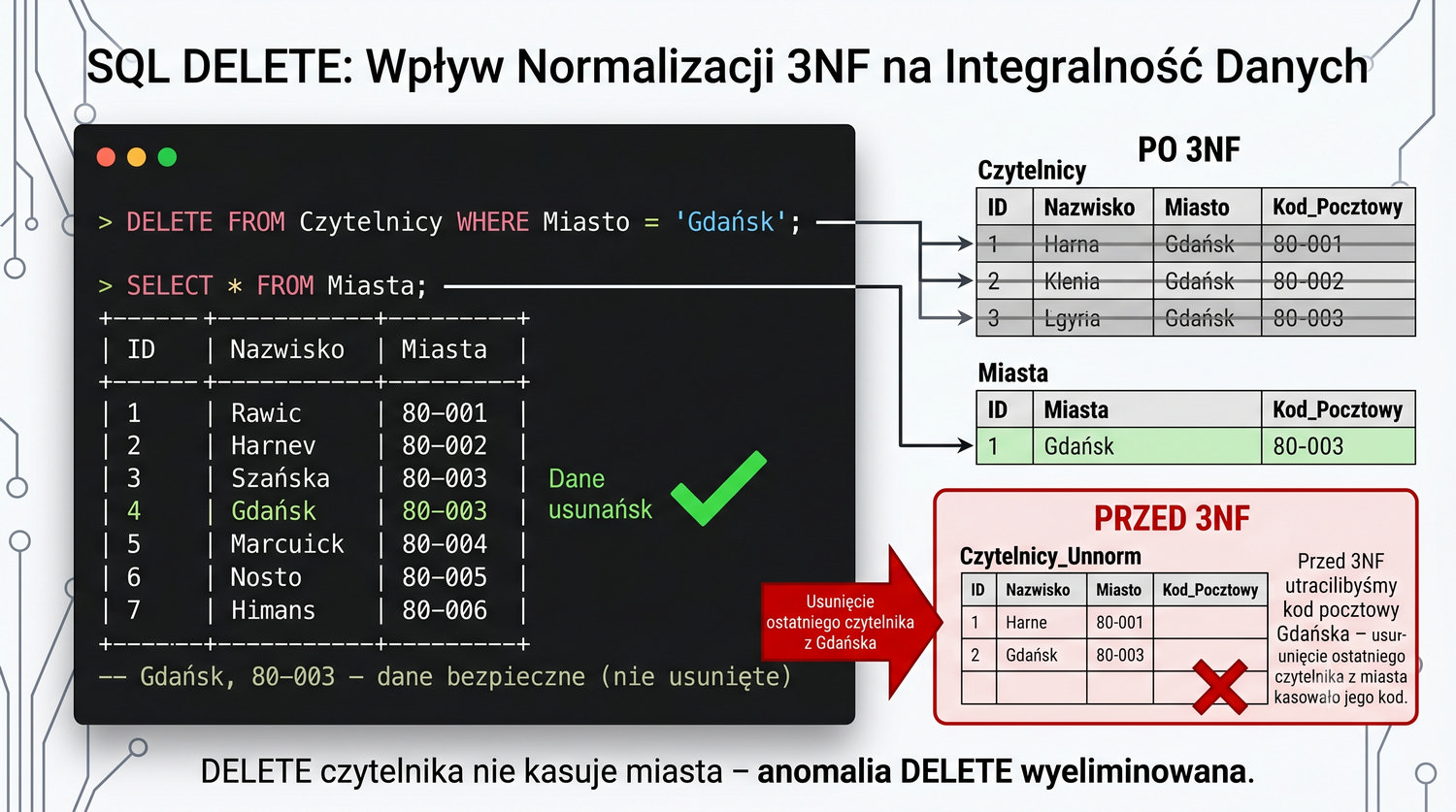
Stwierdzenie "Przed 3NF utracilibyśmy kod pocztowy Gdańska" odnosi się do konkretnego scenariusza z anomalią DELETE. W tabeli Czytelnicy przed normalizacją, jeśli ostatni czytelnik z Gdańska (Piotr Wiśniewski) zostałby usunięty z systemu, informacja o kodzie pocztowym Gdańska (80-003) zostałaby bezpowrotnie utracona. To klasyczny przykład anomalii DELETE, która jest eliminowana przez 3NF.
Po dekompozycji do 3NF, tabela Miasta zawiera wszystkie miasta niezależnie od tego, czy mieszkają w nich czytelnicy. Gdańsk z kodem 80-003 istnieje w tabeli Miasta jako osobny wiersz. Usunięcie Piotra Wiśniewskiego z tabeli Czytelnicy nie ma żadnego wpływu na dane w tabeli Miasta – kod pocztowy Gdańska pozostaje w bazie danych, dostępny dla przyszłych czytelników z tego miasta.
Anomalia DELETE jest szczególnie niebezpieczna w systemach długoterminowych. Po latach użytkowania systemu, gdy wielu czytelników zmienia miejsce zamieszkania lub kończy członkostwo, można stracić znaczną część danych geograficznych. 3NF zapewnia, że dane o miastach są przechowywane niezależnie od danych o czytelnikach, co gwarantuje ich trwałość i dostępność przez cały okres eksploatacji systemu.
CREATE TABLE Miasta ( Miasto VARCHAR(50) PRIMARY KEY, KodPocztowy VARCHAR(10) NOT NULL ); INSERT INTO Miasta VALUES ('Kraków', '30-001'), ('Warszawa', '00-002'), ('Gdańsk', '80-003'), ('Wrocław', '50-004'), ('Poznań', '60-005');
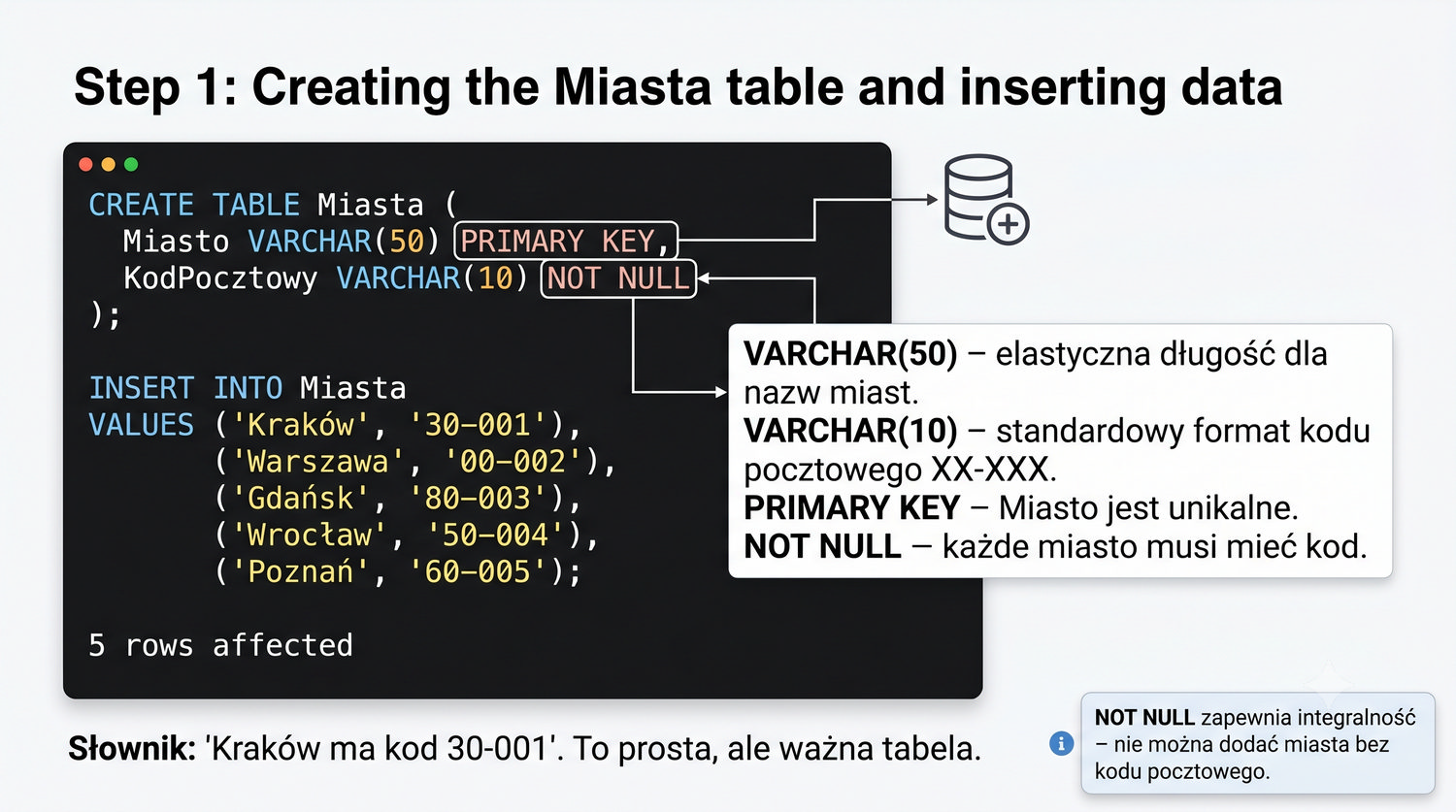
Ograniczenie NOT NULL na kolumnie KodPocztowy w tabeli Miasta jest ważnym elementem zapewnienia integralności danych. Oznacza ono, że każdy wiersz w tabeli Miasta musi zawierać kod pocztowy – nie ma możliwości dodania miasta bez kodu pocztowego. W kontekście 3NF, gdzie kod pocztowy jest atrybutem bezpośrednio zależnym od klucza głównego (Miasto), wymuszenie NOT NULL jest naturalną konsekwencją.
W praktyce NOT NULL powinno być stosowane dla wszystkich atrybutów, które są wymagane z punktu widzenia logiki biznesowej. W systemie bibliotecznym każda książka powinna mieć ISBN (NOT NULL), każdy czytelnik powinien mieć Imię i Nazwisko (NOT NULL), a każde miasto powinno mieć kod pocztowy (NOT NULL). Ograniczenia NOT NULL są implementowane na poziomie bazy danych, co zapewnia, że żadna aplikacja nie może wprowadzić danych bez wymaganych atrybutów.
W MariaDB deklaracja NOT NULL jest dodawana po typie danych w definicji kolumny: `KodPocztowy VARCHAR(6) NOT NULL`. Warto również rozważyć dodanie ograniczenia CHECK, jeśli kod pocztowy ma specyficzny format (np. w Polsce "XX-XXX"). Choć MariaDB nie egzekwuje CHECK w starszych wersjach, w nowszych wersjach (10.2+) CHECK jest w pełni obsługiwany i może być używany do walidacji formatu kodu pocztowego.
-- Sprawdź miasta w Czytelnicy SELECT DISTINCT Miasto FROM Czytelnicy; -- Czy wszystkie są w Miasta? SELECT c.Miasto FROM Czytelnicy c LEFT JOIN Miasta m ON c.Miasto = m.Miasto WHERE m.Miasto IS NULL;
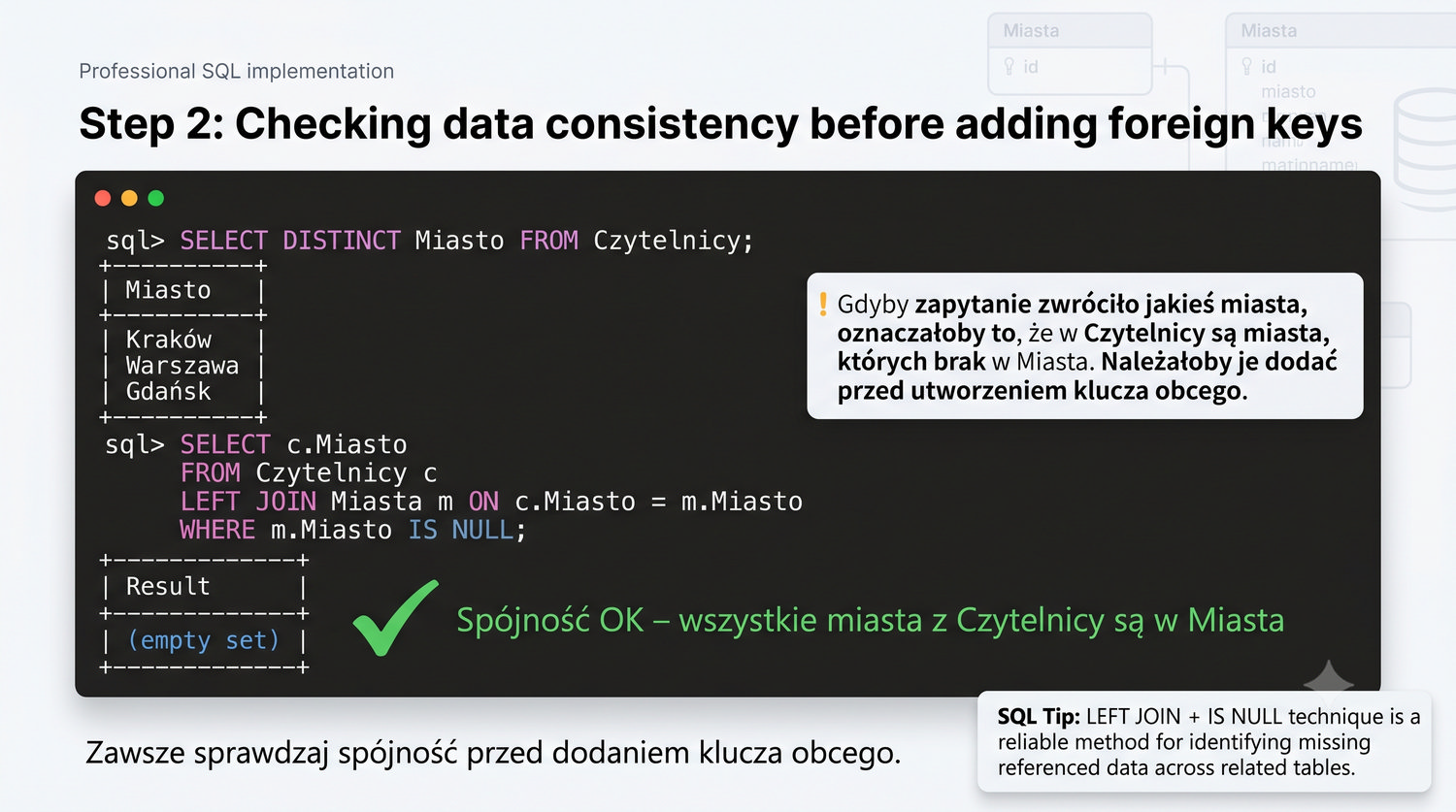
Technika LEFT JOIN + IS NULL jest zaawansowanym narzędziem do znajdowania danych, które są w jednej tabeli, ale nie w drugiej. W kontekście 3NF i tabeli Miasta, możemy użyć tej techniki do znalezienia miast, które nie mają żadnych czytelników. Zapytanie: `SELECT m.Miasto FROM Miasta m LEFT JOIN Czytelnicy c ON m.Miasto = c.Miasto WHERE c.Miasto IS NULL` zwróci listę miast bez czytelników.
LEFT JOIN zwraca wszystkie wiersze z tabeli Miasta oraz pasujące wiersze z tabeli Czytelnicy. Dla miast, które nie mają czytelników, kolumny z tabeli Czytelnicy będą zawierać NULL. Warunek `c.Miasto IS NULL` filtruje wyniki, pozostawiając tylko miasta bez czytelników. To bardzo przydatne narzędzie dla administratorów baz danych do analizy kompletności danych.
W szerszym kontekście normalizacji, ta technika może być używana do wykrywania problemów z integralnością referencyjną. Na przykład, jeśli chcemy znaleźć książki, które nigdy nie były wypożyczone, użylibyśmy: `SELECT k.ISBN FROM Ksiazki k LEFT JOIN Wypozyczenia w ON k.ISBN = w.ISBN WHERE w.ISBN IS NULL`. To pokazuje, jak znajomość zaawansowanych technik SQL idzie w parze z umiejętnością projektowania znormalizowanych baz danych.
-- Usuń KodPocztowy ALTER TABLE Czytelnicy DROP COLUMN KodPocztowy; -- Dodaj FK ALTER TABLE Czytelnicy ADD CONSTRAINT fk_miasto FOREIGN KEY (Miasto) REFERENCES Miasta(Miasto);
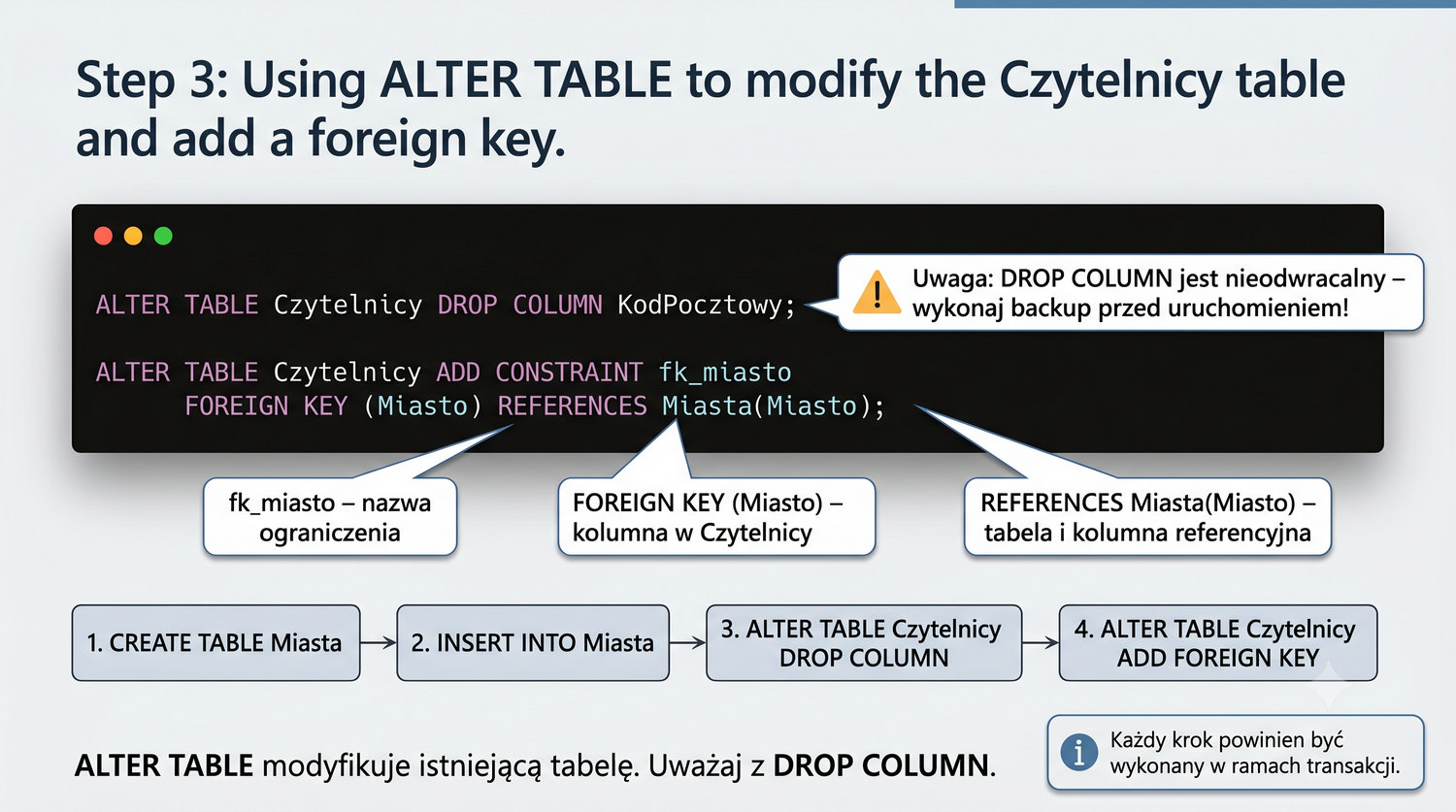
Kolejność operacji SQL podczas dekompozycji do 3NF ma kluczowe znaczenie dla powodzenia migracji danych. Zasadniczo najpierw należy utworzyć nową tabelę Miasta i wypełnić ją danymi, następnie dodać kolumnę ID_Miasta w tabeli Czytelnicy, zaktualizować ją odpowiednimi wartościami, a dopiero potem usunąć starą kolumnę KodPocztowy z tabeli Czytelnicy.
Usunięcie kolumny KodPocztowy przed dodaniem klucza obcego spowodowałoby utratę danych. Dlatego właściwa kolejność to: (1) CREATE TABLE Miasta, (2) INSERT INTO Miasta SELECT DISTINCT, (3) ALTER TABLE Czytelnicy ADD COLUMN ID_Miasta, (4) UPDATE Czytelnicy SET ID_Miasta = ..., (5) ALTER TABLE Czytelnicy ADD FOREIGN KEY, (6) ALTER TABLE Czytelnicy DROP COLUMN KodPocztowy. Każdy krok powinien być wykonany w ramach transakcji, aby zapewnić atomowość migracji.
W środowisku produkcyjnym, gdzie baza danych jest używana na żywo, migracja do 3NF wymaga dodatkowych zabezpieczeń. Należy zaplanować okno konserwacyjne, wykonać kopię zapasową, przetestować migrację na kopii bazy danych, a dopiero potem wykonać ją na produkcji. W systemach o wysokiej dostępności można zastosować migrację online z użyciem triggerów lub narzędzi do replikacji danych.
-- Dane z kodem przez JOIN SELECT c.Imie, c.Nazwisko, c.Miasto, m.KodPocztowy FROM Czytelnicy c JOIN Miasta m ON c.Miasto = m.Miasto;

Stwierdzenie "Każda normalizacja dodaje JOIN-y, ale eliminuje anomalie" oddaje fundamentalny kompromis w projektowaniu baz danych. Każdy kolejny poziom normalizacji zwiększa liczbę tabel w bazie danych, co z kolei wymaga większej liczby złączeń (JOIN) w zapytaniach. Z drugiej strony, eliminuje to anomalie INSERT, UPDATE i DELETE, które mogłyby prowadzić do niespójności danych.
W przypadku 3NF, dodanie tabeli Miasta oznacza, że każde zapytanie wyświetlające kod pocztowy czytelnika musi teraz łączyć tabele Czytelnicy i Miasta. Przed normalizacją wystarczyło zapytanie: `SELECT KodPocztowy FROM Czytelnicy`. Po normalizacji: `SELECT m.KodPocztowy FROM Czytelnicy c JOIN Miasta m ON c.Miasto = m.Miasto`. Dodatkowy JOIN ma wpływ na wydajność, szczególnie przy dużych zbiorach danych.
W praktyce jednak wpływ dodatkowego JOIN-a na wydajność jest zwykle pomijalny, jeśli indeksy są prawidłowo skonfigurowane. W systemach z tysiącami czy nawet milionami rekordów, JOIN na kolumnie z indeksem (Miasto) wykonuje się w milisekundach. Koszt normalizacji w postaci dodatkowego JOIN-a jest więc niewspółmiernie mały w porównaniu do korzyści, jakie przynosi eliminacja anomalii i zapewnienie integralności danych.
CREATE TABLE Gatunki ( Nazwa VARCHAR(50) PRIMARY KEY, Opis TEXT, KategoriaNadrzędna VARCHAR(50) ); ALTER TABLE Ksiazki ADD CONSTRAINT fk_gatunek FOREIGN KEY (Gatunek) REFERENCES Gatunki(Nazwa);
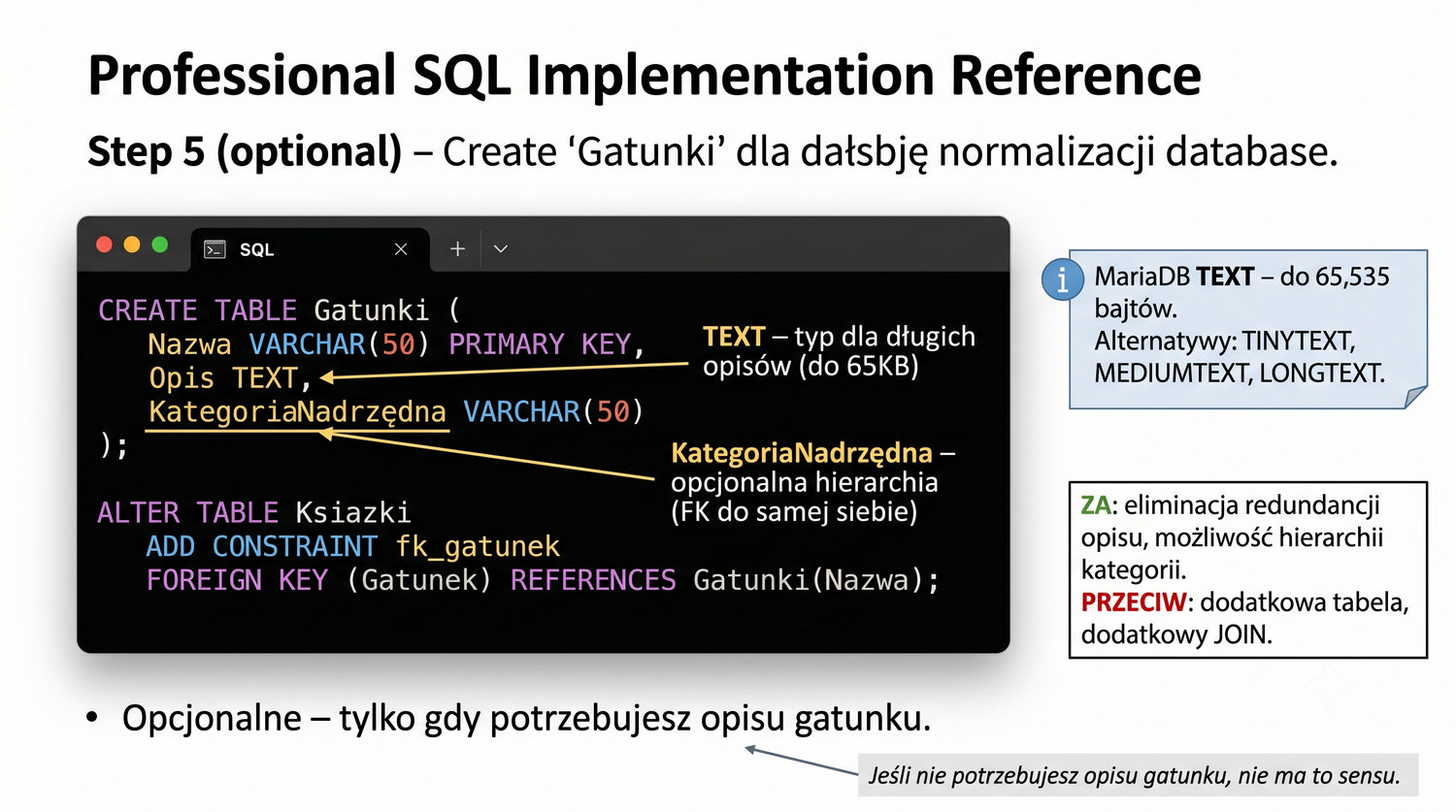
Typ TEXT w MariaDB jest używany do przechowywania długich ciągów znaków, które przekraczają limit standardowego VARCHAR (zwykle 65535 znaków). W kontekście 3NF, typ TEXT może być używany do przechowywania opisów w tabelach słownikowych. Na przykład, opis gatunku w tabeli Gatunki (jeśli zdecydujemy się na jej utworzenie) może być przechowywany jako TEXT, ponieważ opisy mogą być długie.
MariaDB oferuje kilka typów tekstowych: TINYTEXT (do 255 bajtów), TEXT (do 65535 bajtów), MEDIUMTEXT (do 16 MB) i LONGTEXT (do 4 GB). Wybór odpowiedniego typu zależy od przewidywanej długości danych. W systemie bibliotecznym rzadko będziemy potrzebować więcej niż TEXT dla opisów. Warto pamiętać, że kolumny typu TEXT mają pewne ograniczenia – nie mogą być częścią klucza głównego i wymagają indeksów FULLTEXT dla wyszukiwania.
Z punktu widzenia normalizacji, przechowywanie długich opisów w osobnych tabelach jest dobrą praktyką. Nawet jeśli opis jest długi, nie tworzy to zależności przechodniej – opis zależy bezpośrednio od klucza głównego tabeli, w której się znajduje. Jednak z punktu widzenia wydajności, warto rozważyć wydzielenie długich opisów do osobnej tabeli, aby nie obciążać pamięci przy zapytaniach, które nie potrzebują opisu.
-- Sprawdź kolumny Czytelnicy SELECT COLUMN_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'Czytelnicy'; -- Każda kolumna zależy od ID\_Czytelnika (bezpośrednio) -- 3NF spełniona!
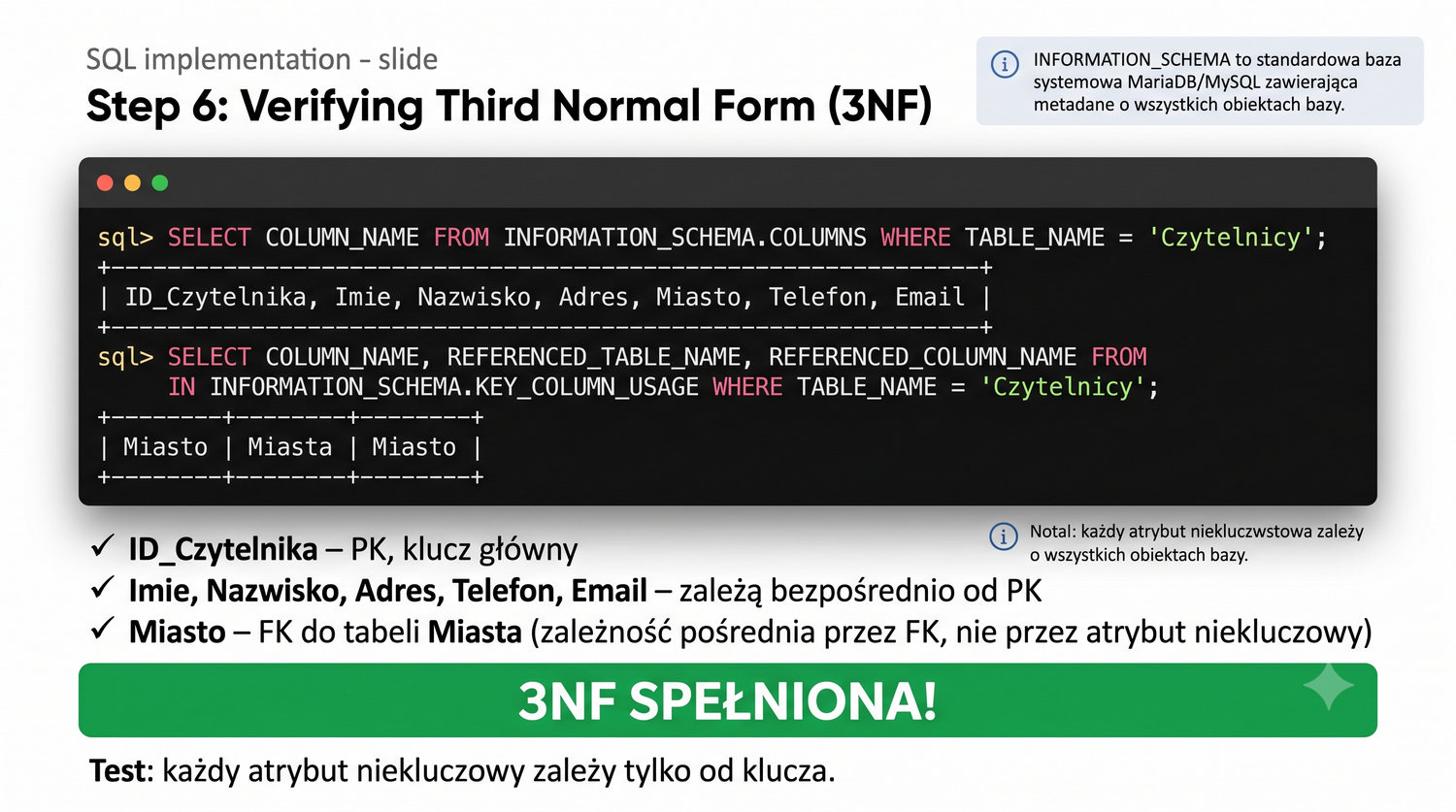
INFORMATION_SCHEMA to standardowa baza danych systemowych dostępna w MariaDB i MySQL, która zawiera metadane o wszystkich obiektach w bazie danych – tabelach, kolumnach, indeksach, kluczach obcych, ograniczeniach i wielu innych. Dla projektanta baz danych INFORMATION_SCHEMA jest nieocenionym narzędziem do analizy struktury bazy danych i weryfikacji poprawności normalizacji.
Można użyć INFORMATION_SCHEMA do sprawdzenia, czy klucze obce są prawidłowo zdefiniowane po dekompozycji do 3NF. Na przykład, zapytanie: `SELECT COLUMN_NAME, REFERENCED_TABLE_NAME, REFERENCED_COLUMN_NAME FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE TABLE_NAME = 'Czytelnicy'` wyświetli wszystkie klucze obce w tabeli Czytelnicy, w tym klucz do tabeli Miasta.
W kontekście 3NF, INFORMATION_SCHEMA może być używane do automatycznej walidacji, czy baza danych spełnia wymagania normalizacyjne. Można sprawdzić, czy wszystkie tabele mają klucze główne, czy klucze obce są indeksowane, czy nie ma kolumn o zduplikowanych nazwach w różnych tabelach itp. To narzędzie jest szczególnie przydatne przy audycie istniejących baz danych przed migracją do nowej struktury.
| Etap | Tabele |
|---|---|
| Przed norm. | 1 |
| Po 1NF | 1 |
| Po 2NF | 3 |
| Po 3NF | 4-5 |
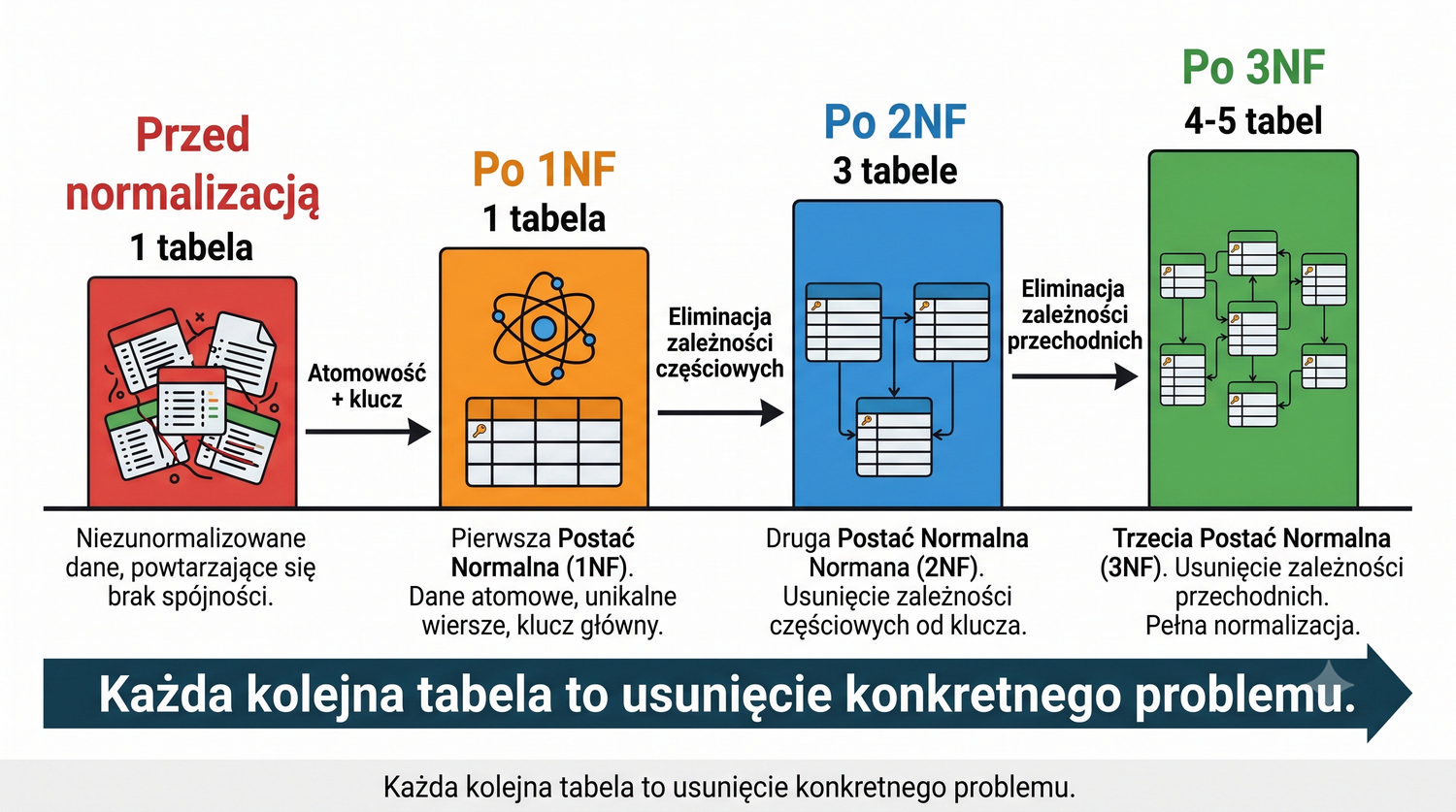
3NF to zazwyczaj ostatni krok w praktycznych systemach.

Zasada "Najpierw zaprojektuj w 3NF, potem optymalizuj" pojawia się w tej prezentacji po raz trzeci, co świadczy o jej fundamentalnym znaczeniu. Nawet w slajdzie dotyczącym wyjątków od normalizacji, ta zasada pozostaje aktualna. Nawet jeśli docelowo planujemy denormalizację (np. dla systemu OLAP czy systemu czasu rzeczywistego), punktem wyjścia zawsze powinna być baza w 3NF.
Świadoma denormalizacja różni się od przypadkowego bałaganu w danych. W pierwszym przypadku wiemy, jakie anomalie wprowadzamy i dlaczego to robimy – mamy udokumentowaną decyzję projektową. W drugim przypadku po prostu nie zdajemy sobie sprawy z problemów, które mogą wyniknąć z nieprawidłowej struktury danych. Różnica jest fundamentalna dla jakości i utrzymywalności systemu.
Przykładowo, w systemie OLAP można świadomie pozostawić kod pocztowy w tabeli faktów, aby przyspieszyć zapytania agregujące. Ale ta decyzja powinna być podjęta po analizie: wiemy, że kod pocztowy jest zależny od miasta, wiemy, że może powodować anomalie, ale akceptujemy to ryzyko w zamian za 10-krotne przyspieszenie zapytań. Taka decyzja jest świadoma i możliwa do odwrócenia w przyszłości.
(ID\_Biletu, Klient, Email, Film, GatunekFilmu, Sala, Data, Godzina, Cena)
Rozwiązanie: Filmy, Klienci, Bilety.
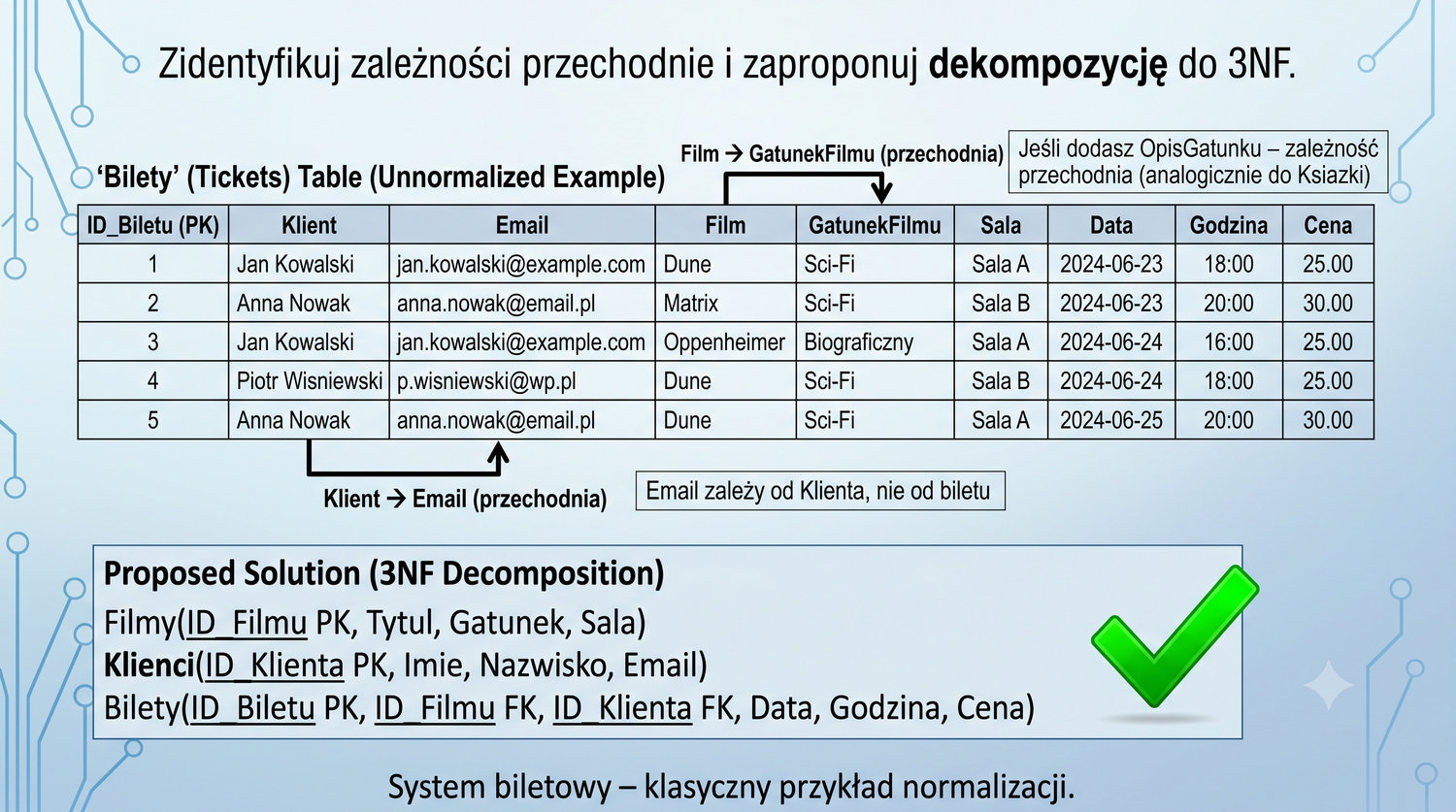
Ćwiczenie dotyczące systemu wypożyczania filmów (analogicznego do systemu bibliotecznego) wymaga od studentów samodzielnego zastosowania reguł 3NF. W tabeli Bilety znajdują się dane filmu (tytuł, gatunek) oraz dane klienta (imię, nazwisko). Celem ćwiczenia jest rozpoznanie, że dane filmu i dane klienta powinny znajdować się w osobnych tabelach, ponieważ reprezentują różne encje.
Zależności funkcyjne w tabeli Bilety: ID_Biletu → ID_Filmu → Tytul, Gatunek oraz ID_Biletu → ID_Klienta → Imie, Nazwisko. Obie są zależnościami przechodnimi, które należy wyeliminować. Rozwiązanie: tabele Filmy (ID_Filmu, Tytul, Gatunek), Klienci (ID_Klienta, Imie, Nazwisko) oraz Bilety (ID_Biletu, ID_Filmu (FK), ID_Klienta (FK), Data, Cena).
To ćwiczenie pokazuje, że wzorzec 3NF jest uniwersalny – niezależnie od dziedziny (książki, filmy, produkty), reguły normalizacji są takie same. Studenci powinni nauczyć się rozpoznawać encje i zależności funkcyjne w dowolnym zestawie danych, co jest kluczową umiejętnością w projektowaniu baz danych. System filmowy jest często łatwiejszy do zrozumienia dla studentów niż system biblioteczny.
(ID\_Prac, Imie, Stanowisko, PlacaMin, PlacaMax, ID\_Dzialu, NazwaDzialu, Budzet)
Rozwiązanie: Stanowiska, Dzialy, Pracownicy.

Ćwiczenie dotyczące systemu kadrowego jest bardziej złożone, ponieważ zawiera wiele encji i wiele zależności przechodnich. W tabeli Pracownicy mamy: ID_Prac, Imie, Stanowisko, PlacaMin, PlacaMax, ID_Dzialu, NazwaDzialu, Budzet. Zależności funkcyjne: ID_Prac → Stanowisko → PlacaMin, PlacaMax oraz ID_Prac → ID_Dzialu → NazwaDzialu, Budzet. Rozwiązanie wymaga utworzenia trzech tabel.
Pierwsza tabela: Stanowiska(ID_Stanowiska, NazwaStanowiska, PlacaMin, PlacaMax). Druga: Dzialy(ID_Dzialu, NazwaDzialu, Budzet). Trzecia: Pracownicy(ID_Prac, Imie, ID_Stanowiska(FK), ID_Dzialu(FK)). Każda z tych tabel spełnia wymagania 3NF – wszystkie atrybuty niekluczowe zależą bezpośrednio od klucza głównego swojej tabeli. To ćwiczenie pokazuje, że w realnym systemie może być wiele zależności przechodnich.
W systemach kadrowych często występują również lokalizacje, co dodaje kolejny poziom normalizacji. Jeśli tabela Dzialy zawiera kolumnę Lokalizacja, a lokalizacje mają swoje atrybuty (np. adres, powierzchnia), to należy utworzyć osobną tabelę Lokalizacje. W praktyce, systemy kadrowe mogą mieć od 5 do 10 tabel słownikowych (stanowiska, działy, lokalizacje, departamenty, itp.), co wymaga starannego projektowania.
-- 1NF: prosty SELECT SELECT Czytelnik, Miasto, KodPocztowy FROM Wypozyczenia_1NF; -- 3NF: JOIN-y SELECT c.Imie, m.KodPocztowy, k.Tytul FROM Wypozyczenia w JOIN Czytelnicy c ... JOIN Miasta m ... JOIN Ksiazki k ...;
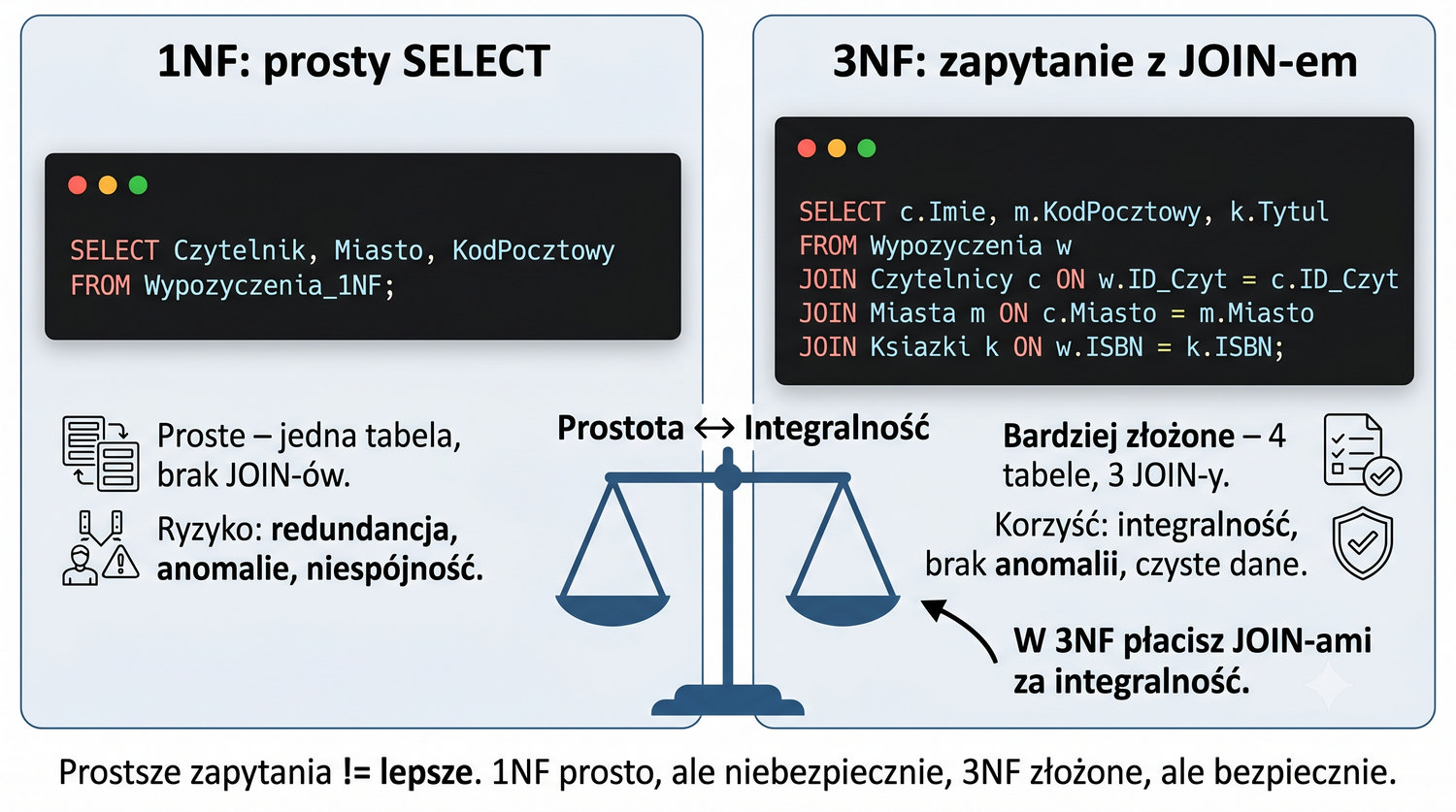
Stwierdzenie "W 3NF płacisz JOIN-ami za integralność" oddaje kompromis, jaki projektant bazy danych akceptuje, decydując się na normalizację. Koszt normalizacji to przede wszystkim konieczność wykonywania dodatkowych operacji JOIN podczas odczytu danych. Zamiast jednej tabeli, z której można odczytać wszystkie dane, po normalizacji potrzebujemy połączenia dwóch lub więcej tabel.
W rzeczywistości jednak koszt ten jest często przeszacowany. Nowoczesne systemy bazodanowe są zoptymalizowane do wykonywania JOIN-ów – jeśli kolumny używane do łączenia są indeksowane, JOIN wykonuje się w ułamku milisekundy. W systemie bibliotecznym z tysiącem czytelników, JOIN tabel Czytelnicy i Miasta po kolumnie Miasto (z indeksem) jest praktycznie natychmiastowy.
Koszt JOIN-a staje się istotny dopiero przy bardzo dużych wolumenach danych (miliony rekordów) lub przy bardzo złożonych zapytaniach (10+ JOIN-ów). W takich przypadkach można rozważyć denormalizację lub zastosowanie widoków zindeksowanych. Jednak dla zdecydowanej większości systemów biznesowych, koszt JOIN-ów jest akceptowalny w zamian za integralność danych, którą zapewnia 3NF.
CREATE VIEW WypozyczeniaPelne AS SELECT ... FROM Wypozyczenia w JOIN Czytelnicy c ... JOIN Miasta m ... JOIN Ksiazki k ...; SELECT * FROM WypozyczeniaPelne WHERE Nazwisko = 'Kowalski';
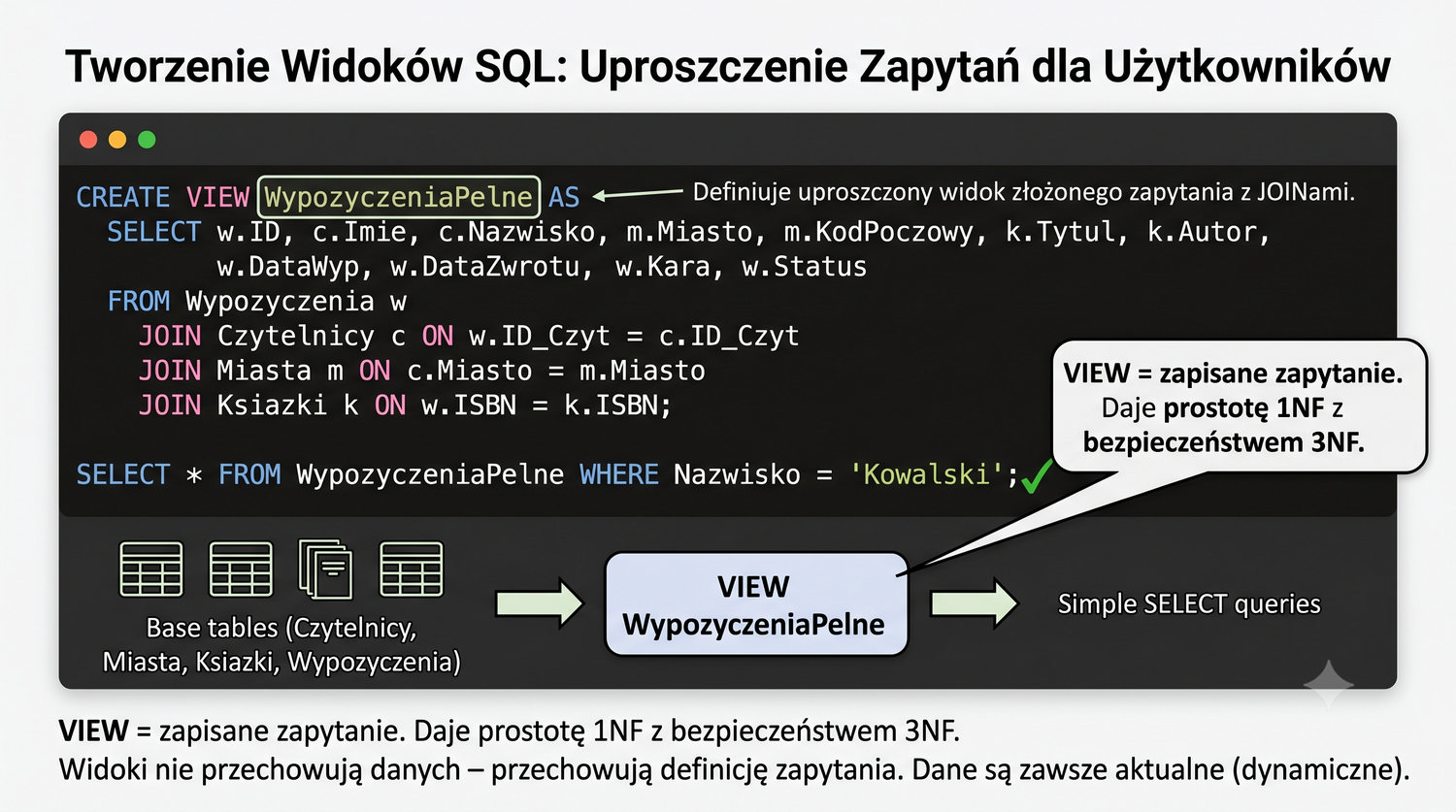
Widoki (VIEW) w SQL są zapisanymi zapytaniami, które można traktować jak wirtualne tabele. W kontekście 3NF, widoki są szczególnie przydatne do raportowania – pozwalają na połączenie danych z wielu tabel w jeden zestaw wynikowy bez konieczności każdorazowego pisania złożonych zapytań. Użytkownik może pracować z widokiem tak, jakby był to pojedyncza tabela.
Przykładowo, możemy utworzyć widok `CzytelnicyZMiastami`, który łączy tabele Czytelnicy i Miasta: `CREATE VIEW CzytelnicyZMiastami AS SELECT c.ID_Czytelnika, c.Imie, c.Nazwisko, m.Miasto, m.KodPocztowy FROM Czytelnicy c JOIN Miasta m ON c.Miasto = m.Miasto`. Raportujący może teraz wykonać `SELECT * FROM CzytelnicyZMiastami` bez znajomości struktury normalizacyjnej.
Widoki dają "prostotę 1NF z bezpieczeństwem 3NF" – użytkownik widzi dane tak, jakby były w jednej tabeli, podczas gdy w rzeczywistości są one przechowywane w osobnych tabelach znormalizowanych do 3NF. To najlepszy przykład praktycznego wykorzystania normalizacji: dane są przechowywane w sposób zapewniający integralność, ale prezentowane w sposób wygodny dla użytkownika końcowego.
Stwierdzenie "Większość systemów produkcyjnych zatrzymuje się na 3NF" pojawia się w tej prezentacji po raz trzeci i ostatni, co podkreśla, jak ważna jest to zasada w praktyce inżynierskiej. 3NF jest uznawana za standard przemysłowy, ponieważ zapewnia optymalny balans między integralnością danych a wydajnością zapytań. Systemy produkcyjne rzadko wymagają dalszych postaci normalnych.
Warto jednak rozumieć, dlaczego systemy się na tym zatrzymują. BCNF jest potrzebna tylko w specyficznym przypadku nakładających się kluczy kandydujących, co w praktyce występuje rzadko. 4NF eliminuje zależności wielowartościowe, które pojawiają się, gdy jedna encja ma wiele niezależnych atrybutów wielowartościowych. 5NF dotyczy zależności złączeniowych, które są jeszcze rzadsze.
Dla 90% systemów biznesowych 3NF jest w pełni wystarczająca. Zamiast dalszej normalizacji, projektanci często skupiają się na optymalizacji zapytań, indeksowaniu, partycjonowaniu tabel i innych technikach poprawy wydajności, które nie wymagają zmiany struktury logicznej bazy danych. Znajomość dalszych postaci normalnych jest jednak ważna, aby móc rozpoznać wyjątkowe sytuacje, w których są one potrzebne.
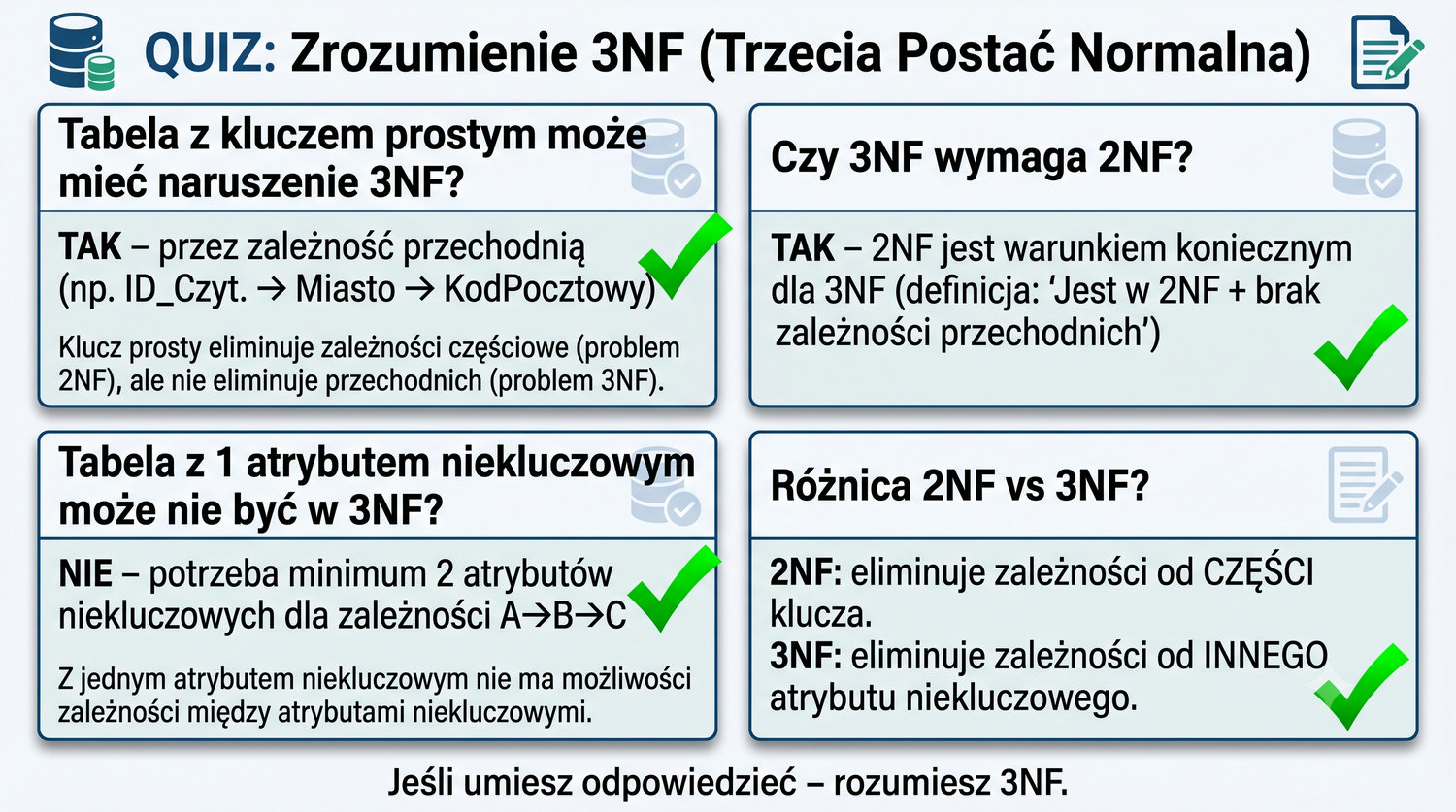
Porównanie 2NF i 3NF pod kątem rodzaju eliminowanych zależności jest kluczowe dla zrozumienia różnicy między tymi postaciami normalnymi. 2NF eliminuje zależności częściowe – sytuację, w której atrybut niekluczowy zależy tylko od części klucza głównego (w przypadku klucza złożonego). 3NF eliminuje zależności przechodnie – sytuację, w której atrybut niekluczowy zależy od innego atrybutu niekluczowego.
Różnicę można zilustrować na przykładzie tabeli Wypozyczenia z kluczem złożonym (ID_Czytelnika, ISBN). W 2NF wyeliminowaliśmy zależności częściowe: ISBN → Tytul (Tytul zależy od ISBN, nie od całego klucza) i ID_Czytelnika → Nazwisko (Nazwisko zależy od ID_Czytelnika). W 3NF wyeliminowaliśmy zależności przechodnie: ID_Czytelnika → Miasto → KodPocztowy (KodPocztowy zależy od Miasta, nie od ID_Czytelnika).
W praktyce rozróżnienie jest proste: jeśli problem dotyczy atrybutu zależnego od CZĘŚCI klucza głównego, to jest to problem 2NF. Jeśli problem dotyczy atrybutu zależnego od INNEGO atrybutu niekluczowego, to jest to problem 3NF. W obu przypadkach rozwiązaniem jest dekompozycja tabeli, ale w 2NF wydzielamy atrybuty zależne od części klucza, a w 3NF wydzielamy atrybuty zależne od innych atrybutów niekluczowych.
| Cecha | 1NF | 2NF | 3NF |
|---|---|---|---|
| Atomowość | ✔ | ✔ | ✔ |
| Brak grup | ✔ | ✔ | ✔ |
| Klucz główny | ✔ | ✔ | ✔ |
| Brak częściowych | ✘ | ✔ | ✔ |
| Brak przechodnich | ✘ | ✘ | ✔ |
| Liczba tabel | 1 | 3 | 4-5 |
3NF to najwyższa postać używana w praktyce.

Stwierdzenie "Optymalny poziom dla większości systemów" pojawia się w różnych kontekstach w tej prezentacji i za każdym razem odnosi się do 3NF. 3NF jest uznawana za optymalną, ponieważ znajduje złoty środek między integralnością danych (celem normalizacji) a wydajnością zapytań (celem praktycznym). Niższe postaci normalne (1NF, 2NF) pozostawiają anomalie, wyższe (4NF, 5NF) dodają złożoność bez proporcjonalnych korzyści.
W praktyce oznacza to, że dla zdecydowanej większości systemów informatycznych – systemów bibliotecznych, handlowych, kadrowych, magazynowych, bankowych – 3NF jest poziomem docelowym. Projektant bazy danych powinien dążyć do 3NF, a odstępstwa od tej reguły powinny być świadome i uzasadnione konkretnymi wymaganiami biznesowymi lub technicznymi.
Systemy, które wykraczają poza 3NF, zazwyczaj robią to z konkretnych powodów: (1) wymagania analityczne (OLAP) – celowa denormalizacja dla szybszych agregacji, (2) wymagania czasu rzeczywistego – minimalizacja JOIN-ów dla szybszych odpowiedzi, (3) specyficzne wymagania domenowe – np. systemy GIS, które mają swoje własne reguły modelowania danych. W każdym przypadku decyzja powinna być udokumentowana.
Zasada "Najpierw projekt w 3NF, potem optymalizacja" jest wariantem wcześniej omawianej reguły. Projektowanie bazy danych powinno zawsze zaczynać się od pełnej normalizacji do 3NF, niezależnie od przewidywanych wymagań wydajnościowych. Dopiero po zakończeniu fazy projektowania logicznego i wdrożeniu systemu, na podstawie rzeczywistych pomiarów, można świadomie odstąpić od normalizacji.
Ta zasada jest analogiczna do ogólnej zasady inżynierii oprogramowania: "najpierw napisz czysty kod, potem optymalizuj". W kontekście baz danych oznacza to, że najpierw projektujemy strukturę, która jest logicznie spójna i wolna od anomalii, a dopiero później, jeśli wydajność jest niezadowalająca, wprowadzamy optymalizacje, które mogą obejmować denormalizację.
W praktyce, większość systemów po wdrożeniu nie wymaga znaczących modyfikacji struktury – 3NF zapewnia wystarczającą wydajność dla typowych zapytań. Jeśli jednak wydajność jest problemem, istnieje wiele technik optymalizacji, które nie wymagają denormalizacji: indeksowanie, partycjonowanie, widoki zindeksowane, materializowane, cache'owanie, replikacja. Denormalizacja powinna być ostatecznością.
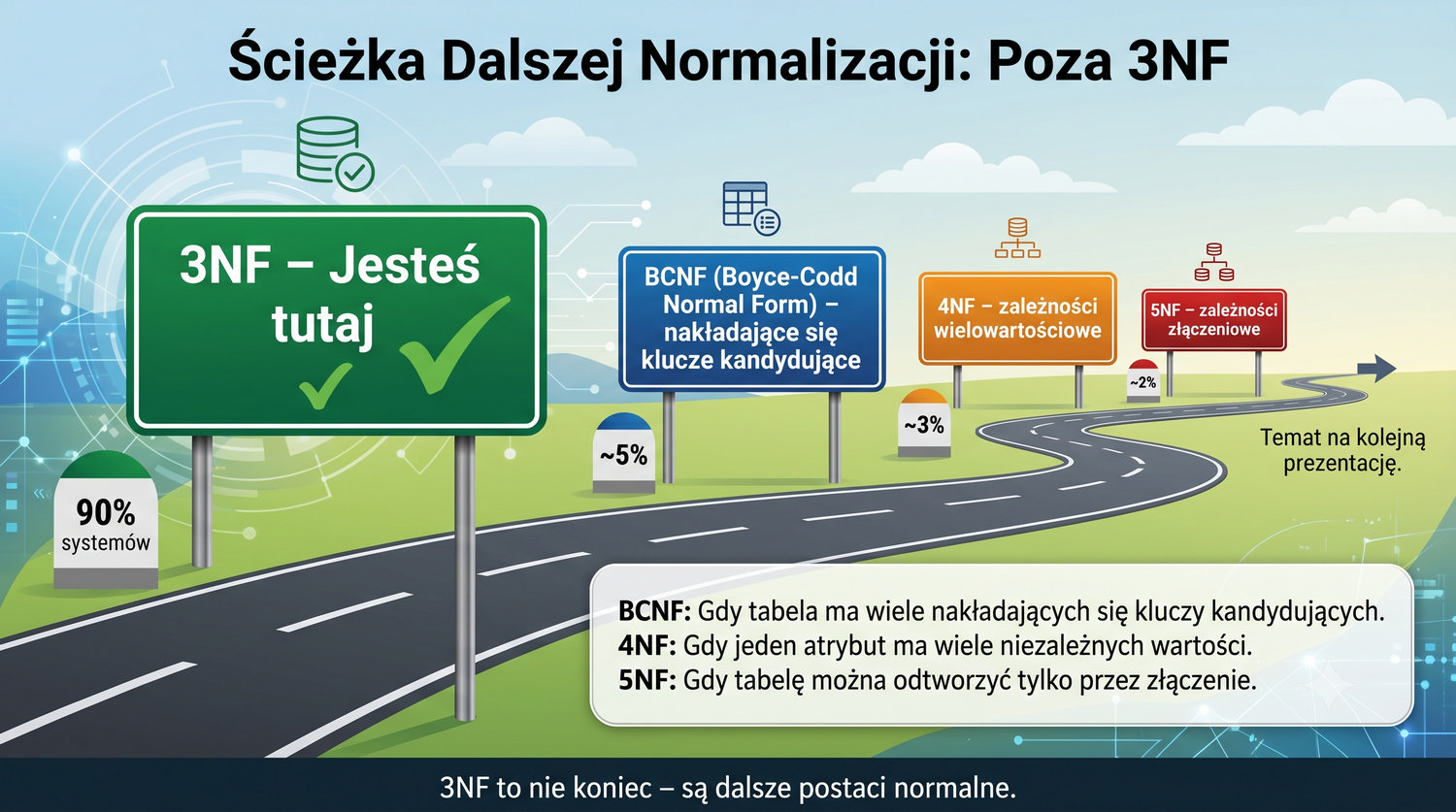
Stwierdzenie "Temat na kolejną prezentację" pojawia się w kontekście zapowiedzi dalszych postaci normalnych (BCNF, 4NF, 5NF) oraz technik zaawansowanych. Prezentacja o 3NF jest trzecią z serii poświęconej normalizacji – po 1NF i 2NF. Kolejne prezentacje będą dotyczyć wyższych postaci normalnych, które są rzadziej stosowane w praktyce, ale warto je znać.
Studenci powinni potraktować tę zapowiedź jako zachętę do samodzielnego zgłębienia tematu. BCNF jest naturalnym rozszerzeniem 3NF dla przypadków z nakładającymi się kluczami kandydującymi. 4NF i 5NF dotyczą bardziej zaawansowanych problemów, które pojawiają się w specyficznych scenariuszach. Zrozumienie tych koncepcji jest ważne dla pełnego opanowania teorii normalizacji.
W praktyce zawodowej, znajomość dalszych postaci normalnych może być potrzebna przy projektowaniu systemów o wysokich wymaganiach integralnościowych – systemów bankowych, medycznych, czy naukowych. Nawet jeśli rzadko stosuje się je bezpośrednio, ich znajomość pogłębia zrozumienie teorii relacyjnych baz danych i pomaga w podejmowaniu świadomych decyzji projektowych.
3 z 6 kroków – w połowie drogi.
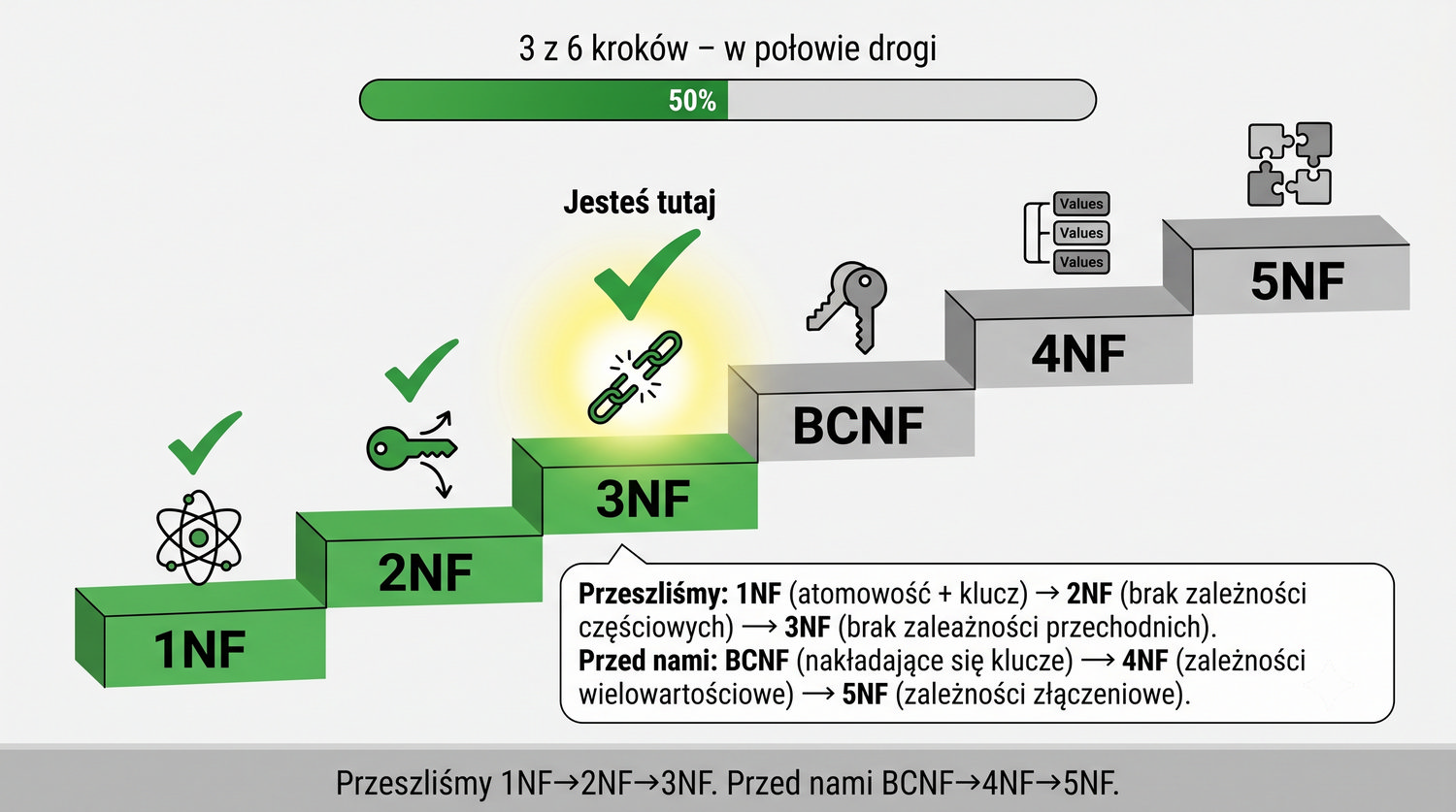
"Połowa drogi za nami" – to stwierdzenie pojawia się w kontekście całego kursu baz danych. Po przerobieniu 1NF, 2NF i 3NF, studenci mają za sobą połowę materiału z normalizacji. Przed nimi jeszcze BCNF, 4NF i 5NF. W szerszym kontekście całego przedmiotu, normalizacja jest jednym z kluczowych tematów, obok języka SQL, projektowania schematów i zarządzania transakcjami.
Połowa drogi oznacza również, że studenci zdobyli już umiejętność projektowania poprawnych struktur baz danych dla większości praktycznych zastosowań. 3NF jest wystarczająca dla 90% systemów produkcyjnych, więc studenci mogą już projektować bazy danych na poziomie profesjonalnym. Dalsze postaci normalne to już specjalistyczna wiedza dla zaawansowanych przypadków.
Warto jednak pamiętać, że normalizacja to tylko jeden z aspektów projektowania baz danych. Równie ważne są: modelowanie danych (diagramy ER), język SQL (zapytania, manipulacja danymi), optymalizacja wydajności (indeksy, zapytania), bezpieczeństwo (uprawnienia, szyfrowanie) i zarządzanie transakcjami (ACID). Każdy z tych tematów jest równie obszerny i ważny w praktyce zawodowej.
(ID\_Dostawy, ID\_Produktu, NazwaProduktu, ID\_Dostawcy, NazwaDostawcy, AdresDostawcy, Data, Ilosc, Cena)
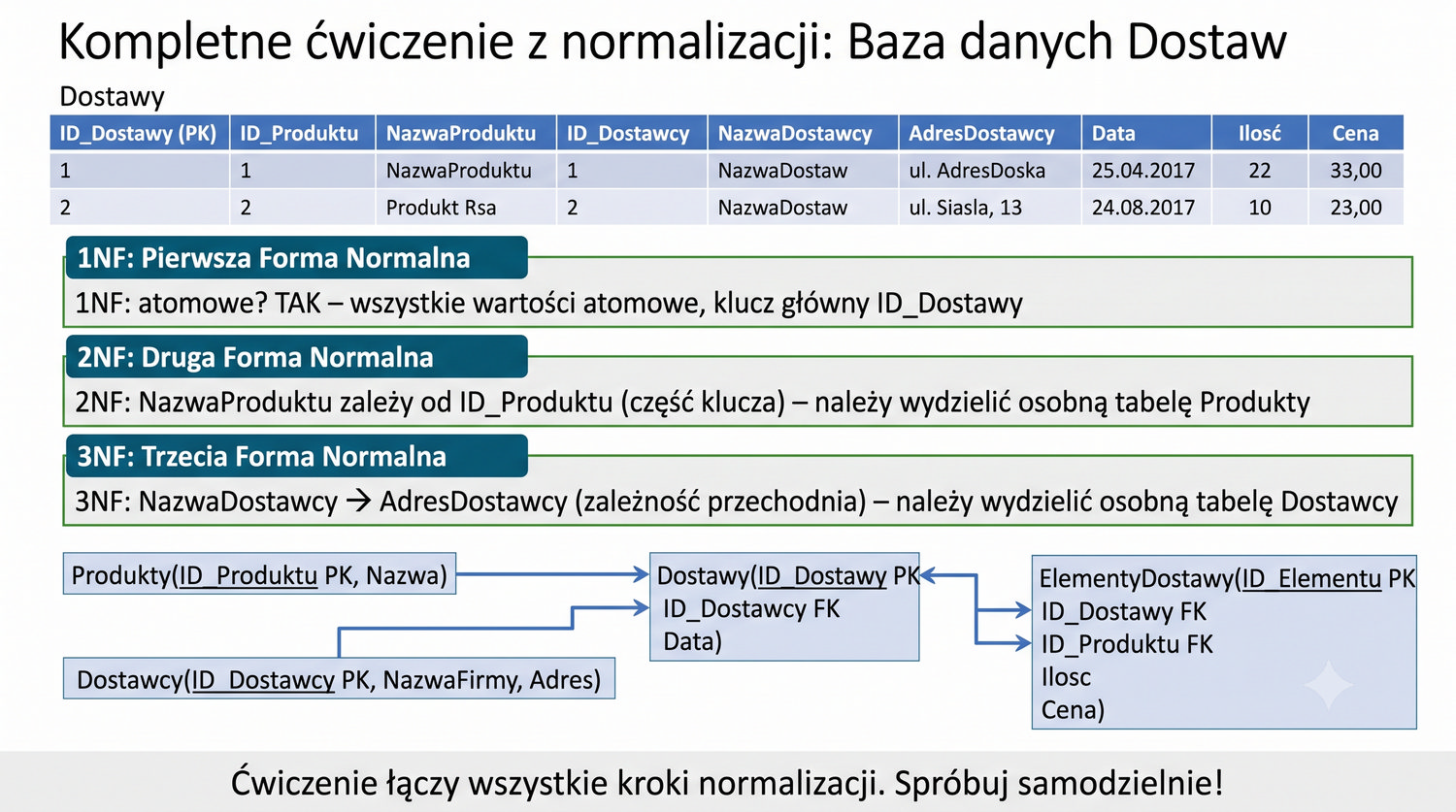
Lista "Produkty, Dostawcy, Dostawy, ElementyDostaw" to podpowiedź do ćwiczenia dla studentów, którzy mają zaprojektować schemat bazy danych dla systemu magazynowego. Każda z tych encji reprezentuje osobny byt w systemie: Produkty (towary w magazynie), Dostawcy (firmy dostarczające towary), Dostawy (zdarzenia dostawy) i ElementyDostaw (szczegóły każdej dostawy – które produkty i w jakiej ilości).
Studenci powinni samodzielnie określić klucze główne, atrybuty i zależności funkcyjne dla każdej encji. Produkty: ID_Produktu, Nazwa, Cena, Kategoria. Dostawcy: ID_Dostawcy, NazwaFirmy, Adres, Telefon. Dostawy: ID_Dostawy, ID_Dostawcy(FK), DataDostawy, Status. ElementyDostaw: ID_Elementu, ID_Dostawy(FK), ID_Produktu(FK), Ilosc, CenaJednostkowa.
Następnie studenci powinni znormalizować ten schemat do 3NF. Potencjalne problemy: kategoria produktu może mieć opis (zależność przechodnia), adres dostawcy może zawierać miasto i kod pocztowy (zależność przechodnia), cena jednostkowa w ElementyDostaw może zależeć od produktu (zależność funkcyjna do sprawdzenia). To ćwiczenie integruje wiedzę z 1NF, 2NF i 3NF w jednym praktycznym zadaniu.
Efekt: czysta, spójna baza.
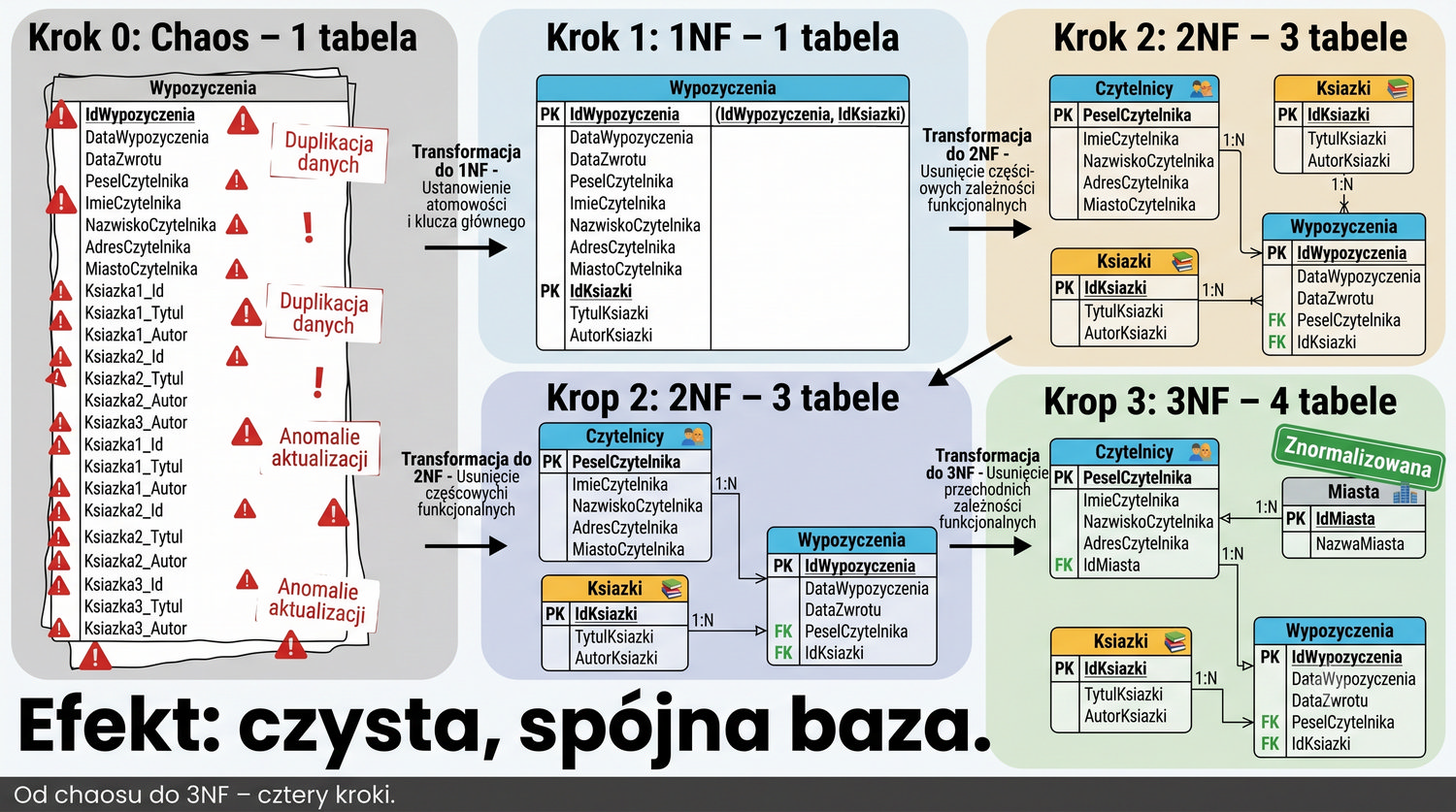
Stwierdzenie "Z jednej wielkiej tabeli do dobrze zaprojektowanej bazy" podsumowuje cały proces normalizacji, który studenci przeszli przez trzy prezentacje: 1NF, 2NF i 3NF. Punktem wyjścia była jedna, nienormalizowana tabela Wypozyczenia zawierająca wszystkie dane w jednym miejscu – dane czytelników, książek i wypożyczeń wymieszane ze sobą, z grupami powtarzalnymi i redundancją.
Po trzech etapach normalizacji z jednej tabeli powstało 4-5 tabel: Czytelnicy, Miasta, Ksiazki, Wypozyczenia i opcjonalnie Gatunki. Każda tabela ma jasno określony cel, klucz główny i zestaw atrybutów bezpośrednio zależnych od tego klucza. Redundancja jest zminimalizowana, anomalie wyeliminowane, a integralność danych zapewniona. To właśnie jest cel normalizacji.
Proces ten – od chaotycznej, nienormalizowanej struktury do czystej, znormalizowanej bazy danych – jest analogiczny do procesu refaktoryzacji kodu w inżynierii oprogramowania. W obu przypadkach celem jest poprawa jakości, utrzymywalności i integralności (w przypadku kodu – czytelności i testowalności). To pokazuje, że normalizacja jest nie tylko techniką techniczną, ale przede wszystkim dyscypliną projektową.

"Warto sięgnąć do oryginałów" – to zachęta do samodzielnego studiowania oryginalnych prac Edgara F. Codda, który w 1970 roku opublikował przełomowy artykuł "A Relational Model of Data for Large Shared Data Banks", wprowadzający relacyjny model danych. Codd później zdefiniował 1NF, 2NF i 3NF w artykułach z 1971 i 1972 roku, kładąc podwaliny pod całą dziedzinę normalizacji.
Oryginalne prace Codda są napisane językiem formalnym i matematycznym, ale ich zrozumienie daje głęboki wgląd w fundamenty teorii relacyjnych baz danych. Dla studentów informatyki, którzy chcą pogłębić swoją wiedzę, sięgnięcie do oryginalnych źródeł jest nieocenione. Warto również poznać prace Raymonda F. Boyce'a i innych badaczy, którzy rozwijali teorię normalizacji.
W epoce internetu oryginalne publikacje są łatwo dostępne – wiele z nich można znaleźć w cyfrowych bibliotekach ACM i IEEE. Polecam również podręczniki: "Database System Concepts" (Silberschatz, Korth, Sudarshan) oraz "Fundamentals of Database Systems" (Elmasri, Navathe), które zawierają szczegółowe omówienie normalizacji z przykładami i ćwiczeniami. Samodzielna lektura pogłębia zrozumienie i pozwala na krytyczne myślenie.

"Im więcej samodzielnie przeanalizujesz, tym lepiej" – to motto kończące prezentację o 3NF, które podkreśla znaczenie praktyki w nauce normalizacji. Teoria normalizacji jest stosunkowo prosta – kilka reguł, kilka definicji, kilka przykładów. Prawdziwe zrozumienie przychodzi jednak dopiero z praktyką, z samodzielnym rozwiązywaniem problemów i analizowaniem rzeczywistych struktur danych.
Zachęcam studentów do wzięcia dowolnego systemu informatycznego, z którego korzystają na co dzień – system biblioteczny uczelni, sklep internetowy, portal społecznościowy – i spróbowania odtworzenia schematu bazy danych, która za nim stoi. Jakie tabele mogą istnieć? Jakie są klucze główne? Jakie zależności funkcyjne występują? Czy baza jest w 3NF? To ćwiczenie rozwija umiejętność abstrakcyjnego myślenia.
Dodatkowym ćwiczeniem jest próba znalezienia w rzeczywistych systemach naruszeń normalizacji. Wiele komercyjnych systemów ma błędy w projekcie bazy danych – grupy powtarzalne, zależności częściowe, zależności przechodnie. Znajdowanie takich błędów i proponowanie poprawek to doskonały trening umiejętności normalizacyjnych. Im więcej samodzielnej analizy, tym lepsze zrozumienie i większa biegłość w projektowaniu baz danych.
Zapowiedź: BCNF – Boyce-Codd Normal Form
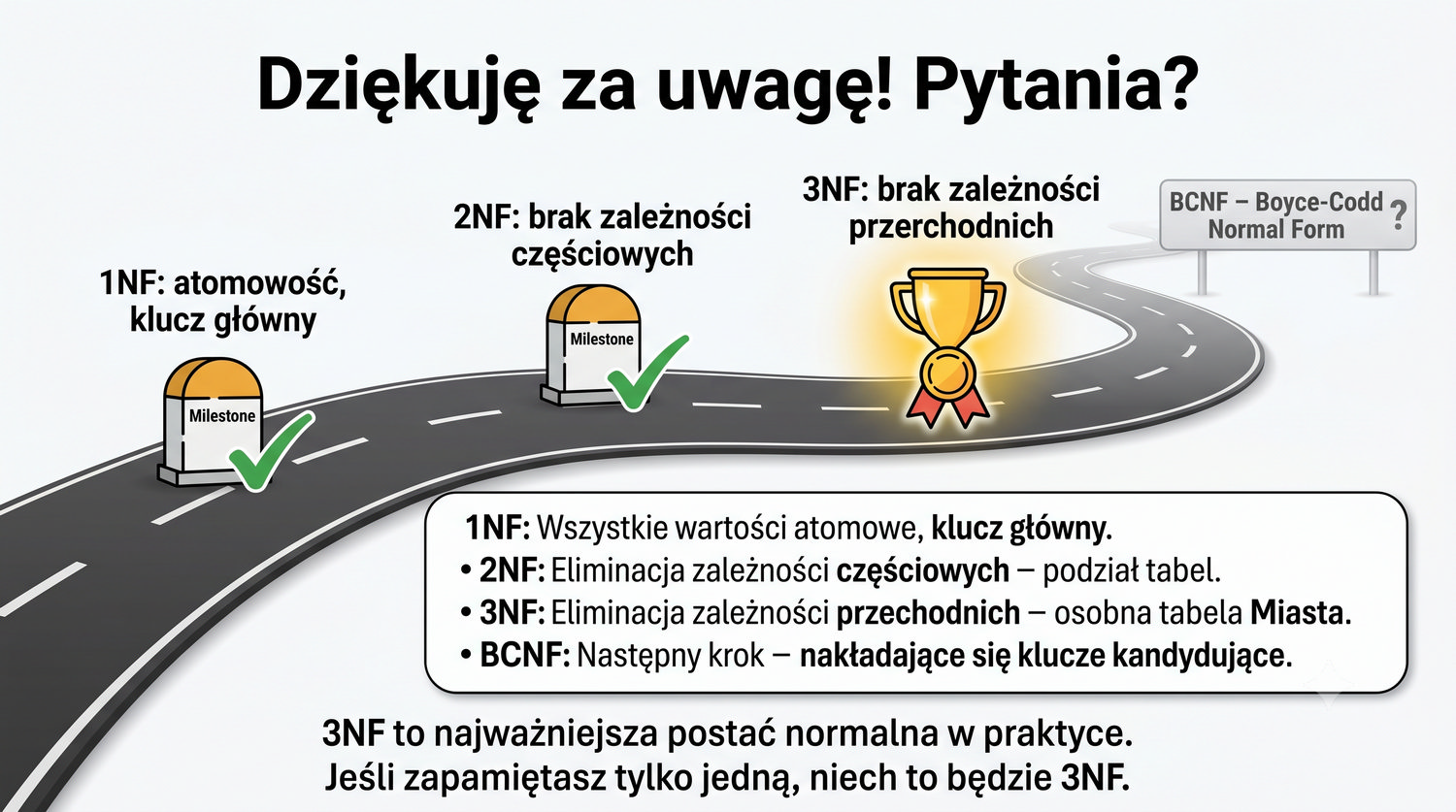
"Jeśli zapamiętasz tylko jedną, niech to będzie 3NF" – to ostatnie zdanie prezentacji, które podkreśla kluczowe znaczenie 3NF w praktyce projektowania baz danych. Spośród wszystkich postaci normalnych (1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF), 3NF jest najważniejsza, ponieważ stanowi standard przemysłowy dla systemów produkcyjnych.
3NF to "złoty środek" normalizacji – nie za mało (jak 1NF czy 2NF, które pozostawiają anomalie), nie za dużo (jak 4NF czy 5NF, które są zbyt restrykcyjne dla większości zastosowań). To poziom, do którego dąży się podczas projektowania, i poziom, na którym zatrzymuje się w praktyce. Znajomość 3NF jest absolutnie niezbędna dla każdego informatyka pracującego z bazami danych.
Rekomendacja na zakończenie: jeśli z całej prezentacji zapamiętasz tylko jedną rzecz, niech to będzie reguła 3NF: każdy atrybut niekluczowy musi zależeć wyłącznie od klucza głównego, i to w sposób bezpośredni – bez pośrednictwa innych atrybutów niekluczowych. Stosując tę regułę, zaprojektujesz bazę danych, która będzie integralna, utrzymywalna i gotowa do produkcji. To najważniejsza lekcja z całego kursu normalizacji.